临床数据中心数据处理过程的实现
2015-04-17左铭万歆刘迎崔洁朱立峰上海交通大学医学院附属瑞金医院计算机中心上海200025
左铭,万歆,刘迎,崔洁,朱立峰上海交通大学医学院附属瑞金医院计算机中心,上海 200025
临床数据中心数据处理过程的实现
左铭,万歆,刘迎,崔洁,朱立峰
上海交通大学医学院附属瑞金医院计算机中心,上海 200025
1 医院信息化建设的数据积累
中国医院信息化建设从20世纪90年代起步,从最初的收费模块、挂号模块和诊断模块,到后来完善的医院信息系统(HIS)、实验室信息系统(LIS)、医学影像存储与传输系统(PACS)、放射科信息管理系统(RIS)、电子病历(EMR)系统等,已积累和沉淀了大量的临床数据,同时也存在着大量的数据冗余,例如几乎每个系统都有一套病人基本信息,且存在着数据的不一致性。近年来,不少医院和厂商在不同系统之间进行了一定的数据同步,或采用了企业服务总线(Enterprise Service Bus)之类的数据共享平台或中间件来同步或共享数据,但是对于医生或行政管理人员来说,为了获取所需的完整数据,还是要在不同系统界面间切换,甚至需要分别登录这些系统,带来了巨大的工作量。
对于大型三级甲等综合性教学医院,一般拥有大量临床诊疗应用系统,总数据量多达约数10 TB(含影像数据文件)。如何充分合理利用这些多年积累起来的临床诊疗数据,是我们面临的一个难题。由于数据散落在不同的应用系统之中,数据存储结构差异较大,系统之间没有直接的交互,缺乏统一的标准,医生在进行诊疗和科研时,很难对这些数据进行方便、合理的收集和分析。所以,当前急需建立一个统一的临床数据中心来对临床诊疗决策和临床科研分析进行支持。
临床数据中心对数据收集和处理的手段之一是通过抽取、转换、加载(Extraction Transformation Load,ETL)过程实现数据的转移和转换。本文重点介绍我院在构建临床数据中心时,将数据从数据源装载到数据仓库的ETL过程的具体实现方法。
2 医院临床数据中心ETL的实现
2.1 数据流架构
一个数据仓库系统通常包含两种主要数据架构:数据流架构和系统架构。数据流架构是有关如何在数据仓库中组织数据存储以及数据如何从源系统经过数据存储,流向最终用户;系统架构是有关服务器、网络、软件、存储和客户端的系统配置[1]。数据流架构通常有多维数据存储(Dimensional Data Store,DDS),规范化数据存储(Normalized Data Store,NDS)+DDS,操作数据存储(Operational Data Store,ODS)+DDS三种形式。
大型医院目前拥有HIS、LIS、RIS、EMR等业务系统,数据库产品有MS SQL Server、 Sybase ASE和Oracle等,为了使数据ETL过程对实时业务系统的影响降到最低,一般采用NDS+DDS 的数据流架构,即从数据源装载到数据仓库,再到NDS的数据流架构,见图1。
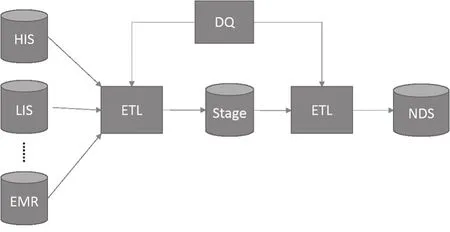
图1 数据流架构
其中,Stage为源系统数据的一个副本,从数据源装载到数据仓库的ETL过程并不对数据进行删减、修改或整合,仅负责抽取和装载,而从数据仓库到NDS的ETL过程,则需要按照数据仓库建模的需要对数据进行一定的清洗和转换。
2.2 数据库复制
当数据从源系统的数据库被读取并写入到Stage数据库中,不可避免的会对源系统产生一定的影响,尤其对于HIS、LIS这类特别繁忙的业务系统而言,为了避免对其进行直接对接和数据抽取,当下流行的方式有硬盘整盘拷贝技术以及数据库复制两种。但是为了捕获增量数据,一般选择数据库表中有时间戳(Timestamp)字段。对于原业务系统中无时间戳字段,可以利用数据库产品的事务复制功能,由系统自动跟踪 INSERT、UPDATE和 DELETE 等DML语句或其他数据修改,并将这些更改数据存储到分发数据库中,然后将更改数据传播到订阅服务器上,并按其发生次序加以执行,这样就不需要对生产数据库的表结构进行改动,而只需在订阅数据库的表上增加时间戳字段。数据库复制是一种技术,它将数据和数据库对象从一个数据库复制和分发到另一个数据库,然后在数据库间进行同步,以维持一致性。复制的拓扑结构包括发布服务器、分发服务器、订阅服务器及发布、项目和订阅等组件。
医院的临床业务系统属于业务繁忙、吞吐量大的OLTP(联机事务处理系统),通过设置分发服务器、订阅服务器以及相关组件,来建立系统的复制服务,并在订阅服务器的相关表中增加了时间戳字段用于识别增量数据,通过元数据管理服务对增量数据的抽取进行管理和控制,既不影响生产系统的正常运行,又能保证数据的完整性和一致性,同时能识别出增量数据,提高了数据抽取的效率和实时性。
2.3 增量数据的抽取
数据仓库在企业管理和决策中是面向主题的、集成的、与时间相关的、非易失的;其数据随时间变化,是支持各层管理的数据集合[2]。但是,近年来对于数据仓库中数据的时效性要求越来越高,如在临床科研随访中,对于每个参与临床随访患者的每次就诊数据都必须及时汇总到随访数据库中,以供科研分析支持。对新增数据识别,并及时地抽取到数据仓库中,这就是对增量数据抽取(CDC)。
增量数据的识别很大程度上依赖于时间戳。时间戳,通常是一个字符序列,唯一地标识某一刻的时间。通过记录每次抽取数据的最后时间戳(终点),来作为下一次抽取的起始时间戳(起点),就可以很容易收集两次抽取之间的变化数据。时间戳字段在数据库系统中通常由系统自动产生,这样就可以避免数据的遗漏。对于采用复制方式的源数据抽取,是在订阅数据库的相关表中增加时间戳字段,由于生成时间戳需要一定的系统开销,这样就可以避免生产库生成时间戳数据而对生产系统带来性能的损失。对于繁忙程度较低的系统,如病理系统、手麻系统等,我们直接在生产库的相关表中增加时间戳字段来捕获增量数据。
我们使用SQL Server 2005版本以上的系统,开启数据库提供的CDC服务来获取增量数据。SQL SERVER CDC Service通过对事务日志的异步读取,记录操作的发生时间、类型和实际影响的数据变化,然后将这些数据记录到启用CDC时自动创建的表中。通过CDC相关的存储过程,可以获取详细的数据变化情况。由于数据变化是异步读取的,对整体性能的影响不大,远小于通过Trigger实现的数据变化记录。此外,通过SQL Server集成服务(SQL Server Integration Services,SSIS)工具箱中的CDC控制任务和数据流任务中的CDC拆分器,可以很容易地识别出增量数据,且可以分别获得新增、更新和删除的数据集。
捕获增量数据的另一种手段是使用触发器技术,来记录变更的数据。但这种方式会对系统产生一定的性能损失,有时甚至会影响到业务系统的正常运行,因此不建议轻易使用该技术。如果采用复制技术,也可以在订阅服务器上使用触发器。显然在订阅服务器相关表上增加时间戳字段是保障系统性能更优的选择。
2.4 ETL工具
目前,主流的数据库供应商都提供了各自的ETL工具[3-4]。本文以微软SSIS(企业级的)工具为例来介绍ETL过程。该工具包括用于生成和调试包的图形工具和向导;用于执行工作流函数(如FTP操作)、执行SQL语句或发送电子邮件的任务;用于提取和加载数据的数据源和目标;用于清理、聚合、合并和复制数据的转换;用于管理集成服务,以及用于对集成服务对象模型编程的应用程序编程接口(API)。
在Microsoft的所有工具中,SSIS是最重要的商业智能工具,该工具具有清洗和将数据转换为合适的格式的功能,并可以快速地完成对数据的提取、转换和加载。同其他的ETL工具相比,SSIS是随SQL Server数据库产品一起提供的,有较好的经济适用性。
3 实践心得
在临床数据中心的ETL设计和实现过程中,我们通过不断地实践,反复地调试,使整个ETL过程达到了预期目标。同时也积累了一些经验和教训[5-8]:
(1)ETL过程应尽可能地配置大内存服务器,并给数据库服务配置较高的内存份额以提高数据读取和写入的性能。
(2)提高创建索引所使用的内存配额。由于Stage中的数据需要对增量读取,DW数据库的目标表写入时需要进行查找等操作来进行数据清洗,所以需要在相关字段创建索引,提高查找的效率。
(3)对于SQL Server数据库源,抽取数据的查询语句加上option,并指定参数为MAXDOP ?,问号处设置数字1~9,如option (MAXDOP 6)。该选项用于忽略由Sp_ configure 设定的针对查询的最大并行线程数目,以此来提高查询的并行度,以充分利用服务器的CPU资源。
(4)利用SSIS的CDC源抽取数据时,开启CDC服务的源数据库,必须设置CDC源的CommandTimeout,如300 s,而不要使用系统默认值。系统默认值为0,表示无限超时时间,但实践表明,若不进行设置,SSIS运行时会抛出命令执行超时的异常。
(5)设置数据流目标时使用快速加载选项,快速加载选项数据插入采用Bulk Insert,大大提升了插入速度,但由于不产生日志,所以目标表的触发器将不会执行。
(6)利用SQL Server的预估执行计划对数据抽取的SQL语句进行分析,对于查询优化器未使用到索引的大表的查询操作,在查询语句的表名后面加上with (index(索引名称))的选项,强制查询优化器使用索引来进行查询。
(7)将“执行卷维护任务”权限赋予给SQL Server的启动账户。这样在数据库文件增长时可以避免清零操作,最大限度地减少数据库文件增长造成的影响。
(8)将“锁定内存页”权限赋予给SQL Server的启动账户,避免SQL Server进程被操作系统页出(page out)。
[1] Vincent Rainardi. Building a Data Warehouse With Examples in SQL Server[M].Berkeley,CA:Apress,Inc,2008:29.
[2] W.H.Inmon.Building the Data Warehouse[M].Third Edition.New York:Wiley Computer Publishing,2002:31.
[3] 徐春艳.面向实时数据仓库的ETL研究[D].南京:南京航空航天大学,2007.
[4] 张旭峰,孙未未,汪卫,等.增量ETL过程自动化产生方法的研究[J].计算机研究与发展,2006,43(6):1097-1103.
[5] 安继业,薛万国,史洪飞,等.临床数据中心构建方法探讨[J].中国数字医学,2008,(10):13-16.
[6] 施今驰.数据挖掘技术在医院信息系统中的应用[J].中国医疗设备,2012,27(1):86-88.
[7] 俞磊,杨宋涛,王宗殿.基于数据仓库的医院决策系统的研究与设计[J].计算机与数字工程,2010,38(4):142-145.
[8] 林超英.数据挖掘在医院信息化建设中的应用研究[J].信息与电脑(理论版),2011,(2):127-128.
Implementation of Data ETL Processes in the Clinical Data Center
ZUO Ming, WAN Xin, LIU Ying, CUI Jie, ZHU Li-feng
Computer Center, Ruijin Hospital Affiliated to the Shanghai Jiao Tong University School of Medicine, Shanghai 200025, China
构建临床数据中心是进行临床诊疗决策和临床科研分析的重要手段。本文重点介绍了我院在构建临床数据中心过程中,将各信息系统的数据从数据源装载到数据仓库的抽取、转换、加载的具体实现方法,同时也总结了经验、教训,供同行参考。
医院信息系统;临床数据中心;ETL;数据库复制
Construction of the clinical data center is an important approach for decision-making of clinical diagnosis and treatment as well as analysis of clinical and scientific researches. Ruijin Hospital Affiliated to the Shanghai Jiao Tong University School of Medicine is exemplified in this paper for its successful implementation of data ETL (Extraction-Transformation-Load) processes in loading the data of multiple information systems from the data source to the data warehouse during construction of the clinical data center in the hospital. Experiences and lessons are also summarized in this paper to provide references for hospital in China.
hospital information system; clinical data center; extraction-transformation-load; database replication
TP392
A
10.3969/j.issn.1674-1633.2015.04.023
1674-1633(2015)04-0078-03
2014-10-10
2015-02-09
上海市科学技术委员会成果转化与应用课题(1251150 2406)。
朱立峰,高级工程师。
通讯作者邮箱:zlf@rjh.com.cn
