一种基于海量语料的网络热点新词识别方法
2015-02-24张海军闫琪琪
张海军 ,李 勇 ,闫琪琪
1.新疆师范大学 初等教育学院,乌鲁木齐 830054
2.新疆师范大学 计算机科学技术学院,乌鲁木齐 830054
1 引言
随着时代进步和网络技术的发展,作为人类信息传播的载体——语言在不断地发展和进化。表现形式为,网络新词语的大量产生,如:“下海”、“炒股”、“海归”、“非典”、“超女”、“山寨”、“动车组”、“屌丝”等,据统计,每年网络新词产生的数量大约800个[1]。新词语的大量产生,丰富了语言,方便了交流,但也给语言自动处理带来了诸多障碍,包括信息检索、语言分析、机器翻译、网络热点追踪等。为使相关处理顺利进行,需要将新词检测和识别出来,因而就产生了新词识别技术。
汉语没有缺少形态变化,且词语没有边界,这导致新词识别需要更多的智力因素。针对新词识别问题,国内外的很多研究人员都开展了大量的研究。在研究中将新词识别分成了三个阶段[2],即候选新词提取,新词检测和新词属性识别,并分别在上述三个方面开展了大量研究。
2 相关研究
对于候选新词提取,目前研究中主要有两类方法,基于单字散串和基于高频重复模式方法[3]。基于单字散串方法的出发点是,新词在分词过程中不能被有效识别,会被切分成单字串,因此分词后的单子串或由单字和相邻串组合成的散串就极有可能是新词。基于重复模式方法的出发点是,新词具有相对较高的使用频率,因此将语料中出现的重复模式作为候选新词。因召回率高,高频重复模式方法在候选新词提取研究中受到了广泛重视。刘挺等[4]使用局部频率作为候选词提取的标准。郑家恒[5]、邹刚[6]、崔世起[7]以及罗智勇[8]、贺敏[9]和黄玉兰[10]等在对语料进行重复模式统计的基础上,将满足阈值约束条件的重复模式作为候选新词,然后使用规则或统计方法进行过滤。在此类方法中,关键是研究能快速有效地从大规模语料中提取重复模式的方法,但目前的重复模式提取算法在处理汉语这样的大字符集的大规模语料时还存在一定局限。基于高频重复模式方法一般不需大规模训练语料的支持,且能有效地提取新造词,但对于低频词的提取会受到一定限制,对新词过滤机制要求较高,因没有训练语料作为指导,在候选新词提取时会产生大量非词垃圾串,严重影响新词检测的效率和效果。
在已经获得候选新词的前提下,新词识别的任务就转换为新词检测和过滤,但该阶段需要大量的智力因素。该任务的目的是检测新词,并为新词属性识别提供处理对象。目前主要的过滤技术是应用规则以及统计方法过滤新词[5-8,11-12]。这些研究方法,虽都涉及了候选字串的统计和语言知识特征,但一般采用相对简单的处理方法,没有将统计特征和语言知识加以有效融合来充分发挥组合特征的作用,导致在新词检测时对训练语料的依赖性较强,方法的适应性和领域泛化能力较差。
对于网络新词属性识别,目前研究集中在新词词性猜测方面,研究方法以统计方法为主[13-16]。根据所用特征不同,主要有应用内部特征方法、外部特征方法和组合方法。其中外部特征包括:上下文信息(相邻的词,相邻的字以及相邻标记);整篇文档信息等。内部特征包括:字串长度;前缀(后缀);字串中字符的具体特征(位置,词性)等[17]。上述研究方法,虽然取得了很好词性猜测效果,但在模型中应用了不现实的上下文词性特征,使实际应用受到了极大影响。
对于将上述三个模块有效整合,并形成有效的网络新词识别框架,邹刚[6]和贺敏[9]在这方面做了大量工作,并构建了基于网络的新词识别框架。
但目前研究中存在三方面问题,第一是研究中处理语料规模有限,一般都远小于内存规模,还不能称为大规模语料;第二是在候选新词过滤过程中没有很好地整合统计特征和语言知识特征,导致识别效果有待提高;第三是对于新词属性识别的效果还有待改进,新特征挖掘不充分。
针对上述三个方面的问题开展了针对性的研究,形成了一个有效的基于海量网络语料的新词识别框架。本文的主要创新之处包括:提出了基于逐层剪枝的大规模语料重复模式提取算法、基于统计学习模型的新词检测方法以及基于组合特征的新词属性识别方法。
3 基于海量语料的网络热点新词识别框架
根据前期的大量调研,做了相应研究和规划,将新词识别的几部分内容进行了整理,形成了一个整合的新词识别框架,具体结构参见图1。
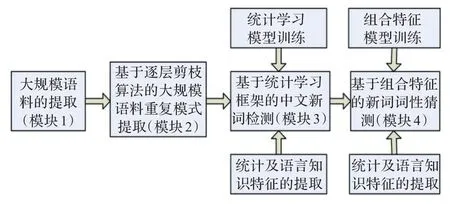
图1 基于海量语料的网络热点新词识别框架图
该新词识别框架中包含了4个主要的模块,它们在网络新词的识别过程中,依次开展工作,在层次上是一种递进关系,即第一步取得大规模汉语语料资源,第二步获取文本中重复串,形成候选新词集合,然后对候选新词进行检测,最后针对所提取的新词进行属性识别。
模块1是网络新词识别的起点,用于从网络等环境提取大规模文本语料,其中还包含将网页格式的文件转化为普通文本格式操作,其主要任务是为后续的重复模式提取做好准备。
为了提高候选新词的召回率,本文提出了基于逐层剪枝的大规模语料重复模式提取算法作为候选新词的提取方法(模块2);为了提升新词检测和新词词性猜测效果,采用在统计学习框架下,组合使用统计特征和语言知识特征来提高新词检测(模块3)和新词词性猜测(模块4)的效果。整个框架中,后3个模块是关键,本文主要针对这3个模块开展了大量研究,以下就重点介绍对这3个模块所做的工作。
3.1 基于逐层剪枝(HP)的大规模语料重复模式提取方法
大规模语料的重复模式快速提取是基于重复模式新词识别技术的基础和关键步骤,用于构造网络热点新词的候选对象集合,本文采用频率高于阈值的重复模式构造候选新词集合。重复模式提取的最大问题是会在中间产生大量的低频垃圾字串,严重降低处理效率。
通过对中文字串重复模式性质的研究,设计了逐层剪枝方法来过滤垃圾字符串,提高处理速度。操作步骤是,在递增N-Gram模型的基础上,逐层地进行低频垃圾字串剪枝和过滤,以充分减少垃圾字串的数量。具体地,先提取2字长的重复串集合,然后使用2字串集合过滤3字串,使用3字串集合过滤4字串,……,直到最大串长的重复串提取完成。当语料规模大于内存容量时,还需要先进行分割,分块提取候选重复模式,最后再进行全部候选模式的归并。
对低频垃圾字串的逐层剪枝算法,是基于对重复模式性质的观察和研究:
(1)对于候选模式R中的任意字符cx,如果有cx∈Σ0(Σ0为出现频率低于阈值λ的字符集),必然会存在f(R)<λ(即该字串R的频率小于阈值λ),因此可将模式R滤掉,从而在字符层面上实现低频模式剪枝。
(2)对于模式X=ciR1或X=R2cj,其中X,R1,R2为字串,ci或cj为字符,当R1∈φ且R2∈φ时(集合φ中字串频率大于等于λ),X可作为候选重复串,否则,将X过滤掉,这是逐层剪枝的判断规则。
这两个重复模式剪枝规则形式简单,应用方便,数据实验表明,该剪枝算法可将80%以上的出现频率低于阈值的垃圾字串滤出。
为处理容量远大于内存的海量语料,需要提前对语料分块,便于在内存范围内高效处理。为获取整个语料满足阈值约束的重复模式全体,需对从所有分块中所提取的候选重复模式进行外部排序。外部排序包含内部排序和外部归并两步操作,已经研制了一种中文字符串的快速排序方法[18],时间复杂度为O(dn),有效提高了重复模式归并效率。
3.2 基于统计学习框架的新词检测方法
在已经取得候选新词集合的前提下,新词检测的任务就是以重复字串的各种有效特征作为标注条件,对候选字串进行标注过程。经观察和分析,候选字串标记的概率估计可表示为:
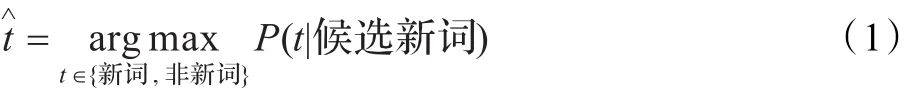
其中候选新词的标记集为:{新词,非新词},式(1)可转化为:

因候选字串本身和标记之间先验知识未知,考虑用关键特征来代表候选字串,前提是关键特征要能充分代表候选字串。这样候选字串与标记t之间的联系就转化为关键特征集合与标记t之间的关系,即在特征与标记t之间建立起了有效联系[19],据此式(2)可转化为:

其中FS表示候选字串的关键特征集。若根据式(3)对训练关键特征和标记集合,即可取得候选字串与标记集合间的概率。鉴于条件随机场模型不要求所用特征之间具有独立性,可用之有效地整合能代表候选字串的各种关键特征。
对条件随机场模型所用特征进行列举和编号(括号内为特征编号,便于后续分析):前缀(1)、双字前缀(2)、后缀(3)、双字后缀(4)、命名实体后缀(5)、串长(6)、串频(7)、互信息(8)、色子矩阵(9)、左熵(10)、右熵(11)。其中,前后缀、字串长度、命名实体后缀是候选字串的基本信息;字符串频率是重要的统计信息,用于统计字串是否频繁出现,来自于重复模式提取阶段,某一字符串是否出现在候选字符串集合中在于其频率是否高于频率阈值。左右熵等用于检验字串作为整体的前后文搭配的灵活程度。互信息和色子系数用于计算字串整体结合的牢固程度。
3.3 基于组合特征的新词词性猜测方法
新词词性猜测是新词识别的关键阶段,是网络热点新词识别的重要环节。针对目前研究方法中存在的问题,采用的方法是:对新词词性猜测过程中使用的上下文标记,由于新词的词性尚未确定,其上下文的词性标记也未确定,考虑采用多遍的扫描方式,通过第一遍扫描来获得新词的上下文词性,第二遍扫描应用新词的内部特征和外部特征组合来猜测新词属性;通过挖掘新词的内部特征,来提高新词词性猜测的准确率,初步思路是在前期研究的基础上,考虑将汉字的偏旁作为新的内部特征,来提高词性猜测准确率。
中文词法分析的特有难点在于,词语没有形态标记;但作为表意文字,如果能充分挖掘汉字的表意特征,即可增加汉字分析的有用信息,提高处理效果。从字理分析,偏旁能在代表部分字义。如:如提、拉、打、拽都是“扌”旁,与动作相关;思、想、念、志都是“心”旁,与心理活动相关;江、河、湖、海都与水相关等。随着汉字演化,虽然许多偏旁都产生了变形,但并不影响其表意功能,比如,“水”和“氵”、“心”和“忄”、“火”和“灬”等都具有相似功能。从统计分析来看,具有偏旁表义的汉字在常用汉字中占据了绝对多数。文献[20]对3 500个常用汉字做统计,有3 204个偏旁表意的汉字,占总数的91.4%。由于词性与词义密切相关,偏旁与词性必然具有内在联系。
在上述思路基础上,本文考虑使用CRF模型作为统计框架,通过两遍扫描,在上下文特征的基础上,增加偏旁作为词性猜测特征,提高新词属性识别的效果。
4 实验和数据分析
进行了大量实验用于验证新词识别框架的各项性能。因涉及3个算法性能验证,实验中使用了多种语料和工具。验证基于逐层剪枝的大规模语料重复模式提取算法所用的语料为搜狗实验室提供的大规模中文网络语料(SogouT);验证新词检测以及新词词性猜测方法所用语料是北京大学1998年1月公开版的标注语料(下称199801)及兰卡斯特大学的平衡标注语料(下称LCMC);实验中的CRF训练及解码工具为“CRF++0.52”开源工具;实验软硬件环境是windows XP(SP3),2 GB内存。
4.1 基于逐层剪枝算法(HP)的大规模语料重复模式提取实验及分析
为了验证算法的正确性,使用了10 kB的纯文本语料,采用手工方法标注所有频率阈值为2字串长度从2到10的重复模式,实验结果该方法的准确率和召回率皆为100%;使用10组1 MB的纯文本语料,采用递增的N-gram重复模式提取方法作为基准,针对频率阈值为2字串长度从2到10的重复模式进行实验,结果该方法所有重复模式提取的准确率和召回率皆为100%。从实验的角度来讲,该方法能准确可靠地从语料中提取重复模式。
针对不同规模的语料,处理频率阈值为10模式长度从2到10,该算法的处理速度参见表1。
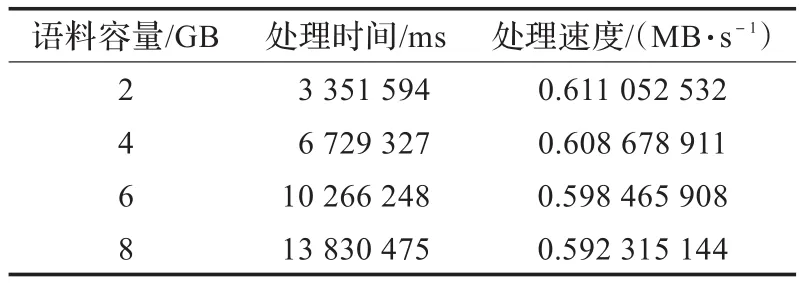
表1 算法处理速度表
从表1中可见,随着语料规模的增长,重复模式提取速度有所降低,但基本保持在0.59 MB/s左右;该方法特别适用于大规模语料的高频重复模式提取,当频率阈值进一步增大时,处理速度会得以更为显著的提升。
为分析逐层剪枝算法(HP)对I/O读写次数的影响,对比不用HP方法,进行了多组相同语料的平行实验,结果详见表2。可见对相同容量的语料,使用HP过滤较不用过滤相比,读写数据量都有大幅度减少。为便于分析,定义过滤比来标识HP过滤效果,定义如下:
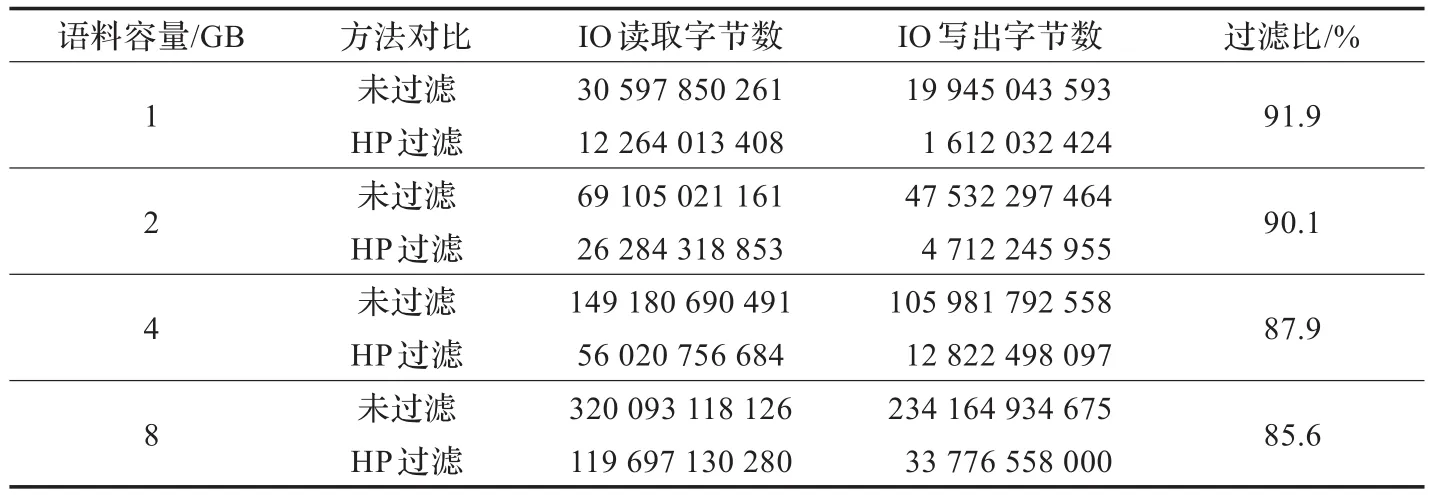
表2 平行对比实验结果

根据表2中的数据,使用HP进行低频字串过滤,能将85%以上的垃圾字串滤去;可见HP具有非常明显的过滤效果,能有效降低I/O的读写次数,提高重复模式查找效率。但随着语料规模的增长,过滤比会逐渐降低,这是因为随着语料规模的增长,字符之间的组合变得更加复杂,造成越来越多垃圾字串通过HP过滤,进入到候选重复模式集合中,导致过滤效果有所降低。
在处理语料规模大于内存容量的重复模式提取方法中,文献[19]所提出的是比较有代表性的方法,但因实验条件和实验语料不具有可比性,本文没有进行量化比较分析。因I/O读写速度要远远地低于内存处理速度,当语料规模超过内存容量后,对于I/O的操作次数就成为衡量算法性能的关键指标。如在处理中文语料时,文献[21]中方法在语料规模增大到内存容量时其I/O操作次数约为汉字字符集规模,不超过7 000,当语料规模进一步增大时,需要进行二次划分,导致I/O操作次数成指数级增长,会严重影响处理效率;而本文方法的I/O操作次数同语料规模是一种准线性关系,因此对语料规模不敏感。前述实验中当处理规模为32 GB的中文语料时,其I/O操作次数约为16.3+6.3=22.6次。当然,文献[21]中方法适用于并行计算,若在并行环境中其处理效率会非常高,而本文算法因需要逐层剪枝和全局垃圾字串过滤,难以用于并行环境中。
4.2 新词检测实验及分析
在重复模式集合的基础上开展候选新词检测实验。训练语料和测试语料分别为前面提到的北大的199801和兰卡斯特大学的LCMC语料,在开放条件下,实验数据参见表3。
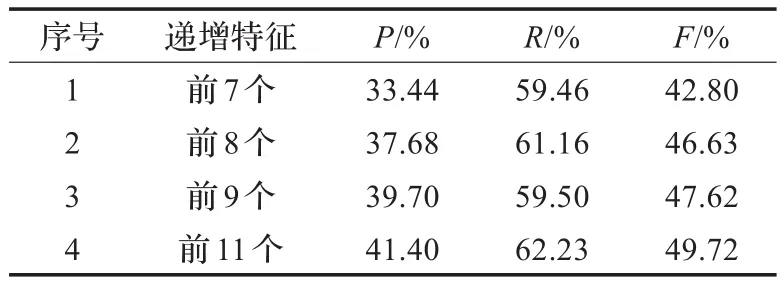
表3 递增特征实验数据表
从表3可见,随着有效特征的加入,新词检测的效果在稳步提高。多特征组合可以发挥特征之间的综合作用,比特征的简单组合具有更好的新词检测效果,实验4(11个特征组合)已很好地说明了这一点[19]。
贺敏[11]取得了较好的新词检测效果,在相同的封闭实验条件下,对比检测实验数据参见表4。
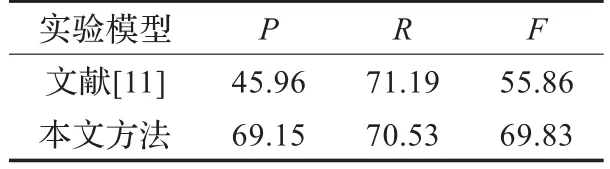
表4 对比数据表 %
从表4对比分析,文献[11]中召回率较高,本文在准确率和综合性能方面效果稍好。分析原因,可能是文献[11]采用的实验语料规模很小,其性能没有完全发挥。但从总体上看,本文所用的统计模型方法能有效整合不同类型的多个特征,凸显特征间的合力作用。
4.3 新词词性猜测实验及分析
为比较特征在词性猜测中所起的作用,使用组合特征进行对比实验。所用特征包括:外部特征(下称EF)、未登录词本身(下称W)、词缀、词长和词缀偏旁,实验结果参见表5。
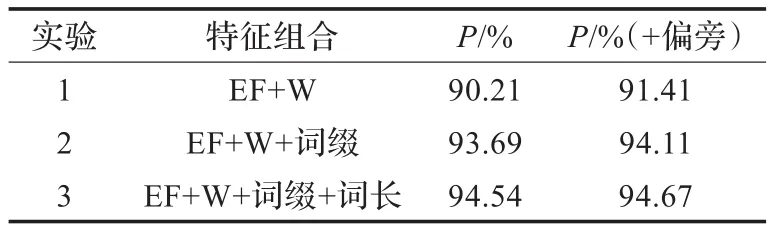
表5 对比实验数据
在外部特征和词语本身的组合作用下,随着词缀、词长及偏旁特征的依次加入,词性猜测的准确率由90.21%最终提高到94.67%,可见多种特征的共同作用是提高词性猜测准确率的可靠方法[17]。
根据表5对比可见,“偏旁”特征的表义作用是明显的,能有效提高词性猜测的效果。根据对比,使用“偏旁”数据,3个对比实验的准确率依次提高了1.2,0.4和0.13个百分点。可见汉字偏旁特征的加入,增加了词性猜测的有用信息,改善了词性猜测效果。在表6中列出了具体的准确率分布数据。
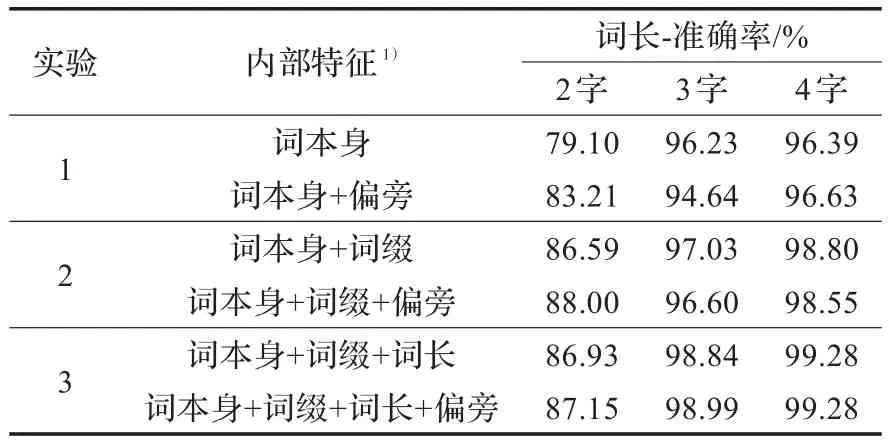
表6 词性猜测效果详细数据
随着“偏旁”数据的加入,在实验1中,2字、3字及4字长词词性猜测准确率的提升依次是:+4.11、-1.59和+0.24;在实验2中依次为:+1.41、-0.43和-0.25;在实验3中为:+0.22、+0.15和0.0。说明“偏旁”特征,能显著提高2字词的词性猜测准确率,但对词长大于2词的作用却不明显。分析其原因有二:(1)在短词中字义与词性关联较大,而长词因多字组合会冲淡词性与字义间的关联;(2)因特征模板限制,对2字词偏旁能完全覆盖整个词,而对于长度大于2的词偏旁特征数据只能涵盖首尾,这也是造成其对“长词”作用不显著的原因。
目前的研究成果中,Lu[22]和Qiu[16]所采用的方法具有代表性,效果也较好。Qiu等综合应用了内外特征,使词性猜测准确率达到了94.2%,是目前的最好水平。对比数据参见表7。
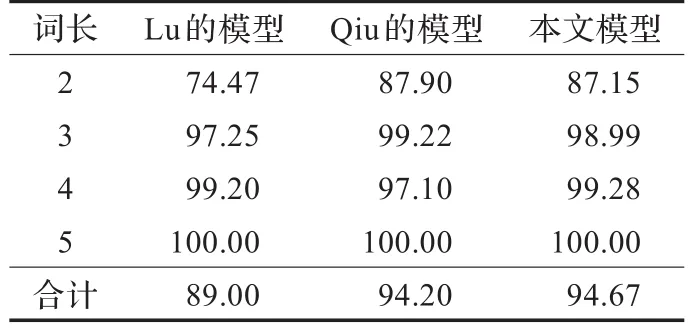
表7 相关方法数据比较表 %
从2,3字词的词性猜测准确率来看,Qiu的模型效果较好;而本文模型4字词效果稍好,总体性能比之提高了0.47%。从操作层面,Qiu的模型需要预先分词、计算词性猜测的置信度及使用搜索引擎分析新词的全局特征;而本文模型使用两次扫描提取外部特征,通过字串处理和查表取得内部特征,进而实现词性快速猜测,因此该方法相对简单方便。
5 结论和进一步工作
在大量调研和研究的基础上,本文构造了一个基于网络语料的热点新词识别框架。该框架由4个主要模块组成,本文重点研究和阐述了所提出的基于逐层剪枝算法的大规模语料重复模式提取、候选新词的检测以及新词的词性猜测方法,通过大量实验验证了所述方法的有效性。实验表明,逐层剪枝算法能将85%以上的垃圾模式预先过滤出去,并能从容量远大于内存的语料中提取重复模式;通过统计模型来有效整合统计特征和语言特征,并深入挖掘新特征,可以有效提高新词检测及新词词性猜测的效果;根据实验数据,该框架的新词检测和词性猜测效果分别为69.83%和94.67%,是目前的较好水平。
对于新词检测,“长词”需要进一步开展深入研究,而对于词性猜测,“短词”的效果需要进一步加强,这两个方面是研究需要深入开展之处。下一步工作是在现有研究基础上,将基于重复模式的方法扩展到大规模语料的领域术语识别的研究中,通过提取重复模式的方式提取候选领域术语。
[1]黄昌宁,赵海.中文分词十年回顾[J].中文信息学报,2007,21(3):8-19.
[2]张海军,史树敏,朱朝勇,等.中文新词识别技术综述[J].计算机科学,2010,37(3):6-10.
[3]Zhang H J,Huang H Y,Zhu C Y,et al.A pragmatic model for new Chinese word extraction[C]//Proceedings ofthe 6th InternationalConference on NaturalLanguage Processing and Knowledge Engineering,Beijing,China,2010:91-98.
[4]刘挺,吴岩,王开铸.串频统计和词形匹配相结合的汉语自动分词系统[J].中文信息学报,1998,12(1):17-25.
[5]郑家恒,李文花.基于构词法的网络新词自动识别初探[J].山西大学学报:自然科学版,2002,25(2):115-119.
[6]邹纲,刘洋,刘群,等.面向Internet的中文新词语检测[J].中文信息学报,2004,18(6):1-9.
[7]崔世起,刘群,孟遥,等.基于大规模语料库的新词检测[J].计算机研究与发展,2006,43(5):927-932.
[8]罗智勇,宋柔.基于多特征的自适应新词识别[J].北京工业大学学报,2007,33(7):718-725.
[9]贺敏.面向互联网的中文有意义串挖掘[D].北京:中国科学院研究生院,2007.
[10]黄玉兰.有意义串挖掘及其应用[D].北京:中国科学院研究生院,2009.
[11]贺敏,龚才春,张华平,等.一种基于大规模语料的新词识别方法[J].计算机工程与应用,2007,43(21):157-159.
[12]Luo S,Sun M.Two-character Chinese word extraction based on hybrid of internal and contextual measures[C]//Proceedings of the 2nd SIGHAN Workshop on Chinese Language,Sapporo,Japan,2003:24-30.
[13]Wu A,Jiang Z.Statistically-enhanced new word identification in a rule-based Chinese system[C]//Proceedings of the 2nd Chinese Language Processing Workshop,Hong Kong,China,2000:46-51.
[14]Peng F,Feng F,McCallum A.Chinese segmentation and new word detection using conditional random fields[C]//Proceedingsofthe20th InternationalConferenceon Computational Linguistics,Switzerland,2004:562-568.
[15]Nakagawa T,Matsumoto Y.Guessing parts-of-speech of unknown words using global information[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics,Sydney,Australia,2006:705-712.
[16]Qiu L,Hu C,Zhao K.A method for automatic POS guessing ofChinese unknown words[C]//Proceedings of the 22nd International Conference on Computational Linguistics,Manchester,2008:705-712.
[17]张海军,冯冲,史树敏,等.一种基于组合特征的新词词性猜测方法[J].小型微型计算机系统,2010,31(7):1402-1406.
[18]张海军,潘伟民,木妮娜,等.一种自定义顺序的字符串排序算法[J].小型微型计算机系统,2012,33(9):1968-1971.
[19]张海军,栾静,李勇,等.基于统计学习框架的中文新词检测方法[J].计算机科学,2012,39(2):232-235.
[20]冯冲.统计方法信息抽取中的若干关键技术研究[D].合肥:中国科学技术大学,2005.
[21]龚才春,贺敏,陈海强,等.大规模语料的频繁模式快速发现算法[J].通信学报,2007,28(12):161-166.
[22]Lu X.Hybrid methods for POS guessing of Chinese unknown words[C]//Proceedings of the ACL Student Research Workshop,Michigan,USA,2005:1-6.
