一种基于二叉树的数学公式抄袭检测算法
2015-04-14秦玉平唐亚伟伦淑娴王秀坤
秦玉平 ,唐亚伟 ,伦淑娴 ,王秀坤
1.渤海大学 工学院,辽宁 锦州 121000
2.渤海大学 信息科学与技术学院,辽宁 锦州 121000
3.渤海大学 新能源学院,辽宁 锦州 121000
4.大连理工大学 计算机科学与技术学院,辽宁 大连 116024
1 引言
为保护知识产权,防止学术论文抄袭,论文查重检测技术已成为信息检索领域的一个研究热点[1-2],并取得了一些研究成果。如数字指纹法[3-4]、词频统计法[5-6],篇章结构相似度法[7]、段落相似度法[8]、句子相似度法[9]和局部词频指纹法[10]等。但这些方法都针对纯文本内容的检测,对数学公式的抄袭检测尚处于探索阶段[11-13],现有的抄袭检测系统都不能对数学公式进行检测。但一篇学术论文,尤其是自然科学学术论文,其思想、观点或创意等核心内容往往体现在公式中,因此,对数学公式的抄袭检测的研究具有十分重要的意义。
LaTeX软件已被广泛地用于制作科技论文、书籍、档案、学位论文、手稿、私人信件以及各种复杂的符号公式等。另外,其他格式的文档可转化为LaTeX格式[14]。为此,本文提出了一种基于二叉树结构的LaTeX格式数学公式检测算法,实现了对数学公式的抄袭检测,并通过实验结果验证了算法的有效性。
2 数学公式的二叉树表示
2.1 二叉树构造
在LaTeX文档中,根据标记提取用字符串形式表示的数学公式。由于LaTeX格式的数学公式具有较强的结构特征,因此,可将一个复杂的数学公式分解为多个子式,再将每个子式分解成多个更小的子式[15],如此反复,直到不能分解为止。分解后得到的最小子式称为公式元素。
对于三目运算符,如求和运算“∑”,它与上、下、右都有联系,通过增加一个“link”运算符,将其与右面的子式结合起来。
从左向右遍历增加了“link”运算符后的字符串,生成公式元素的优先级列表。依据结构特征和优先级列表可生成数学公式的二叉树表示。二叉树中结点的数据结构如表1所示。

表1 二叉树结点的数据结构
由数学公式的公式元素串表示生成其二叉树表示的方法是先建立根结点,根结点的公式元素是公式元素串中优先级最低的公式元素,由于公式元素串中位于根结点公式元素之前的公式元素在根结点的左子树,位于根结点公式元素之后的公式元素在根结点的右子树,递归建立根结点的左右子树。
每个结点的公式元素类别和结合方式根据公式元素确定。每个结点的高度根据公式(1)计算。每个结点的结构码在对树形结构作归一化处理后生成。

其中,H(node)是结点node的高度,Hl是结点node左子树的高度,Hr是结点node右子树的高度。
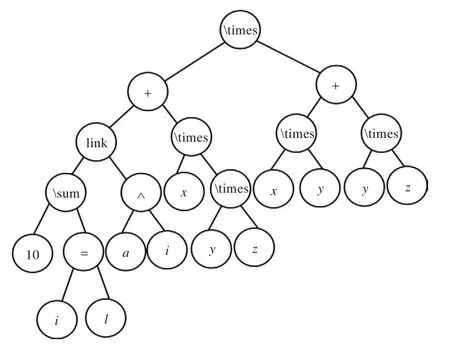
图1 数学公式的二叉树表示
2.2 归一化处理
由于一些运算符的操作数具有可交换属性,即交换前后数学公式的含义不变,但它们对应的二叉树树形结构可能不同,因此,必须对二叉树树形结构作归一化处理。树形结构归一化处理的方法是先序遍历二叉树,若当前结点公式元素类别为OPS且其左子树的高度大于右子树的高度,则交换其左右子树。例如,对图1作归一化处理后的二叉树如图2所示。

图2 树形结构归一化后的二叉树
对树形结构作归一化后处理后,后序遍历二叉树,根据式(2)生成各结点的结构码,最终得到根结点的结构码,即二叉树的结构码。

其中,C(node)是结点node的结构码,Cl是结点node左子树根结点的结构码,Cr是结点node右子树根结点的结构码。
另外,数学公式中的变量名与公式含义无关。对于一个树形结构确定的二叉树,为使按给定的遍历方式遍历后得到的公式元素序列唯一,必须对序列中的变量名作归一化处理。对变量名作归一化处理的方法是按从左到右的顺序,用固定的变量名序列依次替换遍历序列中公式元素类别为VAR的公式元素。
3 公式检测数据库设计
公式检测数据库包含论文信息表和数学公式信息表两种表。论文信息表的结构见表2,数学公式信息表结构见表3。数学公式信息表以结构码命名,即结构码相同的数学公式信息存储在同一个表中。

表2 论文信息表结构

表3 数学公式信息表结构
4 数学公式检测算法
步骤1对于待检测文档,提取所有数学公式,得到数学公式集Formula={f1,f2,…,fn}。
步骤2若数学公式集Formula非空,则从Formula中取出一个数学公式fi,生成fi的二叉树表示并对二叉树结构作归一化处理,得到fi的二叉树表示Ti及其结构码fcode,转步骤3;否则,转步骤7。
步骤3查找文件名为fcode的数据表,若该文件存在,转步骤4;否则,转步骤2。
步骤4在数据表fcode中,查找与二叉树Ti根结点的公式元素相等的记录,若存在,转步骤5;否则,转步骤2。
步骤5对二叉树Ti中的公式元素类别为OPS且左、右子树高度相同的结点(设有k个),交换这类结点的左右子树,得到2k-1棵树形结构与Ti相同的二叉树,分别先序遍历这2k棵二叉树,得到相应二叉树的公式元素遍历序列,对序列中的变量名作归一化处理,公式元素序列相同的只保留一个,得到公式元素序列集L={L1,L2,…,Lm},转步骤6。
步骤6在数据表fcode中,查找与L中的公式元素序列相同的记录,若存在,输出数学公式fi所在的论文名和发表信息,转步骤2。
步骤7检测结束。
5 实验结果及分析
为了验证算法的性能,从258篇公开发表的学术论文中选取1 000个含义和结构互不相同的数学公式,预处理后存入公式检测数据库。
实验环境为CPU Pentium 2.0 GHz,内存2 GB,操作系统Windows XP SP3,数据库ACCESS 2007。
实验中采用准确率P、召回率R和F1值作为评价标准。

其中,A是检测结果中语义相同且实际相同的表达式数,B是检测结果中未出现但实际语义相同的表达式数,C是检测结果中语义相同但实际不相同的表达式数。
数学公式抄袭的手段主要有原样复制,修改变量名称和交换可交换运算符两边子式的位置等。根据抄袭手段的不同,对公式检测数据库中的公式人工修改后进行检测,具体的修改方式如表4所示。

表4 修改方式的种类
实验中,根据数学公式抄袭的手段,对选取的258篇论文中的数学公式按表4中的修改方式作相应的修改后,分别对这些论文进行检测。共进行2 000次数学公式检测,检测的准确率和召回率都为100%,检测检测时间为421 ms。
从实验结果可以看出,该算法对公式未作修改,修改其变量名称及交换其可交换运算符两边子表达式的情况都实现了精准检测。其原因是对源公式和目标公式的树形结构作归一化处理后,源公式和目标公式的树形结构相同,虽然与源公式树形结构形同的目标公式二叉树可能有多种,但在对所有的先序遍历序列的变量名称作归一化处理后,目标公式的遍历序列中至少存在一个与源公式遍历序列完全相同的遍历序列,使修改后的目标公式恢复原形。该算法检测速度比较快。数学公式的检测过程包括数学公式提取、转换和查找。由于LaTeX格式文档中的数学公式有开始和结束标记,所以根据标记能快速识别并提取数学公式。由LaTeX格式表示的数学公式转换成其对应二叉树表示时,其主要操作是遍历公式元素串。遍历串长为n的公式元素串的时间复杂度为nlbn。由于公式元素串的串长较小且操作简单,所以用时较少。查找时,先检查与结构码同名的数据表是否存在,若不存在,检测结束,否则,先在数据表中查找与根结点公式元素相等的记录,若有满足条件的记录,再在满足条件的记录中查找与变量名归一化后的先序遍历公式元素序列相等的记录。
6 结束语
基于数学公式的二叉树表示,提出了一种LaTeX格式的数学公式检测算法。本文方法对未作修改的公式检测,对修改变量名称的公式检测和对交换可交换运算符两边子表达式的公式的检测都十分精确,且具有较高的检测速度,有效地解决了论文抄袭检测中数学公式检测问题,弥补了现有的检测系统中不能对数学公式进行检测的缺陷。
[1]史彦军,滕弘飞,金博,等.抄袭论文识别研究与进展[J].大连理工大学学报,2005,45(1):50-57.
[2]Song Q B,Shen J Y.On illegal Coping and Distrib uting Detection Mechanism for Digital Goods[J].Journal of Computer Research and Development,2001,38(1):121-125.
[3]Hoad T,Zobel J.Methods for identifying versioned and plagiarism documents[J].Journal of the American Society for Information Science and Technology,2002,54(3):203-215.
[4]Chowdhury A,Frieder O.Collection Statistics for Fast Duplicate Document Detection[J].ACM Transactions on Information System,2002,20(2):171-191.
[5]Zobel J,Moffat A.Exploring the similarity space[J].ACM SIGIR Forum,1998,32(1):18-34.
[6]Antonio S,Leong H V.A document plagiarism detection system[C]//Proceedingsofthe1997 ACM Symposium for Applied Computing.San Jose:ACM Press,1997:70-77.
[7]金博,史彦军.基于篇章结构相似度的复制检测算法[J].大连理工大学学报,2007,47(1):125-130.
[8]赵俊杰,胡学钢.一种基于段落词频统计的论文抄袭判定算法[J],计算机技术与发展,2009,19(4):231-233.
[9]秦新国.基于句子相似度的文档复制检测算法研究[J].现代图书情报技术,2007(11):63-66.
[10]秦玉平,冷强奎,王秀坤,等.基于局部词频指纹的论文抄袭检测算法[J].计算机工程,2011,37(6):193-194.
[11]Lee H,Wang J.Design of a mathematical expression recognition system[J].Pattern Recogniton Letters,1997,18(8):289-298.
[12]陈国俊,唐勇智.基于基准线的多候选数学公式识别[J].计算机工程与应用,2013,49(1):206-209.
[13]陈康,许婷.基于Web的全文搜索引擎的设计与实现[J].计算机工程,2005,31(10):51-53.
[14]靳简明,江红英,王庆人.数学公式识别系统:MatheReader[J].计算机学报,2006,29(11):2018-2026.
[15]郭育生,黄磊,刘昌平.基于多候选的数学公式识别系统[J].计算机研究与发展,2007,44(7):1144-1150.
