基于异常评分行为分析的虚假评论商品识别方法
2015-03-03焦易于
焦易于, 刘 刚
(河南大学 计算机与信息工程学院, 河南 开封 475004)
基于异常评分行为分析的虚假评论商品识别方法
焦易于, 刘 刚
(河南大学 计算机与信息工程学院, 河南 开封 475004)
在电商平台的所有评论信息中检测虚假评论时,评论领域的多样性以及虚假评论的总体稀疏性会导致识别准确率的下降。如果首先识别出包含虚假评论的商品,再对其中的评论进行针对性检测,会大大提高识别的效率和准确性。本文提出了一种基于异常评分行为分析的虚假评论商品识别方法,在对虚假评论行为分析的基础上,采用正态分布拟合和时序数据突变点检测方法,实现对虚假评论的发现。实验结果表明,该方法可以有效地识别虚假评论目标商品。
虚假评论;异常评分行为;正态分布拟合;时序数据突变点检测
当前电商平台发展迅猛,网购已经成为人们生活的重要组成部分。当选购电商平台的商品时,经常需要参考商品的评论,尽量多获取商品的信息,以便做出正确的购买决定。然而,虚假评论在商品评论中占据了相当比例,这些虚假评论使消费者获得的商品信息不真实,对消费者形成误导。因此,检测虚假评论,对于确保商品评价的真实性、维护消费者权益,具有重要的意义。
当前针对商品虚假评论检测的研究,主要从评论内容本身、评论相关要素信息(时间、地点、评论者等)以及关系网络中挖掘真实评论和虚假评论的区别。Wang G等[1]提出了一种基于异质图模型的虚假评论检测方法,该方法利用评论、评论者、商店三者间的关系网络构建虚假评论检测模型。Xie S等[2]深入剖析了虚假评论发布者的活动规律,把虚假评论检测问题映射成为异常不相关模式检测问题。Jindal N等[3]最先提出基于监督学习的方法,他们认为重复是虚假评论的一大特征,可利用文本相似度的方法来识别出评论集中的重复评论作为虚假评论,然后将这些重复评论作为训练集,采用logistic回归模型将评论分成虚假评论和真实评论两大类。Ott M等[4-5]分析了虚假评论和真实评论文本的特点,并从中提取出了能够区分两者的特征,然后利用监督学习的文本分类技术实现虚假评论的检测。Xu Q等[6]深入地分析了评论文本的深度语言特征,提出了一种集成了依存句法树等高级语言特征的新模型,用于检测虚假观点。当训练数据集较大时,以上这些方法展示出了良好的精度和鲁棒性。此外,针对训练数据的缺乏问题,Hernández D等[7]提出了一种使用PU-Learning学习策略的虚假评论分类器学习方法。
以上的研究重点集中在小数据集上的虚假评论检测模型和有效性验证分析上,距离实用还有很大差距。电商平台的商品种类繁多,不同商品的评论具有不同的特点,而且从评论数据总体上看,虚假评论的密度还是相对较低的。若采用同样的方法不加区分地对所有评论进行检测,评论领域多样性以及虚假评论的总体稀疏性将会导致识别准确率的下降。基于此,针对海量评论数据,若要使检测方法实用化,可以先筛选出有虚假评论的商品,再识别商品对应的虚假评论。这样,不仅可以大量减少需要判断的评论数量,而且更具针对性,有利于提高虚假评论检测性能。
专门针对虚假评论目标商品识别的研究还未见报道。本文利用评论网站的评分系统实现虚假评论目标商品的识别。评论网站的评分系统是指现在的电商平台都提供一个打分机制,在进行内容评价的同时,可以对商品进行1~5分的打分。这个分数代表消费者对商品的情感态度,4~5分表明消费者对商品比较满意;1~2分表明消费者对商品很不满意;3分则代表了消费者基本认可。虚假评论可以分为两类:一类是积极的虚假评论,这类虚假评论含有吹捧性质,目的是促进销售,这类评论通常都会打5分;另一类是消极的虚假评论,这类评论是竞争对手有意打压制造的贬低的虚假评论,这类评论通常都会打1分。因此,商品中存在大量5分或1分的评分行为,是该商品存在虚假评论的一个重要参考。
基于上述分析,本文提出了基于异常评分行为的虚假评论商品筛选技术,通过分析商品评论的评分行为异常,筛选出含有虚假评论的商品,为虚假评论分析提供更加准确的研究目标。
1 基于异常评分行为的目标商品识别方法
1.1 虚假评论的评分行为分析
虚假评论要起到诱导消费者的作用,需要一定的量,少量的虚假评论很难影响到消费者的决策。要使商品获得较多的虚假评论,可以雇佣专业水平的写作团队或者对消费者实行好评返现活动等。这样会形成几种虚假评分状态:第一种虚假评分状态是好评返现等活动引诱消费者打高分,这样的过程通常伴随商品销售的整个过程,也就是说虚假评论和真实评论一直混合;另一种虚假评分状态是雇水军刷分,有的新商品从商品销售开始到当前为止,一直是水军刷分和真实评分相混合。和第一种状态相同,第二种虚假评分状态持续不长久,因为雇佣水军刷分是一种短期行为。有的商品有正常评论阶段,也有雇佣水军参与刷分阶段,但刷分对商品正常评分扰动明显,形成第三种虚假评分状态。最后,有的商品阶段性出现雇佣水军刷分,但是由于商品整体评论数量大,对水军刷分有修复作用,因此,水军刷分对商品整体评分扰动影响小,形成第四种虚假评分状态。
通过以上分析可知,在前3种虚假评分状态中虚假评分对整体评分扰动明显;最后一种虚假评分状态,虚假评分对整体评分扰动小。基于上述分析中的评分行为异常特点,提出两种虚假评论目标商品的识别算法:一种是利用正态分布拟合方法进行虚假目标商品识别,这种方法对商品的整体评分分布进行拟合,称为静态识别方法;另一种是利用时序方法进行虚假目标商品识别,称为动态识别方法。
1.2 虚假评论目标商品的静态识别方法
社会现象中,许多随机变量的分布属于正态分布。通过对大量正常商品的评分分布的观察发现,正常的商品评分分布规律符合正态分布。但当商品评论中含有大量虚假评论时,商品评分分布受到虚假评分的扰动,会出现偏离正态分布的现象。正如前面所述,虚假评论的目标明确,要么给高的评分吹捧商品,要么给低的评分贬低商品。正是由于这种现象,导致高的或者低的评分数量大量增加,破坏正常的评分分布规律。本文利用这一特点,提出基于正态分布拟合的算法。利用该算法对商品的评分分布进行拟合,若拟合结果不符合正态分布,说明评分受到虚假评分的扰动,依此判断其为潜在目标商品。
虚假评论目标商品静态识别方法是依据对商品评分的拟合结果来判断商品是否为含有大量虚假评论的目标商品。因此,评分分布的拟合是本方法的关键。由于评论评分是从1分至5分的离散值,对评分分布的拟合将通过以下方式进行:首先根据已有的评论评分数据得到每个评分等级所占的比例,再得到评分平均值;接着,计算得到标准差;然后,根据计算得到的均值和标准差得到理想的正态分布;接下来,依据理想正态分布计算分布函数对应的分位数;最后,根据分位数和评分等级的关系判断评分是否符合正态分布。具体可以分为以下几步:
(1)计算每个等级所占比例pi,(i=1,2,3,4,5),如式(1)所示。其中,si表示第i等级评分数量。
(1)
(2)计算整体评分均值u,如式(2)所示。其中,ri∈(1~5)表示评分等级。
(2)
(3)计算整体评分标准差σ,如式(3)所示。
(3)
(4)计算分布函数F(rn),如式(4)所示。
(4)
根据上面计算得到的参数值u和σ,可以获得一个理想正态分布。根据这个理想正态分布,计算F(ri)对应的分位数。(x1,x2,x3,x4,x5)5个分位数表示在理想正态分布下,评分在(-∞,x1)区间的概率为p1,评分在(x1,x2)区间的概率为p2,以此类推,评分在(x4,x5)区间的概率为p5,(x5,+∞)区间的概率为0。因为实际的评论评分为5级离散值,所以如果实际评分满足正态分布,则评分在(xi-1,xi)的用户选择pi对应的评分分值,即ri。若实际评分值ri都在(xi-1,xi)之间,则说明商品评分的正态分布拟合成功;若有不符,则说明可能存在较多的虚假评分,使得商品的评分受到扰动影响。
通过静态目标商品识别方法,可以识别虚假评分使评分分布发生扰动的商品。正如前面所说的3种虚假评分状态,商品评分分布都可能受到扰动,因此,可以通过此方法识别处于3种虚假评分状态的商品。但是对于第四种虚假评分状态,由于含有大量评论,虚假评论相对真实评论较少,可能不会引起整体评分分布的扰动,因此,此方法对第四种虚假评分状态的商品不适用。
第四种虚假评分状态是阶段性雇佣水军发布虚假评论,由于水军通常是整体行动,因此在水军发布虚假评论的时间窗口内,评论数量会突发性增多,且由于虚假评论极度吹捧或极度贬低的特性,造成时间窗口内的评分均值会与评论数量存在正相关或负相关的关系。基于此特点,本文提出利用时序数据挖掘虚假评论目标商品的动态识别方法。
1.3 虚假评论目标商品的动态识别方法
对于阶段性雇佣水军发虚假评论的商品,可以通过时序分析方法,发现其突发异常行为模式,从而确定目标商品。其思想是:对于正常评论的商品,时间窗口内评论的数量和评论的平均评分值之间是无关系的。而对于阶段性水军发虚假评论的商品,在水军运作的时间窗口内,评论数量和评分均值之间呈现正相关或者负相关,即评论数量的突发增长,伴随着评分均值的突发增大或减小。因此,按时间窗口对评论数量和评分均值构建时序数据,再通过两时序数据的关联突发性找到虚假评论目标商品。这种方法即为动态识别方法。
根据以上描述,该方法首先对分析时间长度T按时间窗口大小划分,然后获得每个窗口内的评论数量和评分均值,最后得到评论数量和评分均值的时间序列。对所得到的时间序列进行分析,如果能确认有关联的评论数量和评分均值突发点,则说明商品包含了虚假评论,即确认了目标商品。
目标商品动态识别方法的步骤如下:
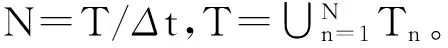
f1(Tn)=|{ri∶tpi∈Tn}|
(6)
(7)
其中:f1(Tn)表示时间窗口Tn内的评论数量;f2(Tn)表示时间窗口Tn内的评分均值。
(2)时间序列异常点检测。在上一步,通过数据统计得到了二维时间序列(f1(Tn),f2(Tn)),虚假评论目标商品的识别问题转化为二维时间序列的异常点检测问题。将时序上的点分别拟合成折线,然后查找折线上的异常点。若能查找到相关异常点,则说明商品中含有虚假评论,即为查找的目标商品。
1.4 虚假评论目标商品识别方法
将上述动态、静态2种方法结合起来,可得到一个完整的虚假评论目标商品的识别方法。
针对虚假评论目标商品的筛选,主要分为3步。首先,分析用户对商品的打分,对商品评分进行统计;然后,根据静态识别方法筛选目标商品;最后,根据动态识别方法识别剩余的商品,得到潜在的虚假评论目标商品。主要流程如图1所示。
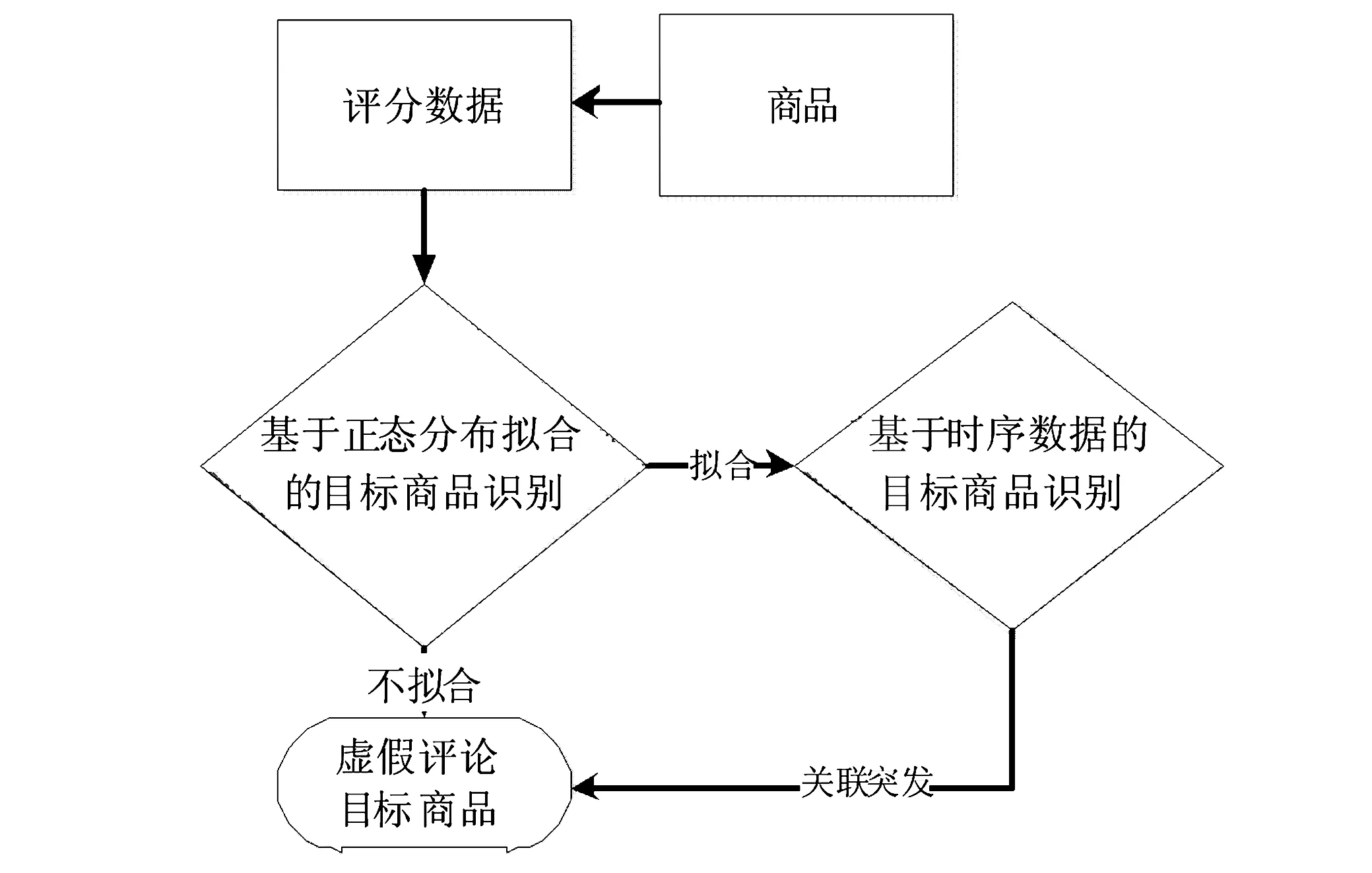
图1 基于异常评分行为的虚假评论目标识别框架
2 实 验
2.1 实验数据的选取
实验采用从Resellerating.com上采集到的数据,包括343 629个评论者对25 034件商品的408 469条评论。
2.2 评价指标
准确率广泛用于信息检索和统计学分类领域的度量。本文中的数据分析结果拟采用该指标进行评价。
准确率P是指提取出含有虚假评论的商品数量M占提取出的全部商品的数量N的比值,即
P=M/N×100%
(8)
通过该指标,可以衡量本方法筛选分析目标的效果。
2.3 实验结果分析
评测中选择评论数量1 000以上的商品作为待测对象,最终从得到的目标商品中,选择最可疑的50件商品进行手工验证。
选择3个具有丰富网购经验的人作为评测员,将3人分开,分别独立对商品进行标记,并制定目标商品标记规则。如果有两个人认为商品为虚假评论的目标商品,则可认为该商品为虚假评论的目标商品。标记的结果如表1所示。

表1 虚假评论目标商品人工标注结果
评测员1和评测员2共同标注其为目标商品的数量为40个,评测员1和评测员3共同标注其为目标商品的数量为41个,评测员2和评测员3共同标注其为目标商品的数量为39个。最后的标注结果为所有两两交集的并集,其值为42,即评测员在50件商品中找到42件目标商品,其准确率为:
P=M/N×100%=42/50×100%=84%
从实验结果来看,证明本方法在虚假目标商品识别上有效,仅通过商品的评分而不需要其他信息便可识别虚假评论目标商品。
3 结 语
已有的虚假评论检测研究重点集中在小数据集上的虚假评论检测模型和有效性验证分析上,距离实用还有很大差距。在面对海量数据级别的虚假评论时,由于数据量较大,需要有针对性地对数据进行分析。本文从虚假评论目标商品的识别入手,以提高虚假评论检测效率和准确率。
针对虚假评论目标商品的识别问题,本文将其转换为商品异常评分行为识别问题。首先,将商品虚假评分状态分为4种类型,鉴于前3种类型虚假评分对商品整体评分分布规律造成扰动,提出基于正态分布拟合的目标商品识别方法。对第四种虚假评分状态,由于其虚假评论发布呈阶段性特点,提出基于时序数据异常点检测的识别方法。通过仿真实验,证明了该方法的有效性。
[1]WangG,XieS,LiuB,etal.ReviewGraphBasedOnlineStoreReviewSpammerDetection[C]//2011IEEE11thInternationalConferenceonDataMining.Piscataway:IEEEPress, 2011: 1242-1247.
[2]XieS,WangG,LinS,etal.ReviewSpamDetectionviaTemporalPatternDiscovery[C]//Proceedingsofthe18thACMSigkddInternationalConferenceonKnowledgeDiscoveryandDatamining.Texas:ACM, 2012: 823-831.
[3]JindalN,LiuB.ReviewSpamDetection[C]//Proceedingsofthe16thInternationalConferenceonWorldWideWeb.Texas:ACM, 2007: 1189-1190.
[4]OttM,CardieC,HancockJT.NegativeDeceptiveOpinionSpam[C]//The2013ConferenceoftheNorthAmericanChapteroftheAssociationforComputationalLinguistics:HumanLanguageTechnologies.Atlanta:NAACL, 2013: 497-501.
[5]OttM,ChoiY,CardieC,etal.FindingDeceptiveOpinionSpambyanyStretchoftheImagination[EB/OL]. (2012-04-04)[2015-05-04].http://www.docin.com/p-376055993.html.
[6]XuQ,ZhaoH.UsingDeepLinguisticFeaturesforFindingDeceptiveOpinionSpam[C]//The24thInternationalConferenceonComputationalLinguistics.Mumbai:COLING, 2012: 1341-1350.
[7]HernándezD,GuzmánR,MóntesyGM,etal.UsingPU-learningtoDetectDeceptiveOpinionSpam[C]//Proc.ofthe4thWorkshoponComputationalApproachestoSubjectivity,SentimentandSocialMediaAnalysis,Atlanta:Medicine, 2013: 38-45.
[8]HamoudaA,RohaimM.ReviewsClassificationUsingSentiwordnetLexicon[C]//WorldCongressonComputerScienceandInformationTechnology.Cairo:INFOMESR, 2011:120-123.
[9]OhanaB,TierneyB.SentimentClassificationofReviewsusingSentiwordnet[C]//Proceedingsof9thInformationTechnology&TelecommunicationsConference.Dublin:DublinInstituteofTechnology, 2009: 13.
(责任编辑:席艳君)
A Method for Identifying Target Products with Fake Comments Based on Abnormal Rating Behavior Analysis
JIAO Yi-yu, LIU Gang
(Henan University, Kaifeng 475004, China)
The diversity of the product field and the overall sparsity of the fake comments will lead to the recognition accuracy decline when detecting the fake comments by directly processing all the comments on the business platform. So the identification of the target product with fake comments will greatly improve the efficiency and accuracy of recognition. To this end, an abnormal rating behavior identification method is presented to identify the target products.Based on the analysis of the fake comments, using the normal distribution fitting and the abrupt point detection of the time sequence data, the discovery of the target products is realized. Experimental results show that the proposed method can effectively identify the target products with fake comments.
fake comments; abnormal rating behavior; normal distribution fitting; abrupt point detection of the time sequence data
2015-05-04
焦易于(1990-),女,河南安阳人,硕士生。
1671-6906(2015)06-0080-05
TP391
A
10.3969/j.issn.1671-6906.2015.06.018
