基于视觉词袋模型的图像分类改进方法
2015-03-28曹宁冯阳
曹宁,冯阳
(河海大学计算机与信息学院,江苏南京210098)
分类和识别是图像理解中的关键问题,由于图像目标存在视角变化、亮度变化、尺度、目标变形、遮挡、复杂背景以及目标类内差别等影响,使得图像目标的分类识别非常困难。针对这些问题,已提出了各种具有不变性的局部特征提取的方法。在这些方法中,视觉词袋(BOVW,Bag-Of-Visual-Word)模型是最具代表性的一种。BOVW模型是由Bag of word(BOW)模型应用到计算机视觉领域演变而来的,BOW模型最初应用于文档分类领域并因其简单而有效的优点得到了广泛的应用,计算机视觉领域的研究者们尝试将同样的思想应用到图像处理和识别领域,从而建立了由文本处理技术向图像处理领域的过渡。然而,视觉词袋模型在计算机视觉领域的应用仍存在一定的问题,例如在应用于图像分类时分类精度不够高,为了进一步提高该模型的性能,使其在图像识别和分类领域得到更好的应用,研究者们一直致力于对模型的实现过程进行改进。
文中基于BOVW[1]模型来完成图像原始特征的提取、特征聚类并形成统一的特征词典来表达图像。基于BOVW模型,我们选用D.G.Lowe提出的SIFT经典描述子来提取描述图像特征,并利用改进的Kmeans+聚类算法把提取的特征聚类构建视觉词典,为了增强识别性能,引入了一种基于视觉词典的权重直方图表达来表示图像,文中仅仅应用简单的KNN分类器进行分类,并允许在训练图像数目较少的情况下即可达到良好的分类效果。
1 视觉词袋模型的基本原理
在应用BOVW模型来处理图像时,图像被看作是文档,而图像中的关键特征被看作“单词”,其应用于图像分类识别时,主要包括3个步骤:特征的提取和描述;视觉词典的构建;选取合适的分类器进行分类和识别。
1.1 图像特征提取和描述
文中选用D.G.Lowe提出的SIFT[2]经典算子来提取描述图像特征。SIFT描述子通过在尺度空间高斯差分图像去找相邻尺寸之间的局部极值点来确定图像中显著的位置和尺度,然后再找到这些显著点的位置,提取归一化的区域梯度直方图获取最终的SIFT局部描述子。SIFT描述子具有良好的判别性,对旋转、尺度和光照等具有不变性,因此在计算机视觉领域得到了广泛的应用。具体实现步骤为:首先将图像与高斯核函数进行卷积,得到高斯差分尺度空间,这一步为粗糙地探测兴趣点的位置,因此得到的兴趣点中含有大量的无用信息,下一步就要对这些关键点进行精确的定位,以得到其尺度、方向等信息,最后要给每一个兴趣点分配方向和尺度,每一个特征便具备了是个参数,中心点的水平坐标,中心点的垂直坐标、尺度以及方向,接着用SIFT描述子对特征进行描述,每个特征都将被表示成128维的特征向量,首先以关键点为圆心取16×16的领域窗口,然后将该窗口分成4×4个子区域,在每个子区域中计算8个方向(0°,45°,90,135°,180°,225°,270°,315°)的梯度累加值,这样每个特征便可以用4×4×8=128维的向量来表示。按照这种方法对特征进行描述可以避免尺度变换、旋转变化的影响。
1.2 构建视觉词典
这一步的任务就是将特征提取环节得到的向量表示形式表示的特征转换成图像的“单词”,然后利用这些单词来构建视觉词典。这样每一张图像都可以表示为视觉单词出现概率的集合,这样就可以利用视觉词典来表示图像。通常采用聚类的方法来构建视觉词典,聚类的目的在于将具有最大相似性的特征归为一类,聚类中心定义为“单词”。将所有单词进行组合就构成了视觉词典,通常词典大小由单词个数决定。K-means[3]聚类方法比较经典而且简单有效,基本的K-means的核心思想为:将向量空间中n个特征点按照类内方差和最小的原则分为指定的k类,如式(1)所示。

其中Ci表示中心为μi的第i个聚类类别,xj表示属于类别Ci的数据点。K-means聚类方法的具体步骤:1)随机选取k个初始中心;2)计算每个数据与聚类中心距离,将数据按最短距离分配到k个初始中心为代表的聚类类别中;3)根据上一步的结果对新形成的k个类别进行中心计算,重新得到新的聚类中心;4)重复2)、3)操作直到结果收敛为止。
1.3 分类器进行分类和识别
文中选用最简单有效的k最近邻(KNN,K-Nearest-Neighbors)分类算法。KNN算法的核心思想是如果一个样本在特征空间中的k个最近邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类时采用投票决策,即主要靠周围邻近的有限样本投票而不是靠判别类域的方法来确定所属类别。
2 改进型K-means算法
由于K-means算法初始中心选取的随机性,大大增加了迭代的计算花销。本文采用了它的改进算法K-means+[4],两者的不同之处在于初始中心的选取方式,K-means+算法选取初始中心是基于彼此之间距离大小选取K个可能性最大的特征点,也即是假如一个特征矢量与其他所有的特征矢量有最大的欧式距离,那么它被选举为一个初始中心的概率最大,这是因为类别差异越大,它们类别中的视觉单词的欧式距离也应该越大。基于这种思想,我们定义待聚类的特征矢量为:F={f1,f2,f3,…,fn},然后从中任选一个特征矢量,计算它与其余所有特征矢量的欧式距离得到n-1个距离,我们把它写为距离矢量形式为:D={d1,d2,…,dn-1},最后计算基于距离的概率大小为:p={p1,p2,…,pn-1}其中

因此,第1)步选取可能性最大的k个特征点作为初始中心点,其余步骤同k-means相同。使用k-means+算法可以加快中心点收敛的速度,以减轻对计算机硬件的压力。
3 加权统计直方图词典表达
利用BOVW模型完成特征提取描述和视觉特征词典的构建后,最重要的是要利用视觉词典完成图像的表示,对每图像的表达时,不同于传统的统计直方图表达,本文提出了一种加权的统计直方图表达[5],传统直方图统计表达时是统计图像特征到视觉单词的距离最短的特征单词,而加权统计直方图词典表达在图像表达时考虑了邻近特征的贡献[6],也即是说如果一个特征距离该视觉单词距离最短,那么该特征对该视觉单词统计值具有最大的影响,而非最短的其余特征也按距离的远近对该视觉单词的统计值分配不同的权重值。
这里我们假设训练图像集完整表示为ma={ma(i),Fa(i),Ra(i)|1≤i≤na},其中ma(i)表示第i张图片;Fa(i)={fa(i1),fa(i2),fa(i3),fa(in)}表示第i张图片的sift特征;Ra(i)是第i张图片的权重直方图表达。同理,我们用mb表示测试图像集mb={mb(i),Fb(i),Rb(i)|1≤i≤na}。假设V={v1,v2,…,vk}是k个视觉单词组成的词典。单词vj的权值为wj,对于任意一张特定的图片ma(i),它可以被表示为Ra(i)={w1,w2,…,wk}。Fa(i)到Vj的距离Dj可用下式(3)求解。
Dj=sort(dj1,dj2,dj3,…,djni),djn=pdist(vj,fa(in))1≤n≤ni(3)
其中sort函数是一个升序的排序函数;pdist函数是欧式距离计算函数。假设一张图片的特征最大不超过M个,因此通过Dj,可获得权值wj,即权值如下:
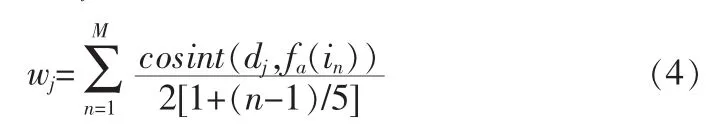
其中cosin函数是计算余弦距离函数。对每一个视觉单词计算Dj和Wj,这样训练集图片ma(i)都可以基于视觉单词分配的权值大小表达出来,mb(i)同理也能按其对应视觉单词分配的权值大小统计表达出来。
4 实验结果及分析
我们选用Caltech101,Caltech256这两组经典的数据集作为实验数据库。为了方便起见我们两组数据集都随机选取训练集和测试集,但选取不能雷同。实验部分将通过反复实验演示统计直方图词典表达(NWR)和加权统计直方图词典表达(WR)的对分类性能的表现。
4.1 实验一:Caltech 101数据库
Caltech 101[7]由加利福尼亚理工学院的李飞飞提出的,共包括101类常见对象类别,每一类包含31到800张图片,本文随机选取其中的8类,示例图像如图1所示。
图1 Caltech101数据库选取图像示例Fig.1 Example images of Caltech101 database
实验中,每类中随机选取20张图片作为训练集,选取其余40张作为测试集,然后提取图像特征,采用K-means+算法把训练集特征聚类得到视觉单词,视觉单词的数量按间隔50从100到300逐次递增,分别统计2种图像表达下图像识别平均准确率(AP,Average Precision),定义AP如下:

其中nc表示类别总数,ei表示第i类正确识别的概率。分别在2种词典表达下进行实验,随不同的词典长度变化识别的平均准确率,如下表1。
表1 实验在不同词典长度下AP值(Caltech101)Tab.1 The AP results of WR and NWR(Caltech-101)
为了描述每一类识别的正确率,我们定义词典长度固定为250时,每一类识别的正确率,如图2所示。
图2 采用WR和NWR表示图像时每类识别正确率Fig.2 The per class recognition correct rate of the WR and NWR represent
实验结果表明,采用权重直方图词典表达图像均比采用传统统计直方图平均识别率要高,尤其是当词典长度为300时,平均识别正确率比非加权的统计直方图表达高出4.58%。
4.2 实验二Caltech 256数据库
Caltech 256可以看作是Caltech 101的扩展,它包括256个常见对象类别。相比Caltech101数据库,Caltech 256的对象变化更加多样性,因此也就增加了分类的难度。我们从中随机选取6类(分别为:Baseball,Computer mouse,Eiffel,Fish,Skeleton,AK)中的20张图片作为训练集,40张作为测试集。进行两组实验并计算平均识别正确率,如表2和图3所示。
图3可以直观地看出相比传统统计直方图表达图像,引入权重统计直方图表达图像性能提升显著。尤其在词典长度为200时,分类性能提高了12.09%
5 结论
图像的表示和分类是图像处理中的关键技术[8],文中主要从图像的表达入手,将图像处理中常用的加权技术引入对图像基于视觉词典的直方图表示中,文中没有过多地涉及分类器部分,如果对分类器加以改进或者改用更加有效的新的分类器将是改进BOVW模型的另一个研究领域。为使视觉词典的构造方法更加稳定,特征聚类时采用改进的K-means算法,结合权重表达图像,利用最简单有效的KNN分类器就取得了优异的分类效果。

表2 实验在不同词典长度下AP值(Caltech256)Tab.2 The AP results of WR and NWR(Caltech256)

图3 权重直方图表达(WR)和非权重表达(NWR)下平均识别正确率Fig.3 The average correct recognition rate of expression of weight histogram expression and non-weighting
[1] Jégou H,Douze M,Schmid C.Improving bag-of-features for large scale image search[J].International Journal of Computer Vision,2010,87(3):316-336.
[2] Lowe D.G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[3] 严华.一种改进的K-means算法[J].计算机与现代化,2009,161(1):56-59.YAN Hua.An improved K-means Algorithm[J].Computer and Modernization,2009,161(1):56-59.
[4] Arthur D,Vassilvitskii S.K-means++:The advantages of careful seeding[C].Proceedings of the eighteenth annual ACM-SIAMsymposium on discrete algorithms.Society for Industrial and Applied Mathematics,2007:1027-1035.
[5] 曾璞.面向语义提取的图像分类关键技术研究[D].长沙:国防科学技术大学,2009.
[6] Sivic J,Zisserman A.Video Google:A text retrieval approach to object matching in videos[J].In ICCV,2003(2):1470-1477.
[7] Fei-Fei L,Fergus R,Perona P.Learning generative visual models from few training examples:An incremental bayesian approach tested on 101 object categories[J].Computer Vision and Image Understanding,2007,106(1):59-70.
[8] 牛志彬.图像识别中图像表达的关键技术研究[D].上海:上海交通大学,2001.
