多重填补法在任意缺失随访资料中的应用*
2015-03-09同济大学医学院预防医学教研室200092邹莉玲吴娟丽
同济大学医学院预防医学教研室(200092) 邹莉玲吴娟丽 李 觉
多重填补法在任意缺失随访资料中的应用*
同济大学医学院预防医学教研室(200092) 邹莉玲△吴娟丽 李 觉
目的比较任意缺失模式下不同填补方法在随访资料缺失数据中的多重填补效果。方法结合我国外周动脉疾病患者踝臂指数(ankle brachial index,ABI)等基线及六年随访数据,通过SAS9.3/MI过程,分别采用马尔可夫链蒙特卡罗(markov chain monte carlo,MCMC)、回归分析、判别分析(discriminant analysis)和logistic回归等方法,实现生存时间、生存结局变量缺失值的填补,并作综合分析及比较。结果得到不同填补方法、不同填补次数多重填补后的生存时间和结局变量完全数据集,并对总体参数作出估计和统计,计算各次填补效率等综合评价指标。结论对于多次随访资料中的连续性变量生存时间,采用回归分析方法填补效率较高,填补效率随着填补次数增加而增大,对于缺失率小的变量填补效率更高。
多重填补MI 任意缺失模式 缺失数据 随访研究
数据缺失是实验研究和调查研究中普遍存在的问题,数据缺失会增加统计分析任务的复杂性,降低工作效率,甚至造成结果偏倚。数据缺失特征一般可根据缺失机制、缺失模式两种方法进行分类[1-4]。按缺失机制分为:(1)完全随机缺失(missing completely at random,MCAR),缺失现象完全随机发生,与自身或其他变量的取值无关。该缺失机制在实际应用中较少存在。(2)随机缺失(missing at random,MAR),是指缺失数据的发生与数据集中其他无缺失的完全变量的取值有关。MAR是最常见的缺失机制。(3)非随机缺失(missing not at random,MNAR),是指数据的缺失不仅与其他变量的取值有关,也和自身有关。这种缺失大都不是由偶然因素所造成的,缺乏有效的处理方法[1-3]。按数据缺失模式分为:(1)单调缺失模式:对数据集进行适当的行列变换后,可以得到这样一个矩阵,即呈现出一种层级缺失的模式,矩阵中的元素yj缺失时,则对任意的P≥j,元素yp也是缺失的。(2)任意缺失模式:数据缺失具有随意性,没有任何规律可循,即使通过行列变换也无法看出任何规律[1-3]。
在20世纪70年代首先由Donald B.Rubin提出的多重填补(multiple imputation,MI)方法被认为是解决数据缺失问题的首选方法[2-3],该方法通过多次填补产生若干个完整数据集并用于综合分析,可反映出由于数据缺失造成的统计推断结果的不确定性。随着计算方法和软件技术的成熟,该方法被越来越多地应用于生物医学、社会科学及其他许多领域。本文拟采用SAS9.3/MI过程中的MCMC、回归(regression)、logistic回归、判别分析(discriminant analysis)等方法[9],实现各种类型变量任意缺失值的填补,并对各填补方法进行比较和评价。
资料与方法
1.资料
(1)资料来源
本文所用数据来源于国家自然科学基金项目:我国外周动脉疾病的危险因素及心血管疾病死亡风险预测模研究。2004年7月1日至2005年1月16日期间完成包含踝臂指数(ABI)的基线资料收集。对每位研究对象测量静态ABI,并由专业人员采用问卷调查表记录研究对象的人口学资料、生活行为习惯、既往史和现病史、体格检查及实验室检查结果。此后分别于2006年1月、2008年1月和2010年9月开展三次随访调查,收集研究对象的心血管事件发生、死亡结局和生存时间等数据。本文选用数据核查后的3606例研究对象的性别、年龄、身高、体重、ABI以及三次随访获得的生存时间T值(T1、T2、T3)及结局变量S值(S1、S2、S3)作为欲填补的数据集。
(2)数据特征
ABI随访数据中的性别、年龄、身高、体重、ABI和第一次随访S1、T1为完全变量(N=3606)。其中性别(Gender)和第一次随访结局(S1)为二分类变量,男性患者1912例(53.02%),第一次随访死亡308人(8.54%)。第二次随访和第三次随访的结局变量(S2、S3)和生存时间(T2、T3)为不完全变量,S2、S3和T2、T3的数据缺失频数分别为522(14.48%)、535(14.84%)、559(15.50%)和1148(31.84%),见表1,表2。
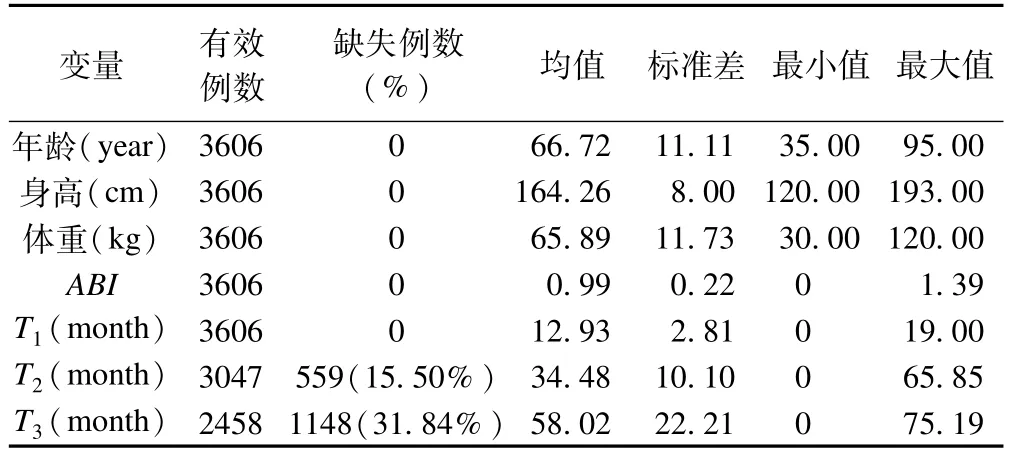
表1 ABI随访数据中各连续变量的统计描述特征

表2 ABI随访数据中各分类变量的统计描述特征

表3 数据缺失模式
表3为数据缺失的模式。对该矩阵进行任意的行列变换都无法呈现层级缺失的模式,因此本资料数据缺失为任意缺失模式。
2.方法
分别采用SAS9.3/MI过程中的MCMC、FCSREG、FCS-Discrim、FCS-Logistic方法进行多重填补[9],填补次数(m)依次设置为2、5、10次。并对填补后的多个数据集进行综合分析和结果比较,连续性变量计算各次填补后的填补效率、总体参数的均值Q和方差σ2、可信区间范围,分类变量计算各事件频率。
假定某不完全变量的总体参数为Q和σ2,多重填补的次数为m。则每次多重填补后可得到m个Q和σ2的点估计值,进行综合分析即可得到总体均值Q和方差σ2的估计和推断[5,7]。

结 果
将不同填补方法、不同填补次数用于任意缺失模式下的第二次和第三次随访的结局和生存时间变量进行数据填补,再采用以上各指标作出总体参数估计和推断结果(表4、表5和表6),并给出综合评价指标填补效率的计算结果(表7)。

表4 不同方法填补后的生存时间变量方差及相关信息
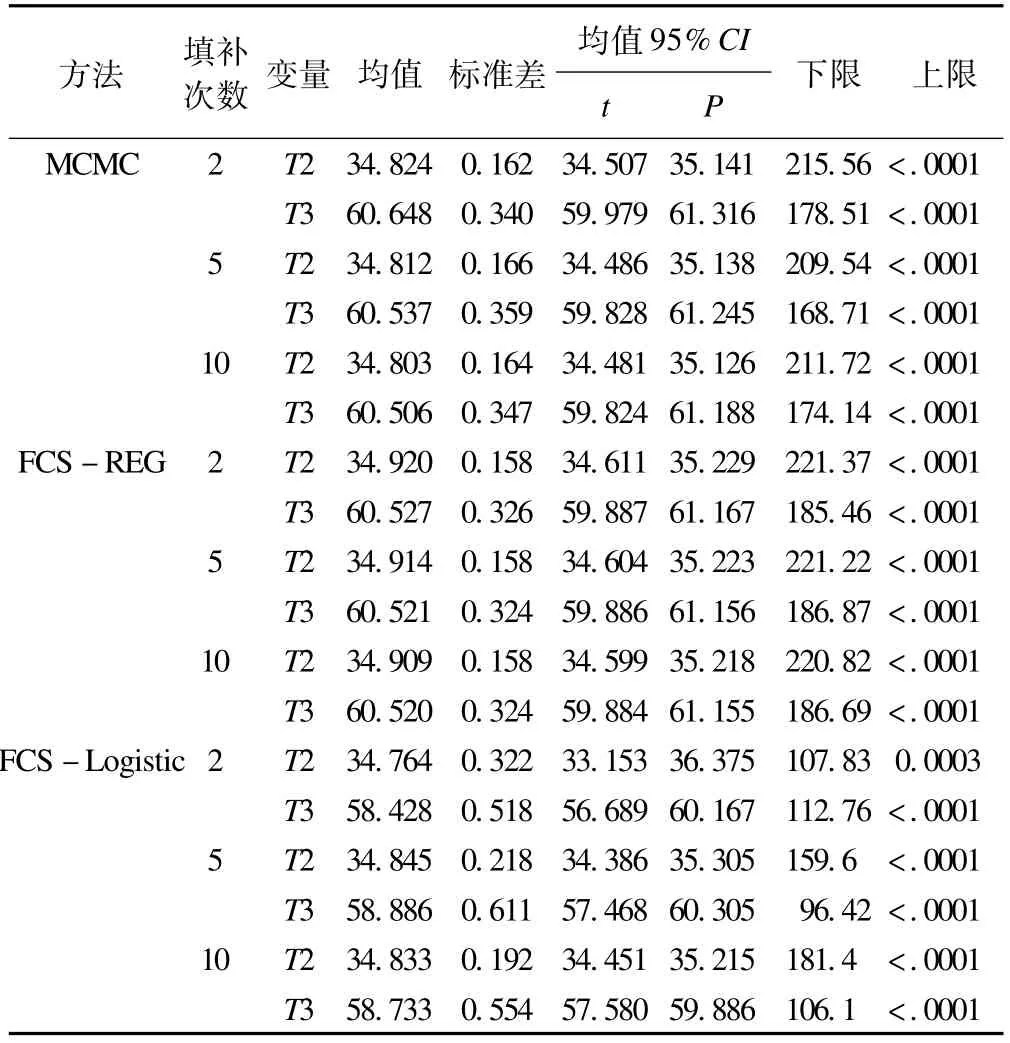
表5 不同方法填补后的生存时间变量参数估计

表6 不同方法填补与删除法的结局变量死亡频率(%)

表7 不同方法填补的效率RE计算表
讨 论
本研究通过采用MCMC、回归分析、logistic回归和判别分析等MI填补方法,对外周动脉疾病ABI基线及多次随访资料中任意缺失模式下的生存时间和结局变量进行缺失数据填补,结果提示对于连续性变量(生存时间),回归分析方法填补效率最高,效率随着填补次数增加而增大,并且对于缺失比例较小的变量填补效率更高,这与其他文献结论一致。本文还应用logistic回归和判别分析等填补方法,对二分类变量(生存结局)的缺失数据进行了多重填补并加以比较。由于两变量的缺失率都很小(S2=14.48%,S3=14.84%),采用两种填补方法得到的总死亡频率估计值和删除法的结果都比较接近,填补次数增大对结果影响不大。对于二分类变量,有研究者认为一般不必进行填充,缺失较少时采用成组删除法简单易行、准确高效,但是当缺失率较大(缺失率>40%)时,为满足数据分析的需要,有时可以根据数据缺失机制或模式选用不同方法进行填充[5]。本文由于缺乏模拟数据的研究结果,尚无法得出该结论。
在随访研究中,由于研究周期较长,往往后续随访调查数据的缺失较为普遍,而生存时间和结局变量由于其在生存分析中的重要作用不可或缺,数据缺失较大时对结果的影响较大,有必要对实际资料结合缺失模式和缺失机制,采用相应的数据填补方法进行填补。MI法由于其填补效果高、参数估计结果更稳定和接近真值[8],而越来越受到国内外广大研究者的关注和推崇。目前,SAS9.3已经将MI和MIANALYZE作为两个正式过程纳入其中[9],并且增加了FCS方法用于不同类型多变量条件下的各种缺失数据填补,进一步丰富了MI填补的方法选择。
1.Abraham,Todd W,Russell,et al.Missing data:a review of current methods and applications in epidemiological research.Current Opinion in Psychiatry,2004,17(4):315-321.
2.James M,Robins,Wang N.Inference for imputation estimators.Biometrika,2000,87(1):113-124.
3.Little RJ,Rubin DB.Statistical Analysis with Missing Data.New York:John Wiley&Sons,1987.
4.张桥,李宁,张秋菊,等.任意缺失模式缺失数据不同填补方法效果比较.中国卫生统计,2013,10(35):690.
5.茅群霞.缺失值处理统计方法的模拟比较研究及应用:硕士毕业论文.
6.花琳琳.施念,杨永利,等.不同缺失值处理方法对随机缺失数据处理效果的比较.郑州大学学报:医学版,2012,47(3):315.
7.Combining Inferences from Multiple Imputed Data Sets.SAS/STAT 9 User′s Guide,North Carolina:SAS Institute Inc,2002:211-213.
8.Schafer JL,Maren kO.Multiple imputation for multivariate missing-data problems:a data analysis's perspective.Multivariate Behavioural Research,1998,33:545.
9.http://support.sas.com/rnd/app/stat/procedures/mi.html.
(责任编辑:郭海强)
Multiple Imputation Method Used in Arbitrary Missing Follow-up Data
Zou Liling,Wu Juanli,Li Jue(Department of Preventive Medicine,Medical School,Tongji University(200092),Shanghai)
ObjectiveTo evaluate the multiple imputation effect of different imputation methods in arbitrary missing data of follow-up research.MethodsUsing different methods including Markov chain Monte Carlo(MCMC),Regression,discriminant analysis and logistic regression and SAS9.3/MI process,to make the comprehensive analysis and comparison for missing values imputation.The real data come from a6 years follow-up research including peripheral arterial disease patients′information and ankle brachial index(ABI)data.ResultsIncluding population parameters estimation and statistics inference of continuous variables,frequency calculation of classified variables,based on different imputation methods and imputation numbers.ConclusionIn the continuous variables such as survival time,Regression method has the largest imputation efficiency,and the efficiency increases with the increase of imputation number and decrease of the missing rate.
Multiple imputation MI;Arbitrary missing model;Missing data;Follow-up study
*国家自然科学基金青年项目(81102203/H2611)
△通信作者:邹莉玲,E-mail:zouliling_59@tongji.edu.cn
