基于向量自回归模型的GDP数据质量评估
2015-02-18廖传勤
党 玮,廖传勤
(石河子大学 商学院,新疆 五家渠 831300)
0 引言
我国通常用GDP来衡量国民经济的运行情况,由于各种因素的存在,GDP数据质量或多或少存在一定的问题。现任中国国务院总理李克强在2007年任辽宁省委书记时,通过运用工业耗电量、铁路货运量和贷款发放量这三个指标来分析当年辽宁省的经济运行状况,此衡量方法得到了花旗银行等众多国际机构的认可,英国《经济学人》2010年正式将其命名为李克强指数,以此作为评估中国经济增长量的指标。相对于GDP的统计,“克强指数”三个指标不仅数据易于核实,而且更符合我国的经济特征,与地方的GDP崇拜无关,更能挤出一般统计中的水分。三个指标从工业生产、能源消耗和经济运行状态三个方面更能真实、精确地反映我国经济运行现状。
对GDP数据质量的研究无论是从定性和定量的角度,还是从理论研究和实践操作方面,国内外学者都提出了许多有参考价值的见解。目前,对我国GDP数据质量评估的研究相对较少,孟连和王小鲁(2000)从我国地区GDP的汇总结果和国家统计局公布的GDP数据存在差异、通货膨胀和经济增长的关系出现偏差等方面进行分析,结果表明,1992~1997年中国的GDP高估了2.5个百分点[1]。Klein和Ozmucur(2002)采用了15个对中国经济具有广泛代表性的经济指标,利用主成分分析的方法进行分析后认为,各项指标的变动和中国官方估计的实际GDP的变动具有一致性[2]。刘洪、黄燕(2009)通过利用经典的最小二乘法估计得到生产函数,对我国某地区历年的地区生产总值,采用学生化残差、DIFFITS统计量、Cook的D统计量等经典的诊断统计量对数据中的异常点进行了诊断[3]。卢二坡、黄炳艺(2010)通过运用稳健的MM估计异常值的诊断方法,并在使用生产函数模型框架的前提下,用两种不一样的劳动投入数据,对1978~2008年我国GDP的数据质量进行了评估。研究表明,相对于传统方法容易掩盖异常点的现象,稳健MM估计异常值诊断的方法能有效地解决这种情况,研究表明,1978~2008年间我国GDP数据是比较可靠的[4]。李庭辉(2011)在对数据质量的评估现状进行整理的基础上,构建了由空间、时间和结构三个维度形成的GDP数据质量评估体系,并提出了完善GDP数据质量评估的方法[5]。陈黎明、傅珊(2013)选取1985~2010年我国的GDP数据作为研究样本,对我国GDP数据用误差绝对值和最小的组合预测模型进行预测,预测所得的值代表“真值”,再利用异常值对我国GDP数据的准确性进行分析,研究表明组合预测模型对统计数据准确性的检验具有较高的实用价值,值得进行深层次的研究[6]。李庭辉(2013)选取与各产业相应的指标,根据数据之间的关系选择VAR模型,结果表明全国产业的结构化数据和地区产业汇总后的结构化数据匹配性程度很高,我国GDP数据质量在总体上是较好的[7]。与已有文献不同的是,本文试图在运用“克强指数”来分析我国GDP数据质量的基础上,用VAR模型来判断两者之间是否匹配以及使用相对误差系数来判断我国GDP数据质量的可靠性。
1 我国GDP数据质量匹配因素的理论分析
GDP即国内生产总值是国民经济核算的核心指标,是以货币形式表现的一定时期内(一个季度或一年)一个国家(或地区)的经济中所生产出来的全部最终成果(产品和劳务)的价值总和。从“克强指数”与我国GDP的关联性即匹配性角度评估我国GDP的数据质量,主要应寻找与其具有关联性的统计指标作为匹配因素。与国内生产总值相关联的指标有很多,相对于其它指标而言,组成“克强指数”的三个指标更能真实、精确地反映我国GDP现状。因为,现代的工业生产与能源消耗密切相关,所以,工业耗电量的多少,既可以准确反映我国工业生产的活跃度,又可以反映工厂的开工率;铁路作为我国货运的最大载体,其“铁路货运量”的多少,可以反映经济运行现状以及经济运行效率;而对于间接融资占社会融资总量的比重高达84%的我国而言(银行贷款占了我国间接融资的大部分),既可以反映市场对当前经济的信心,又可以判断未来经济的风险度。由此可见,选取“克强指数”三个指标作为国内生产总值的核心关联性指标较为合适。
据此提出以下基本假设:国内生产总值GDP与工业用电量、铁路运输量和银行中长期贷款具有系统匹配性,且在时间上具有动态可变性,所以,从匹配性角度出发,需要选取反映动态系统结构的模型对我国GDP进行数据质量评估,而向量自回归模型(Vector Autoregression Model,简称VAR模型)恰好符合该特征,故可以采用VAR模型对我国GDP数据质量进行评估。
2 基于VAR的我国GDP数据质量评估模型的构建
2.1 指标选取及数据来源
根据前述理论分析及其基本假设,对我国GDP的数据质量进行评估主要涉及工业用电量(P)、铁路货运量(S)和银行中长期贷款(L)三个与之相匹配的指标。确定好指标以后,需要确定研究指标的数据频率和时间。因为国内生产总值没有月度数据,有的指标没有收集到季度数据,所以,本文选取GDP的年度数据来进行数据质量评估,数据来源于《中国统计年鉴》。数据的时间范围为1985~2012年(共28个数据),数据的空间范围是全国。本文采用EViews6.0软件进行分析。
2.2 基本理论模型的设定
根据GDP与“克强经济”三个指标的匹配关系和基于匹配性的GDP数据质量评估的假设,GDP与工业用电量、铁路货运量和银行中长期贷款四者之间存在较为稳定的相关关系、相互依赖的内在匹配性,利用VAR模型既可以判断四者之间是否匹配,还可以对它们之间的动态关系进行研究,进而对GDP数据质量进行评估,评估的基本思路是借助VAR模型来寻找GDP与工业用电量、铁路运输量和银行中长期贷款在一定经济条件下不相符的样本点。
根据向量自回归分析理论,得到基于匹配性的GDP的数据质量评估理论模型如下:
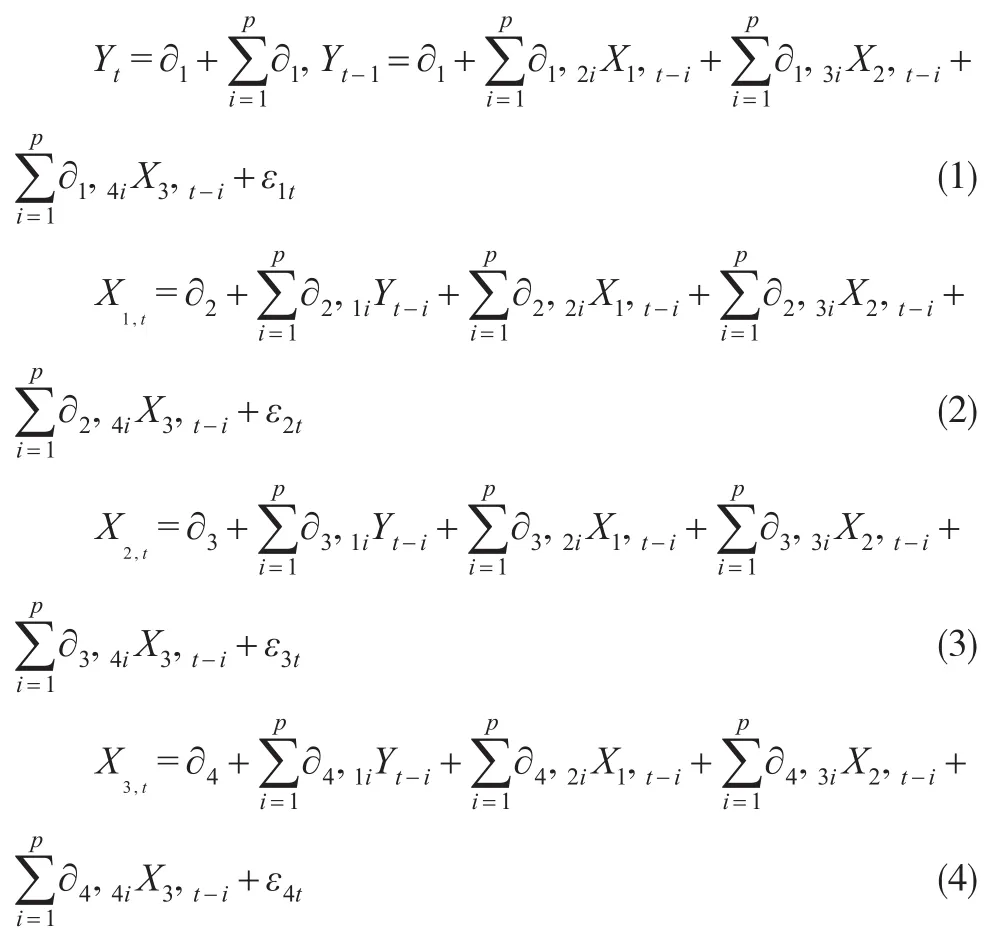
上式中,t为时间下标,Yt为第t期的GDP,X1,t为第t期的工业用电量,X2,t为第t期铁路货运量,X3,t为第t期银行中长期贷款。
3 基于VAR的GDP数据质量的评估实证
3.1 VAR模型的估计及检验
使用VAR模型,首先需要考察相关变量的平稳性,同时,为了消除异方差和指数化趋势,对纳入模型的相关变量均进行了取对数处理,取对数后的我国GDP、工业用电量、铁路货运量和银行中长期贷款分别记为lnGDP、lnP、lnS和lnL。本文采用单位根(ADF)方法对各变量进行单位根检验,结果如表1所示。
从表1可以看出,各变量原始序列的对数值均在10%的显著性水平上没有拒绝“存在单位根”的零假设,各序列都不平稳,但经过二阶差分之后P值都小于0.05,且ADF的值均小于10%水平下的临界值,拒绝“存在单位根”的零假设,所以原始序列对数的二阶差分是平稳序列。
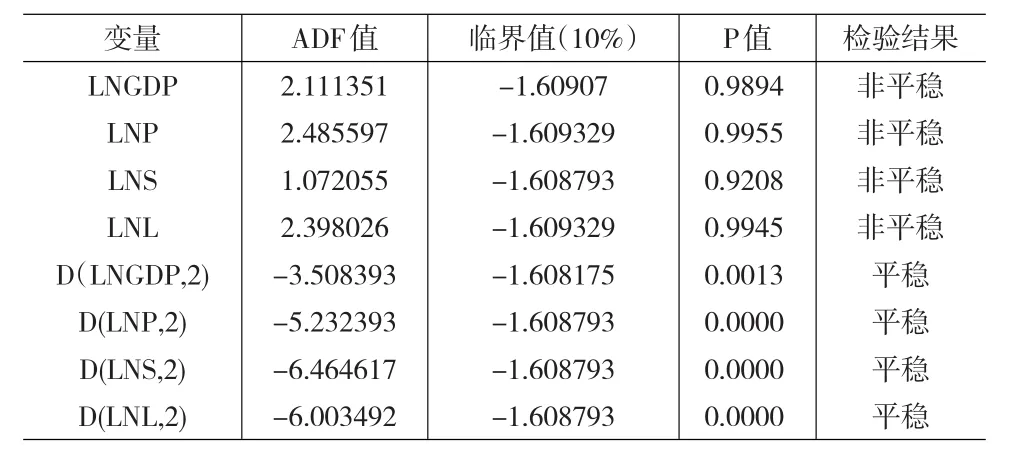
表1 单位根检验

表2 滞后期的选择
由表1和表2可知,我国GDP与工业用电量、铁路货运量和银行中长期贷款之间存在动态的依赖关系,因此可以建立无约束的VAR模型。根据赤池消息准则(AIC)和施瓦茨准则(SC),滞后期为1时的AIC(-15.57062)和SC(-14.60286)均小于滞后期为2时的AIC(-15.56664)和SC(-13.82466)所以确定最优滞后期为1,对模型进行参数估计,模型的整体拟合效果较好,进而得到GDP与工业用电量、铁路货运量和银行中长期贷款四个指标之间的回归方程:

模型的AIC和SC值分别为-15.57062和-14.60286都较低,通过检验模型是稳定的,即所有根的模的倒数都小于1,位于单位圆内。从模型的整体检验和参数的显著性检验结果可以看出,模型较好地刻画了我国GDP与工业用电量、铁路货运量和银行中长期贷款之间的动态结构与匹配关系,可以利用该模型对我国GDP的数据质量进行评估。
3.2 数据质量的判断标准
对GDP数据质量是否可疑,还需要给定判断标准,可以构造GDP相对误差系数指标作为判断标准。相对误差系数δt用来测量第t期实际的GDP与GDP估计数据的相对误差,如果相对误差超过某一标准时,则可认为该期GDP的数据质量可疑。其中,相对误差系数δt的计算公式为如果第t期的GDP统计数据相对误差系数的绝对值满足则认为该期GDP估计的相对误差较大,说明该期的GDP统计数据质量可疑。
3.3 评估结果及其分析
对GDP进行数据质量评估,表3中的GDP是取对数处理后实际的GDP的值,是取对数处理后估计的GDP的值,根据相对误差系数δt的计算公式得到δt的值。得到的结果如表3所示。

表3 GDP相对误差系数
GDP相对误差系数如表3所示,1985~2012年这28个年份中,GDP整体的数据质量整体较好,变动幅度相对较小,所有年份的GDP相对误差系数的绝对值都小于0.05,由表3可知,从“克强指数”与我国GDP匹配的角度来看我国的GDP数据质量在逐步改善。
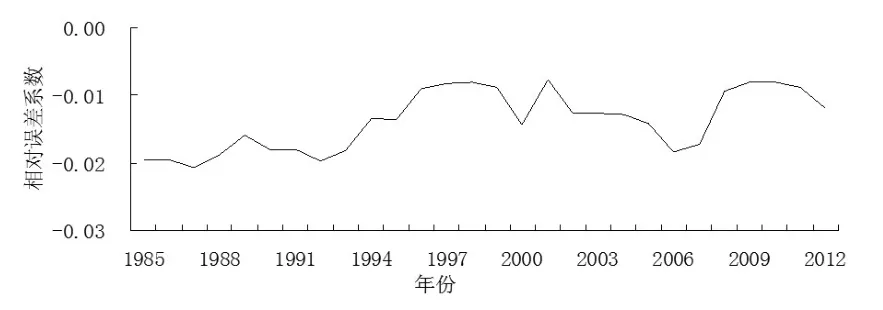
图1 基于匹配性的GDP数据质量评估结果
从图1可以看出,我国GDP的数据在允许误差范围之内,根据数据特征,可以将这28个年份分成3个阶段,1985~1992年、1993~1999年、2000~2012年,从图1可以明显看出,1985~1992年的相对误差系数变动较为平稳,但数据质量是这3个阶段中最差的,这是因为1985~1992年之间,我国处在MPS和SNA两种核算体系共存阶段,到1985年国家统计局才第一次计算国内生产总值,GDP核算制度在不断完善与发展之中。国家统计局在1992年才开始实施《中国国民经济核算体系(试行方案)》,从而使得1992年以前的GDP数据质量相对较差。1993~1999年的数据质量逐步改善是因为在1993年的十四届三中全会中全面的提出了建立社会主义市场经济体制,且我国使用SNA1993(联合国),使得1993~1999年的GDP数据质量逐步得到改善;在2000~2012年这十三年间,我国的社会主义市场经济已经相对的完善。2000年国家统计局制定了《中国国民经济核算体系(修改本)》(征求意见稿),广泛地征求理论和实际部门的意见。经过多年的实践,在总结经验的基础上,我国国家统计局颁布了《中国国民经济核算体系(2002)》。至此,我国国民核算模式实现了向SNA的全面转型,所以,该阶段内的GDP数据质量相对更好一些,变动幅度也较适中。我国GDP数据质量在总体上是不断提高的,近年来相对误差有逐渐减少的趋势,说明GDP数据质量整体上可靠,数据质量在不断地提升,其误差基本上控制在5%的范围之内。
4 结论
通过对我国GDP与“克强指数”相关指标数据匹配性的实证分析,发现我国1985年至2012年的GDP年度数据基本上在误差控制范围之内,且近几年数据质量有逐步提高之趋势,说明我国GDP统计数据质量整体上是比较可靠的。基于“克强指数”和GDP数据质量评估的基本理论,结合实证分析的结果,得到如下结论:
(1)基于我国的宏观经济数据,构建“克强指数”各指标与我国GDP匹配关系的VAR模型,模型显示“克强指数”各指标与我国GDP的具有较强的匹配性。
(2)从“克强指数”角度来分析的我国GDP数据质量整体上是较好的,“克强指数”为我们提供了一个全新的、真实的、客观的视角来衡量我国的GDP的运行与发展。研究表明,“克强指数”不仅与我国GDP之间存在密切地联系,且能在一定程度上更真实地反映我国GDP的运行和发展的现状。
(3)从相对误差系数的结果来看,我国GDP的数据质量存在阶段性的特征,我们可以将这些年份分成三个阶段。第一阶段为1985~1992年,数据质量相对较差;第二阶段为1993~1999年,数据质量有逐步改善的趋势;第三阶段为2000~2012年,数据质量整体较好[8]。这与我国的国民经济核算的改革有密切的关系。
[1]孟连,王小鲁.对中国经济增长统计数据可信度的估计[J].经济研究,2000,(10).
[2]Thomas G R.What's Happening to China's GDP Statistics[J].China Economics Review,2001,(12).
[3]刘洪,黄燕.基于经典计量模型的统计数据质量评估方法[J].统计研究,2009,(3).
[4]卢二坡,黄炳艺.基于稳健MM估计得统计数据质量评估方法[J].统计研究,2010,(12).
[5]李庭辉.基于匹配性的GDP数据质量评估体系构建[J].调研世界,2011,(11).
[6]陈黎明,傅珊.基于组合预测模型的GDP统计数据质量评估研究[J].统计与决策,2013,(8).
[7]李庭辉.基于地区产业结构匹配的GDP数据质量评估[J].统计与决策,2013,(19).
[8]薛丽娜,李正辉,李庭辉.基于地区投入结构的GDP数据质量评估[J].统计与决策,2012,(20).
