基于边界标记集的专利文献术语抽取方法*
2015-03-19吕学强刘克会
丁 杰,吕学强,刘克会
(1.北京信息科技大学网络文化与数字传播重点实验室,北京100101;2.北京城市系统工程研究中心,北京100035)
1 引言
专利文献是当今世界科学技术最大的信息源,快速有效地利用此信息源,能够促进人类新知识的传播和科技成果的普及。术语是自然语言处理中的一种特殊的词汇数据,与语言中一般的普通词汇不同,术语大多数都是由多个单词组成的词组型术语,它们对于科学技术的发展特别敏感,随着科学技术的发展而发展[1]。在中文专利信息处理过程中,专利术语识别是一个基础环节,专利的检索、专利翻译等后续工作都离不开中文专利术语的识别。因此,专利术语识别质量的高低直接影响到专利文献的应用和科学技术的普及。
现有的专利术语抽取方法主要有语言学方法、统计学方法及统计学和语言学相融合的方法[2]。目前,大部分的研究已经从传统的语言学方法逐步转变为统计与语言学相结合的方法。利用统计的方法获取候选术语,再结合规则的方法对候选术语进行规则过滤。其中,文献[3,4]通过改进的TFIDF模型并经权重计算和阈值筛选后得到专利术语集,但是其方法领域针对性较强,无法证明在大规模语料中的通用性。文献[5~7]等使用条件随机场模型CRF(Conditional Random Fields)机器学习方法结合过滤规则对术语进行抽取,该方法能显著提高未登录术语的召回率,但是语料的标注却需要消耗大量的人力和时间。文献[8,9]通过统计和规则相结合的方法,构建相应的规则库并选择有效的统计量或机器学习模型对中文专利文献进行术语抽取,但并未考虑上下文的信息。
本文在总结前人研究的基础之上,针对前人研究方法在大规模语料中的通用性差、语料标注费时费力的缺点,提出了边界标记集的概念,并应用边界标记集的获取无需人工标注、领域独立性的特点,提出基于边界标记集的术语抽取方法。该方法首先根据文中边界标记集的定义提出边界标记集的构造方法;然后使用种子术语权重计算方法抽取候选术语并结合术语部件库抽取术语;最后通过统计和规则的方法对抽取出的术语进行过滤。该方法充分考虑了专利术语的上下文信息特点,对抽取长术语和短术语都有较好的效果,可明显提高术语抽取的准确率和召回率。
2 基于边界标记集的专利术语抽取方法
2.1 边界标记集的概念
句子是由实词和虚词连接构成的,对于句子中的每一个词,与它直接相邻的两个词称之为它的前驱与后继,本文根据专利文献中术语和前后两个词的位置关系,定义术语边界标记集如下:
定义1术语边界标记集:在专利文献中,由专利术语的前驱和后继及对应的词性所构成的集合称为术语的边界标记集。
作为专利术语的边界标记是通用性较强、具有一般词汇意义的词,并且这些词具有一定的领域独立性。在专利文献中,同一个术语的上下边界标记可能存在多个。例如:术语“光刻投影装置”的上边界标记词有“一种”、“用”、“的”等,下边界标记词为“来”、“中”、“工作”等;不同专利术语可能存在相同的边界标记词,例如“掩模台”和“晶片步进器”具有相同的上边界标记词“在”。虽如此,但可以看出这些词在词性构成上具有一定的相似性,如大部分是动词、助词、标点等。为能够更直观地展示出专利文献中边界标记集元素的构成,本文随机抽取10篇不同领域专利文献并统计术语边界标记集,文献中术语的边界标记词性构成的统计结果如表1所示。
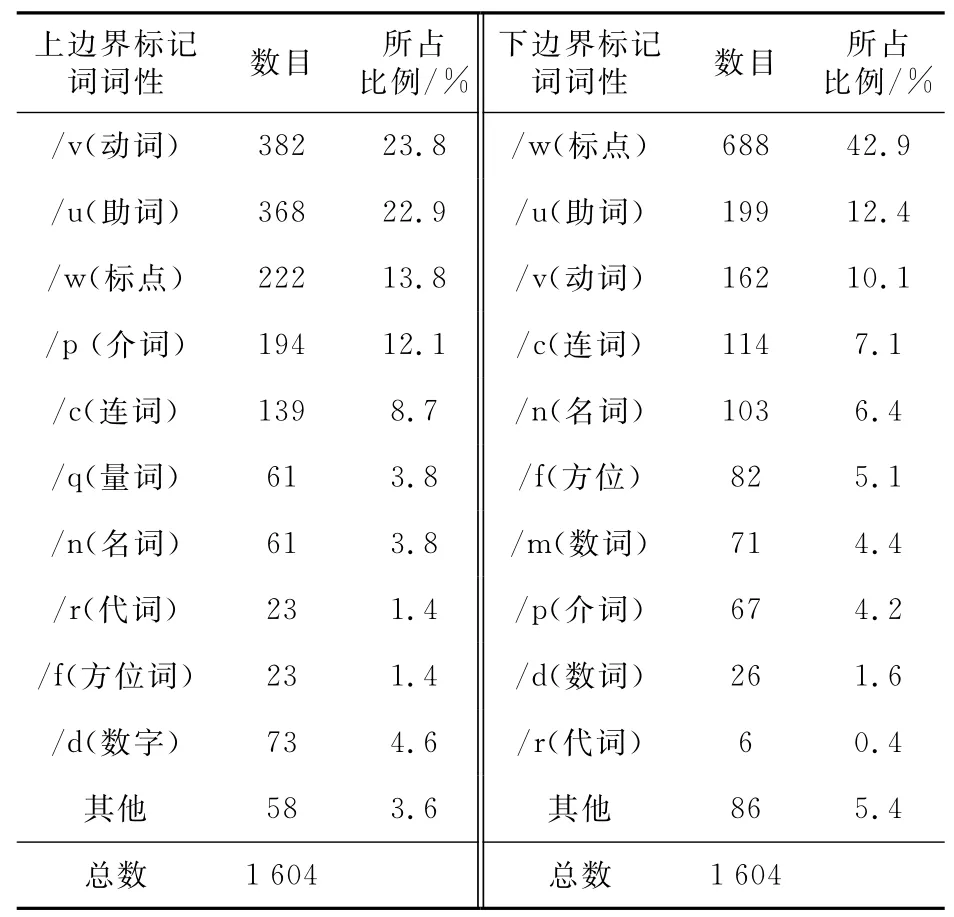
Table 1 Part of speech distribution of boundary tags in the term boundary tag set表1 术语边界标记集中边界标记词性分布表
由表1可以看出:专利术语边界标记符的集合由一些没有构词能力的实词,如动词,一些标点符号以及一些虚词,如介词、连词、量词等构成。根据上述边界集词性特点并对边界词与术语在专利文献中的共现信息统计分析,总结边界标记集的特点如下:
(1)完备性。边界标记集的完备性是指边界标记集合中的边界标记可将专利文献完全切分为字符串长度符合术语长度的候选术语串的程度。一般来讲,边界标记集的完备性越高,抽取专利术语的召回率越高。
(2)多样性。边界标记集合的多样性是指由于专利术语的上下文不同导致专利术语的边界标记也不相同,同时,不同术语的上下文标记也不完全相同。
(3)重复性。边界标记集的重复性是指边界标记集中存在一些边界标记可以作为多个术语的边界。例如,同一个介词或其它一些常见的虚词可能成为不同专利术语的上界标记或下界标记。例如“由/p扎/v模/n工艺制备/n”“由/n 传感器装置/n”中上边界“由/p”可作为多个专利术语的边界。
根据专利文献中对发明专利陈述的特点,不同领域的专利文献都可采用相同的边界标记集的构建方法。首先,不同领域的专利文献有很多相同的边界标记集,例如:“该发明”“利用”“使用”“提高”“以便于”都在不同领域的专利文献中出现;另外,一些标点等非文字特征的边界标记也是不同领域的专利文献所共有的边界标记。因此,边界标记集具有一定的通用性,并根据不同领域专利文献的扩展而扩展。
虽然中文专利文献中的边界标记集提供了边界词之间词串构成术语的可能性,但不能完全保证前后边界标记词之间的词串就是术语。因此,需要根据边界标记集的特点,并结合一定的术语抽取规则和统计量来抽取术语。
2.2 基于边界标记集的术语抽取流程
根据术语边界标记集的特点,本文提出基于部件的本体术语抽取方法,如图1所示,主要包括种子术语抽取、种子术语扩展和候选术语校验三个部分。其中在种子术语抽取部分包括边界标记构建和术语部件库构建;种子术语扩展部分充分利用词性规则和统计量对抽取出的种子术语进行扩展,最终根据术语左右熵的方法对搭配错误的候选术语进行过滤。
3 种子术语抽取
3.1 边界标记集构建方法
从边界标记集的定义可以看出,每个术语都具有术语边界标记集,且专利术语的边界标记集就是专利术语的上下文信息。根据专利文献术语上下文信息并结合边界标记集的特点,通过以下方法构建术语边界标记集Set:
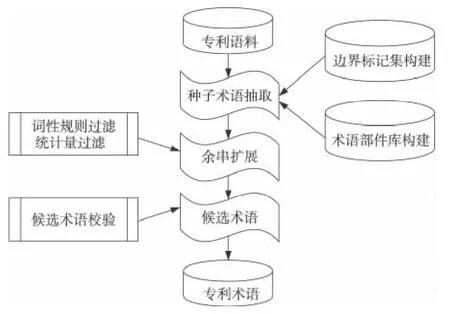
Figure 1 Chinese patent term extraction method图1 中文专利术语抽取方法
(1)初始化术语边界标记集Set为空。
(2)利用统计量IDF构造专利文献通用词表,将专利文献中IDF值较高的无构词能力的词作为专利文献通用词,并添加到标记集Set中。
(3)将专利文献中标点、数词、介词、连词、助词等添加到标记集Set中。
虽然介词、连词和副词后面的动词是专利术语边界标记集的组成部分,但均不能作为专利术语的组成部分,将该类的动词也加入边界标记集Set中,例如,专利文献中“还/d 包括/v”“所/u 述/v”“还/d 可以/v”中“还/d”、“所/u”都不是术语的组成部分。
3.2 术语部件库构建
术语是由一个或多个词构成的,其中有些词生成术语的能力很强,有些词生成术语的能力不强,这些构成术语的一个个词就叫做术语部件[10]。术语一般分为单词型术语和多词型术语两类,单词型术语由单个词语组成,如“传感器”“过滤器”等。单词型术语本身就是部件,它可以生成新的短语型术语,如“温度传感器”“废气过滤器”,而构成多词型术语的每个词都可以看作术语部件。
单词型术语识别通常采用语料库比较的方法,即选择一个通用的平衡语料库与领域语料库相比较,比对两个语料库生成的词表并按照与频度相关的某个统计量进行排序,删除领域词表中在通用词表中统计量高的,剩下的词被认为是术语[11]。
单词型术语的识别和部件库的构建在方法上是一致的,但部件库中的每个词未必都是术语。文中的术语部件仅从术语的领域性来考虑,如果一个词具有较强的领域性,可以把这个词看作术语部件,因此可以采用与上述抽取单词型术语类似的方法来抽取领域部件。人民日报中的词汇大部分是人们生活中经常使用的词汇,领域性较弱,为此本文选用1998年1 月份人民日报熟语料[12]作为专利文献的对比语料,比较两个语料库生成的词表,将只在专利词表出现的词汇抽取出来作为专利术语部件,所得的部分术语部件如表2所示。

Table 2 Term component library表2 术语部件库
从表2的结果中可以看出,有些部件已经是术语,如“暗电流”“光电二极管”等,或是术语的组成部分,如“设备、蚀刻、输出”。通过观察抽取出的术语部件库发现:部件库中存在一些词不能作为术语的组成词,如“范围”,但这并不影响术语的抽取效果,因为文中的部件库仅用于对候选串进行过滤,并不使用部件库来生成术语,所以最终能够提高候选术语的术语度,而不会在术语识别过程中引入噪音。
3.3 种子术语抽取
根据术语边界标记集完备性的特点,将专利文献中相邻的两个边界标记之间的字符串抽取出来,并通过术语部件库过滤以获取候选术语。种子术语抽取的过滤规则如下:
规则1若抽取出的字符串为单字词,则该单字词必须在部件库中出现,否则删除该字符串;
规则2若抽取出的字符串为多字词,经分词后的每个单字词中应该至少有一个在部件库中出现,否则将该字符串删除。
将上述规则过滤之后剩余的字符串作为术语候选串。专利术语在专利文献中的存在具有相对稳定的结构,其内部词语可以看作一个完整的结构,不可随意拆分。目前,术语抽取研究中使用的大部份统计方法都是基于术语的结构完整性特征,选择有效的统计量和评估机制,来衡量术语中词语之间的黏合度以及共现概率[13]。其方法可分为两类:一类是通过统计量分析词串内部词语之间的紧密关系,来确定该词串是否是一个结构稳定的短语;另一类认为:如果一个词串多次在不同的上下文中出现,那么该词串可以作为结构上结合紧密的单元,并且很有可能是术语。
专利术语边界标记集具有多样性,同一个术语上下文环境的不同,术语的上下边界标记也不相同,从而可证明该术语具有稳定的结构,这也符合上文中第二种评估字符串粘合度的方法。因此,可通过候选术语被不同的切分标记切分的数量来衡量候选术语的紧密结合程度。实验中使用了改进的TF-IDF方法,弱化了高词频对权重的影响,增加了通过多样性切分标记切分获取的候选串的权重。本文根据边界标记集的特点提出种子术语的权重计算方法,具体计算方法如下:

其中,preSeg、postSeg分别为候选术语S前后边界标记集合;f(preSeg)为术语边界标记集合大小,因为preSeg、postSeg都表示集合,都已将重复的候选串删除,弱化了同一术语相同上下文在术语抽取中的作用,增强了切分标记集多样性的影响;N表示所有专利文献的篇数;df(S)表示候选术语串在所有专利文献中出现的篇数;α、β为权重因子。将Weight(S)满足某一个阈值的候选术语抽取出来作为种子术语。
4 种子术语余串扩展
为了便于对种子术语进行扩展,通过种子术语对包含种子术语的候选串进行扩展,并定义如下变量。
定义2种子术语余串:在候选术语串中,去除种子术语后剩余的部分,称之为种子术语的余串。
定义3单字词:本文将经ICTCLAS[14]切分且具有独立词性标注的最小语义单元称作单字词。如“形成/v”,“传感器/n”“的/u”。
定义4最长术语:本文将在专利文献中出现的且不被更长的术语包含的专利术语称之为最长术语。
在本文实验中,通过边界标记符集抽取的候选串都是“宽类型”的,这里的“宽类型”是指一个候选串是术语或者包含一个最长的术语,而不会被其它更长的专利术语包含。例如候选串“制造/v CMOS/x 图像/n 传感器/n”中包含最长的术语“CMOS/x 图像/n 传感器/n”,而不会被其他更长的术语包含,这是因为在候选串中出现的词未在边界标记集中出现。基于候选串的这个特点,可以在种子术语基础之上,对候选串进行左右种子术语余串扩展。例如,种子术语“传感器/n”,如果“图像/n 传感器/n”不在种子术语中,可以通过种子术语左扩展一个单字词“图像/n”,抽取出术语“图像/n传感器/n”。
4.1 词性规则过滤单字余串
定义5上边界拒取:设候选串S可以表示为S1S2,其中S2为种子术语,S1为单字词,如果S1S2不符合术语词性搭配规则,则将S1删除,称之为上边界拒取。
定义6下边界拒取:设候选串S可以表示为S1S2,其中S1为种子术语,S2为单字词,如果S1S2不符合术语词性搭配规则,则将S2删除,称之为上边界拒取。
根据文献[13]中统计结果并结合专利术语的特点发现,专利术语大多都是以名词(/n)、动词(/v)、形容词(/a)、副词(/d)等四类词开头,且大多以名词和动词为主极,少数以副词开头。但是,当候选串是以动词开头时,若动词前面的修饰词是副词时,该副词和动词具有“发出动作”的语义,不是术语的组成部分,因此一些被副词修饰的动词不能作为专利术语上边界,此时副词将视为拒绝后驱词(动词)作为术语上边界的提示词;一些紧跟介词后面的动词也具有“发出动作”的语义,同样也不能作为术语的上边界。如“以/p 保护/v 感测组件/n”“通过/p调节/v减压阀/n”中“保护”“调节”都不能作为专利术语的组成部分。术语大多以名词(/n)、动词(/v)、形容词(/a)、助词(/u)、后缀词(/k)、量词(/q)等作为结尾。因此,一些具有“发出动作”的动词以及紧跟其后的介词也都不能作为术语的构成词。部分统计的规则如表3和表4所示。

Table 3 The pre-boundary tag rules表3 上边界拒取规则表

Table 4 The post-boundary tag rules表4 下边界拒取规则表
4.2 统计量扩展单字余串
在术语抽取过程中,常使用一些统计量来计算术语之间的结合程度。其中,张锋等[15]使用互信息来计算术语之间结合的紧密程度,林磊等[16]通过似然比来计算。但是,一些结合紧密、频度较高的候选串并不能构成术语。例如:“操纵/v 送/v料/n 推杆/n”、“推动/v送/v料/n 推杆/n”都不是术语,只是选术语“送/v 料/n 推杆/n”的两个固定搭配。针对以上问题,本文综合考虑了词频、构成术语的词串长度和词性搭配信息,提出了余串术语修饰度的计算方法来衡量单字余串和种子术语之间的粘合程度,以决定是否对种子术语扩展。余串修饰度是对余串和种子术语之间紧密关系的度量,计算方法如公式(2)所示:

其中,Weight(Left)表示候选串中余串的修饰度;POSTTagging表示候选术语S所包含的种子术语的所有单字余串;POSTSet表示所有单字余串集合,在POSTSet中出现的单字词都是实词,因为大部分虚词已经作为候选术语的边界标记;F(POSTTagging)为特征函数,如果集合中POSTTagging的词性与候选串S的单字余串相等 则 取1,否 则 取0;β为 调 节 因 子,若∑F(POSTTaging)值为1,β取1,否则β取0。当∑F(POSTTaging)的取值大于1时,表明修饰同一种子术语的同一词性的实词有多个,该词性余串和种子术语不具备修饰关系。Len(Left)表示候选术语S单字余串的长度,Fre(S)表示候选术语S的频度。例如:候选串“制造/v 图像/n 传感器/n”中“图像/n 传感器/n”是种子术语,Contex={制造/v,触发/v},则β取0,不对种子术语往前扩展。因为如果修饰“图像/n传感器/n”的动词有多个,那么这些动词应该都具有发出动作的语义,而不应作为种子术语的前缀,而对候选术语“透光/v树脂/n 材料/n”中种子术语是“树脂/n 材料/n”,Contex={透光/v},β取1,那么“透光/v”很有可能是术语的组成部分。
4.3 种子术语多字余串扩展
上述两种方法只能处理种子术语前后的单字余串,在候选术语中存在余串为多字的候选术语。如候选术语“易/a受/v 腐蚀性/n 含氟/n 化合物/n 侵蚀/v”中包含种子术语“含氟/n 化合物/n”,其前余串为“易/a 受/v 腐蚀性/n”,后余串为“侵蚀/v”,后余串可以采用上述统计量扩展单字余串的方法给予排除,而对于前余串主要使用词性规则的方法处理。统计术语的词性搭配规则,采用如下算法对多字余串进行扩展:
算法种子术语多字余串扩展算法
输入:
包含种子术语和多字余串的种子候选术语集合Set:S为Set中的候选术语且候选串可以表示为preSeg+Seed+PostSeg形式,其中preSeg、PostSeg都为多字余串;
所有单字词的词性集合TagSet:TagSet中元素为〈Token,Tag〉,其中Token为单字词性,Tag为单字词性的词性。
输出:经多字余串扩展后的术语。
算法描述:

边界标记集抽取出来的候选术语中有的不包含种子术语,对此,我们计算出候术语和其他候选术语的最长公共字串作为种子术语,如果公共字串包含名词,使用上述种子术语扩展的方式进行术语扩展,否则丢弃该候选术语,这就弥补了部分候选术语中因为不存在种子术语而不能对种子术语进行扩展方法的不足,提高了术语抽取的召回率。
5 候选术语校验
实验中的候选术语,依然有部分类似于v+n型的名词性短语作为候选术语,但该类的候选术语大多是一些固定的搭配,不能作为专利术语。通过统计发现:在该类候选术语中存在一些词很容易构成搭配关系,即这类词语与其它词语搭配的灵活性非常大。针对术语抽取中的这种现象,刘里[17]提出了一种基于左右熵的短语过滤方法,本文借鉴上述方法,对活跃词性候选术语进行过滤。具体方法如公式(3)所示:
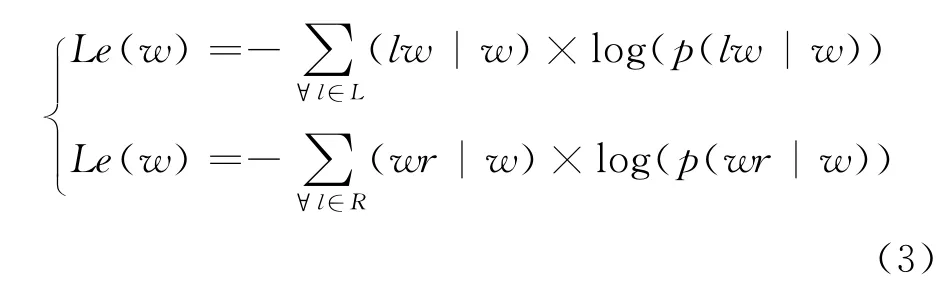
其中,l表示出现在种子术语w左侧的词汇的集合;r表示出现在种子术语w右侧的词汇集合;p(lw|w)表示词l出现在w左侧的概率;p(lw|w)表示词r出现在w右侧的概率。
根据上述公式,如果某个余串是易于搭配的活跃词汇,那么这个词的左右两个熵应该只是有一个比较大。如果一个单字词作为词首出现,那么需计算该单字词右侧与其它词汇搭配的熵的大小,如果该单字词作为词尾出现,则需要计算该单字词左侧与其它词汇搭配的熵的大小。例如,候选串“面对/v集成电路/n”“布置/v 传感器/n 器件/n”“传感器/n器件/n制造/v”都可以通过活跃词汇的左右熵过滤后正确抽取出术语“集成电路”“传感器器件”。
6 实验结果和分析
本文使用涉及纺织、机械、物理、电学四个领域每个领域1 000篇、共计4 000篇专利文献作为实验语料,通过ICTCLAS[14]对专利文献进行专利分词及词性标注,并基于此构建边界标记集。评测采用准确率(P)、召回率(R)和F值进行评测。各指标定义如下:

在评估实验结果正确率和准确率时,每个领域随机抽取150篇、共600篇作为测试语料,在术语抽取过程中阈值设定的好坏将极大地影响实验的结果,阈值的最终确定需要通过大量的实验来实现。在本实验中,鉴于候选术语的前后边界标记在种子术语抽取过程中起到等同的作用,在公式(1)中人为设定α、β都为0.5,在选取阈值抽取候选术语时经实验验证选取0.6作为候选术语阈值,公式(2)中使用统计量方法进行余串扩展时设置权重Weight(Left)为3.0时具有较佳的识别效果。人工标注选取文献中出现的术语,将本文的方法和传统的c-value[18]和文献[15]中互信息抽取术语的方法在相同测试集下进行对比,表5是在候选术语权重分别取0.55、0.60、0.65的实验结果。
从表5统计结果可以看出,本文提出的基于边界标记集的方法效果良好,正确率和召回率都明显高于互信息方法和c-value方法。从本方法不同的weight(S)阈值设定可以看出,当候选串weight(S)阈值设为0.55时本文方法具有较高的召回率,当weight(S)阈值设为0.65时具有最高的准确率,但weight(S)设为0.60时本文方法具有最高的F值,此时准确率比c-value方法高出3个百分点,比互信息方法高出6个百分点,召回率比c-value方法高3个百分点,与互信息方法相比,高11个百分点。
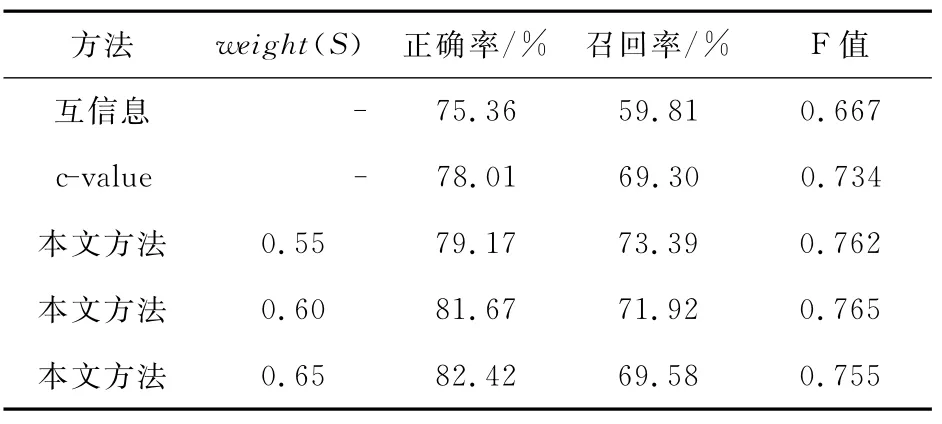
Table 5 Experiment results in contrast with other methods表5 本方法和其它方法结果对比
由此可见,本文方法相对对比实验中的其他方法具有良好的术语抽取准确率和召回率。为当weight(S)阈值设为0.60 时,不同长度术语抽取结果如表6所示。
从表6中可以看出,本文中将单字定义为分词后的最小单词形式,因此互信息的方法不能对单字术语起作用,然而本文的单字抽取召回率高于cvalue的方法。这是因为在应用c-value方法来计算候选术语权重时,不仅考虑了候选术语的词频,还需要考虑该候选串被包含更长候选术语的次数,即被包含的次数越多,对应的术语的权重就会越低。专利文献中的术语有很大一部分是被长术语包含的,而本文中的方法不需要考虑这些因素。但是,互信息的方法对双字词的抽取效果最佳,高于本文中的方法,而本文中双字词的抽取效果略高于c-value的方法。
但是,通过对四字和四字以上的长术语的对比效果可以看出,本文方法要明显优越于其它两种方法,这是因为本文的方法中的边界标记集的多样性,一些作为短术语的边界标记同样可以对较长的术语边界标记;同样,术语部件库对不同长度的候选术语都能起到相同的过滤效果,即与候选术语长度无关。另外,在专利文献中存在一些词频为1的长术语,例如“P/x-/n 型/k 金氧半/n 位/q 准/a转换/v电路/n”“堆栈式/n N/x-/n 型/k 金氧半/n 晶体管/n 形式/n”等也可以通过本文中的方法抽取出来。
7 结束语
本文通过构建边界标记符集进行术语抽取,过滤部分标记之间的候选串作为种子术语,包含种子术语的候选串,采用规则和修饰度的方法来确定是否对种子术语进行扩展。对低频候选串采用最长公共字串扩展的方法抽取低频术语,提高了低频术语的召回率。实验表明,该方法能够有效地识别出大部分高频术语和部分低频术语。但同时,规则制定时难免会引入一部分噪音,同时对低频术语抽取时,扩展模式过于单一,不能提取所有低频术语。本文中边界标记集的构建存在一些不足,边界标记集中存在一些单字词是术语的组成部分,但错误地判别为停用词,如术语“电子/n-/n 空穴/n 对/p”中“对/p”错误地判定为边界标记。
下一步工作中,我们将根据论文中边界标记集中出现的错误,进一步优化边界标记集,提高边界标记集的正确性并制定出一些更加准确的术语扩展规则,以抽取出更多的术语。
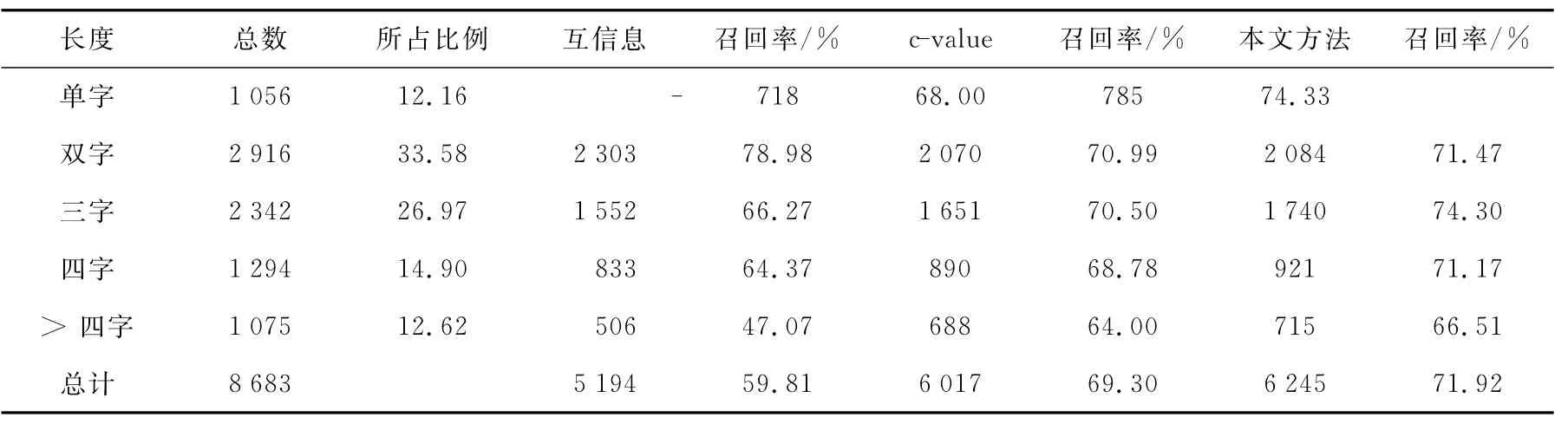
Table 6 Accuracy comparison of different methods表6 不同方法正确率对比
[1] Feng Zhi-wei.A new scientific domain in terminology——computational terminology[J].Terminology Standardization&Information Technology,2008(4):4-9.(in Chinese)
[2] Zhang Wen-jing,Liang Ying-hong.Study on the technology of term identification [J].Information Technology,2008(3):6-9.(in Chinese)
[3] Zhai Du-feng,Liu Bai-song.Automatic domain-specific term extraction in administrative-domain ontology[J].New Technology of Library and Information Service,2010,26(4):59-65.(in Chinese)
[4] Gu Jun,Wang Hao.Study on term extraction on the basis of Chinese domain texts[J].New Technology of Library and Information Service,2011,27(4):29-34.(in Chinese)
[5] Jia Mei-ying,Yang Bing-ru,Zheng De-quan,et al.Research on automatic military intelligence term extraction using CRF model[J].Computer Engineering and Applications,2009,45(32):126-129.(in Chinese)
[6] Tang Tao,Zhou Qiao-li,Zhang Gui-ping.Term extraction based on the combination of statistics and rules[J].Journal of Shenyang Aerospace University,2011,28(5):71-74.(in Chinese)
[7] Yue Jin-yuan,Xu Jin-an,Zhang Yu-jie.Chinese word segmentation for patent documents[J]Acta Scientiarum Naturalium Universitatis Pekinensis,2013,49(1)159-164.(in Chinese)
[8] Dai Cui,Zhou Qiao-li,Cai Dong-feng,et al.Automatic identification of Chinese maximum noun phrase based on statistics and rules[J].Journal of Chinese Information Processing,2008,22(6):110-115.(in Chinese)
[9] Zeng Wen,Xu Shuo,Zhang Yun-liang,et al.Automatic extraction technology research and analysis of scientific literature terminology[J].New Technology of Library and Information Service,2014:30(1):51-55.(in Chinese)
[10] W Yun-fang,Sui Zhi-fang,Qiu Li-kun,et al.The approaches and strategies to describe the term component in information science and technology[J].Applied Linguistics,2003(4):34-39.(in Chinese)
[11] He Yan,Sui Zhi-Fang,Duan Hui-ming,et al.Term mining combining term component bank[J].Computer Engineering and Applications,2006,42(33):4-7.(in Chinese)
[12] Peking University Institute of Computational Linguistics.January 1998 Daily segmentation,annotated corpus[EB/OL].[2014-10-19].http://icl.pku.edu.cn/ic_groups/corpus/dwldform1.asp.2001-05-10/2004-04-1.(in Chinese)
[13] Zhou Lang.Several research questions Chinese term extraction[D].Nangjin:Nangjin,Nanjing University of Science&Technology,2009.(in Chinese)
[14] Zhang H P,Yu H K,Xiong D Y,et al.HHMM-based Chinese lexical analyzer ICTCLAS[C]∥Proc of the 2nd SIGHAN Workshop on Chinese Language Processing-Volume 17,2003:184-187.
[15] Zhang Feng,Xu Yun,Hou Yan,et al.Chinese term extraction system based on mutual information[J].Application Research of Computers,2005,22(5):72-73.(in Chinese)
[16] Lin Lei,Sun Cheng-jie,Zhang Er-yan,et al.A term extraction approach based on modified log-likelihood ratio[J].Journal of Guangxi Normal University(Natural Science),2010,28(1):153-156.(in Chinese)
[17] Zhou Long,Feng Chong,Huang He-yan,et al.Oriented terminology extraction phrase filtering technology [J].Computer Engineering and Applications,2006,45(19):9-11.(in Chinese)
[18] Frantzi K T,Ananiadou S,Tsujii J.The c-value/nc-value method of automatic recognition for multi-word terms[C]∥Proc of the 2nd Eruopean Conference,ECDL’98,1998:585-604.
附中文参考文献:
[1] 冯志伟.一个新兴的术语学科——计算术语学[J].术语标准化与信息技术,2008(4):3.
[2] 张文静,梁颖红.术语抽取技术研究[J].信息技术,2008(3):6-9.
[3] 翟笃风,刘柏嵩.政务领域本体术语的自动抽取[J].现代图书情报技术,2010,26(4):59-65.
[4] 谷俊,王昊.基于领域中文文本的术语抽取方法研究[J].现代图书情报技术,2011,27(4):29-34.
[5] 贾美英,杨炳儒,郑德权,等.采用CRF 技术的军事情报术语自动抽取研究[J].计算机工程与应用,2009,45(32):126-129.
[6] 唐涛,周俏丽,张桂平.统计与规则相结合的术语抽取[J].沈阳航空航天大学学报,2011,28(5):71-74.
[7] 岳金媛,徐金安,张玉洁.面向专利文献的汉语分词技术研究[J].北京大学学报(自然科学版),2013,49(1):159-164.
[8] 代翠,周俏丽,蔡东风,等.统计和规则相结合的汉语最长名词短语自动识别[J].中文信息学报,2008,22(6):110-115.
[9] 曾文,徐硕,张运良,等.科技文献术语的自动抽取技术研究与分析[J].现代图书情报技术,2014,30(1):51-55.
[10] 吴云芳,穗志方,邱利坤,等.信息科学与技术领域术语部件描述[J].语言文字应用,2003(4):34-39.
[11] 何燕,穗志方,段慧明,等.一种结合术语部件库的术语提取方法[J].计算机工程与应用,2006,42(33):4-7.
[12] 北京大学计算语言学研究所.1998年1月人民日报切分、标注语料库[EB/OL].[2014-10-19].http://icl.pku.edu.cn/ic_groups/corpus/dwldform1.asp.2001-05-10/2004-04 一1.
[13] 周浪.中文术语抽取若干问题研究[D].南京,南京理工大学,2009.
[15] 张锋,许云,侯艳,等.基于互信息的中文术语抽取系统[J].计算机应用研究,2005,22(5):72-73.
[16] 林磊,孙承杰,张二艳,等.一种基于改进似然比的术语自动抽取方法[J].广西师范大学学报(自然科学版),2010,28(1):153-156.
[17] 周浪,冯冲,黄河燕.一种面向术语抽取的短语过滤技术[J].计算机工程与应用,2009,45(19):9-11.
