一种可自由配置的网页采集系统原理及其实现
2015-03-07李营那张瑜
李营那 张瑜
摘要:随着信息技术的发展,互联网已成为信息发布和获取的主要渠道,大数据环境下,信息就是资源、竞争力,如何从互联网中发现并获取有效的信息已成为各行业亟待解决的问题。该文提出了一种可自由配置的网页采集系统的原理及其实现,该系统可高效采集用户所需信息,并对网页内容进行清洗,提供多种可视化的内容展示,解决了用户获取信息的难题。
关键词:网络爬虫;内容抽取;自由配置
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)35-0133-03
Abstract: With the development of information technology, the Internet has become the main channel of publishing and achieving information and data. In a BIG DATA environment, the information is the resources and competitiveness, how to find and obtain effective information from the Internet has become an urgent problem for the industry. This paper presents the principle and realization of a free configuration web page collection system. The system can effectively collect the information for the users and clean the contents of the web and provide a variety of visual display.
Key words: web spider;content extraction;free configuration
1 背景
信息技术的飞速发展,互联网已成为人类发布和获取信息最重要的途径,互联网中的信息呈现爆炸性的增长、快速更新的特性。大数据被普遍提出的时代,各学者和工程人员面临的最大问题是数据从何处来?最大的数据源是互联网,如何从互联网中发现并获取用户需求的信息已成为亟待解决的问题。搜索引擎应运而生,通用搜索引擎百度、Yahoo和Google等作为辅助用户检索信息的工具成为用户访问互联网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性:返回内容杂乱、不能及时应对互联网展现形式的变化、难以支持根据语义信息提出的查询。
为解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问互联网上的网页与相关的链接,获取所需要的信息[2]。本文提出一种可自由配置的网页采集系统的原理及其实现,该系统提供了灵活、自由的网页采集配置方法,并对网页内容进行有效清洗,为用户提供了高质量的信息。
2 相关技术
2.1 网络爬虫
网络爬虫是捜索引擎抓取系统的重要组成部分,目标是将互联网上的网页下载到本地,基本工作流程如图1所示:
1)选取URL作为待采集的种子,将这些种子URL放入待抓取URL队列;
2)从待抓取URL队列中取出待抓取URL,通过HTTP连接下载URL对应的网页,同时存储在已下载网页库,并将这些URL放进已抓取URL队列;
3)从新下载的网页中分析新的URL,并其放入待抓取URL队列;
4)重复执行第2、3步,直到待抓取URL队列为空。
网络爬虫过程中待抓取队列中URL的排列顺序决定了抓取策略,最常见的抓取策略有以下几种。
深度优先遍历策略,采用深度优先算法思想,从起始页开始,逐层处理一条线上的所有链接,处理完一条线路之后再转入下一个起始页,继续跟踪链接。
广度优先遍历策略,采用广度优先算法思想,将最新下载的网页中发现的新链接直接插入待抓取URL队列尾部;即会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页;
反向链接数策略,反向链接数指一个网页被其他网页链接指向的数量,表示了一个网页的内容受到其他人的推荐程度;搜索引擎的抓取系统通常会使用这个指标来评价一个网页的重要程度,进而决定网页的抓取顺序;
Partial PageRank策略,借鉴了PageRank算法的思想,即将下载的网页与待抓取队列中的URL形成一个网页集合,计算每个页面的PageRank值,将待抓取队列中的URL按照PageRank值排列,并按照该顺序抓取页面;
OPIC策略,该算法实际上也是对页面进行一个重要性打分;在算法开始前,给所有页面一个相同的初始现金(cash),当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空;对于待抓取URL队列中的所有页面按照现金数进行排序;
大站优先策略,对于待抓取队列中的所有网页,根据所属的网站进行分类,对于待下载页面数多的网站,优先下载。
2.2 内容抽取
网页通常包含部分无用的噪声信息,如导航栏、广告、外部链接等,在进行网页内容抽取时要除去这些噪音,只保留有用的正文信息。
一种方法是从网页的HTML DOM树中自动生成模板的技术,这种方法通常假设所有的网页都使用相同的模板生成,同时抽取的网页必须是一个集合[1];因此,在使用范围方面受到了限制。
另一种做法是基于统计的方法[5],这种方法基于网页中正文部分的文本密度比其他部分明显大的假设,定义了一个名为“文本-标签比例(Text-to-Tag Ratio)”的指标:首先计算每一行的文本-标签比例,然后使用聚类算法区分正文内容部分与其他部分。
3 系统设计实现
3.1 系统总体功能模块设计
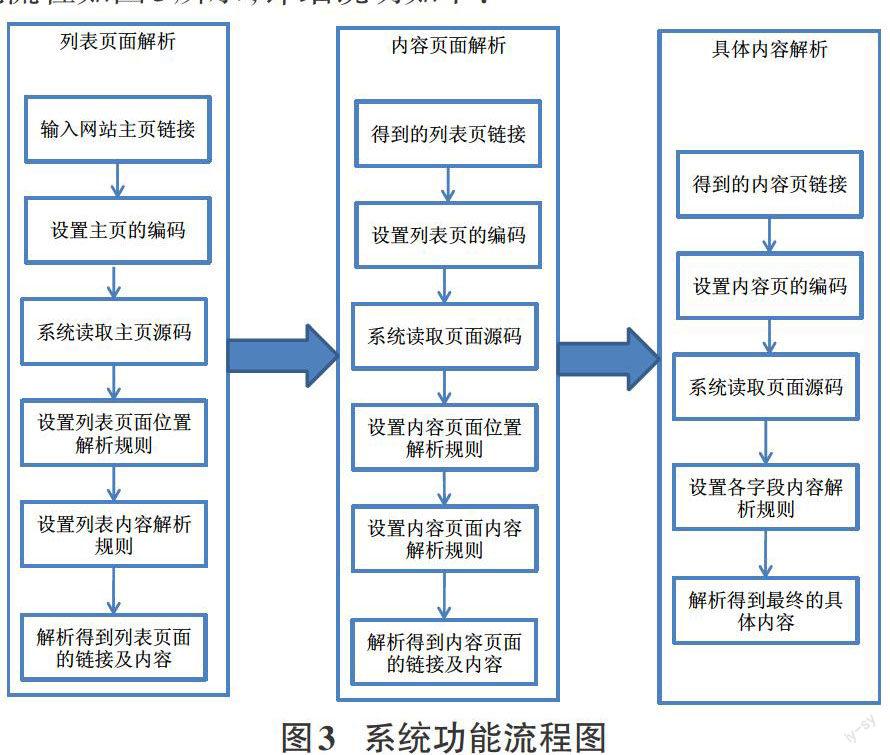
对于大多数据的新闻网站抽取,采集过程通常可以分为列表页面链接解析、内容页面链接解析和具体内容解析三大步骤,相应的配置过程也主要分为列表页面链接解析配置、内容页面链接解析配置和具体内容解析配置三大模块。系统的功能流程如图3所示,详细说明如下:
1)列表页面链接解析配置。给定一个网页的主页地址或列表页面的入口地址,需要从此地址中解析出列表页面的链接列表。通常,解析链接列表时需要得到列表的名称及列表页面的URL链接。首先,用户配置好网站的主页链接,并设置主页所使用的编码,系统自动读取页面的源码;接下来,用户需要配置列表页面链接的抽取规则,通常首页确定链接的位置,然后设置具体的抽取解析规则;系统依据用户的配置,即可实现列表页面链接的抽取。
2)内容页面链接解析配置。内容页面链接解析的主要目标为内容页面的标题,部分网站的内容链接列表页面还包括发布时间等信息,则也需要一同抽取。从第(1)步获得的列表页面链接中,在用户设置好列表页面的编码后,系统自动读取页面的源码;用户接下来配置内容页面链接的位置及内容解析相关信息,然后系统依据用户的配置解析得到内容页面的链接URL及配置的其他需要解析的信息。
3)具体内容的解析配置。对于新闻页面而言,具体内容的抽取目标包括标题、来源、发布时间、作者和具体的新闻内容。用户首先设置内容页面的源码,系统依据URL和编码读取页面的源码返回后,用户需要分别对解析的内容进行相关的配置,最后系统依据用户的配置完成所需要内容字段的抽取。
3.2 系统实现
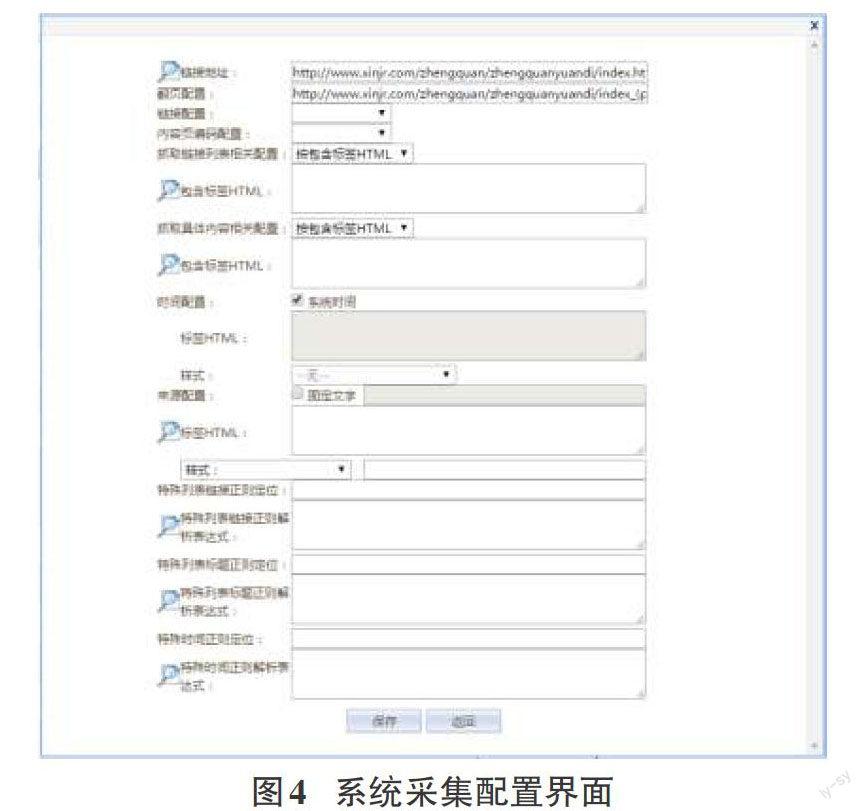
从主页面解析列表页面的过程相对简单,其所使用的技术都包含在后两步中,因此,此处以后面两个步骤为例说明系统的具体实现。系统最终的功能界面如图4所示,具体实现的过程在以下小节中详细进行介绍。
3.2.1 编码设置
编码设置:中文网页的编码通常只有常见的UTF-8、GB2312、GBK几种,由于GBK中包含了GB2312,因此,在系统中仅需要用户选择UTF-8和GBK两者中的一种即可。
3.2.2 目标块的位置确定
目标块(列表页面链接、内容页面链接、具体内容)的位置设置通常有以下几种方式:包含标签的XPath、包含标签的ID、包含标签的CSS Class、包含标签的源码内容和包含标签前后代码。
1)包含标签的XPath:HTML网页可以解析成DOM树的形式,其中的内容在整个DOM树中是有一定的位置的,通常把这一个位置称为XPath;XPath在网页中是唯一的,因此通过它可以定位到标签;
2)包含标签的ID:在HTML页面中,HTML标签可以设置唯一的ID,因此,通过标签的唯一ID也可以定位到相应的标签;
3)包含标签的CSS Class:在使用CSS技术的网页中,标签通常会设定Class名,这一名称虽然不一定是唯一的,但如果设置的目标标签在网页中具备唯一的CSS Class,则也可以通过设置它来定位标签;
4)包含标签的源码:每个HTML标签都可以带有一些属性,例如前面提到的ID和CSS Class,那么,把标签的全部源码都利用起来,在大多数情形下也可以标识一个标签,因此也可以用来进行标签定位。
5)包含标签前后代码:使用标签前后代码片断,即包含目标标签的HTML代码,只要保证在整个网页中是唯一的,也可以用于定位标签。
在上述5种方案中,使用XPath通常比较专业和复杂,需要相应的工具配合才能完成,但它的优势是XPath标识的标签一定是唯一的,因此几乎可以用于全部情形。其它方式相对比较简,但有时却不一定能达到目的,比如时,目标标签正好没有ID时,则使用标签ID的方式便无法达到目标。
3.2.3 解析匹配规则
上一小节通过定位可以确定目标的位置,解析匹配是指得到具体的,比如得到列表页面的链接。用于解析匹配的方式通常有:固定模式、前后缀模式、包含模式和正则表达式模式。固定模式是指内容是固定的文字,比如说来源字段,对于一个网站,我可以统一指定固定来源;前后缀模式是批解析的目标可以通过前缀或者后缀来标记,例如作者字段,通常使用“作者:***”的形式描述,此时通前缀“作者:”即可得到后述内容为解析的目标;包含模式是指可以如上一小节一样指定特定的HTML标签来确定解析的目标,不同之后在于此处可以指定非HTML标签形式的包含;正则表达式形式,顾名思义即指使用正则表达式来确定目标,例如日期可以使用正则表达式“\d{4}\-\d{2}\-\d{2}”来确定。
4 结束语
网页采集与内容抽取是获取互联网内容的关键,本文提出的可自由配置的网页采集系统以灵活、简洁、易操作的方式为用户提供了一种高效获取互联网中优质信息的方法,解决了用户面对大量信息无法使用的窘境。本文详细介绍了网络爬虫中爬虫器的实现、网页内容的抽取关键技术及方法,为其他相关研究人员提供借鉴。
参考文献:
[1] Ji X W, Zeng J P, Shang S Y, et al. Tag Tree Template for Web Information and Schema Extraction[J]. J. Expert Systems with Applications, 2010(37): 8492-8498.
[2] 周立柱, 林玲. 聚焦爬虫技术研究综述[J]. 计算机应用, 2005, 25(9):1965-1969.
[3] 刘金红, 陆余良. 主题网络爬虫研究综述[J]. 计算机应用研究, 2007, 24(10): 26-29.
[4] 周德懋, 李舟军. 高性能网络爬虫:研究综述[J]. 计算机科学, 2009, 36(8): 26-29.
[5] 游贵荣, 陆玉昌. 基于统计和机器学习的中文Web网页正文内容抽取[J]. 福建商业高等专科学校学报, 2009(2): 68-72.
