用于图像分类在线字典学习算法
2015-03-10兰俊花
兰 俊 花
(天津大学 理学院数学系, 天津300072)
用于图像分类在线字典学习算法
兰 俊 花
(天津大学 理学院数学系, 天津300072)
稀疏编码在人脸识别上的成功促使这项技术应用在更广泛的计算机视觉中.图像分类是图像检索的基础,而图像的识别是比人脸识别更复杂,因为首先图像数据量更大,其次图像中要检索的目标数据不易得到.为解决这两个问题,提出了一种新的在线字典学习的算法.实验结果表明本方法在图像分类上比最近提出的其他字典学习的方法效果更好.
稀疏编码;字典学习;图像分类
近些年,稀疏编码和字典学习被成功地应用在很多的领域,包括图像去噪[1],图像超分辨率,面部识别[2],以及图像分类和识别[3].这主要是因为属于同一类的高维的自然信号近似地存在于一个低维的子空间,这样一个信号可以被少量的原子近似的表示,也就是存在一个过完备的字典D={d1,d2,…,dk}∈Rm×k(m 经典的字典学习包含两个迭代步骤:稀疏编码和字典更新.稀疏编码就是对于给定的字典找到信号的线性分解,然后固定稀疏编码对字典进行更新,这个过程不断迭代直到最合适的字典找到为止.然而,尽管这些方法得到的字典对原始信号有很高的精确度,在图像去噪,图像填充中有很好的效果,但是这些字典对于图像的分类却没有很好的效果.因为这些方法的目的是最小化原始信号的重构误差,所得到的字典没有图像类别的判别信息. 为了解决分类问题,许多监督的字典学习方法被提出来.最近Zhang等[3]在字典学习中将分类器的训练添加到目标函数中,获得了很好的分类效果.Pham等[4]首先学习一个字典,然后用稀疏编码作为特征来训练一个分类器,比如,SVM. Ramirez等[5]通过加入了一个非同类表示错误项学习了一个结构化的字典,然后应用重构误差进行分类,但是这样的分类过程比较复杂. 受前面方法的启示,我们也考虑将类的标签信息加在字典学习的过程中.直观上来说,像图像这类高维的信号,属于同一个类中的图像接近与一个低维的子空间,这样,如果找到了每一个类中的具有代表性的较少的几个采样标本,联合他们成为一个整体的字典,那么一个信号在这个字典下将有稀疏的表示,同时所得到的稀疏编码包含了这个信号属于哪一个类这样的语义信息.实验证明,不同类的特征通常共享一些相同的信息,所以不同类中的字典可能共享一些相似的字典原子,这样使得依靠重构误差得到的分类结果变差,为了解决这类问题,本文将不同类表示错误项和分类错误项加到目标函数中,本方法将学习一个鉴别的字典,同时学习到的分类器可以使得分类更简便. 考虑一组输入信号Y=[y1,y2,…,yn]∈Rm×n,传统的字典学习即最小化下面的期望重构误差: (1) (2) 许多算法可以得到这个问题的近似解,比如 K-SVD, 然而K-SVD解的是一个l0范数限制问题,这个问题不是凸的,因此这个解在理论上是次最优的. 最近,作为l0范数的一个凸松弛,l1范数被广泛的应用,因为l1范数比l0范数稳定,所以对于输入信号的一些小地扰动不是很敏感,同时l1范数求解到的非零系数集中在训练采样所在的类中,这样字典学习的问题可以表示为: (3) 参数λ控制着重构误差和稀疏编码的权重.需要注意的是式(3)中的问题对于D和X不是凸的,但对于D和X中的任意一个是稳定时,同时这个问题是一个凸问题. 当D固定时这个问题叫做稀疏编码.每个信号yi期望用少量的几个原子字典进行稀疏表示,这个问题是一个l1正则化最小二乘问题,许多方法可以用来解决此问题,比如:内点法,同伦法,LARS,Lee等[3]提出了feature-signsearch算法对于解决此问题有更好的效. 当稳定时,这个问题叫做字典学习,这是一个 l2限制的最小二乘问题,用Marial等[6]block-coordinatedescent方法来求解. 稀疏编码作为一个特征用来学习一个分类器被广泛的应用.对于分类器一个简单的形式可以定义为: (4) 2.1 固定D和W求解稀疏编码X 令Y=[y1,y2,…,yc]∈Rm×n是输入信号,X=[x1,x2,…xc]为输入信号经过字典后的的稀疏表示 λ‖xi‖1 (5) 这是一个经典的lasso模型,这里我们使用feature-sign search 算法来解决此问题. 2.2 固定X, 更新D和W 为了加强字典的鉴别作用,使得得到的稀疏编码更简单,同时更新D和W, 这个问题可以表示为: (6) (7) 我们应用用Marial等[11]block-coordinate descent方法来求解. 2.3 初始化参数D0,W0 对于D0我们采用高斯随机矩阵(Gaussian random matrix),对于W0我们采用多变量回归模型(multivariate ridge regression) (8) W的解为: W=HXT(XXT+αI)-1 (9) (10) 对于一个新的检测信号,我们首先通过下面的等式得到它的稀疏编码: (11) 然后x的类可以通过: (12) 获得.这里的l∈Rc是类标签向量. 本文在两个公共数据库上检测这个方法(Extended YaleB database[7],MNIST[8]),同时和一些监督的学习方法(D-KSVD[9],LC-KSVD[10],LLC[11])以及一些基准算法(K-SVD[1]和SRC[2]进行比较. 3.1 Extend YaleB database上的实验 我们取了4个不同的字典个数,即对于每一类字典原子的个数k=5,10,15,20.实验的结果显示在表1中.从表1中可以看出本文的新方法比其他的方法有更高的识别准确度.当每个类中有20个字典时,SRC的最好的识别率是88.8%,而我们的方法在每个类中字典个数是5时就超过了SRC方法.这意味这我们的方法得到了一个简洁的合适的字典.当k=15时,识别率达到95.6%,但当k=20时,识别率下降到94.9%,这可能是因为训练集个数过小而产生的过完备效应.K-SVD算法当k=20时识别率明显下降,这也说明了l0范数处理问题的不稳定性. 表1 Extend YaleB database上人脸识别 3.2 对于数字的识别 本文应用MNIST[8]数据集作为手写字体识别.它包含了70 000个手写字,其中60 000个作为训练集,10 000作为检测集每个数字被正则化和中心化为一个2828的图片,我们仅仅显示4,7,9这三个容易混淆的数字.实验结果显示在表2中(实验中每类中字典原子的个数选为15),实验结果显示我们的算法得到很好的结果. 表2 对数字识别 对于图像的分类,本文提出了一个在线鉴别字典学习的方法.通过实验显示了范数在处理稀疏编码问题中比范数更精确,同时实验表明在线字典学习使用更少的内存和时间,字典和分类器同时学习得到更好的分类效果.我们将来的工作包括研究核字典学习和核稀疏编码,从而对大数据有更好的分类效果. [1] AHARON M, ELAD M, BRUCKSTEIN A,etal. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation [J]. IEEE Trans. Signal Processing, 2006, 54(11): 4311-4322. [2] WRIGHT J, YANG A, GANESH A,etal. Robust Face Recognition via Sparse Representation [J]. IEEE Trans. Pattern Analysis and Machine Intelligence, 2009, 31: 210-227. [3] JIANG Z, LIN Z, DAVIS L. Label Consistent K-SVD: Learning a discriminative dictionary for recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35: 2651-2664. [4] PHAM D S, VENKATESH S. Joint learning and dictionary construction for pattern recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition, 2008. [5] RAMIREZ I, SPRECHMANN P, SAPIRO G. Classification and clustering via dictionary learning with structured incoherence and shared features[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2010. [6] MARIAL J, BACH F, PONCE J,etal. Online learning for matrix factorization and sparse coding [J]. Journal of Machine learning Research, 2010, 11: 19-60. [7] LECUN Y, BOTTOU L, BENGIO Y. Gradient-based learning applied to document recognition [J]. Proceedings of IEEE, 1998, 86: 2278-2324. [8] GEORGHIADES A, BELHUMEUR P, KRIEGMAN D. From few to many:Illumination cone models for face recognition under variable lighting and pose [J]. IEEE Trans. Pattern Anal. Mach. Intelligence, 2001, 33: 643-666. [9] ZHANG Q, LI B. Discriminative k-svd for dictionary learning in face recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition, 2010. [10] JIANG Z, LIN Z, DAVIS L. Label Consistent K-SVD: Learning a discriminative dictionary for recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35: 2651-2664. [11] WANG J, YANG J, YU K,etal. Locality-constrained linear coding for image classification[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2010, 3360-3367. Online dictionary learning algorithm for image classification LAN Jun-hua (Department of Mathematics, School of Science, Tianjin University, Tianjin 300072, China) The success application of sparse coding in face recognition makes this technology used to a variety of problems in computer vision. Image classification is the basis of image retrieval, but image recognition is more complex than face images.In order to solve these two problems, this paper proposed a new online dictionary learning algorithm. The experimental results showed that the method was better than other dictionary learning method in image classification. sparse coding, dictionary learning, image classification 2014-08-11. 兰俊花(1989-),女,硕士,研究方向:图像处理. TP391 A 1672-0946(2015)05-0637-041 字典学习的介绍

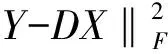




2 算法实现的过程










3 实 验


4 结 语
