检索质量评价标准的研究与实例分析
2015-03-06胡新海
胡新海
(陇南师范高等专科学校 数信学院,甘肃 成县 742500)
检索质量评价标准的研究与实例分析
胡新海
(陇南师范高等专科学校 数信学院,甘肃 成县 742500)
随着web2.0进一步推广与应用,广大用户通过网络查询所感兴趣的信息时都要借助搜索引擎来实现,但在搜索结果中有些是与用户所查询的信息相关的,有些信息是无关的,那些无关的信息在一定程度上影响了用户的搜索体验。通过对精确率与召回率等指标与实例的分析,在搜索系统推出结果之前,对性能进行测评,如果效果不够理想,则重新研究设计和改进搜索技术,以期达到理想的搜索性能。
搜索质量;评价标准;P@10指标;MAP指标;实例分析
0 引言
随着网络的普及与应用,网上的海量数据信息急剧增长。网民面临的问题不是信息不够,而是如何快速找到自己所感兴趣的信息。搜索引擎是一种广为使用的信息检索工具,但是通过搜索引擎检索的信息往往与用户的需求不完全一样,这其中一个主要原因就是搜索引擎将检索的信息推出之前,对检测效果的性能进行了评测[1]。评测时,除了时间和空间等运行效率方面的评测外,更重要的是对搜索结果质量进行评测[2-4]。
目前,广大用户使用搜索引擎仍然存在不少局限,其主要原因是搜索引擎只是简单的利用用户给予的关键词,利用关键词机械地匹配来实现[5-7],如果用户给予的关键词不准确,那么用户肯定就检索不到自己所需要的信息。搜索引擎缺乏知识处理能力和理解能力,要达到理想的搜索效果,必须在将检索的信息推向用户之前,研发人员可以根据测试结果选择效果较好的搜索技术,或验证搜索系统在真实环境中运行时的实际效果,以辅助系统不断进行设计、研究和改进。因此搜索系统的性能评测对于系统的研制和发展是至关重要的。
1 搜索性能的评价指标与实例
1.1 精确率与召回率
评价搜索结果质量,最广为接受的评价标准是用精确率和召回率这两个指标来评价搜索质量[8-10]。
给定一个固定的用户搜索请求,搜索系统将系统认为和用户请求相关的文档返回给用户。对于这次搜索行为,可以根据两个维度来将所有文档构成的集合划分成4个互不相交的子集(参考图1)。一个维度是:“该文档是否与用户发出的搜索请求相关”,由此维度,可以将整个文档集合划分为相关与不相关两种类型,图1中的第1列表示相关文档,第2列表示不相关文档;第2个维度是:“文档是否在本次搜索结果列表里”,由此维度,可以将整个文档集合划分为“在本次搜索结果列表”与“不在本次搜索结果列表”两种类型,图1中的第1行表示本次搜索结果包含的文档列表,第2行表示集合中不在本次搜索结果列表中出现的其他文档。
将以上两个划分维度组合,把文档集合切割为4个互不相交的子集。如图1所示坐标中,左上角的子集代表“在本次搜索结果中与搜索请求相关”的文档,假设集合大小为N;右上角的子集代表“在本次搜索结果中与搜索请求不相关”的文档,假设集合大小为M;左下角的子集代表“在本次搜索结果之外与搜索请求相关”的文档,即那些本来应该由搜索系统返回但因为算法原因没有找到的相关文档,假设集合大小为K;右下角的子集代表“在本次搜索结果之外且与搜索请求无关”的文档,假设集合大小为L。
在将文档集合划分为4个子集的基础上,我们可以对精确率和召回率进行定量描述,得出两个指标的计算方法。
所谓精确率,就是本次搜索结果中相关文档所占的比例,分子为本次搜索结果中的相关文档(即图1中的左上角子集),分母为本次搜索结果包含的所有文档(即图1中的第1行),两者相除得到精确率。
(1)
所谓召回率,即本次搜索结果中包含的相关文档占整个集合中所有相关文档的比例,分子与精确率分子相同,即本次搜索结果中包含的相关文档,分母为整个文档集合所包含的所有相关文档(即图1中的第1列),两者相除得到召回率。
(2)
这表示在所有集合中相关文档的总量中分类正确的相关文档的数量。例如,10个文档集合中的5个是分类正确的文档,Recall就是正确分类的文档集合数量和分类正确总数的商数。
召回率用于评价搜索系统是否把该找出的文档都找出来了。
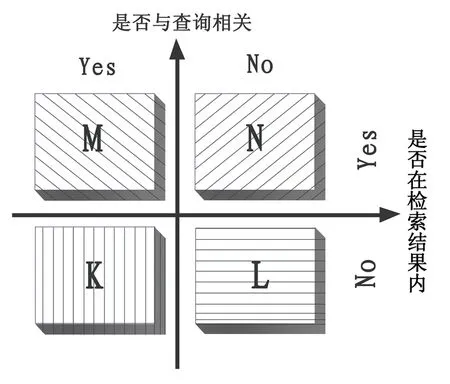
图1
精确率和召回率是常见的评估检索系统的指标[11],但是对于捜索引擎来说,精确率更为重要,因为搜索引擎处理海量数据,一方面在这种环境下,对于某个査询,找到与这个查询相关的所有文档(也即计算召回率公式的分母)难度很大,导致召回率很难准确计算;另一方面由于数据量比较大,所以能够满足用户需求的文档量也很大,用户很少需要看到所有相关文档,往往是看到一部分即可满足搜索需求,全部召回相关文档对于满足用户需求意义也不是特别重要。而相对应地,精确率在搜索引擎场景下就非常重要了,因为排在搜索列表前列的搜索结果如果有太多不相关的内容,直接影响用户体验,所以对于搜索引擎质量评估来说,往往更加关注精确率。
上面介绍的精确率和召回率的计算方法只是通用的计算框架,在具体评估时,需要做更加精细的考虑。常用的评估搜索引擎精度的指标有P@10和MAP。
1.2 P@10指标
P@10指标更关注搜索结果排名最靠前文档的结果质量,它用于评估在捜索结果排名最靠前的头10个文档中有多大比例是相关的[12-14]。计算P@l0的公式3所示:
(3)
图2是P@l0计算的一个示例,打对钩的文档代表与用户査询相关,叉号代表无关。在这个例子中,头10个文档中包含了6个相关文档,所以其精度为0.6。

图2 文档相关性
计算过程如下:
1.3 MAP指标(Mean Average Precision)
MAP指标是针对多次查询的平均准确率衡量标准,是评价检索系统质量的常用指标,如果习惯阅读信息检索相关学术论文的话,会经常在论文中遇到这个评价指标。
要了解MAP,首先需要了解AP(Average Precision)。MAP是衡量多个査询的平均检索质量的,而AP是衡量单个查询的检索质量。计算AP的公式4所示:
(4)
图3是如何计算某次检索的AP得分的示意图。例子中假设与用户查询相关的文档有3个,经过搜索系统输出后,分别排在搜索结果的第2位、第4位和第6位,如果是一个理想的搜索系统,理论上应该将这3个文档排在第1位、第2位和第3位,所以用这3个文档的理想排名位置除以实际排名位置,会得到每个文档的得分,3个文档求平均值得到本次搜索的AP值0.5。AP值越高,则意味着越接近理想的搜索结果,说明检索系统质量越好。如果例子中的3个相关文档分别处于搜索结果的第1位、第2位和第3位,那么AP值为1,这就是理想的搜索结果。AP指标兼顾了排在前列结果的相关性和系统召冋率,这是为何被经常采用的原因。
其中AP计算过程如下:
AP是针对单次査询的衡显指标,如果存在多组査询,那么每个査询都会有自己的AP值,对这些査询的AP值求平均值,就得到了MAP指标。
2 结束语
本文通过精确率与召回率,P@10和MAP指标三个测评性能指标的研究与实例的分析,探讨在改进搜索过程中,选择一种或多种方法结合对搜索结果测评,如果效果不够理想,则重新研究设计和改进搜索技术,以期达到理想的搜索性能[15-16]。推出较为理想的搜索技术,提高搜索的质量,用户搜索到的信息才是值得信赖且有意义的,从而才能获得满意的搜索结果。
[1] 方洁.搜索引擎及其性能改进方法研究[J].软件导刊,2014,13(12):41-43.
[2] Franzen K,Karlgren J.Verbosity and interface design[J].SICS Research Report,2000,1(1):1-5.
[3] Wu S,McClean S.Result merging methods in distributedinformation retrieval with overlapping databases[J].Information Retrieval,2007,10(3):297-319.
[4]DaiHK,ZhaoL,NieZ,etal.DetectingOnlineCommercialIntention(OCI)[C]//Proceedingsofthe15thInternationalConferenceonWorldWideWeb.Berlin:SpringerBerlinHeidelberg,2006:829-837.
[5]BroderA.Ataxonomyofwebsearch[J].ACMSigirForum,2002,36(2):3-10.
[6]HaveliwalaTH.Topic-sensitivepagerank:acontext-sensitiverankingalgorithmforwebsearch[J].IEEETransactionsonKnowledgeandDataEngineering,2003,15(4):784-796.
[7]WuS,McCleanS.Performancepredictionofdatafusionforinformationretrieval[J].InformationProcessing&Management,2006,42(4):899-915.
[8]BingLi.Web数据挖掘[M].俞勇,薛贵荣,译.北京:清华大学出版社,2009.
[9] 李超,谢坤武.多搜索引擎权重计算及搜索结果排序质量评估[J].计算机工程与应用,2014,50(12):21-25.
[10]WuS,McCleanS.Improvinghighaccuracyretrievalbyeliminatingtheunevencorrelationeffectindatafusion[J].JournaloftheAmericanSocietyforInformationScienceandTechnology,2006,57(14):1962-1973.
[11] 李稚楹 .基于网页内容和时间反馈的网页排序PageRank算法研究[D].重庆: 重庆理工大学,2012.
[12] 张俊林.这就是搜索引擎:核心技术详解[M].北京:电子工业出版社,2012:125-128.
[13]KhareR,CuttingD,SitakerK,etal.Nutch:aflexibleandscalableopen-sourcewebsearchengine[EB/OL].[2013-06-20]http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.105.5978&rank=1.
[14]GuoF,LiuC,WangYM.Efficientmultiple-clickmodelsinwebsearch[C]//ProceedingsoftheSecondACMInternationalConferenceonWebSearchandDataMinin.NewYork:ACMInc,2009:124-131.
[15]AgichteinE,BrillE,DumaisS.Learninguserinteractionmodelsforpredictingwebsearchresultpreferences[C]//Proceedingsofthe29thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.NewYork:ACMInc,2006:3-10.
[16]MengWeiyi,YuC.Buildingefficientandeffectivemetasearchengines[J].ACMComputerSurveys,2002,34(1):48-89.
(责任编辑:尹晓琦)
Retrieval Research and Case Analysis of the Quality Evaluation Criteria
HU Xin-hai
(School of Mathematics and Information, Longnan Teachers College, Chengxian Gansu 742500, China)
With further application of web 2.0, user information queries of interest are generally relied over the network using a search engine. Some search results are related to the information on user request, but other irrelevant information to a certain extent affect the user's search experience. Through precision and recall ratio to search systems before introducing the results, searching performance were evaluated, and if the results were less than ideal, the search technology would be re-examined and redesigned in order to achieve the desired search performance.
search quality; evaluation criteria; P@10 indicators; MAP indicators; case analysis
2015-03-25
陇南师范高等专科学校校级科研项目(2014LSZK02006)
胡新海(1977-),男,甘肃西和人,讲师,硕士,主要从事数据挖掘与云计算研究。
G202
A
1009-7961(2015)03-0014-03
