基于麦克风阵列的数字助听器语音增强技术*
2015-02-26戴红霞
戴红霞,赵 力
(1.江苏信息职业技术学院电子信息工程系,江苏无锡214153;2.东南大学信息科学与工程学院,南京210096)
基于麦克风阵列的数字助听器语音增强技术*
戴红霞1*,赵力2
(1.江苏信息职业技术学院电子信息工程系,江苏无锡214153;2.东南大学信息科学与工程学院,南京210096)
摘要:针对噪声和混响环境下的助听器用户聆听上的困难,基于麦克风阵列的数字助听器设计能够很好的提高助听器在这种环境下的语音信噪比。本文研究了应用麦克风阵列进行数字助听器语音增强处理技术,提出了一种基于粒子群优化的改进粒子滤波算法,它将语音增强问题转换为从带噪语音中对纯净语音的估计过程,引入粒子群优化的方法来产生建议分布,使降噪结果更接近纯净语音,从而得到更好的语音增强效果。
关键词:麦克风阵列;数字助听器;粒子滤波;语音增强
项目来源:国家自然科学基金项目(61273266,61375028)
语音增强是数字助听器算法的一个重要组成部分,其主要任务是抑制背景噪声和干扰。助听器在目标语音的实际拾取过程中,不可避免会受到外界环境噪声和其他说话人的干扰。如果干扰噪声过强对收听者而言则会觉得刺耳乃至听不清目标语音。针对这种情况,通常采用增强语音、去除背景噪声的方法来改善数字助听器系统性能。
由于目标声源到麦克风有一定的距离,麦克风接收到的语音信号受到环境噪声和干扰的影响很大。一般的基于单麦克风的语音增强系统难以获得较好的增强效果。麦克风阵列由于利用了目标信号、噪声和干扰的空间信息。基于麦克风阵列的数字助听器语音增强系统能提供更好的增强效果[5]。国外对于麦克风阵列语音增强的研究取得了很多研究成果,而国内类似的研究很少。
麦克风阵列的引入为数字助听器的语音增强打开了一个崭新的思路,它利用目标语音和干扰在空间位置上的差异,以及各个麦克风信号彼此之间的相关性,通过波束形成算法对来波方向上和语音分离的背景噪声和干扰进行抑制,从而增强语音,已逐渐成为语音增强领域研究的热点。
1 数字助听器中麦克风阵列语音增强的原理
在高度嘈杂和混响环境下,数字助听器对于目标声源的准确定位和获取一直都是提高助听器言语信噪比的关键所在。麦克风阵列接收到的信号不仅有直接到达的目标语音,还有目标语音经过反射、衍射等其他路径到达的部分即混响,不管处于室内室外,目标声源位于麦克风阵的近场远场都会有这种效应,具体环境下强度可能不同。同样对于噪声源也是如此[4]。典型的干扰和混响环境示意图如图1(a)所示。
麦克风阵列通过对拾取的多路语音信号进行分析与处理,使阵列形成的波束方向图主瓣对准目标语音,“零点”指向干扰源以抑制干扰信号,从而尽可能地获取目标语音。其中波束方向及波束主瓣宽度与麦克风的间距、麦克风数目、麦克风的摆放位置、声源入射角及采样频率紧密相关。波束的形成不仅消除了使用单个麦克风时需人工调节麦克风指向性问题,而且可以使输出语音的信噪比大幅度提高,从而无需人工干预亦可获得高质量的语音[4]。利用麦克风阵列获取目标语音信号示意图如图1(b)所示。
由上述可见麦克风阵列数字助听器系统较之单麦克风数字助听器系统具有许多优点,和单个麦克风相比,麦克风阵列在时频域的基础上增加了一个空间域,对来自空间不同方位的信号进行空时频联合处理。因此,麦克风阵列可以弥补单个孤立的麦克风在噪声处理、声源定位跟踪、语音提取分离等方面的不足,能够广泛应用于各种具有嘈杂背景的语音通信环境。麦克风阵列数字助听器研究是数字助听器发展的新方向,具有广阔的市场应用前景。

图1
2 基于粒子滤波的麦克风阵列语音增强技术
粒子滤波,是一种用蒙特卡罗(Monte-Carlo)模拟实现递归贝叶斯滤波的方法,其关键思想是用一组带有相关权值的随机样本的加权和来表示后验概率密度。基于粒子滤波的麦克风阵列声源定位与跟踪方法.该方法在粒子滤波框架下,将无混响影响的语音建立信号作为观测信息,通过计算麦克风阵列波束形成器的输出能量来构建似然函数,同时考虑语音信号不同频率成分在声源定位中的作用,利用分层采样方法提高粒子的采样效率。实验结果表明,该方法具有理想的声源跟踪能力及抗噪声与抗混响能力。
将粒子滤波的思想运用到数字助听器麦克风阵列语音增强中在国内外研究的并不是很多,基于粒子滤波的麦克风阵列信号处理可以为助听器提供良好的目标声源定位能力从而提高助听器在恶劣环境下的言语信噪比。粒子滤波方法成熟的体系结合麦克风阵列信号处理可以为数字助听器语音增强算法设计提供很好的研究方向与背景。
3 语音信号建模
语音信号xt和带噪的观测信号yt的模型可表示如下:
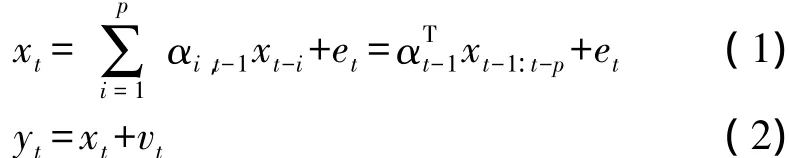


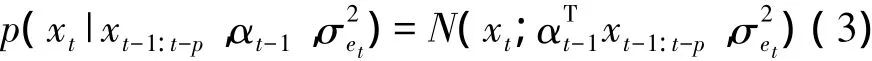


则语音信号模型可以表示为
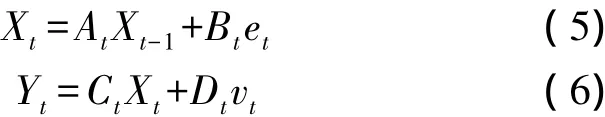


在模型中的线性观测系数αt的时变特性描述最简单的方法也是使用高斯移动模型描述,即

式中: Ip为p阶单位矩阵。至此语音信号的模型已经完整定义了。上述所有的N(x;μ,σ2)均指变量x服从均值μ、方差σ2的高斯分布,未加说明的高斯分布均值为0。
信噪比是衡量针对宽带噪声失真的语音增强算法的常规方法。假设y(n)表示带噪信号,s(n)表示其中的纯净语音信号,s(∧n)表示相对应的增强信号,所有这些信号都假设是能量信号,则时域误差信号为:
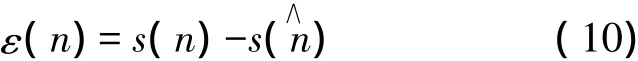
误差能量是:

纯净语音信号的能量是:
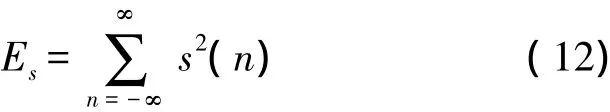
信噪比定义为:

4 基于PSO-EPF粒子滤波的语音增强算法
基于语音参数模型的语音增强问题可以归结为从带噪语音y1:t={ y1,y2,…,yt}中估计纯净语音x1:t= {x1,x2,…,xt}的贝叶斯滤波问题,在此,我们利用粒子滤波器来实现对非线性非高斯序列的实时跟踪。
选取语音模型状态为
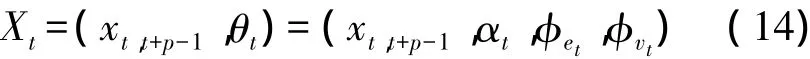
假设语音参数满足一阶马尔可夫随机过程

则上述状态变量的转移概率密度为
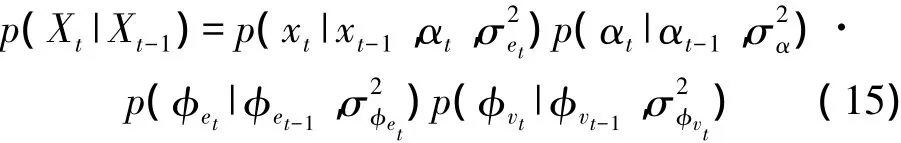
系统的观测模型为

以下是基于改进粒子滤波的语音增强的算法流程:
(1)初始化
设置粒子数目N,指定N个初始权重,从先验分布p(X0)中采集粒子,其中,再设置粒子初速度X =给定初始值为常量;设置惯性权重λ,速度调节参数η,求解初始时刻全局最优解
(2)重要性采样
①调整粒子的速度和位置
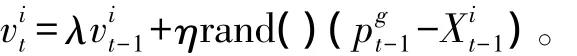
②根据EKF算法对每个粒子状态进行更新,即在EKF算法重要性采样中将EKF算法重要性采样中状态k时刻的状态估计改为
⑤粒子权值更新。
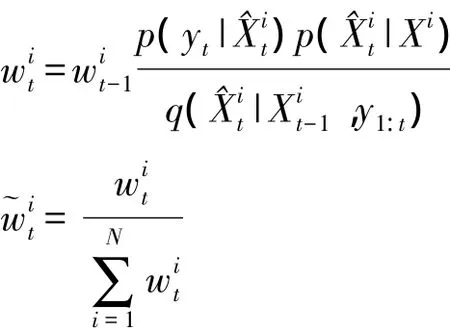
(3)重采样
消除权值较小的粒子,复制权值较大的粒子,当满足重采样条件时,获得N个随机样本,从近似服从分布p(X0: t|y1: t)为每一个再采样之后的样本粒子赋给相同的权值,即:当i=1,2,…,N,有=1/N。 (4)计算t时刻目标状态的后验概率估计Xt=
(6) t = t+1,返回重要性采样步骤,递推估计下一时刻的目标状态的后验概率
5 系统整体架构与硬件设计
助听器自适配系统主要包含三个要素:助听器、患者和自适配平台。系统工作流程为:助听器根据算法参数处理输入声音,并输出处理后的声音给用户;用户接收助听器输出的声音并按照其主观标准进行评价;评估的结果反馈给自适配优化模型进行参数的优化调整,并返回给助听器。
本文设计的助听器自适配系统的硬件构成如图2所示。各模块具体参数与指标如下: (a)麦克风:一路驻极体麦克风/耳机接口,用于语音信号采集、处理和回放; (b)语音编解码模块:采用CS5368高速音频语音编解码芯片; (c)核心微处理器模块:采用Samsung公司出品,业界广泛使用的S5PV210微处理器; (d)外部接口:串口、音频接口以及其他接口; (e)存储模块:本地存储或者通过计算机接口存储在计算机上; (f)扬声器:将经过处理的音频信号转换为可以感知的声信号; (g)人机交互模块:使用PDA或智能手机用于反馈患者信息,并通过无线方式反馈给A8处理器。

图2 系统硬件结构图
在平台设计中,语音编解码模块和核心处理模块相对比较重要。语音编解码模块采用Cirrus Logic公司推出的一款模拟数字音频转换器集成芯片CS5368,完成8路差分模拟输入信号的同步采样。核心处理模块主要包含内部时钟模块、FPGA采集模块和信号处理模块。FPGA采集模块主要用于实现模数转换芯片的采样控制、采样数据的串并转换处理以及数据的缓存和传输;信号处理模块主要完成采样数据的处理和各种算法的实现;时钟模块则负责为各个模块提供准确的时钟信号。设计中采用ASIC+FPGA的设计理念,其好处在于利用FPGA的并行处理能力,提高数据的吞吐率;同时保证ASIC只负责信号的运算处理,提高系统的运算效率。
6 实验仿真与结果分析
在实验中,分别利用EKF算法、PF算法、PSOEPF算法对带噪语音信号进行增强,进行100次蒙特卡罗仿真。采用的语音材料为自己录制,纯净语音为女声“人尽其才,团结合作”,噪声为录制的生活噪声,时长为2.5 s,语音和噪声信号经8 kHz采样、16 bit量化为数字信号,并在计算机中按一定比例混合生成不同信噪比的带噪语音,其信噪比变化范围为0 dB到10 dB。使用的粒子滤波的粒子数为200,在实验中,TVAR模型的阶数为10,如图所示:图3为纯净的语音信号,图4为带噪的语音信号,其初始信噪比为0.09 dB。
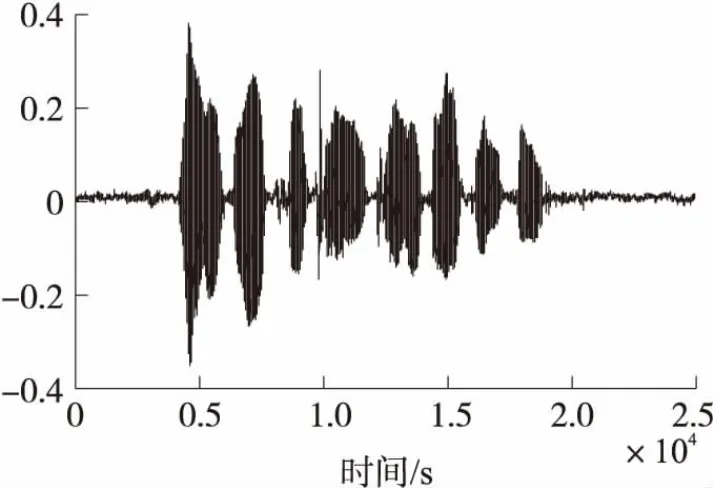
图3 纯净语音信号
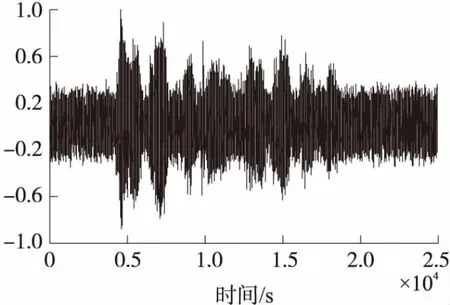
图4 带噪语音信号
在以上语音的基础上,使用MATLAB在PC上进行仿真实验,来比较带噪语音通过EKF算法、PF算法、PSO-EPF算法一次语音增强后的波形图。
由图5~图7可知,使用PSO-EPF算法处理后的带噪语音信号与纯净语音信号最为接近,也说明了它语音增强的效果最好。
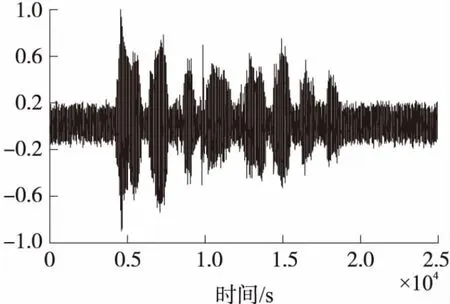
图5 EKF算法处理后的语音信号
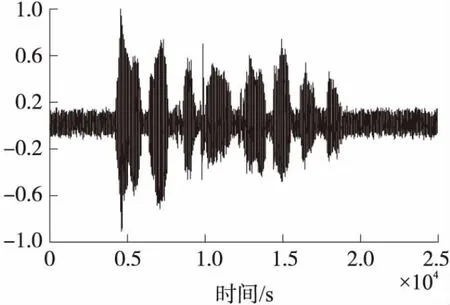
图6 PF算法处理后的语音信号

图7 EPF-PSO算法处理后的语音信号
下面从信噪比角度来说明,在不同的信噪比下,各种算法的语音增强效果如表1所示。
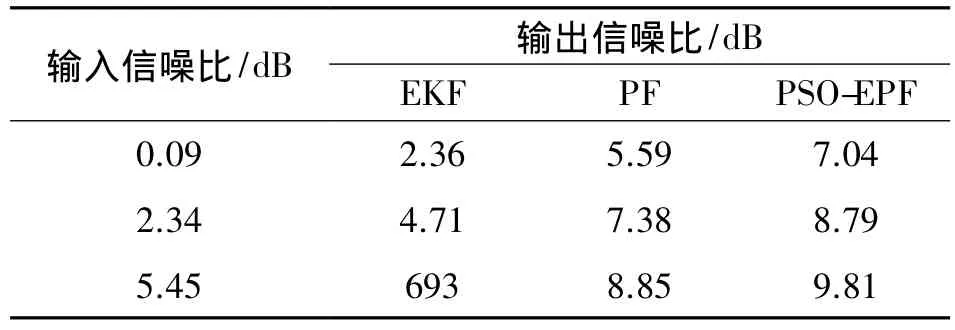
表1 不同信噪比下的语音增强效果
从表1可以看出,对于带噪语音信号,3种算法都能在一定程度上增强语音信号,表明TVAR模型可以很好描述语音信号的变化特性。而PSO-EPF算法对TVAR模型参数的估计能力比PF算法、EKF算法要有更好的效果,从而也具有更强的滤波降噪、增强语音的能力。
由前文可知,粒子数目对粒子滤波器的估计性能有很大的影响,因此选择不同的粒子数来进行100次蒙特卡罗仿真,对带噪语音进行语音增强,输入信噪比设定在0.09 dB,增强效果如表2所示。

表2 不同粒子数目下的语音增强效果
由表2可见,随着粒子数目的增加,经过PF算法和PSO-EPF算法进行语音增强后,语音信号的信噪比得到增强,对TVAR模型参数的估计更加准确,但是增加粒子数目的同时,也使得计算量增大。所以,我们在选择语音增强算法时,要协调好粒子数目和SNR的关系,以便可以达到最好的语音增强效果。
7 结论
目前在数字助听器中,麦克风阵列的技术得到日益广泛的应用。使用这种技术的原因来自几个方面:首先,在有噪声的环境下助听器在增强目标语音信号幅度时也增强了噪声的幅度;其次,在有混响时助听器不仅增强了直接到达的语音信号也增强了后来经过反射后到达的语音;再者,助听器的输出反馈会削弱助听器的频率响应。因此一个优异的助听器不仅能增强幅度,而且要提高信噪比、减小混响影响并消除反馈。由于传统的基于粒子滤波语音增强算法不能很好地逼近实际的后验分布,影响了估计精度,同时也导致了粒子的退化。对此本文提出了一种基于粒子群优化的改进粒子滤波算法,它将语音增强问题转换为从带噪语音中对纯净语音的估计过程,引入粒子群优化的方法来产生建议分布,使降噪结果更接近纯净语音,从而得到更好的语音增强效果。
参考文献:
[1]Hu H T,Yu C.Adaptive Noise Spectral Estimaton for Spectral Subtraction Speech Enhancement[J].Signal Processing,IET,2007,1(9) : 156-163.
[2]王振力,张雄伟.基于分数阶谱相减的语音增强方法[J].电子信息学报,2007,29(5) : 1096-1100.
[3]Kalman R E,A New Approach to Linear Filtering and Prediction Problem[J].Trans ASME J Basic Engineering,1960,82: 34-45.
[4]Vermaak J,Andrier C,Doucet A.Paticle Methods for Bayesian Modeling and Enhancement of Speech Signals[J].IEEE Transactions on Speech and Audio Processing,2002,10(3) : 173-185.
[5]金乃高,殷福亮,王冬霞,等.基于子带粒子滤波的一种语音增强方法[J].通信学报,2006,27(4) : 23-28.
[6]Lim J S,Oppenheim A V.A11-Pole Modeling of Degraded Speech [J].IEEE Transactions on Acoustics,Speech and Signal Processing,1978,26(3) : 197-210.
[7]Grenier Y.Time-Dependent ARMA Modeling of Nonstationary Signals[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1983,3l(4) : 899-911.

戴红霞(1970-),女,1991年6月获苏州大学工学院电子工程系无线电技术专业工学学士学位,2006年10月获东南大学信号与信息处理专业工学硕士学位,现任江苏信息职业技术学院电子信息工程系教授,研究方向为电子与通信、信息与信号处理等。
Research on Wireless Voice Communication of GSM Multifunctional Base Station
LIU Hui,WAN Guojin*
(College of Information Engineering,Nanchang University,Nanchang 330031,China)
Abstract:Voice communication function is realized for a multifunctional base station working on GSM networks based on its ability to induce cell phones to work on it.Firstly,voice services system is designed for the station.Then,the function of transferring original voice to voice sending bursts is added to it.Lastly,the station induces a cell phone to work on it to test the voice function.Eventually,the voice communication function with the ability to handle call exception is implemented according to functional and performance requirements of the station.Besides,compared with commercial base station,some improvements have been done.Measured results confirm that the station can send voice to a cell phone working on it.
Key words:GSM multifunctional base station; voice communication function; voice services; voice sending bursts; handle call exception
中图分类号:TN912.34
文献标识码:A
文章编号:1005-9490(2015) 03-0606-05
收稿日期:2014-06-24修改日期:2014-07-17
doi:EEACC: 6002; 6220M10.3969/j.issn.1005-9490.2015.03.027
