基于One-R的改进随机森林入侵检测模型研究
2015-03-07胡学钢杨秋洁
王 翔, 胡学钢, 杨秋洁
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.安徽省科学技术情报研究所,安徽 合肥 230011;3.中国银行安徽省分行,安徽 合肥 230061)
随着网络安全问题的日益突出,入侵检测作为主动式动态防御方式正起着传统方式如防火墙等无法达到的作用。从数据挖掘的角度看,入侵检测就是对数据的分析过程,分类技术作为数据挖掘的热门自然成为入侵检测研究的关键[1]。
分类算法是一种有监督学习的算法,入侵检测领域常用的分类算法有贝叶斯、决策树、支持向量机、神经网络[2]、粗糙集等,其中应用广泛的有C4.5算法[3]、随机决策树[4]、RIPPER、朴素贝叶斯[5]、贝叶斯网络、SVM等。入侵检测所处理的网络审计数据具有高维海量、冗余、不相关属性多、入侵种类多等特点,使得上述分类模型易出现过拟合现象、算法时空性能不高、对各种入侵攻击检测不均衡等问题。
文献[6]提出的随机森林(random forest,RF)算法对数据的适应能力强,不易出现过拟合现象,时空开销较小,有较高的分类准确率。由于入侵检测审计数据具有较多不相关属性,RF选择属性时易出现过度随机现象,即由于选择属性的随机性导致元分类器分类性能不高,从而影响RF模型的检测效率。本文提出一种基于One-R快速属性评价的改进RF模型(1R-RF),在进行入侵检测时,通过One-R对属性排序,将最大相关属性提供给RF模型进行选择,使不相关属性的影响最小化,显著提高了算法的抗干扰能力。这使得1R-RF在保持RF模型优点的基础上,与经典入侵检测分类方法相比,具有较好的抗过拟合性能、更好的分类准确率与时空性能。
1 RF与One-R算法
1.1 RF算法与改进
随机森林(RF)是树型分类器 {h(x,βk),k=1,2,3,…}的集合,其决策结果是通过类似多数投票法来确定,它的基础分类器h(x,βk)通常采用没有剪枝的CART决策树。
具体算法描述如下:
(1)选取训练集。RF算法抽取训练集方法与Bagging中的方法类似,即如果需要构建K个基础分类器,则对数据集作K次抽样(每次抽样均为随机且不放回)。
(2)构建RF模型。如果训练数据有M个属性,则指定1个属性数F≤M,从M个属性中随机抽取F个属性作分类属性集,一般采用CART方法构建单棵决策树(基础分类器),使每棵决策树尽量地生长,不进行任何剪枝。
(3)投票。RF作为集群分类器,其决策结果采取多数投票法,所构建的K棵决策树将对某条数据进行分类,最后做多数投票,得票最多的结果,将作为RF的最终输出结果。对于得票一致的结果,通常随机选取一个作为最终的结果。
从算法中可以看出,随机森林采用2次随机的方法使判定结果不易出现过拟合现象,同时具有较好的抗噪性能。这2次随机分别为:① 对单棵决策树随机选取训练数据,并且不做任何剪枝,一定程度上避免了单棵树的过拟合;② 对整体而言,每次均随机地选取属性子集构建决策树,一定程度上提升了抗噪性。
文献[7]中对K的选取进行了大量实验验证,得出当RF基分类器个数K=10时,RF具有很好的精度且可信度超过99%。同时,有研究表明[7],当随机抽取的属性数F取值为M/2时,RF算法时空性能与分类精度有着最好的表现。除了常规入侵检测分类器的评判标准如分类精度、误分类率、漏报率及时空性能之外,RF算法还有其特殊的评判标准,即RF的泛化误差,其定义如下:
(1)样本间隔点函数(margin function)[6]。
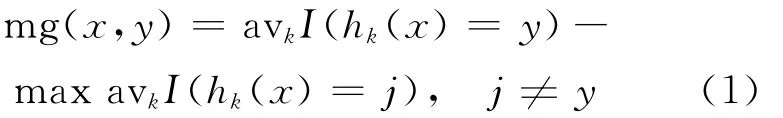
其中,x为输入;y为对应的输出;avkI(hk(x)=y)为对N棵元决策树求平均。mg(x,y)越大,表明RF对该样本分类性能越好。
(2)RF的泛化误差。
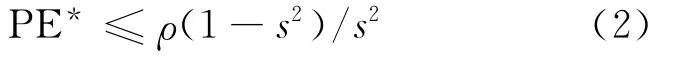
其中,ρ为分类器集合{h(x,θ):θ}∈Θ间的相关度;s=Ex,y(mg(x,y))。
虽然RF方法有着较好的性能,但由于入侵检测所处理的审计数据具有较多的冗余及不相关属性,特别是与决策属性不相关的属性,如果用于构建RF将导致分类正确率的不稳定。有研究表明,树与树之间的相关性越大,则RF分类精度越差,如果能保证选取属性的相对独立性,则RF分类算法的表现有可能提升。为了提高RF模型的入侵检测正确率,特别是对各种入侵行为检测的均衡性,本文采用One-R思想指导RF选择属性的过程,避免选择对分类结果不相关的属性。
1.2 One-R算法
One-R算法是文献[8]提出的一种经过证明的、并不需要复杂的规则就可以得到较好分类精度的算法,大量实验证明在绝大多数数据集(UCI)上One-R得到的分类规则比决策树C4算法在分类精度与时空性能方面有优势。
One-R算法基本思想描述如下:对于训练数据集中的每一个属性Ai形成一种规则,即对于属性Ai的每一个取值v选择包含有这个值的所有条目组成集合,假设C是这个集合中出现最频繁的类,则得到关于属性Ai的一个规则——如果某条记录的Ai取值为v,则该记录的类别为C。
文献[9]通过 Weka软件验证了One-R的思想,并且创造性地提出将One-R作为属性选择的方法。其主要思想是:对每个属性都使用One-R算法构建分类规则,并在训练数据集上得到每个属性对应规则的正确率,根据正确率的高低对属性进行排序。文献[9]通过大量实验表明One-R是一种高效的属性选择方法,同时它选择的属性是基于属性独立的假设,因此有可能选择出属性间相互独立的属性集合。
2 基于One-R的改进RF算法
2.1 算法描述
基于上述理论分析与实验的结果,本文提出基于One-R的改进RF算法(1R-RF)。具体算法描述如下:
(1)随机抽取训练数据且做不放回抽取,共进行K次(本算法中K=10)。
(2)每次抽取的训练数据利用One-R规则对属性进行评价,并按照One-R正确率进行正向排序,得到排序后的属性集合A= {A1,A2,A3,A4,…}。
(3)构建RF。确定CART树的规模(F值的确定),F=M/2(本算法根据入侵检测审计数据的特点,取F=20);在每次抽样的训练数据上,从属性集合A中选取排名前m的属性构建属性子集B={A1,A2,A3,…,Am},在B中随机选取属性构建单棵随机决策树,共构建10棵元决策树。
(4)对于待检测的审计记录,在10棵决策树上分别检测一遍,将得到的结果做投票,得票最多的结果作为最终的入侵检测结果。如果有多个结果票数一致,则取属于入侵行为的那个类别(入侵行为危害性远大于普通行为)。
2.2 算法分析
(1)时间性能。本算法中,构建RF的时间开销主要有属性评价时间与建树时间2部分;其中One-R仅需通过扫描训练1次即可完成属性排序;建树时间开销也由于随机选择1/2的属性而得以减少;其时空开销远小于需要多次扫描数据集和大量计算的算法,如C4.5;由于选择属性不再盲目随机,因而其随机选择属性的时间消耗也比原始RF算法有降低。
(2)分类性能。由于RF每次选择的属性并不固定,一定程度避免了模型的过拟合,并且经过One-R评价的均为与决策属性具有较好相关性的属性,因而一定程度上避免了原始RF算法过度随机选择属性造成的分类正确率不稳定现象。
(3)空间性能。由于训练数据随机不放回的抽样,加入One-R属性评价仅需要增加1个数组用于存放属性评价的结果,使得空间占用比其他决策树如C4.5算法小。
2.3 算法实验
为方便与其他分类算法比较结果,仍采用KDD Cup 99数据作为实验数据来源。分别采用从KDD Cup 99-Full490万条记录中随机抽取的3 000、10 000、50 000、200 000条记录作为训练数据,以KDD Cup 99-10percent的494 021条记录作为测试数据。将1R-RF集成到 WEKA中(WEKA是新西兰大学开发的数据挖掘实验工具集,集成了许多当前主流的数据挖掘模型,是数据挖掘领域较权威的实验环境),对比试验采用WEKA 中 的 C4.5、RF、朴 素 贝 叶 斯 NB、Bagging+C4.5算法、Boosting+C4.5,实验环境调试环境为Eclipse,WEKA的最大堆栈设置为1 400MB[10]。实验结果见表1所列,“-”号表示15min内无结果输出。
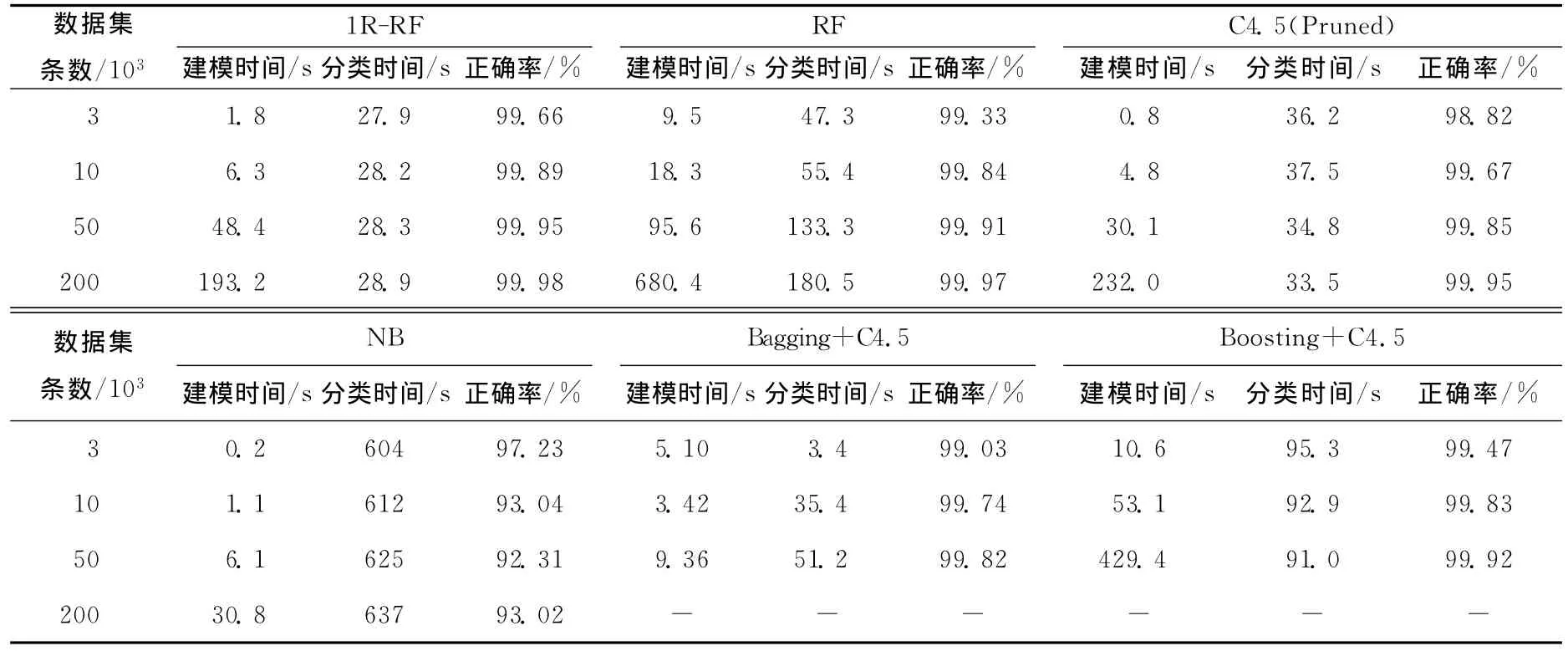
表1 1R-RF与其他分类模型的对比
由表1可以看出,本文提出的1R-RF由于避免了属性选择的过度随机,因而在整体上分类精度优于RF方法,在4个训练集上得到的分类模型分别减少了1 630、247、197、49次错判,且算法整体时间性能有一定提升。
在分类正确率方面,C4.5算法有着不错的表现,由于其属性选择采用了信息增益需要大量计算,因而时间性能较1R-RF稍差;同时,由于C4.5只建1棵树,分类正确率出现不稳定,如训练数据从3 000条增加到10 000条,分类正确率反而下降,而其他分类器均表现出随训练数据增加,测试正确率升高的趋势。
在C4.5基础上构建的集成分类方法,Bagging和Boosting均能提高C4.5的分类精度,但由于涉及额外计算带来的时空开销,其时间消耗比1R-RF差,且由于单棵树精度提升有限,2种集成分类器精度均不如采用多棵树的1R-BF。
朴素贝叶斯仅需扫描数据1次就能得到概率表,简化了分类器构建的计算,但是分类时需进行大量额外计算,整体时间性能较差,同时由于条件独立假设的限制,分类正确率比其他算法略低。
为了进一步体现1R-RF对RF的改进效果,本文比较了两者对各种攻击的漏报次数与误报次数,如图1所示,其中的数据同上一实验。
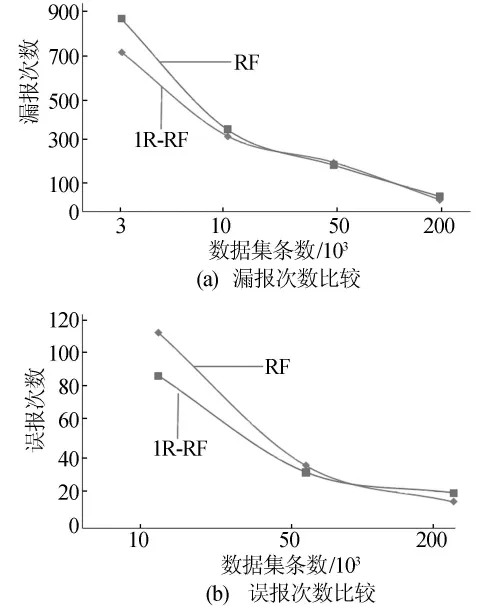
图1 漏报、误报次数比较
从图1可以看出,1R-RF在3个数据集上的结果优于RF,并在另外一个数据集上非常接近RF模型;已有文献说明误报率与漏报率通常成反比关系,由于1R-RF增加了对入侵行为的检测率,使得对于正常访问的误报次数增加。即便如此,相对于 KDD Cup 99-10percent数 据集中97 278条正常访问记录来说,这些略微增加的误报是可以接受的。由于本次实验所选取的3 000、10 000、50 000、200 000条记录是随机获得的,分析数据后,小数据如3 000、10 000、50 000没有覆盖所有的入侵种类,这在一定程度上造成了漏报率的增加。为了更公平地比较1R-RF与RF,本文选择在包含所有入侵种类的训练集(200 000条记录)上得到的2个模型,结果见表2所列。

表2 各种入侵漏检率与误检率
由表2看出,对于U2R,R2L这2种危害较大的应用层攻击1R-RF有着比RF更高的检测率,分别提升了50%与44%;同时1R-RF误检次数比RF误检次数减少了26%。
为了衡量1R-RF模型的性能,除了上述实验对比外,本文还引入了一种需要大量计算的K-折交叉验证的标准——OOB,它是RF泛化误差的一个无偏估计,数值越小说明模型性能越好。其计算方法为:对每颗树利用未被该树选中的训练样本点,统计该树的误分率;将所有树的误分率取平均得到RF的OOB误分率。在4个训练数据集上比较1R-RF与RF模型,结果如图2所示。
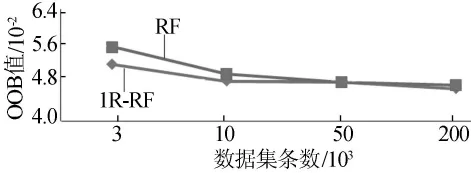
图2 OOB结果
由图2可以看出,在3个训练数据集上得到的1R-RF模型优于RF模型,在1个数据集上接近RF模型。通过实验对比可知,1R-RF模型有着比RF、C4.5以及基于 C4.5的集成分类器Bagging和Boosting更好的分类精度与时间性能。与传统RF模型相比,1R-RF有更低的泛化误差,特别是针对危害大的应用层攻击R2L与U2R,本文的1R-RF模型有更好的检测精度。
3 结束语
本文以RF为模型,展开了入侵检测分类模型的研究,通过引入One-R思想指导RF选择属性,提升了元决策树的分类能力,避免了由于属性选择过度随机造成的分类精度下降的问题;同时由于属性选择不再盲目随机,使得构建树的过程更加迅速。实验结果表明,1R-RF在判别入侵行为时有着非常高的分类精度,时间性能也比入侵检测常用分类模型好,与传统RF模型相比,1RRF有更低的泛化误差、更好的时间性能、更高的分类精度,对各种入侵行为的检测率也较均衡。
[1] Mao Guojun,Wu Xindong,Jiang Xuxian.Intrusion detection models based on data mining[J].International Journal of Computational Intelligence Systems,2012,5(1):30-38.
[2] Behjat A R,Vatankhah N,Mustapha A.Feature subset selection using genetic algorithm for intrusion detection system[J].Advanced Science Letters,2014,20(1):235-238.
[3] Stein G,Chen Bing.Decision tree classifier for network intrusion detection with GA-based feature selection[C]//Proceedings of the 43rd annual Southeast Regional Conference,Vol 2.ACM,2005:136-141.
[4] 郭山清,高 丛,姚 建,等.基于改进的RF算法的入侵检测模型[J].软件学报,2005,16(8):1490-1498.
[5] Benferhat S,Tabia K.On the combination of naive Bayes and decision trees for intrusion detection[C]//International Conference on Computational Intelligence for Modelling,Control and Automation.IEEE Computer Society,2005:211-216.
[6] Breiman L.Random forests[J].Machine Learning,2001,45(1):5-32.
[7] Fan Wei,Wang Haixun,Yu P S,et al.Is random model better?On its accuracy and efficiency[C]//International Conference on Data Mining.IEEE,2003:51-58.
[8] Holte R C.Very simple classification rules perform well on most commonly used datasets[J].Machine Learning,1993,11(1):63-91.
[9] Holmes G,Nevill-Maaning C G.Feature selection via the discovery of simple classification rules[EB/OL].(1996-08-01).http://www.cs.waikato.ac.nz/~ ml/publications/1995/.
[10] 杨秋洁,胡学钢.一种属性选择方法FS-IV的研究[J].合肥工业大学学报:自然科学版,2010,33(12):1811-1814.
