一种基于邮件用户行为分析的发件人信誉值生成方法
2015-04-13魏丽丽何庆戚国飞许敬伟
魏丽丽,何庆,戚国飞,许敬伟
(1.中国移动通信集团广东有限公司,广东 广州 510640;2.深圳市彩讯科技有限公司,广东 深圳 518000)
1 引言
随着互联网技术的迅猛发展,电子邮件以其低成本、便捷、可查阅等特点有效解决了远距离沟通的难题,是人与人之间日常沟通必不可少的重要工具。但是日益泛滥的垃圾邮件严重影响了人们的日常生活,如何高效地过滤垃圾邮件成为热点议题。
调查显示:2015年第一季度中国电子邮箱用户平均每周收到14.6封垃圾邮件,占所有邮件的37.37%。其中,93%的被调查者都对他们接收到的大量垃圾邮件表示非常不满。一方面,垃圾邮件消耗网络资源、占用网络带宽、浪费用户的宝贵时间、增加用户的上网成本,影响企事业单位的日常办公和沟通效率;另一方面,垃圾邮件成了计算机病毒传播的途径,垃圾邮件的传播将严重威胁网络安全,已成为网络公害。
针对反垃圾邮件的方法,有研究者提出基于用户反馈的个性化垃圾邮件过滤方法[1]:首先,根据用户反馈提炼邮件分类特征,由此制定个性化邮件分类标准;其次,综合全局邮件分类标准和个性化分类标准,利用朴素贝叶斯分类过程,完成用户邮件的个性化分类。但是筛选参数会影响选取的邮件特征词,当筛选参数取值较小或较大时,此方法在精确度方面的表现并不理想。还有学者提出了基于行为特征加权的决策树过滤算法[2],这种方法将垃圾邮件的判断转化为邮件的路径权值与垃圾邮件阈值的大小关系的判定。这种优化的算法在一定程度上可以提高筛选的精准性,但筛选结果的准确性受行为特征库影响较大。
现有的这些技术都或多或少的存在缺点,无法进行百分之百的准确判断。其中,也有学者提出一种基于用户群组将信誉值高的用户反馈的规则同步到信誉值低的用户的方法,但是这种做法会使用户的规则受到影响,无法反映用户真实的情况,也无法对用户的信誉值做实时的调整。垃圾邮件拦截准确率的提高迫切需要一种新的拦截技术。
基于此,本文提出基于邮件用户行为分析的发件人信誉值生成方法,通过机器学习的方法,对线上产生的海量日志进行分析,选取多个特征维度,通过海量日志对特征模型进行训练,对这些特征值生成了一个总体的信誉分值库,实时的邮件匹配这个特征信誉库,对满足条件的发件人生成发件人特定的信誉值,提高信誉值的准确度。
2 反垃圾邮件过滤技术
对于垃圾邮件,主流的过滤技术有黑白名单、关键词过滤、基于规则的过滤技术、Hash技术、贝叶斯过滤技术等。
黑名单(Black List)和白名单(White List)技术首先检查邮件头,如果白名单有发件人就接收该邮件[3],否则拒绝接收该邮件。这种方法可以百分之百屏蔽已确认的垃圾邮件制造者所生产的垃圾邮件,但是由于有些用户是首次联系收件人,尚未收录在收件人的白名单内,所以黑名单与白名单技术会过滤掉此类正常通信邮件。此外,因为发送垃圾邮件时可以采用自动邮件伪造邮件发送者或域名,所以这种技术在垃圾邮件防范领域尚有改进空间。
由于某些垃圾邮件会以较高的频率使用“赠送”、“礼包”等关键词,如果标识一些垃圾邮件常用的单词,并以此识别和处理垃圾邮件,那么就能有效拦截垃圾邮件,这就是关键词过滤技术。基于这种识别原理,关键词过滤技术极有可能导致误判,比如设置单词“test”为过滤关键字,那么所有含有“test”的邮件都将难逃滤网。
Hash技术是一种近似文本检测技术,可以描述邮件的内容[4],计算Hash时通常以邮件的题目、发件人等元素作为参数。Hash技术正是利用了垃圾邮件网络传播的高密度性和内容高度相似性等特点,通过检测所收邮件与已知类别邮件的相似性来区分邮件类别,是检测垃圾邮件的有效技术手段。
除此之外,邮件系统还可以根据单词、大小、位置、附件等特征元素制定规则[5],并以此描述和判别垃圾邮件。但该技术的缺点是如果要使过滤器有效,管理人员需要维护一个庞大的规则库。
相比上述几种过滤技术来说,贝叶斯算法更加智能化[6],是最为精确的拦截垃圾邮件的技术之一。它通过持续地学习跟进垃圾邮件的新规则,可使过滤准确率达到99%[7]。但美中不足的是,过滤的准确性依赖大量的历史数据。
贝叶斯过滤器很难被绕过[8]。为了绕过邮件内容检查,通常垃圾邮件发送者会减少信中的垃圾词汇(如免费、礼包)或者在信中掺杂少许正式的词汇(如会议、文件)。但由于贝叶斯具有强烈的个性化色彩,只有研究单个收件人的偏好才有机会绕过贝叶斯检查,而这几乎是不可能完成的任务。
3 基于用户行为分析生成发件人信誉值 解决方案
3.1 方案说明
本文提出一种基于用户行为分析生成发件人信誉值的方法,用来更好地过滤垃圾邮件。这种方法优化实现了对垃圾邮件的过滤,技术方案描述如下:
(1)初始阶段:主要包括运行前准备和特征值录入数据库两部分。
(2)发件人信誉值生成阶段:主要根据用户的历史行为生成相应的信誉值。
(3)发件人信誉值入库阶段:根据发件人特征值的匹配结果进行后续操作。
3.2 方案具体实施方式
基于用户行为分析生成发件人信誉值的流程图如图1所示:
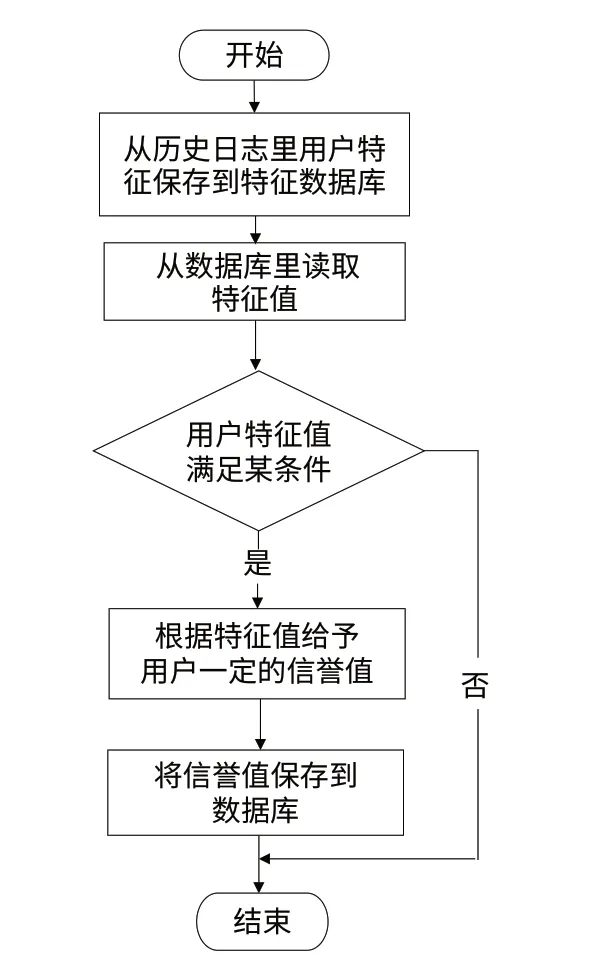
图1 基于用户行为分析生成发件人信誉值的流程图
具体步骤如下:
(1)初始阶段。初始化系统,加载配置文件,从日志信息中提取发信人特征值,连接特征数据库等。
1)运行前准备,加载海量日志文件进行分析,从日志信息中提取邮件体大小、发信成功数、发信失败数、发信总数、收件人回复数、邮件内容、发件人域名、IP发信成功数和失败数等信息;
2)将日志提取的特征值保存到特征数据库。
(2)发件人信誉值生成阶段。本阶段主要是通过对用户历史发信数、发信成功率、当天发信数、收件人是否回复以及邮件内容进行分析生成相应的信誉值,主要步骤如下:
1)从数据库中提取特征值后进行判断,如果发信人历史发信总数小于3封,则数据量太少,无法生成信誉值,直接结束流程;
2)当历史发信量超过3封,邮件发送成功率低于0.76时,设置信誉值为30分;
3)当发信成功率为100%,IP发信记录成功率为100%,且收件人有回复、邮件内容匹配可信关键词、邮件大小超过500KB或者有向可信域发信任何一个条件满足时,设置信誉值为40分;
4)当发信量超过5封,发信失败次数为0,收件人且总数超过3个,邮件含有可信关键词时,设置信誉值为80分;
5)当发信量超过5封,发信失败次数为0,如果当天发信量超过1封,且邮件匹配的可信关键词超过2个、有向可信域发信、收件人有回信或者发送大小超过500KB的邮件超过2封任何一个条件满足时,设置信誉值为80分;
6)当发信量超过5封,发信失败数大于0到2封,是可信域发信,且当天发信量大于1封时,设置信誉值为70分;
7)当发信量超过5封,发信失败数大于0到2封,有收件人回信,且当天发信量大于1封时,设置信誉值为70分;
8)当发信量超过5封,发信失败数大于0到2封,邮件内容含有可信的关键词,邮件内容匹配可信的关键词超过2个,且当天发信量大于1封时,设置信誉值为70分;
9)当发信量超过5封,发信失败数大于0到2封,邮件内容含有可信的关键词,发送的邮件大小超过500KB至少为1封时,设置信誉值为70分;
10)当发信量超过5封,发信失败数大于0到2封,邮件内容含有可信的关键词,收件人有相同的且总数超过3个时,设置信誉值为70分;
11)当发信量超过5封,发信失败数大于2到9封,发信失败数为3且当天发信量小于3封时,设置信誉值为30分;
12)当发信量超过5封,发信失败数大于2到9封,发信量大于20封,邮件内容匹配可信的关键词个数超过4个,收件人总数超过12个且同名的人数超过4个时,设置信誉值为70分;
13)当发信量超过5封,发信失败数大于2到9封,发信量大于20封,邮件内容匹配可信的关键词个数超过4个且当天发信量超过4封时,设置信誉值为70分;
14)当发信量小于5封,发信失败数大于0到2封,大小超过500KB的邮件至少为1封且邮件内容含有可信的关键词时,设置信誉值为70分。
(3)发件人信誉值入库阶段。具体步骤如下:
1)若发件人的特征值匹配了上述的某一规则,则将生成的信誉值保存到数据库中;
2)若发件人的特征值未匹配上述的任意一种规则,则将特征值保存到数据库,供下次再次分析。
数据挖掘[9]是从海量的数据中提取潜在的、有价值的信息。通过对用户长期的发信行为进行分析可知,用户历史发信行为对将来所发邮件的性质(是否为垃圾邮件)有一定的预见性[10],即如果发件人曾经有发送垃圾邮件的历史,以后再发一封邮件是垃圾邮件的概率很高。经智能算法对用户的发信行为进行分析可知,垃圾邮件具备以下特性:
(1)邮件大小不会太大,太大则会影响垃圾邮件的投递速度。
(2)发送的成功率不高,某些邮件被反垃圾系统拦截。
(3)发送量大,邮件一般通过群发工具发送。
(4)收件人不会回复。
(5)邮件内容多为广告、政治或色情言论。
(6)发信域名多为陌生域名。
3.3 本方法的过滤效果
本方法综合考虑了邮件体大小、发信成功数、发信失败数、发信总数、收件人回复数、邮件内容、发件人域名、IP发信成功数和失败数等信息,建立了较完备的特征数据库,可以有效提高匹配准确度;同时,将此次尚未定性的用户信息存入数据库,待达到标准后重新筛选,这种方式使得垃圾邮件的判断更加便捷、准确。
为评估文中提出的基于邮件用户行为分析的发件人信誉值生成方法在提升过滤准确率方面的效果,本文将对2015年3月至5月使用该方法的某邮箱的收件量、垃圾邮件所占比、低信誉发信人数及所中信誉占垃圾邮件比例等数据进行分析。具体数据如表1所示:

表1 某邮箱使用发件人信誉值生成方法前后的收件情况
由表1可知,3月该邮箱尚未使用文中所述的垃圾邮件过滤方法;4月时该方法正式投入使用,从3 206 741封垃圾邮件中累计识别低信誉发信人数为54 876人,该方法为垃圾邮件的判别作出1.473%的贡献;5月时,随着特征数据库的不断丰富,识别能力加强,在垃圾邮件数基本不变的情况下识别低信誉发信人数为126 753人,数量是4月的两倍,该方法对垃圾邮件的判别贡献也增至3.255%。可以看出,随着使用时间的增加,该方法对垃圾邮件过滤的贡献也会增加,这是因为海量邮件为数据库提供了大量的垃圾邮件特征,极大地丰富了特征库,有利于该方法对垃圾邮件的准确判断。
4 结束语
随着网络的日趋复杂,反垃圾邮件技术的重要性和迫切性日益凸显,垃圾邮件过滤技术作为处理垃圾邮件的主流技术之一,在处理垃圾邮件领域有着至关重要的作用。本文提出的解决方案主要是对海量日志进行用户行为分析,综合考虑垃圾邮件的主要特性如发件人发信总数、当天发信数量、发信成功率、邮件大小、邮件内容、可信域发信等信息生成发件人的信誉值。本方案避免了垃圾邮件的误判或因某单一特征造成的信誉值偏差,可以更高效地过滤垃圾邮件,是现有垃圾邮件处理技术的有益补充。
但是该方法在垃圾邮件处理的初期表现欠佳,因为收件数量有限导致特征值数据库有限,所以尚不能快速完成垃圾邮件的判断。下一步将在算法方面做更多的探索,旨在通过优化算法来提高过滤初期的精确度。
[1] 黄国伟,刘云霞,陈志. 基于用户反馈的个性化垃圾邮件过滤方法[J]. 电子设计工程, 2014,22(15): 53-56.
[2] 李璇. 基于行为识别的垃圾邮件过滤技术的研究与应用[D]. 武汉: 武汉理工大学, 2013.
[3] 詹川. 反垃圾邮件技术的研究[D]. 成都: 电子科技大学, 2005.
[4] 帖凯莹. 垃圾邮件判决器的研究与设计[D]. 成都: 四川大学, 2006.
[5] 刘英戈. 一种可信的反垃圾邮件网格体系研究与实现[D]. 无锡: 江南大学, 2007.
[6] 陈渝,黄楚亮,吴志豪,等. 企业信息化中的反垃圾邮件技术[J]. 广东科技, 2007(7): 63-64.
[7] 张启宇. 基于贝叶斯算法的垃圾邮件过滤系统的研究与设计[D]. 曲阜: 曲阜师范大学, 2006.
[8] 闫龙,王文杰. 基于贝叶斯方法的一种垃圾邮件过滤的实现[J]. 微电子学与计算机, 2006,23(2): 86-88.
[9] 柳景超,宋胜锋. 基于参考度的有效关联规则挖掘[J]. 火力与指挥控制, 2011(5): 79-81.
[10] 董建设. 协作式垃圾邮件过滤关键技术研究[D]. 兰州: 兰州理工大学, 2009.★
