融入音乐子人格特质和社交网络行为分析的音乐推荐方法
2015-02-28琚春华黄治移鲍福光
琚春华,黄治移,鲍福光
(1.浙江工商大学现代商贸研究中心 杭州310018;2.浙江工商大学计算机与信息工程学院 杭州310018;3.浙江工商大学工商管理学院 杭州310018)
1 引言
随着互联网和数字音乐的不断发展和普及,人们逐渐从音乐匮乏的时代走入音乐过载的时代。音乐过载带来一个问题:人们往往需要花费大量的时间从海量的音乐库中找到自己喜欢的音乐,因此音乐推荐系统应运而生。
现今,关于音乐推荐系统的研究主要分为3类:基于内容过滤的推荐[1],该方法通过获取音乐的音频特征或社会化网络标签,为用户推荐最近播放的相似音乐,如虾米网、SongTaste等热门音乐网站。这种方法推荐结果直观易理解且几乎不需要特别的用户历史数据,缺点是推荐结果缺乏新颖性、易受音乐特征提取能力的影响;基于用户协同过滤的推荐[2],该方法基于用户对音乐的评分数据,找到具有与该用户最相似偏好的用户,进而推荐相似用户评分最高的音乐,如Ringo、Last.fm等音乐服务提供商。这种方法善于发掘用户新的兴趣点、可处理复杂的非结构化对象,缺点是冷启动问题和数据稀疏性;基于语境的推荐[3],该方法获取用户历史的音乐评论、博客百科等文化背景知识、播放次数等数据,记录用户偏好,为用户推荐个性化的音乐,如豆瓣电台,这种方法优点是更具个性化、准确率高,但缺点是语境信息数据量庞大,受语境提取准确率影响。
上述音乐推荐研究主要集中在音乐本身的分类及分析。然而,音乐最主要的功能是能够引起共鸣、调节情绪、陶冶情操等,单单地从音乐本身的相似性和用户的偏好很难发挥音乐的作用,人们往往更希望能够按照自己的心情推荐适合的音乐,如不高兴的时候,可以推荐一些能够使自己心情平复的音乐。
[4,5]研究音乐特征和用户情绪之间的关系,根据用户不同的情绪为用户推荐适合的音乐。然而,其认为所有的用户无论是什么样的背景因素,都对相同的音乐具有相同的情绪反应,显然这是不合理的。参考文献[6]为不同的用户创建不同的情绪状态转换模型(emotion state transition model,ESTM),从而建立用户情绪和音乐底层特征之间的关系,通过用户实时输入的环境信息,判断用户的实时情绪,根据ESTM将用户的情绪调整到最佳状态。但该研究需要用户实时输入环境信息,较为繁琐,也没有考虑人格因素对ESTM的影响。参考文献[7]提出一个个性化的音乐情绪反应预测分析方法,考虑使用者背景的差异性,预测使用者的音乐情绪反应,从而达到推荐的目的,但该研究并没有考虑到人格因素的影响,且推荐依靠用户最初的问卷,如果后期用户的情绪反应发生变化,推荐并没有相应的改变。目前,针对用户情绪的音乐推荐方法研究不够成熟,融入人格因素的个性化音乐推荐方法还没有被研究。
人格特质早已成为对用户进行音乐偏好研究的重要对象。本文提出了一种融入音乐子人格特质和社交网络行为分析的音乐推荐方法,该方法通过关联用户发布在微博等社交媒体的数据信息和点播音乐记录,挖掘用户在不同情感状态下的音乐偏好;然后,通过基于音乐偏好度预测的相似度计算方法,降低数据稀疏性对推荐结果的影响;最后,通过融入音乐子人格特质的偏好度预测方法,将预测值Top N的项目推荐给用户。
2 音乐子人格特质因素
人格[8](personality)是个体内部的心理特质和机制的集合,具有组织性和相对持久性,它们影响到个体对心灵内部的、物理的和社会环境的适应以及与它们的相互作用。音乐子人格是基于个人气质特征和文化沉淀选择倾向而呈现某些特征的[9],音乐子人格是个体对音乐感受的取向分析,对用户音乐偏好研究具有重要的意义。基于此,邹光宇[9]将音乐子人格用7个音乐气质特征来描述,具体描述见表1。

表1 音乐子人格特质描述
本文在原有数字音乐网站的注册界面上嵌入音乐子人格特质分析模块,即用户首次登录网站时,填写由晴天心理中心邹光宇等人提出的“晴天音乐子人格测评量表”(以下简称量表),晴天音乐子人格量表不计总分,共有7个分量表,各有5道题组成,单个量表粗分范围为5~35分,实际得分除以满分35得出百分比值或者特征指数。
对于用户(user)而言,其音乐子人格特质的7个维度分别为A、B、C、D、E、F、G,用i=1,2,3,4,5,6,7简化表述;xj表示user对量表中第j题的打分,j=1,2,…,35;j=i+5k,k=0,1,2,3,4,k用以选择区分不同题目所属的音乐子人格特质维度;则Oi表示维度i的得分。计算方法如式(1)所示。

由于音乐子人格是分析个体对音乐的情绪感受性,相似的音乐子人格对相同的音乐具有相似的感受,通过分析用户实时情感,将音乐子人格融入推荐方法中,以便能够更好地提高推荐方法的准确性。
3 融入音乐子人格特质和社交网络行为分析的音乐推荐
3.1 基本定义
定义1(用户集合)U={uk|k∈S},U表示用户集合,S表示用户的ID集合。
定义2(音乐子人格特质向量)MPk=(A,B,C,D,E,F,G),k∈S,MPk表示用户ID为k的用户的音乐子人格特征向量,S表示用户的ID集合。
定义3(用户情感状态)Ek={Happy,Like,Anger,Sad,Fear,Disgust,Surprise},k∈S,Ek表示用 户ID为k的用户的情 感 状 态,happy,like,anger,sad,fear,disgust,surprise依次为乐、好、怒、哀、惧、恶、惊。
定义4(音乐集合)M={i|i∈I},M表示音乐集合,I表示音乐ID集合。
定义5(音乐特征)MCi=(PM,PS,IM,IS,PE,PD,LD,LS),i∈I,MCi表示音乐ID为i的音乐特征向量,I表示音乐ID集合,各特征具体描述见表2[10]。

表2 音乐特征
定义6(用户情感—音乐关联)R=
3.2 模型构建
本文的推荐模型分为两个阶段:第一个阶段为用户情感与音乐关联过程,该阶段主要完成音乐特征提取、用户历史微博情感分析、用户情感与音乐关联;第二阶段为实时推荐过程,主要包括用户实时情感分析、基于音乐偏好度预测的音乐相似度计算、融入音乐子人格特征的偏好度预测。融入音乐子人格特质和社交网络行为的音乐推荐模型如图1所示。
3.3 音乐底层特征获取
音乐通常分成单调和复调两类,复调音乐是最一般的形式音乐。通常复调音乐由几个音轨组成,一部分负责旋律,另一部分负责伴奏,负责旋律的音轨比负责伴奏的音轨包含了许多不同音高的独特音符,本文选择音高密度最高的音轨作为主音轨,因为作曲家通常在主音轨上使用最独特的音符[10],音高密度定义如式(2)所示。

其中,NP为该音轨中独特音高的数量;AP为MIDI标准中所有独特音高的数量[11]。
根据获得的音高密度PD,确定主音轨,在此基础上,再根据定义5依次获取其他的各个特征。音乐ID为i的音乐特征向量MCi=(PM,PS,IM,IS,PE,PD,LD,LS),i∈I,I表示音乐ID集合,各特征具体描述见表2[10]。
3.4 用户情感—音乐关联
3.4.1 中文情感词汇本体库
本文采用大连理工大学信息检索研究室(Information Retrieval Laboratory of Dalian University of Technology,DUTIR)提供的情感本体库作为细粒度情感划分的依据,其情感分为7大类21小类,情感强度分为1、3、5、7、9共5档,共含有情感词共计27 466个[12]。考虑到DUTIR情感本体库中对于表情和最新的网络词语没有收集,本文在其基础上添加微博等社交媒体上流行的表情(如:[给力]、[威武])及流行词汇(如呵呵、请允悲、何弃疗),并人工对这些表情及词汇分类并标注情感强度。最终本文构成的情感本体库各个情感类型的情感单词个数见表3。
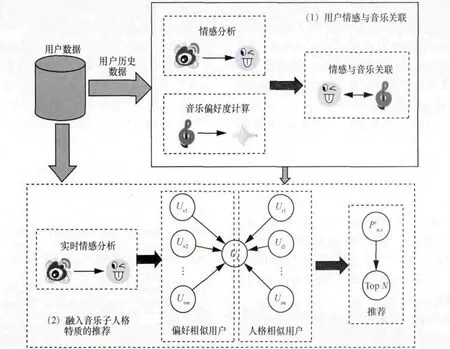
图1 融入音乐子人格特质和社交网络行为的音乐推荐模型

表3 情感本体库分布
本文根据情感类别特点将七大类情感又归结为积极(positive)、消极(negative)和中立(neutral)3个情感倾向类,其中积极包含乐、好,消极包含怒、哀、惧、恶,中立包含惊[12]。
3.4.2 微博情感分析
对于用户发布的某条微博,本文采用中国科学院ICTCLAS2013汉语词法分词系统进行预处理。考虑到句子经常会出现“但是”、“不过”等连接词会将情感词的情感反转,还收集了62个连接词,当情感词与连接词的距离小于2时,则对其进行情感倾向反转,如积极反转为消极。本文微博情感判断步骤如下。
步骤1根据分词结果分别计算属于happy、like、anger、sad、fear、disgust、surprise情感大类情感词强度之和,若全部为0,则结束,句子不含情感;否则,分别计算情感倾 向positive=happy+like,negative=anger+sad+fear+disgust,neutral=surprise。对出现情感反转的情感词,将其情感强度值累积到对立的情感倾向中,例如,原情感倾向属于positive,则将其情感强度值加入negative中,若原情感倾向属于negative,则将其情感强度值加入positive。
步骤2判断情感倾向positive、negative、neutral值大小。若positive最大,则为积极句;若negative最大,则为消极句;若neutral最大,则为中立句。
步骤3根据步骤2判断的情感倾向类,选择该情感倾向类中情感强度最大的情感类别为该状态用户主导情感。如happy最大,则该句情感为happy。
例如,对于微博“周末加班好无语,但是看见萌萌哒的汉良兄,心情一下子舒畅啦[可爱]”(“[可爱]”为微博表情),用分词系统对其进行分析,结果见表4。

表4 微博分词结果
得到情感词{“无语”,“舒畅”,“[可爱]”},其中“无语”属于sad类别,其情感强度为5,“舒畅”属于happy类别,其情感强度为5,“[可爱]”属于happy类别,其情感强度为5,连接词“但是”与情感词“无语”距离最近且距离为1。故各 情 感 类 别 值 分 别 为:happy=10,like=0,anger=0,sad=0,fear=0,disgust=0,surprise=0,情感倾向positive=15,negative=0,surprise=0,可知positive值最大,故该微博为积极句;happy为positive中值最大的情感类,所以该状态用户情感为happy。
3.4.3 用户情感与音乐关联
不同用户在相同情感状态下对同一首音乐的偏好程度不一样,同一用户在不同情感状态下对同一首音乐的偏好程度也会发生变化[13]。因此,为了挖掘用户在不同情感状态下的音乐偏好,本文结合上述微博等社交媒体情感状态分析和用户点播歌曲记录,为每一个用户建立情感与音乐之间的关联模型。
当一个用户发布一条带有情感的微博等社交媒体状态时,本文认为只有在该条状态发布的时间点附近用户所点播的音乐是该用户在该情感状态下喜欢的音乐,点播音乐的时间点离该情感状态发布时间越近,用户的偏好程度越高。本文用数值0~10表示用户对该音乐的偏好度(与评分概念相同),数值越大,用户的偏好程度越高,并构建<用户ID,音乐ID,情感状态,偏好度>四元组。
用户发表的带有情感的状态通常分为两种:普通状态和音乐分享状态。对于一条含有情感的音乐分享状态,最能代表用户的音乐偏好,对于这种类型的状态,本文直接分析用户的情感并提取分享的音乐ID,并设置偏好度数值为10,得到<用户ID,音乐ID,情感状态,偏好度>四元组。对于普通含有情感的状态,将时间窗口选定时间为30 min,也就是该条状态发布时间点的前30 min和后30 min,如果在该时间段内没有点播记录则舍弃这条状态;否则,选取该时间段内播放时长超过该音乐时长一半的所有音乐(用户播放时长低于音乐时长一半的音乐,往往是用户跳过的不喜欢的音乐,这里去除这类音乐)。由于距离状态发布时间点的不同,用户的偏好程度也会不同,所以通过时间加权求和的方式求得用户对点播音乐的偏好度,计算方式如式(3)所示。

其中,Tw为时间窗口长度,本文中取值为30,Tim为音乐时长,t为微博状态发布的时间,ti为第i首音乐点播的时间,tie为第i首歌播放结束时间,λi为第i首音乐偏好度,n为时间窗内符合条件的所有音乐总数目。
例如,用户564813087在2015年6月27日12∶10∶23发布了一条内容为“周末加班好无语,但是看见萌萌哒的汉良兄,心情一下子舒畅啦[可爱]”的微博,通过微博情感分析,得到该用户的情感状态为happy。该用户在2015年6月27日12∶10∶23前后30 min点播的音乐列表见表5。
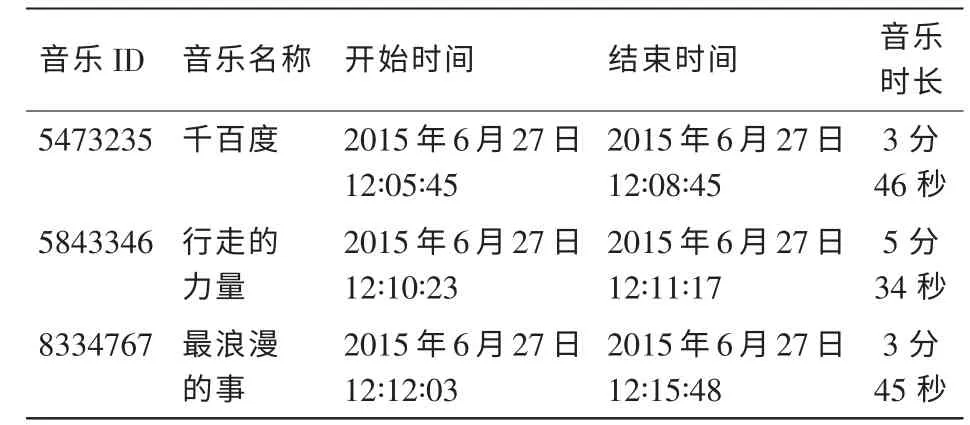
表5 用户564813087在2015年6月27日12∶10∶23前后30 min点播记录
由于音乐《行走的力量》播放的时长小于音乐时长的一半,所以这里去除该条记录。音乐《千百度》的偏好度得到四元组<564813087,5473235,happy,6.8>。音乐《最浪漫的事》的偏好度,所以得到如下的用户情感与音乐四元组:<564813087,8334767,happy,9.4>。为了保证四元组的唯一性,如果用户在相同情感状态下再次点播相同的音乐时,新产生的偏好度会替换原来的偏好度。
3.5 融入音乐子人格特质和社交网络行为分析的音乐推荐
3.5.1 基于音乐偏好度预测的用户相似度计算(SIRP)
传统的用户相似度计算,用户之间对相同音乐进行偏好度标记得越多,计算相似的准确性也就越高。然而,这种方法对于新用户来说存在一定的弊端,新用户的音乐偏好度或评分数据往往极端稀疏,通过这极少的偏好度和评分数据去计算用户相似度显然不是很合理。
为了解决新用户音乐偏好度或评分数据稀疏的问题,本文先通过计算音乐间的相似度,根据最相似音乐的已有偏好度λ去预测未标记音乐的偏好度λ,增加用户之间共同标记偏好度的音乐数,从而使得用户相似度计算更加准确。具体计算步骤如下[14]。
步骤1计算用户u与用户v有偏好度标记音乐的并集Uuv,Uuv=Mu∪Mv,Mu与Mv分别表示用户u与用户v的有偏好度标记的音乐集。
步骤2令用户u没有偏好度标记的音乐集Nu=Uuv-Mu,对任意的音乐m∈Nu,计算音乐m与用户u已有偏好度标记音乐k之间的相似度,m軖与k軋分别表示音乐m与音乐k的特征向量,音乐m与音乐k的相似度计算如式(4)所示。

步骤3设置相似度阈值s,取相似度值大于s的音乐作为音乐m的最近邻。若不存在最近邻,则该音乐的偏好度为0;否则,利用式(5)来预测用户u对音乐m的偏好度Pu,m。

其中,Sm表示音乐m的最近邻音乐集,Pu,k表示用户u对音乐k的偏好度。
步骤4同理,由步骤2和步骤3计算用户v没有偏好度标记音乐的偏好度。得到所有偏好度后,利用式(6)计算用户u与用户v之间的相似度。

3.5.2 融入音乐子人格特质的偏好度预测(MPP)
音乐心理学研究表明,具有相同人格的用户其音乐偏好也会变得相似[15]。单独使用偏好度或评分数据进行用户偏好预测,会存在一定的偏差,本文将音乐子人格特质融入用户的偏好预测中,以便更好地提高偏好预测结果的准确性。用户音乐子人格特质相似度计算如式(7)所示。
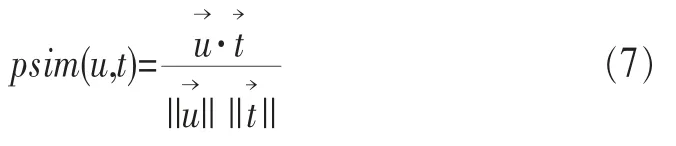
根据Top N最近邻选择策略,分别从偏好相似用户和人格相似用户中选择相应的用户作为邻居。融入音乐子人格特质的偏好度预测计算如式(8)所示。

其中,V和T分别表示偏好相似用户集合和人格相似用户集合,β和1-β分别表示偏好相似用户和人格相似用户在偏好度预测中的权重,权重取值通过交叉验证实验来设定。
3.5.3 推荐过程描述
输入 用户音乐子人格特质、用户点播音乐记录、用户微博等社交媒体数据。
输出 用户的音乐推荐列表。
步骤1用户情感与音乐关联,根据用户历史微博数据和用户点播音乐记录,使用第3.4节方法,分析用户微博情感状态,并计算用户点播的音乐偏好度,构建<用户ID,音乐ID,情感状态,偏好度>四元组;
步骤2用户实时情感分析,根据第3.4.2节方法分析用户实时发布的微博情感,若微博不含任何情感倾向,则结束推荐;否则,继续执行下面操作;
步骤3基于音乐偏好度预测的用户相似度计算,根据用户实时情感状态,选择对应情感状态的数据,利用第3.5.1节方法计算音乐之间的相似度,选取大于音乐相似度阈值的最近邻音乐,并计算用户对未标记偏好度的音乐的偏好度,基于此计算用户相似度;
步骤4选取邻居集,利用用户音乐子人格特质计算用户相似度,根据Top N最近邻选择策略,分别从偏好相似用户和人格相似用户选取相应的用户作为邻居集;
步骤5融入音乐子人格特质的偏好度预测,根据邻居集,利用式(8)预测用户对未标记偏好度的音乐的偏好度;
步骤6构建推荐列表,根据对用户未标记偏好度的音乐的偏好度预测,选取用户在该情感状态下已有音乐偏好度和预测的偏好度前Top N的音乐推荐给目标用户。
4 实验及结果分析
4.1 数据集
本文收集了263位用户的微博数据及点播音乐记录,共收集50 473条用户发布的微博数据和29 530条用户点播音乐记录。为了保证用户数据的可靠性,去除了纯转发、只有图片等不能分析用户情感状态的微博数据,然后去除了那些没有填写音乐子人格量表的用户。最终,本文的实验数据集中共包含226个用户、43 625条用户发布的微博数据以及29 530条用户点播音乐记录。
为了验证推荐算法的准确性和确定推荐算法中相关参数,本文将收集的数据分为训练集和测试集。为了保证用户在训练集和测试集都有数据,将用户微博数据和点播音乐记录提前关联起来,关联的依据是以微博发布时间点的前30 min和后30 min内用户点播的音乐记录,然后按照8∶2的比例将用户的数据随机分为训练集和测试集。
4.2 评价指标
评价指标的选择可以有效评估推荐方法的推荐质量,本文采用MAE和P@N作为评价指标。
(1)MAE根据预测的用户偏好度和实际的用户偏好度来度量预测的准确性,具体定义如式(9)所示[16]。

其中,pi为预测的用户偏好度,qi为实际的用户偏好度,N为已有偏好度项目数。
(2)P@N是根据推荐集中Top N的项目与目标用户实际偏好度前Top N的项目比较,计算其准确度,具体定义如式(10)所示[16]。
P@N=推荐集中前Top N的项目包含用户实际偏好度前Top N的项目数量

4.3 实验结果与分析
4.3.1 相似度计算方法比较
为了验证本文的用户相似度计算方法的准确性,本文基于协同过滤推荐算法分别使用余弦、Pearson及基于项目偏好度预测的相似度计算(SIRP)方法进行比较,协同过滤推荐中使用式(11)作为偏好度预测计算式[17],SIRP方法中项目相似度阈值s通过交叉实验得到取值0.9最佳。实验结果如图2、图3所示。


图2 3种相似度计算方法的MAE比较

图3 3种相似度计算方法的比较
由实验结果图2可知,在选取不同数量的最近邻时,使用SIRP方法比使用余弦和Pearson方法预测项目偏好度的准确度更高,最近邻数目K=10时,相对余弦和Pearson方法改善最优,分别改善4.0%和5.1%。从图3可以看出,不同数量的最近邻,使用SIRP方法相对于使用余弦和Pearson方法在P@5和P@10的准确度依然最好。综上,与传统的余弦和Pearson相似度计算方法相比,使用基于项目偏好度预测的相似度计算方法能够获得更好的推荐结果,这主要是因为项目偏好度预测方法利用用户已有偏好度的项目,通过相似度计算预测没有偏好度的项目,可以有效降低数据稀疏性对推荐准确度的影响,从而提高推荐的准确性。
4.3.2 参数β对推荐结果的影响
由于偏好相似度计算和音乐子人格特质相似度计算使用不同的数据,其最近邻居集在偏好度预测中的权重不同,最终的预测准确度也会不同。该实验主要确定式(8)中的参数β的取值,实验取偏好相似用户20个和人格相似用户20个作为最近邻居集。当β=1时,最近邻居集只含偏好相似用户20个;当β=0时,最近邻居集只含人格相似用户20个。实验结果如图4和图5所示。
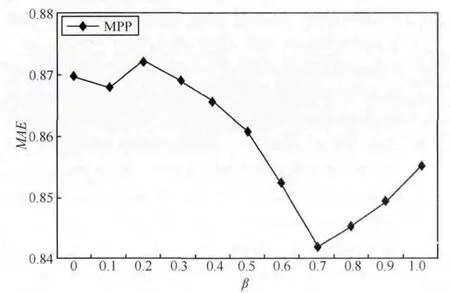
图4 不同参数值β的MAE
由实验结果图4和图5可知,参数β取值不同对推荐结果的影响较大,β取值为0.7时推荐准确度最高。这充分说明偏好相似用户和人格相似用户对推荐结果影响的程度不同,同时也说明本文引入权重β的合理性,后续试验参数β的取值为0.7。
4.3.3 融入音乐子人格特质的音乐推荐
本实验通过与传统协同推荐算法作比较,验证本文算法的有效性。实验中,设置最近邻数量为30,融入音乐子人格特质的推荐设置偏好相似用户15个和人格相似用户15个,未融入音乐子人格特质的推荐取偏好相似用户或人格相似用户30个。实验结果如图6和图7所示。
由图6和图7可知:融入音乐子人格特质的推荐算法相对未融入的推荐算法准确度更高,具有较小的MAE值和较大的P@N值;融入音乐子人格特质的SIRP推荐可以提高推荐方法的质量。实验结果表明,融入音乐子人格特质的偏好度预测的有效性和准确性。
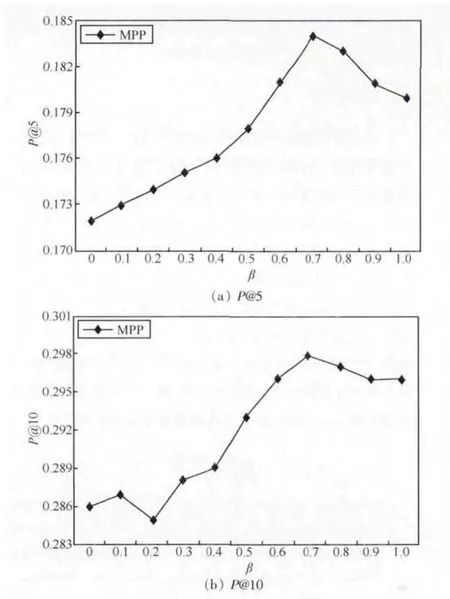
图5 不同参数值β的P@5和P@10

图6 融入音乐人格特质推荐算法的MAE比较

图7 融入音乐人格特质推荐算法的P@N比较
5 结束语
本文提出的融入音乐子人格特质和社交网络行为分析的推荐算法,与传统的依赖于用户评分数据不同,本文提出的算法可以挖掘用户在不同情感状态下对音乐的偏好度,用户不需对音乐进行评分,通过用户发布的实时微博情感分析,为用户推荐在该情感状态下喜欢听的音乐。为了降低数据稀疏性带来的推荐质量差的问题,本文利用基于用户音乐偏好度预测的相似度计算方法,利用用户已有的音乐偏好度去预测没有的音乐偏好度,提高了相似度计算的准确性。为了进一步提高推荐的质量,将音乐子人格特质融入音乐偏好度预测中。实验结果表明,融入音乐子人格特质和社交网络行为分析的推荐算法能够提高推荐的准确度。
参考文献
1 Balabanovic M,Shoham Y.Fab:content-based,collaborative recommendation.Communications of the ACM,1997,40(3):66~72
2 Schafer J B,Dan F,Herlocker J,et al.Collaborative Filtering Recommender Systems.The Adaptive Web.Berlin Heidelberg:Springer,2007
3 Yildirim H,Krishnamoorthy M S.A random walk method for alleviating the sparsity problem in collaborative filtering.Proceedings of the 2008 ACM Conference on Recommender Systems(RecSys 08),Lausanne,Switzerland,2008:131~138
4 Shan M K,Kuo F F,Chiang M F,et al.Emotion-based music recommendation by affinity discovery from film music.Expert Systems with Applications,2009,36(4):7666~7674
5 Yoon K,Lee J,Kim M U.Music recommendation system using emotion triggering low-level features.IEEE Transactions on Consumer Electronics,2012,58(2):612~618
6 Han B J,Rho S,Jun S,et al.Music emotion classification and context-based music recommendation.Multimedia Tools Appl,2010(2):433~460
7 Yeh C C,Tseng S S,Tsai P C,et al.Building a Personalized Music Emotion Prediction System.Advances in Multimedia Information Processing-PCM 2006.Berlin Heidelberg:Springer,2006
8 Larsen R J,Buss D M.人格心理学:人性的科学探索.郭永玉等译.北京:人民邮电出版社,2012 Larsen R J,Buss D M.Person Psychology.Translatel by Guo Y Y,et al.Beijing:Posts& Telecom Press,2012
9 邹光宇.晴天音乐子人格测评量表.中国音乐治疗学会第十届学术年会论文集,广州,中国,2011 Zou G Y.Fineday measurement scale of music sub-personality.Proceedings of the 10th Annual Conference of Chinese Society of Music Therapy,Guangzhou,China,2011
10 Chen H C,Chen A L P.A music recommendation system based on music and user grouping.Journal of Intelligent Information Systems,2005,24(2~3):113~132
11 Winsor P.Automated Music Composition.Automated Music Composition.Denton:University of North Texas Press,2000
12 刘楠.面向微博短文本的情感分析研究(博士学位论文).武汉:武汉大学,2013 Liu N.Emotion analysis on short text for Weibo(doctor dissertation).Wuhan:Wuhan University,2013
13 Meyer L B.Music and emotion:distinctions and uncertainties.Series in Affective Science,2001,29(3):23
14 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法.软件学报,2003,14(9):1621~1628 Deng A L,Zhu Y Y,Shi B L.A collaborative filtering recommendation algorithm based on item rating prediction.Journal of Software,2003,14(9):1621~1628
15 Delsing M J M H,Ter Bogt T F M,Engels R C M E,et al.Adolescents’music preferences and personality characteristics.European Journal of Personality,2008,22(2):109~130
16 胡勋,孟祥武,张玉洁等.一种融合项目特征和移动用户信任关系的推荐算法.软件学报,2014(8):1817~1830 Hu X,Meng X W,Zhang Y J,et al.Recommendation algorithm combing item features and trust relationship of mobile users.Journal of Software,2014(8):1817~1830
17 Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions.IEEE Transactions on Knowledge & Data Engineering,2005,17(6):734~749
