Improved caching policies and hybrid strategy for query result cache①
2015-04-17QianLibing钱立兵
Qian Libing (钱立兵)
(School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, P.R.China)
Improved caching policies and hybrid strategy for query result cache①
Qian Libing (钱立兵)②
(School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, P.R.China)
To improve efficiency of search engines, the query result cache has drawn much attention recently. According to the query processing and user’s query logs locality, a new hybrid result cache strategy which associates with caching heat and worth is proposed to compute cache score in accordance with cost-aware strategies. Exactly, query repeated distance and query length factor are utilized to improve the static result policy, and the dynamic policy is adjusted by the caching worth. The hybrid result cache is implemented in term of the document content and document ids(docIds) sequence. Based on a score format and the new hybrid structure, an initial algorithm and a new routing algorithm are designed for result cache. Experiments’ results show that the improved caching policies decrease the average response time effectively, and increase the system throughput significantly. By choosing comfortable combination of page cache and docIds cache, the new hybrid caching strategy almost reduces more than 20% of the average query time compared with the basic page-only cache and docId-only cache.
query result cache, hybrid caching, query repeated distance, caching policy
0 Introduction
Result caching is widely used in large scale web search engines (WSE). Caching query result is an effective way to enhance system’s performance by storing the results of most recently and/or frequently queries[1]. Since typical result caching can directly respond pages for a large number of queries, the technique is contributed to realize a WSE to satisfy low response latency and high query processing throughput.
In WSE, the result caching mechanisms are extensively studied in literature. A common method is to create a static result cache which keeps the result pages associated with frequent queries obtained from the query log, and then updates periodically depending on the variation in access frequencies of items[2,3]. Another feasible approach is to employ a dynamic cache that aims to capture the recent queries which are more likely to be accessed in the near future[4, 5]. Ref.[6] shows that static cache can achieve better hit ratios in case of small cache capacities while dynamic cache is preferable for large capacity cache. Ref.[7] suggests a hybrid static and dynamic cache, called static-dynamic cache (SDC), which surpasses both static-only and dynamic-only caches. However, the method ignores the issue of capacity allocation between static and dynamic caches. The past research challenge lied in developing novel eviction policies[5]. The current challenge is to design effective policies to keep the cache entries fresh and maximize caching worth[4,8].
For the eviction and admission policies of result caching, many cache replacement policies have been proposed, such as Query Frequency (QF)[6], Query Frequency Stability (QFS)[2], Least Recently Used (LRU), Least Frequently Used (LFU), Least Costly Used (LCU), et al[8]. Since query frequencies follow a power-law distribution, QF and LFU cannot select high frequency queries among a large number of queries with the same (relatively low) frequency value. QFS only focuses on the stability of frequency which doesn’t reflect the degree of hot queries. Although LCU pays attention to the query cost-aware, it ignores the influence of frequency. Recently, many studies introduce optimized caching policies by analyzing the processing time cost of queries, including static policies (such as FreqThenCost, StabThenCost and FC_K,et al) and dynamic policies (such as LFCU_K, GDS et al)[9-11]. Although these cost admission caching can improve the performance of result cache, they don’t involve queries distribution, characteristic and caching worth. In admission caching policies, query repeated distance and query length factor are employed to further improve the cache effectiveness.
For the result cache architecture, a typical approach is employed to store the entire result pages (Page cache, abbr. PageC), which obtains as a response to query[12-14]. Considering the space consumption, a better alternative strategy is to store the documents ids of results (docIds cache, called docIdC)[7,15]. Given the amount of space, the docIdC can store more results than the PageC for a larger number of queries[13]. Therefore, docIdC can obtain higher hit rate than PageC. However, the docIdC needs to search document servers when acquiring the result page.
In this work, the paper draws attention to the result caching policies and architecture. For the caching policies, query heat strategies which use query length and query repeated distance are raised to extend the basic caching policies by analyzing query logs. For the cache structure, a new hybrid caching is presented which incorporates static/dynamic result page cache and static/dynamic result docId cache. On the basis of hybrid structure, an executive algorithm is achieved to optimize efficiency of the result cache.
Rest of the paper is organized as follows. In Section 1, the overview of query processing and main cost is provided in search engines. In Section 2, optimized result caching policies are proposed by analyzing query logs, and then new hybrid architecture of result cache is designed. Simulations are carried out in Section 3 to illustrate the efficiency. Finally, conclusion and future work are presented in Section 4.
1 Query processing
WSE is composed of multiple replicas of large search servers. Usually, the whole index is horizontally split and classified based on themes. Each index server is responsible for searching a partition of the whole index[16,17]. Fig.1 shows the architecture of a typical large-scale WSE, including Broker Servers (BS), multiple replicas of large Index Servers (IS) and Documents Servers (DS). In front of search serves, the BS schedules the queries to various users and collects the feedback results. Then, by merging and sorting the relevant results, BS obtains the ordered docIds. Finally, the docIds are employed to obtain the associated result pages from DS. Each result page includes titles, URLs, and snippets.
According to above-mentioned processing, several aspects overhead is considered (ignoring the network communication cost):
——It needs to fetch the associated inverted index for all terms of query, obtain the docIds from all index servers. The cost denoted as Clist, as step2 to step3 in Fig.1.
——For computing relevant scores, the top-N docIds with high scores are selected. Then the broker merges relevant docIds to get the final top-k docIds. The cost denoted as Crank, as step3~ step5 in Fig.1.
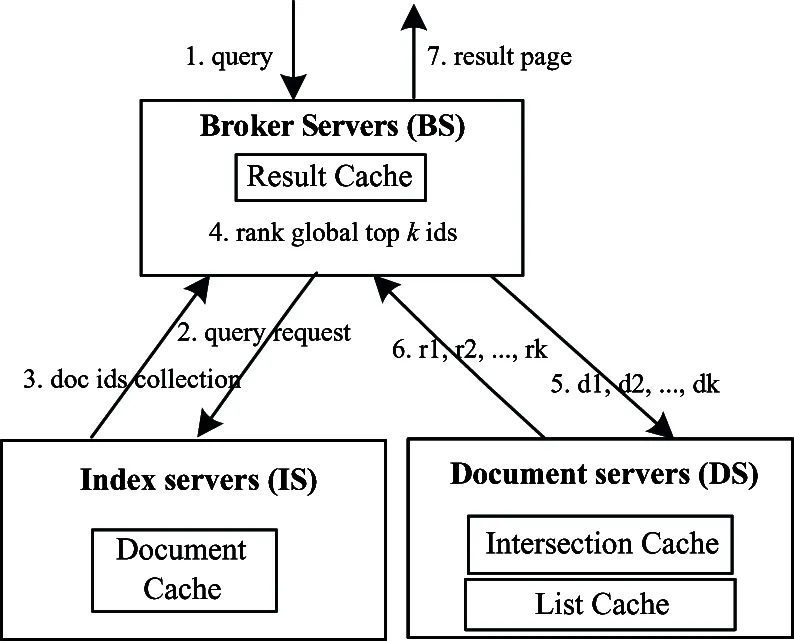
Fig.1 The basic query processing in a typical WSE
——For the top-k docIds, by obtaining the document contents and generating snippet, the final result page is acquired. The cost denoted as Cpage, as step5 to step6 in Fig.1.
In order to upgrade the performance of a search engine, many caches are employed in various level servers. Depending on the memory available on broker, result cache stores the whole result pages which enhance the WSE throughput and reduce the consequent cost for I/O, network, and computational resources. In index server, there are intersection cache and list cache. The intersection cache keeps the intersection of posting lists associated with pairs of terms frequently occurring in queries. The list cache stores the frequently accessed inverted lists to economize I/O cost. To avoid accessing the disk frequently, document cache keeps the frequency documents in memory.
In literature, the result cache is optimized from the aspects of caching policies and architecture.
2 Result cache optimization
In order to improve the result cache performance, this section presents a scoring method of query heat words by analyzing query logs and retrofits the structure of the result cache. Query terms are extracted by removing stop words.
2.1 query log analysis and caching policies
Defination 1: query length (Lq): the number of terms in query q.
Defination 2: query repeated distance sequence (Dq): denote the users request sequence by queryList={q1,q2,…,qm}, where qidenotes the i th request. In the local time T, it means that d is d=|i-j|. d is the query repeated distance when qi=qjat |i-j|<ε, ε is a small number[7,18]. This characteristic is known as query request locality. Consider that time period T is divided into n equal time intervals and the average distance set of qiis Dqi={d1, d2, …, dn-1}.
For the sake of describing users’ queries behavior, search engine query log is analyzed[19]to predict users’ request behavior. 2.2 million web pages are crawled from Taobao (www.taobao.com), a famous commercial search engine of China. 1068674 queries are submitted to the search engine. Table 1 shows the main characteristics of query logs. The distinct query accounts for 16.5% of the total number of queries in logs. By extracting the feature terms of queries, it can be seen that the number of Lq=1 terms accounts for half the overall, the ratio of Lq<6 queries is 95.93%, and the ratio of Lq>=6 terms accounts for 4.07%.
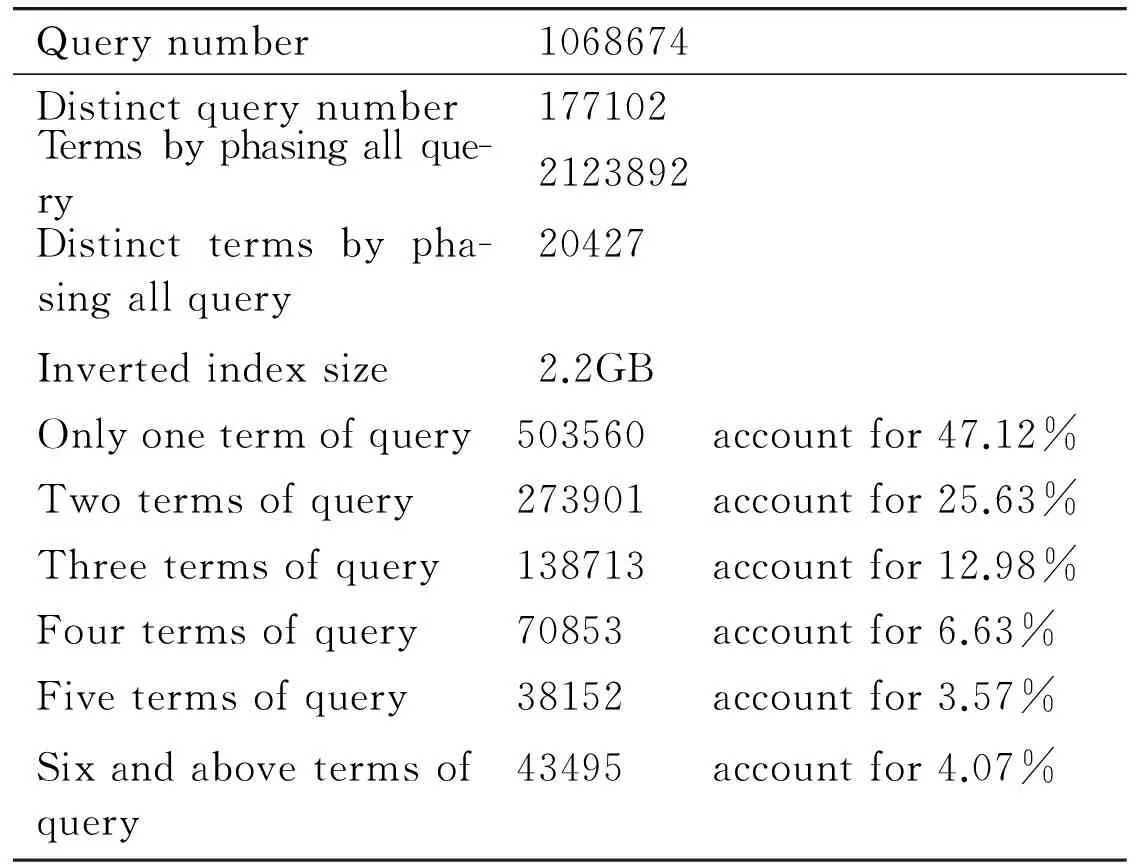
Table 1 Query log data statist
The request time of long query needs to search and merge many post lists. Therefore, in precondition of the same frequency, it is necessary to discount the score weight on the basis of the query length factor. By enlightening Lqfactor, an important query length factor (QLF) which trends to higher Lqis proposed. Assuming that Prob(Lq) denotes the ratio of the length value Lqto all queries, e.g. Prob(Lq=1) equals 47.12% in Table 1. The discount factor is defined as
QLF(q)=1-α×Prob(Lq) (α<1)
(1)
where α is an important factor of Prob(Lq) and the value of α is always set as 0.1 in this article. In practical work, Prob(Lq) is considered as 0 when Lq>6, namely QLF(q) is 1.
Since queries are repeatedly submitted within small time interval, distance sequence factor (Dq) between the same queries is also analyzed by the query log. In Fig.2, it plots the cumulative number of resubmissions of identical queries as a function of the distance between them. In particular, the cumulative number of repeated queries are occurred at a distance less than or equal to d. More than 60% distances cases are less than 500 between successive submissions of the same query.
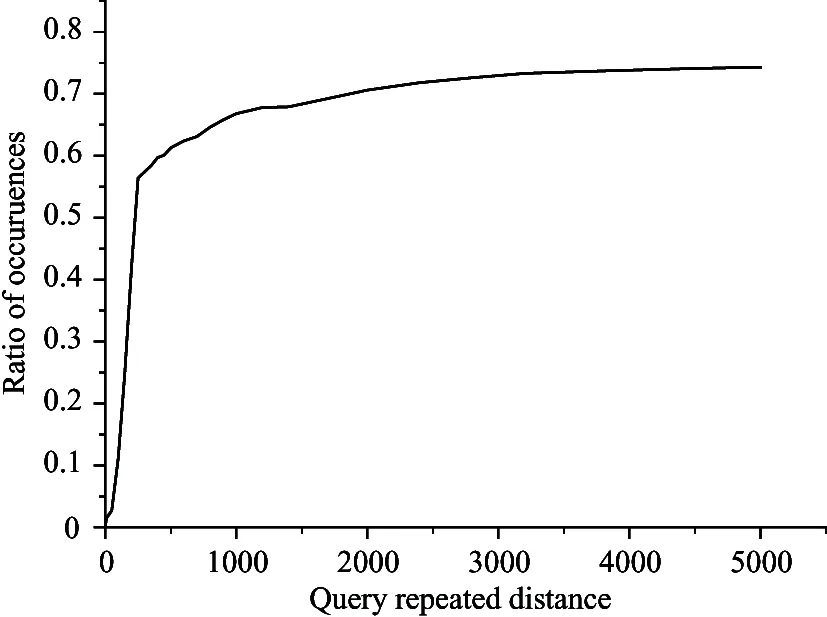
Fig.2 Distance between subsequent submissions with the same query
Based on the excellent cost-aware strategies[10,11],heat-query strategies are proposed which is related to query cost, frequency and worth by the query log.
For static caching, a query repeated distance sequence Dq, result size sqand query cost Cqfactors are introduced. Assuming that fqis a total frequency of q in time period T. The repeated distance sequence is Dq= {d1, d2,…, dn-1}, and the average distance is dμ=∑di/(n-1). Then the static caching strategy is defined, called Heat_Cost (abbr. Heat_C), as follows:
(2)
score(q) is used to compute the static caching score of q. The formula is not only as an initialization strategy of the static and dynamic caching, but also as a periodically update method of the static caching.
For dynamic caching, a caching worth idea is introduced. For query q, the hit time hitqis initialized to zero at the beginning. tstardenotes the building time and tcurdenotes the current time. The caching worth is computed in
(3)Value(q) denotes query caching worth of q. In Eq.(4), a result size sq, a query cost Cqand a query length factor QLF are considered, called Value _Cost (abbr. Value _C), as follows:
(4)
The formula can calculate dynamic cache objects score and update its contents with the query stream.
2.2 A new hybrid structure for result cache
A typical result page contains top-k contents which include titles, URLs and snippets[20,21]. A result cache entry typically stores the result page which can be responded to users without any further processing. The PageC structure is defined as
〈key,value〉=〈query,page〉 =〈(t1, t2,…,tq), (contentid1,contentid2,…,contentidtop-k)〉
(5)
where contentidis a record (including one title, one URL and one snippet) in page, idiis the i th record document identity.
Since the space cost for caching pages is quite high, an alternative is to store the docIds instead of pages (docIdC), as shown in
(6)
where idiis the i th document identity,
Using the docIdC method, a considerably large number of query results can fit into cache. However, the docIdC needs to search document servers when acquiring result page, re-computation will hence lead to larger latencies[22].
In order to improve performance of result cache, a new hybrid caching strategy is proposed by combining static and dynamic strategies, among which an available cache space is split into four parts: static-PageC(SPC), dynamic-PageC(DPC), static- docIdC(SdocIdC) and dynamic-docIdC(DdocIdC), respectively.
Fig.3 illustrates workflow of the modified result cache, according to this serial of priority: SPC, DPC, SdocIdC , DdocIdC. When query q hits SPC or DPC, cost Cqis set to be 0. When q hits SdocIdC or DdocIdC, cost Cqvalue equals Cpage. Otherwise, cost Cqequals the sum of Clist, Crankand Cpage. When DdocIdC misses, query q requests the index servers directly to obtain docIds. BS receives each index server docIds,
and then obtains global top-k ids by ranking and computing. The top-k docIds are used to get document contents from DS. Then associated pages are responded to the user, and the DPC is updated by the result pages.
In the hybrid caching, docIds associated with a query may continue to reside in SdocIdC or DdocId after the corresponding page is evicted from SPC or DPC. If the same query is issued again, it is answered using the result of SdocIdC or DdocId. Then it requests DS to obtain the page (its cost is only Cpage). This cost is relatively lower compared to the cost of re-computing the query results.
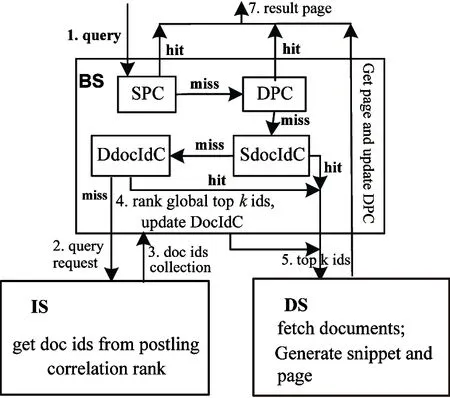
Fig.3 The workflow of the new hybrid result cache in WSE
2.3 Algorithms
In our hybrid result caching strategy, the cache space includes four parts. All parts use the static caching policy to initialize cache space on the query log. With regard to top-k records of result, it is assumed that the docIds size associated with query is a fixed value, namely sids, the result page size is a fixed value, that is spage(spage>> sids).
In initialization, it needs to calculate the number of records for page size spageand docIds size sidsof each cache. Then according to the sequence of workflow, each cache is filled with pages or docIds of heat queries, as the algorithm1.
During execution of the cache, according to workflow in Fig.3, the query routing algorithm is described as algorithm2. When query q is missed in SPC and DPC, it has the second chance to search docIds from SdocIdC and DdocIdC. In algorithm2, when DPC and DdocIdC are inserted into the cache object, Eq.(4) is used to compute current query score.

Algorithm 1: The initialization algorithm of the result caching

Algorithm 2: Query routing algorithm for the hybrid result cache
3 Experiments
A collection of 2.2 million webpages and 1.068 million queries are obtained from the taobao Web. The index file includes only docIds and term frequencies. Since there is no result to cache for such queries, queries which do not match any document are filtered. the performance of each type separately is first evaluated from the average query processing time and query per second. In five kinds of combination of PageC and docIdC, the performance of mixed cache is discussed in the new hybrid result caching.
3.1 Performance of single-level result cache
In Fig.4, it shows average query processing time for versus cache size (ranging from 0.25MB to 2MB). Heat_C and Value_C polices are utilized to improve the performance compared with cost-aware strategies (FC_K and GDS).
For PageC (in Fig.4(a)), when the cache space(less than 1.5M) is smaller, then the static method is higher than the dynamic policy; on the contrary, the dynamic method outperforms static caching. In Fig.4(b), the trends for docIdC are similar to PageC. It is remarkable that dynamic cache is better than the static one. In all cache size, the performances of improved policies (Heat_C and Value_C) are obviously better than FC_K and GDS, respectively. Comparing Fig.4(a) with Fig.4(b), the average processing time of docIdC can be reduced more than 15ms compared with PageC in small cache size(less than 1MB), including static and dynamic approaches. Conversely, when the cache size is more than 1.25MB, PageC has advantages over docIdC. In Table 2, three capability caches (0.5M, 1M and 2M) are selected to describe the efficiency of performance. When the cache is small, the average time of improved algorithms can reduce by between 4.9% and 6.6%. For the medium cache scenarios,the Heat_C of SdocIdC is strong superiority and the average time can be decreased by 12.2%. For the large cache, the improved algorithms are more efficient.

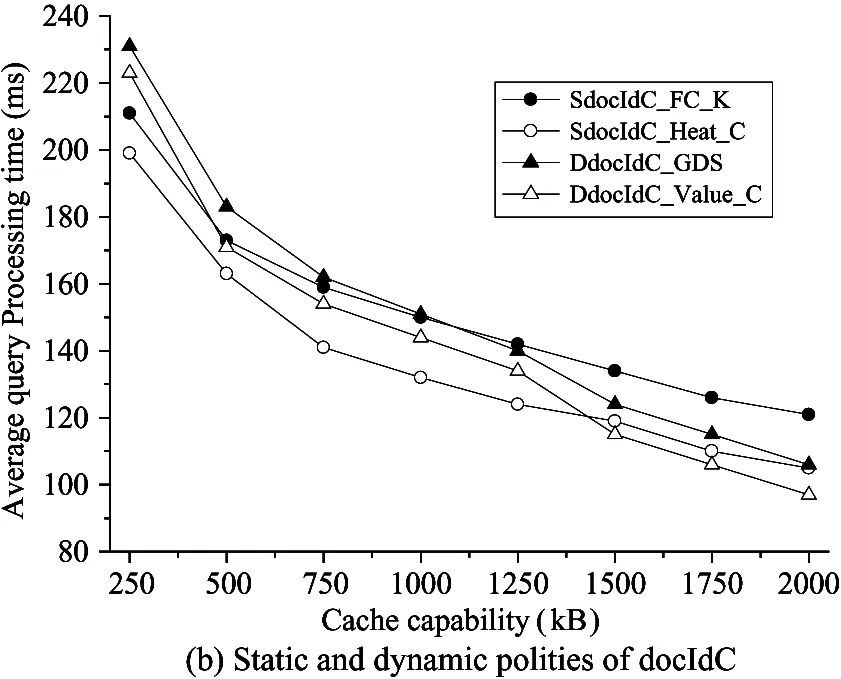
Fig.4 Average query processing time in single-level caching from basic and improved policies
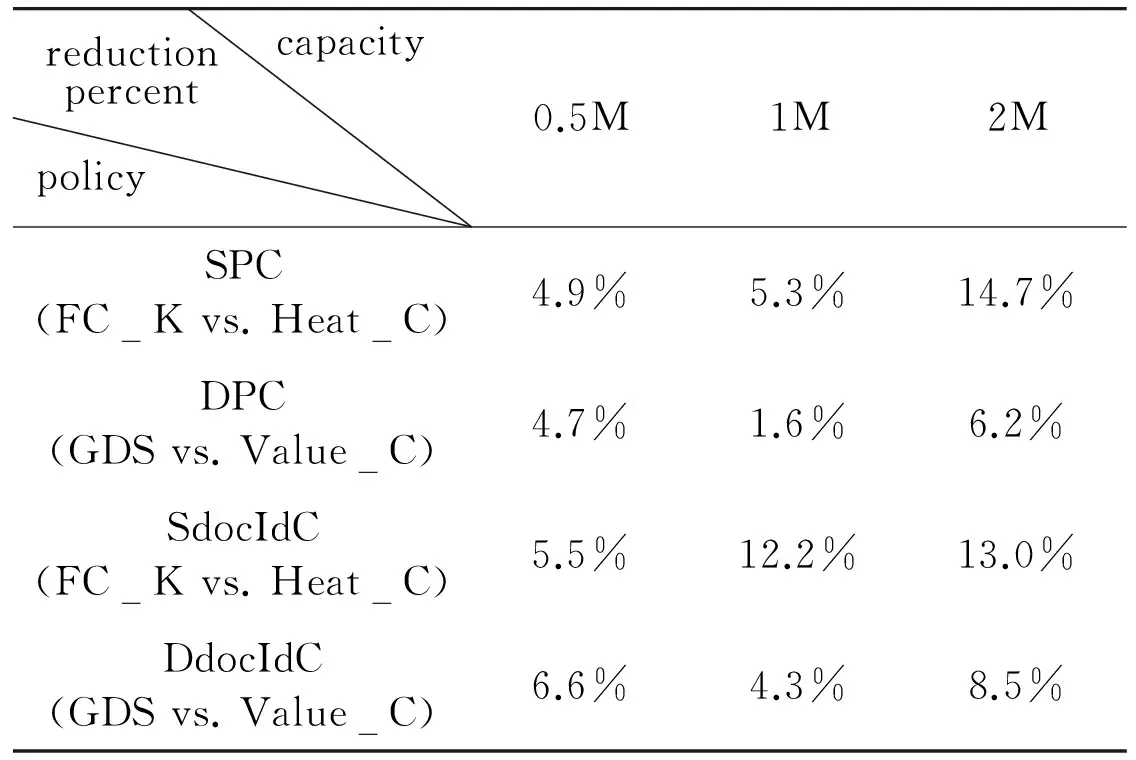
capacityreductionpercentpolicy0.5M1M2MSPC(FCKvs.HeatC)4.9%5.3%14.7%DPC(GDSvs.ValueC)4.7%1.6%6.2%SdocIdC(FCKvs.HeatC)5.5%12.2%13.0%DdocIdC(GDSvs.ValueC)6.6%4.3%8.5%
On the other hand, in Fig.5, the throughput of query per second (QPS) is obtained with different cache size and different caching approaches. The static correlation methods can outperform the dynamic correlation approaches for small cache size. For the large cache scenario, the dynamic polices have obvious advantage compared with the static strategies. From Fig.5(a) and Fig.5(b), it can be seen that the four strategies of PageC achieve obvious higher QPS than the docIdC methods with increasing cache size (more than 0.8MB). Table 3 describes the query throughput performance by comparing various policies in single-level result cache. For the small cache, the throughput of improved algorithms can be increased between 4.6% and 9.9%. For the medium cache, SdocIdC and DdocIdC are more obvious to increase by 11.7%. For the large cache, the improved algorithms are superior and increase between 15.1% and 16.0%.
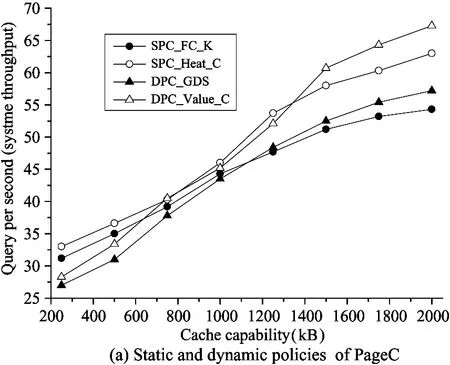

Fig.5 Query throughput in single-level caching
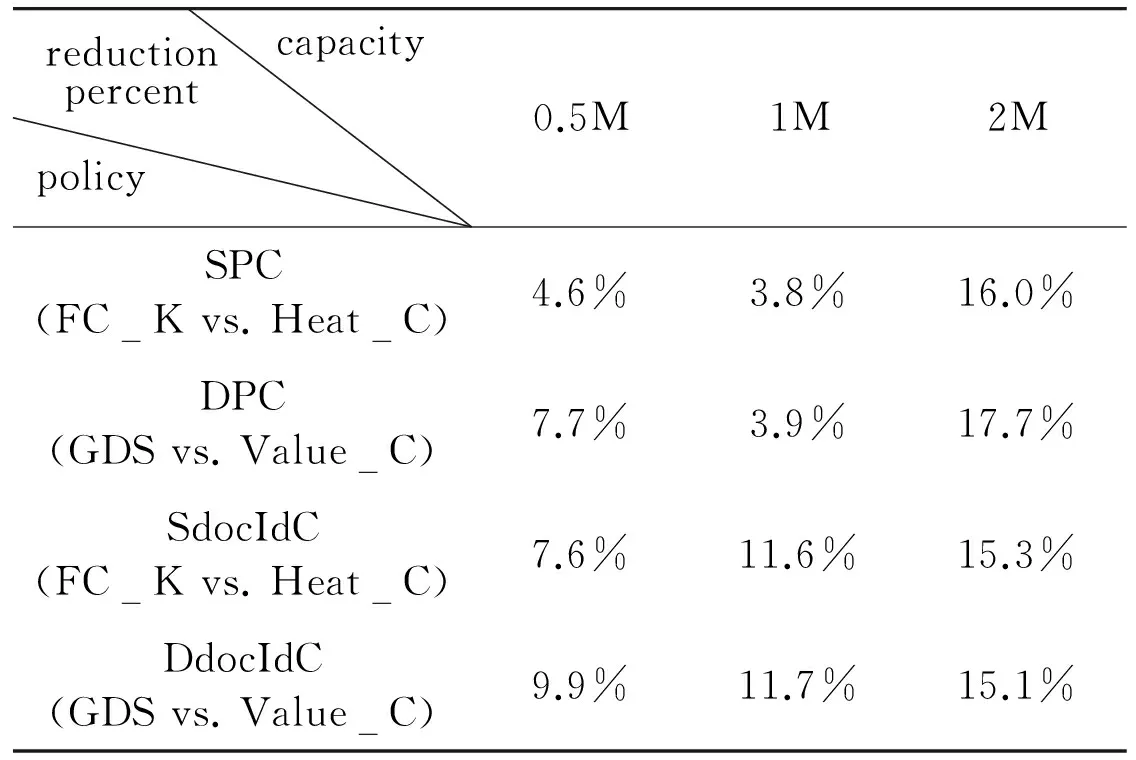
capacityreductionpercentpolicy0.5M1M2MSPC(FCKvs.HeatC)4.6%3.8%16.0%DPC(GDSvs.ValueC)7.7%3.9%17.7%SdocIdC(FCKvs.HeatC)7.6%11.6%15.3%DdocIdC(GDSvs.ValueC)9.9%11.7%15.1%
3.2 Performance of the new hybrid result cache
In this section, the hybrid caching strategy is experimentally evaluated. It has three different cache capacities which are representatives of small (0.5MB), medium (1MB) and large (2MB) caches. For different capacity, five combinations of the ration (denotes μ) of PageC space and docIdC space are chosen in sequence of 1/9, 3/7, 1/1, 7/3 and 9/1. Furthermore, for each combination, assumingis the ratio of static capability to the current PageC or docIdC part capability (is in [0, 1]).
Fig.6 shows the average query processing time of small, medium and large result cache. For the small and medium cache, the hybrid cache of (μ=3/7) achieves the lowest average query processing time regardless of thevalue. For the large one, when>0.7, the ratio of 9/1(μ=9/1) is slightly higher than 3/7(μ=3/7).
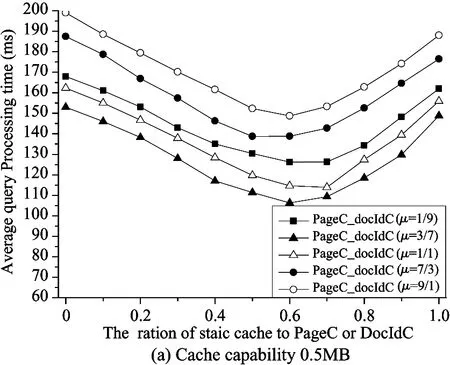
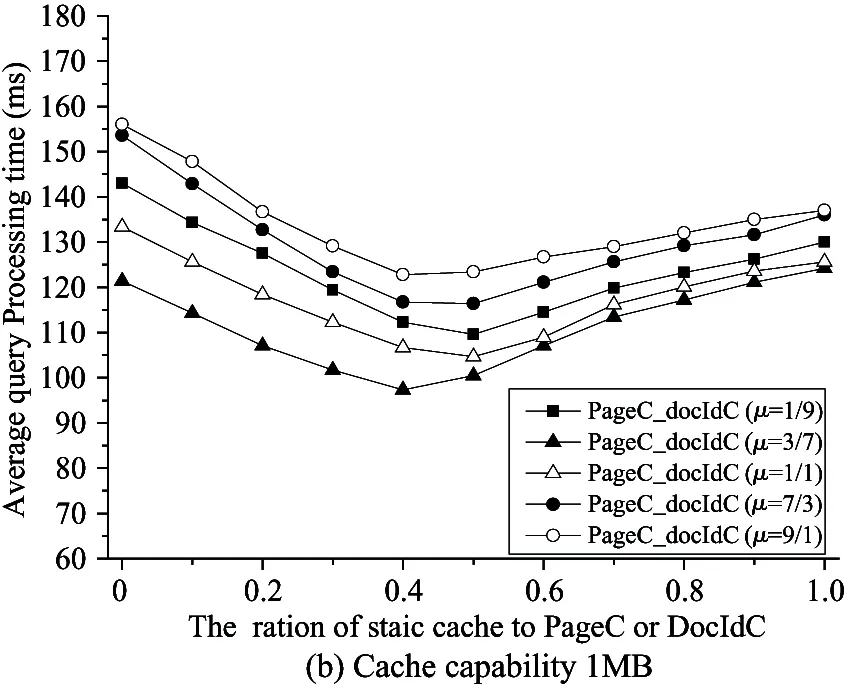

Fig.6 Average query processing time of hybrid result caching
For different capacity cache, the optimal value ofis different. In the small cache, the optimal interval value ofbetween 0.6 and 0.7 for various combinations. When the cache size increases,the optimum interval value ofbecomes smaller. The optimal interval valuesfor medium and large cache are respectively [0.4, 0.5] and [0.3, 0.4].
When μ equals to 3/7 (the best combination in Fig.6), it compares the average processing time for three kinds of capacity caches with the optimalvalue in Table 4. The hybrid cache can decrease by more than 20% average processing time.
Table 4 Reduction percent of avg. query processing time in the hybrid result caching at optimal
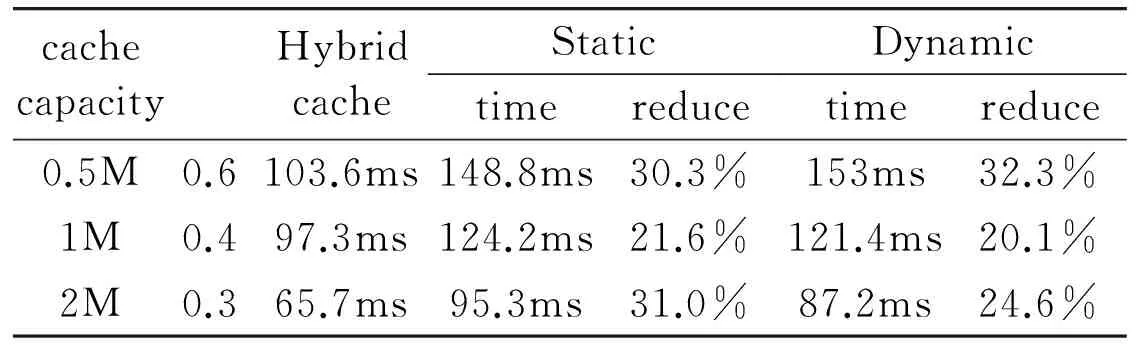
cachecapacityHybridcacheStatictimereduceDynamictimereduce0.5M0.6103.6ms148.8ms30.3%153ms32.3%1M0.497.3ms124.2ms21.6%121.4ms20.1%2M0.365.7ms95.3ms31.0%87.2ms24.6%
4 Conclusions
According to users query logs locality, two scoring strategies of heat query words and caching worth are proposed to improve cost-aware strategies for the result cache. In view of the result cache architecture, a new hybrid result cache is composed of four parts: SPC, DPC, DdocIdC and SdocIdC which are depended on result cache content and static/dynamic caching. The designed scoring approaches and the new hybrid structure of result cache considerably upgrades the performance of result cache.
There are several possible extensions to our work. Firstly, dynamicly adjusting space between PageC and docIdC should consider to maximize efficiency of the result cache. Secondly, it will plan to evaluate the improved policies in more complex architectures which may involve several other mechanisms, e.g. list cache, interaction cache and document cache. Finally, analyzing the characteristics of queries may also contribute to improve the caching performance.
[ 1] Gan Q, Suel T. Improved techniques for result caching in web search engines. In: Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 2009. 431-440
[ 2] Ozcan R, Altingovde I S, Ulusoy Ö. Static query result caching revisited. In: Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 2008. 1169-1170
[ 3] Baeza-Yates R, Jonassen S. Modeling static caching in web search engines. In: Proceedings of the 34th European Conference on IR Research on Advances in Information Retrieval, Barcelona, Spain, 2012. 436-446
[ 4] Cambazoglu B B, Junqueira F P, Plachouras V, et al. A refreshing perspective of search engine caching. In: Proceedings of the 19th International Conference on World Wide Web, Raleigh, USA, 2010. 181-190
[ 5] Bortnikov E, Lempel R, Vornovitsky K. Caching for realtime search. Advances in Information Retrieval, Springer Berlin Heidelberg, 2011: 104-116
[ 6] Baeza-Yates R, Gionis A, Junqueira F P, et al. Design trade-offs for search engine caching. ACM Transactions on the Web (TWEB), 2008, 2(4): 20
[ 7] Fagni T, Perego R, Silvestri F, et al. Boosting the performance of web search engines: Caching and prefetching query results by exploiting historical usage data. ACM Transactions on Information Systems (TOIS), 2006, 24(1): 51-78
[ 8] Blanco R, Bortnikov E, Junqueira F, et al. Caching search engine results over incremental indices. In: Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Raleigh, USA, 2010. 82-89
[ 9] Altingovde I S, Ozcan R, Ulusoy Ö. A cost-aware strategy for query result caching in web search engines. In: Proceedings of the 31th European Conference on IR Research on Advances in Information Retrieval, Toulouse, France, 2009. 447-490
[10] Alici S, Altingovde I S, Ozcan R, et al. Timestamp-based result cache invalidation for web search engines. In: Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 2011. 973-982
[11] Ozcan R, Altingovde I S, Ulusoy Ö. Cost-aware strategies for query result caching in web search engines. ACM Transactions on the Web (TWEB), 2011, 5(2): 9
[12] Ozcan R, Sengor Altingovde I, Barla Cambazoglu B, et al. A five-level static cache architecture for web search engines. Information Processing & Management, 2012, 48(5): 828-840
[13] Jonassen S, Cambazoglu B B, Silvestri F. Prefetching query results and its impact on search engines. In: Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval. Portland, USA, 2012. 631-640
[14] Marin M, Gil-Costa V, Gomez-Pantoja C. New caching techniques for web search engines. In: Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, Chicago, USA, 2010. 215-226
[15] Altingovde I S, Ozcan R, Cambazoglu B B, et al. Second chance: a hybrid approach for dynamic result caching in search engines. Lecture Notes in Computer Science, 2011, 8(1): 510-516
[16] Wang J, Lo E, Yiu M L, et al. The impact of solid state drive on search engine cache management. In: Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 2013. 693-702
[17] Croft W B, Metzler D, Strohman T. Search engines: Information Retrieval in Practice. Reading: Addison-Wesley, 2010. 12-17
[18] Dominguez-Sal D, Perez-Casany M, Larriba-Pey J L. Cooperative cache analysis for distributed search engines. International Journal of Information Technology, Communications and Convergence, 2010, 1(1): 41-65
[19] Ma H, Wang B. Search engine query Results caching based on log analysis. Journal of Computer Research and Development, 2012,49(Suppl.)
[20] Tsegay Y, Puglisi S J, Turpin A, et al. Document compaction for efficient query biased snippet generation. In: Proceedings of the 31th European Conference on IR Research on Advances in Information Retrieval, Toulouse, France, 2009. 509-520
[21] Ceccarelli D, Lucchese C, Orlando S, et al. Caching query-biased snippets for efficient retrieval. In: Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 2011. 93-104
[22] Ozcan R, Altingovde I S, Cambazoglu B B, et al. Second chance: a hybrid approach for dynamic result caching and prefetching in search engines. ACM Transactions on the Web (TWEB), 2013, 8(1): 3
Qian Libing, born in 1986. He is is Ph.D candidate in School of Computer Science and Technology, Harbin Institute of Technology. His research interests include the design of algorithms for information retrieval, high performance computing and parallel processing.
10.3772/j.issn.1006-6748.2015.03.015
①Supported by the National Natural Science Foundation of China (No. 61173024).
②To whom correspondence should be addressed. E-mail: qiannu159@163.com Received on Dec. 3, 2014, Ji Zhenzhou, Bai Jun
杂志排行

High Technology Letters的其它文章
- Improving the BER performance of turbo codes with short frame size based on union bound①
- Probabilistic data association algorithm based on ensemble Kalman filter with observation iterated update①
- A matting method based on color distance and differential distance①
- Probability density analysis of SINR in massive MIMO systems with matched filter beamformer①
- Edge detection of magnetic tile cracks based on wavelet①
- Diversity-multiplexing tradeoff of half-duplex multi-input multi-output two-way relay channel with decode-and-forward protocol①