基于NMF和一致性学习的半监督分类算法
2015-03-05辽宁工业大学电子与信息工程学院孙福明蔡希彪
辽宁工业大学电子与信息工程学院 周 勇 孙福明 蔡希彪
基于NMF和一致性学习的半监督分类算法
辽宁工业大学电子与信息工程学院 周 勇 孙福明 蔡希彪
【摘要】为了在分类中减少数据中的冗余信息、提高分类准确率,提出一种基于非负矩阵分解与一致性学习的半监督学习。该算法首先通过非负矩阵分解(NMF)对原始数据进行有效的降维,并得到特征矩阵;然后再特征矩阵的基础上通过标签传递对原始数据进行分类。实验结果证明,NMF-LLGC算法与其他方法相比不仅能有效地减少数据的冗余信息,还能够提高分类准确率。
【关键词】非负矩阵分解;一致性学习;半监督学习
本课题得到国家自然科学基金(No.61272214,61272371)资助。
1 引言
近年来半监督学习(semi-supervised learning)[1]越来越受到研究者的关注,已发展成为机器学习[2]中的一个热门的研究领域。它能够利用标记样本和未标记样本的分布信息,增强学习性能,提高分类精度,填补了传统机器学习的不足。因此如何更好的利用未标记数据来挖掘数据的内部结构是非常有意义的。
然而,基于图的半监督学习方法更具有一般的解释性和良好的分类性能,能更好的反映及描述样本空间,解决现实生活中的许多问题。Zhou等人[3]在2004年提出局部和全局一致性学习(LLGC)算法,该算法是最具代表性的基于图的半监督学习算法。该算法不仅分类精确度高、计算速度快等优点,而且对错误标注具有一定的容错能力。在实际运用中,由于数据具有“海量性”与“高维性”等特点,从而掩盖了数据的本质特征。而且随着数据维数的增大,很容易出现“维数灾难”问题[4],这会严重影响数据分析结果。
针对以上问题,本文提出一种有效的分类算法——基于非负矩阵分解与一致性学习的半监督分类算法。该算法首先通过非负矩阵分解(NMF)对原始数据进行有效的降维,并得到特征矩阵,这样做能有效的减少数据中的噪声和不相关的特征信息;然后在特征矩阵的基础上构建邻近图,根据数据的相似性通过标签传播对原始数据进行分类。该算法不仅能够获得更高的分类精度、有效的减少数据冗余信息,而且对数据的存储和计算复杂度大大降低。
2 非负矩阵分解
NMF算法[5]是高维数据处理与分析的一种手段,已被广泛应用于各个领域。
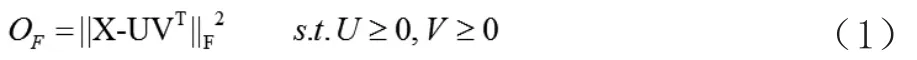
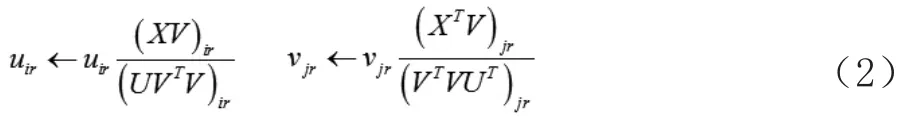
在给定迭代的终止条件后,迭代更新直到满足终止条件,最终的矩阵U和V。
3 局部和全局一致性学习算法
LLGC算法由Zhou等人[3]在2004年提出,其核心思想是根据已标记样本的类别标签预测未标记样本的类别标签,最终达到样本标签全局稳定为止。
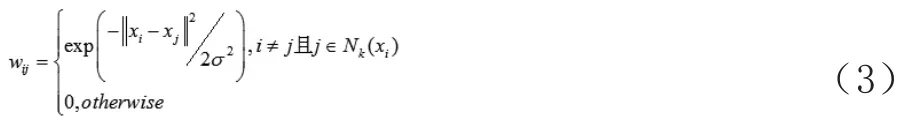
(2)最小化正则化框架:
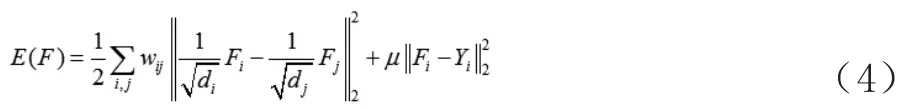
4 基于NMF与一致性学习的半监督分类算法
在实际运用中,原始数据中隐含着冗余信息,数据维数也很高,从而会影响分类器的性能和分类效果。而且随着数据维数的增大,对数据的存储和计算复杂度带来极大的困难。为了解决此类问题本文提出一种基于非负矩阵分解与一致性学习的半监督分类算法。该算法LLGC类似同样设表示为已标记样本,表示为未标记样本,并且。算法的目的是预测未标记样本的标签,其步骤描述如下:

5 实验与结果分析
为评价算法的有效性,本文选用表1所示的2个数据集作为实验对象。

表1 数据集信息
本文分别采用监督学习K 近邻(KNN)、LLGC 和NMFLLGC 算法解决表1这2个数据集的分类问题。在本实验中KNN算法中的近邻数K取为1。
随机抽取前l个数据样本组成已标记样本集,剩下的n-l个数据样本组成未标记样本集在实验过程中,为了保持公平起见维数r=312,参数a=0.99,=0.20。各数据集重复50次实验得到的分类准确率如下表2和表3所示,相对应的分类准确率的曲线如图1所示。
由表2、3及结合图1可以看出NMF-LLGC算法的分类性能优于LLGC算法和KNN算法,当标记样本数量达到一定程度时,其分类准确率将不再有明显改进。因为通过NMF可以降低原始数据结构中存在的噪声或者不相关的特征信息,充分挖掘数据信息。而且在降低冗余信息的数据基础上构建邻近图能够有效的表达数据的内在结构,使得样本的相关性增大,进一步提高了分类精度。
下面我们讨论数据维数r对分类准确率的影响。我们随机抽取前5个数据样本组成已标记样本集,参数a=0.99,=0.20,重复50次实验得到分类准确率的曲线如图2所示。
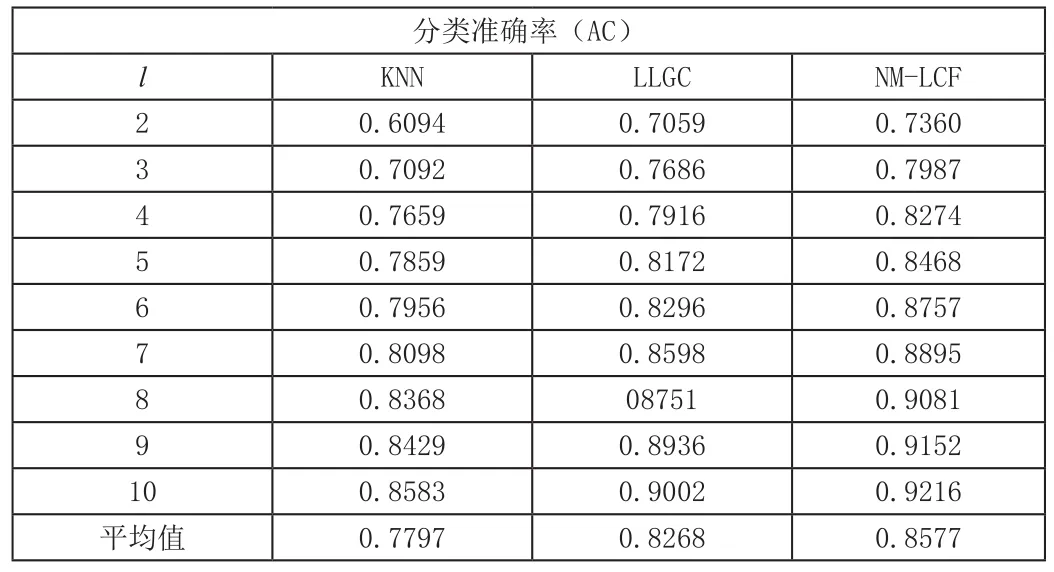
表2 不同算法在COIL20数据集上分类准确率
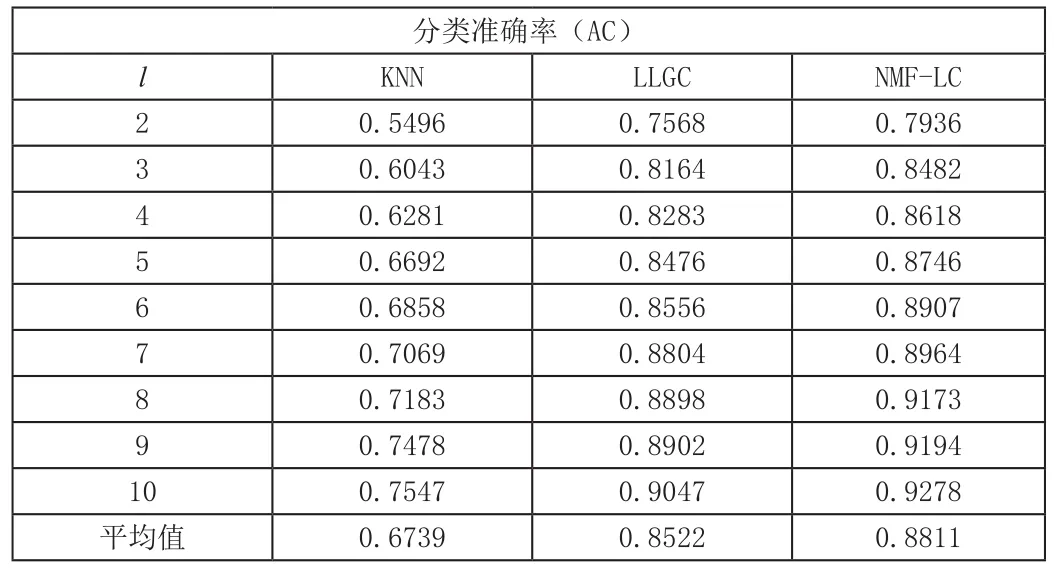
表3 不同算法在在PIE32数据集上分类准确率
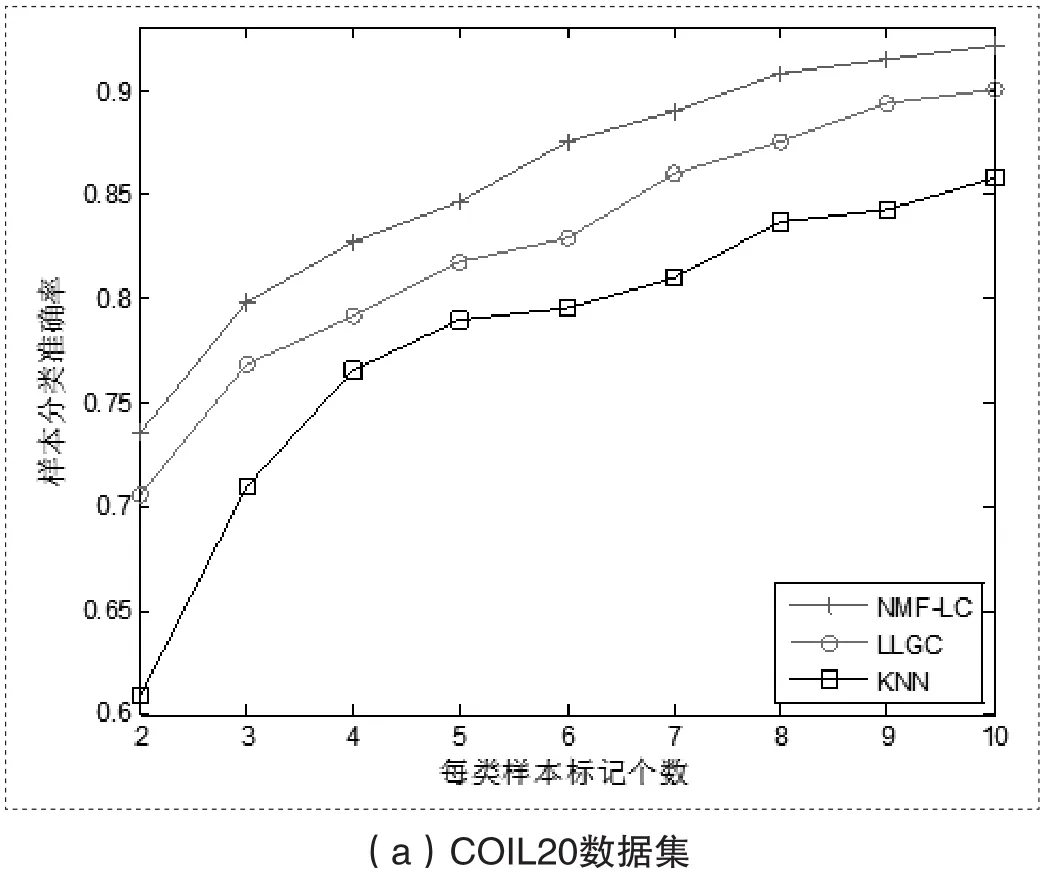
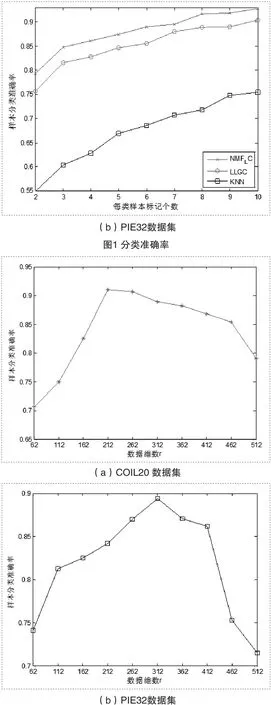
图2 降维的分类准确率
中的冗余信息,如:噪声及不相关的特征信息;降维维数较低时,可能破坏原始数据的内部结构,在构图时是数据的相似性降低,从而影响数据的分类准确率。
6 总结
本文提出了基于NMF与一致性学习的半监督学习算法,该算法秉承了半监督学习的优点。在保持良好的分类效果的前提下有效的减小数据中的冗余信息及提高分类精度,降低了数据的存储和计算复杂度。由实验结果看出,该算法性能较优易于推广,是一种非常有效的半监督分类算法。
参考文献
[1]Zhang Chenguang,Li Yujian.Hash graph based semisupervised learning method and its application in image segmentation[J].Acta Automatica Sinica,2010,36(11):1527-1533.
[2]周志华,王珏.机器学习及其应用[M].北京:清华大学出版社,2007: 259-275.
[3]Zhou D Y,Bousquet O,Lal T N,et al.Learning with local and global consistency[C].Proc of Advances in Neural Information Processing Systems.Massachusetts:MIT Press, 2003: 321-328.
[4]Duda RO,Hart PE,Stork Dg.Pattern Classification [M]. New York:John Wiley & Sons,2001.
[5]Lee D.D,&Seung H.S.Learning the parts of objects with non-negative matrix factorization. Nature,1999,401(6755):788-791.
周勇(1989—),男,主要研究领域为机器学习。
孙福明(1972—),男,博士,教授,计算机学会(CCF)会员(E200014102M),主要研究领域为计算机视觉、图像语义理解。
蔡希彪(1972—),男,博士,副教授,主要研究领域为无线通信、计算机视觉、图像语义理解。
作者简介:
