基于人工蜂群算法的岩体结构面多参数优势分组研究
2015-02-15宋腾蛟陈剑平项良俊杨俊辉
宋腾蛟,陈剑平,张 文,项良俊,杨俊辉
(吉林大学 建设工程学院,吉林 长春 130026)
1 引 言
岩体在其形成与存在过程中,长期经受着复杂的建造和改造两大地质作用,形成了各种不同类型和规模的结构面。岩体的力学性质不仅受岩体的岩石类型控制,更主要的是受岩体中结构面的控制,而结构面对岩体力学性质的影响主要取决于结构面的发育情况。如岩性完全相同的两种岩体,由于结构面的空间方位、连续性、密度、形态、张开度及其组合关系不同,它们的力学性质会有很大的差异[1]。由于结构面的各参数具有很强随机性与不确定性而无法采用确定性的方法进行研究,因此,对此类结构面各参数进行实地测量进而应用概率统计分析方法进行研究是十分有意义的。
目前,最常见的岩体结构面的统计分析方法是将具有某些共同特征的结构面归类,一般做法是按照结构面的产出状态进行优势分组。传统的分析方法是将结构面的产状数据投影到吴氏网或Schmidt 网上,辅以极点等值线图进行目测分析。显然,这种方法的可靠度在很大程度上依赖于分析者的专业素养和个人经验,分组结果缺乏必要的客观性。Mahtab[2]、Shanley[3]等首次应用聚类算法对结构面产状数据进行数学分析,但如何确定合理的小球半径一直未能得到有效地解决,从而限制了该方法的可操作性。陈剑平等[4]在该方法基础上进行了有益改进,提高了该方法的实用性。Hammah[5]应用模糊C 均值(fuzzy C-means,FCM)聚类算法对岩体结构面进行优势组数的划分。蔡美峰[6]、卢波[7]等针对FCM 算法的不足提出了各自的结构面产状优势分组方法。
两组结构面产出方向完全相同,而迹长和张开度等其他几何特征明显不同时,这两组结构面的力学性质和水力学参数将会存在较大差异。因此,仅根据结构面的产状进行优势分组必然存在本质上的缺陷,而考虑应用多参数对岩体结构面进行优势分组就显得非常有意义。为此,Behzad 等[8]采用K 均值聚类算法进行岩体结构面多性质数据的优势分组[9],并应用主成分分析(PCA)方法计算了实测数据协方差矩阵的特征值,从而证明了应用结构面多种性质进行优势组划分的重要性。Zhou 等[10-11]应用最近邻算法、K 均值聚类法、模糊C 均值聚类法和向量量化法根据结构面多种性质进行优势组数划分。K 均值聚类法、模糊C 均值聚类法都属于动态聚类算法,计算过程本质上属于局部搜索寻优过程。而最近邻算法和向量量化法存在计算量大且容易陷入局部最优解的缺陷。徐黎明等[9]提出了基于变尺度混沌优化算法的结构面多参数数据的优势组划分方法。但该方法具有盲目重复的缺点,而且搜索效率较低,运算时间较长。
现如今,岩体工程的规模愈来愈大。面对着大量纷繁复杂的结构面,寻找一种精度高、运行快且易于操作的岩体结构面多参数优势分组新方法是非常有意义的。
鉴于以上方法存在的不足,本文首先建立岩体结构面多参数优势分组问题的数学模型,然后运用现代生物群体智能算法中应用较为广泛的人工蜂群算法进行求解。此算法为2005年Karaboga[14]提出的,是一种较新的全局优化算法,具有较高的寻优精度和收敛速度。模拟数据测试结果表明,本文提出的方法具有较高的可信度。最后,将该方法用于松塔电站坝址岩体结构面的优势分组,取得了令人满意的分组结果,为坝址岩体的力学性质及水力特性分析及稳定性的评价提供了有力依据。
2 建立数学模型
2.1 结构面数据的表达
本文选取以下5个岩体结构面性质参数作为优势分组的依据:产状(倾向和倾角)、迹长、张开度和表面形态。结构面的产状(倾向α和倾角β)与最大主应力的关系控制着岩体的破坏机制与强度。结构面的迹长(trace length,TL)是指在露头中对结构面可追索的长度,用来表示结构面的连续性,不同连续性的结构面力学强度和渗透性能存在很大差异。结构面的张开度(e)是指结构面两壁面间的平均垂直距离,由于结构面两壁之间非紧密接触导致其凝聚力降低,进而影响结构面的强度及渗透性。此外,结构面的表面形态(S)与其力学性质以及传导和渗透性等物理性质亦有密切联系[12]。产状、迹长和张开度在现场统计中用具体数值表示,而表面形态一般做定性描述,为便于计算,需对其进行量化,量化值如表1 所示。

表1 结构面表面形态量化表Table 1 Quantization values for describing surface morphology of discontinuities
在对结构面产状数据进行数学分析时,通常将结构面假设为一空间平面而使用其单位法向量进行表示。将倾向和倾角转换为单位法向量的公式为
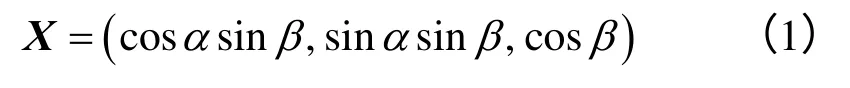
综上所述,结构面数据可表示为P=[X,TL,e,S]。其中,X为结构面单位法向量;TL、e和S分别表示迹长、张开度和表面形态。
2.2 相似性度量
岩体结构面优势分组就是要把性质相似的结构面归为一类,而性质不同的结构面归为不同的类别之中。因此,定量描述两结构面数据样本之间的差异是应用数学方法对岩体结构面进行优势分组的前提。
本文选择结构面单位法向量之间所夹的锐角正弦值作为两结构面之间的产状相似性度量,这样便可以将两倾向相差180°左右的高陡倾角结构面分为一组[7,9]。两个单位矢量X1、X2所夹锐角θ为

则两结构面产状间距离d(X1,X2)为

结构面的迹长、张开度和表面形态均是标量,可以采用欧氏距离进行相似性度量[13]。但由于各特征参数之间单位不同,为了消除量纲的影响,要先进行归一化处理。迹长和张开度数据的归一化公式为

式中:TLi、ei为第i个结构面的迹长和张开度;TLmax、TLmin分别为结构面总体样本数据中迹长的最大值和最小值;emax、emin分别为张开度的最大值和最小值。
不难看出,应用式(3)度量两结构面之间的差异,实际上已经蕴含了对结构面产状数据进行归一化处理的过程。同时,量化后的表面形态之间的距离在0~1范围内,无需再进行归一化处理。
综上所述,可利用式(6)来确定两结构面之间的距离

2.3 目标函数
假定待分组的N个结构面为Pi=[Xi,TLi*,ei*,Si](i=1,2,…,N)划分为M 组,每组Gl的中心矢量即分组中心为gl(l=1,2,…,M)。由式(6)可得Pi与gl之间的距离为d(Pi,gl),定义变量mil用于描述结构面Pi与第l 分组Gl之间的归属关系,即

则各组间总离差平方和为

分组的目标就是使式(8)中的离差平方和E最小,所以式(8)即为问题的目标函数。
从式(8)不难看出,当每个结构面单独自成一组时,式(8)的值为0 且为全局最小值。这是没有意义的,所以要事先设定分组数目M。考虑到结构面分组数目太多会使得分组结果在实际中不易使用,所以一般将结构面分为2~10 组。在分组数M确定的情况下搜索使得离差平方和E 取得最小值的聚类中心,进而确定各组结构面的中心,这实际上是组合优化问题。为此,本文选用人工蜂群算法来解决此问题。有关人工蜂群算法的详细介绍请见第3 节。
2.4 确定最佳分组数
在获得不同分组数目对应的分组结果之后,可以运用聚类有效性指标来评价各个分组结果的优劣,最终确定最优的优势分组结果。常用的有效性指标有in-group proportion 指标(Vigp)和silhouette 指标(Vs)。前者为基于数据集统计信息的指标,后者为基于数据集样本几何结构的指标,两个指标都是在取最大值时指示最优的聚类结果。计算公式如下:

式中:iN为距离样本i 最近的样本;Class(i)为样本i 的类标;#为满足条件的个数。

P、Q为样本;nl、nk为Gl、Gk组中样本个数。
3 人工蜂群算法基本原理
人工蜂群算法(artificial bee colony algorithm,ABC)是Karaboga 于2005年提出的一种基于蜂群觅食行为的群集元启发式智能优化算法,最初是为了解决多变量函数优化问题[14]。该算法具有个体行为简单,分布式控制,较强的鲁棒性和可扩展性,不受领域知识所约束等特点。相比于遗传算法、差分进化算法和粒子群算法,人工蜂群算法收敛速度和算法性能上有较大的提高[15-16],目前已被应用到约束优化问题[17]、聚类分析[18]和工程方案优化问题[19]等相关领域中。
人工蜂群算法(ABC)模型主要包括4个基本元素:雇佣蜂、跟随蜂、侦查蜂和含有花蜜的食物源。其中,食物源位置代表了所求优化问题的可行解,食物源所含花蜜的丰富程度表示可行解的质量。首先在D 维解空间中初始化SN个食物源(即可行解)xi,其中(i=1,2,…,SN)。然后开始以下迭代寻优过程:每一个食物源吸引一个雇佣蜂采蜜,而且食物源的数量保持不变。雇佣蜂在舞蹈区将食物源的相关信息与跟随蜂共享,跟随蜂通过观察雇佣蜂的“摆尾舞”根据式(12)选择食物源。每个跟随蜂到达食物源后,根据式(13)对其进行一次邻域搜索,并将搜索到的新食物源与原来的食物源进行比较,如果新蜜源的花蜜丰富程度比原来食物源高,则忘记原来食物源,开采新食物源;否则,继续开采原来的食物源,并记录开采次数。当某一食物源被开采的次数超过极限次数(limit)后,如果解的质量还没有得到提高,那么开采该食物源的雇佣蜂变成侦察蜂,并且由侦察蜂在解空间中产生一个新的食物源来代替原来的食物源。整个进化过程一遍遍地重复进行,直到结束条件满足为止。
在人工蜂群算法中,每个食物源所含花蜜的丰富程度即其代表的解的适应度fit为

式中:E为离差平方和,用式(8)计算。
食物源i被选择的概率为

式中:fiti为食物源i所代表的解的适应度。
搜索方程为

式中:vij为邻域搜索得到的新食物源;k为不同于i的食物源;j为随机选择的下标;φij为[0,1]之间的随机数。
在人工蜂群算法中只有3个控制参数:食物源数量SN、食物源的开采极限limit和最大循环次数MCN。该模型定义了对自组织与群体智能非常必要的两种主要的行为模式,即招募更多跟随蜂开采蜜源较丰富的食物源的正反馈机制与放弃蜜源枯竭的食物源的负反馈机制。人工蜂群算法结合了全局搜索和局部搜索方法,使蜜蜂在食物源的探索和开采两个方面达到了较好的平衡,从而使得算法的性能得到了很大的提升。
应用人工蜂群算法求解问题的流程如图1 所示。

图1 人工蜂群算法流程图Fig.1 Flow chart of artificial bee colony algorithm
4 方法可行性检验
图2为人工生成的6组结构面的极点等密度图,每个结构面包含倾向、倾角、迹长、张开度与表面形态5个参数指标,详细参数见表2[20]。
根据图2不难看出,如果仅根据产状进行优势分组,将分为近水平、陡倾与中陡倾3组结构面。而从表2可知第1组与第2组虽然都是缓倾结构面,但迹长、张开度与表面形态差异很大,这必然导致两组结构面的力学性质和渗透能力显著不同,是不能分为同一组的,第3组与第4组、第5组与第6组之间会产生相同的问题,所以仅根据产状进行结构面数据优势分组是存在一定缺陷的。
采用本文所提出的基于人工蜂群算法的岩体结构面多参数优势分组方法,相关参数设置为:食物源数量为SN=10,食物源的开采极限limit=100和最大循环次数MCN=2 500。计算得到不同的分组数对应的聚类效果有效性检验结果见图3。由图可知,两个聚类有效性指标在分组数目为6时同时取得最大值,所以确定最优分组数为6。
最终的分组结果如图4所示。其中,X轴表示倾向,Y轴表示倾角,Z轴表示迹长,点的颜色代表张开度,形状代表表面形态,形状与结构面表面形态的对应关系见表1。
从图4 可以看出,分组结果是十分理想的。从而验证了本文方法的正确性。表3 将计算结果与已知参数进行对比,可以看出算法具有较高的求解精度。

图2 人工生成结构面极点等密度图Fig.2 Contour of pole density of artificial discontinuities

表2 人工生成结构面数据Table 2 Data of artificial discontinuities
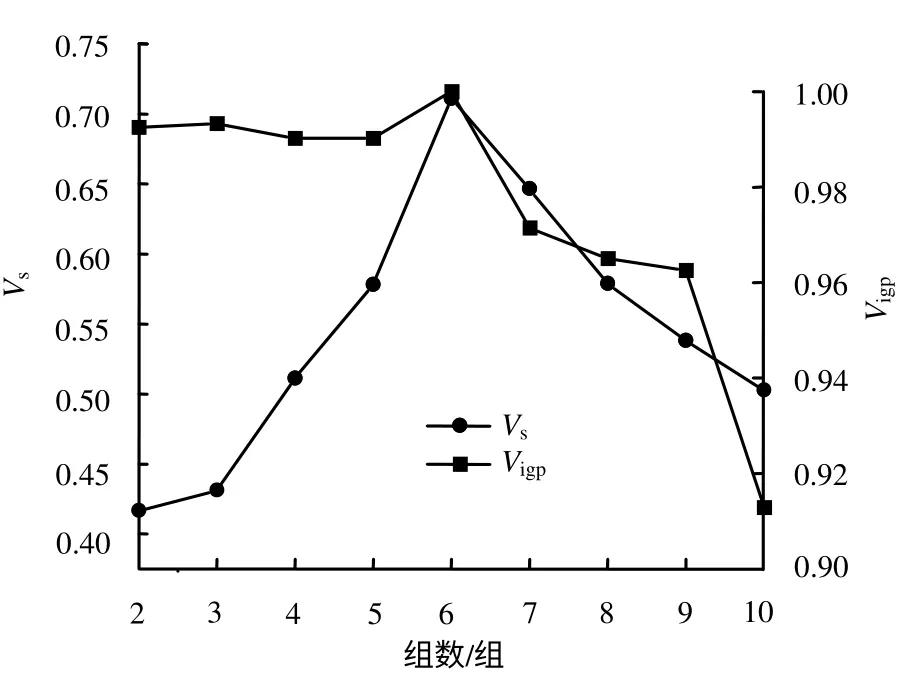
图3 人工生成数据聚类有效性指标计算结果Fig.3 Results of clustering validity measurement for artificial discontinuities data

图4 人工生成结构面分组结果图Fig.4 Classification results of artificial discontinuities data
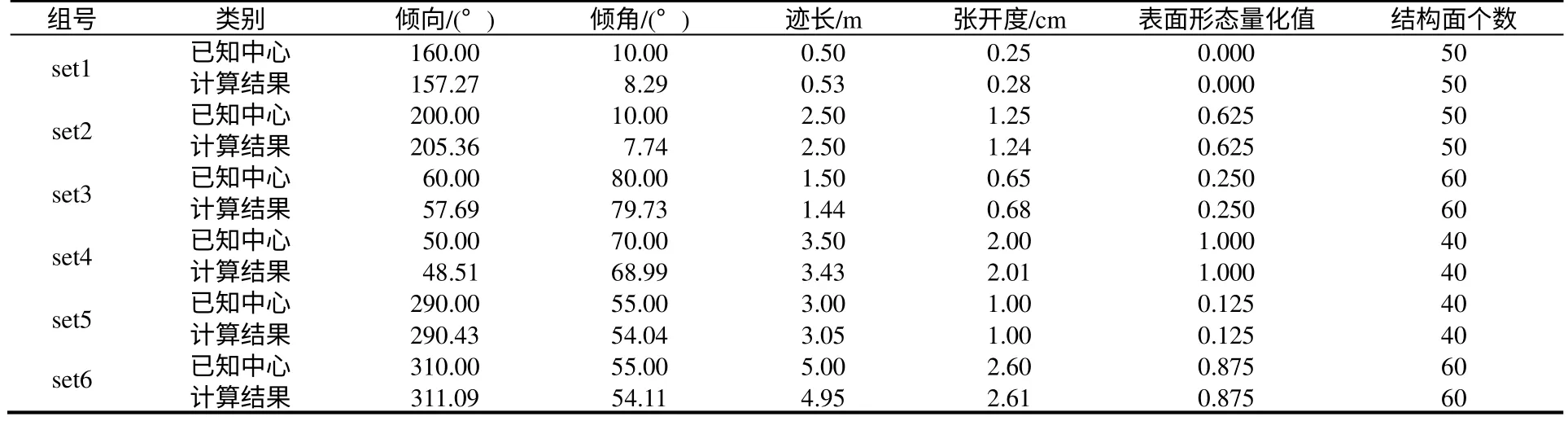
表3 计算结果与已知中心的对比Table 3 Contrast between computation results and centers defined in advance
5 工程实例
怒江松塔水电站位于西藏自治区察隅县察瓦龙乡境内,坝址区属高山峡谷地貌,岩性主要为燕山晚期黑云二长花岗岩,节理裂隙比较发育。要分析工程区岩体稳定性,应首先研究节理裂隙的发育分布及其组合规律。应用本文提出的方法对坝址区平硐内实测的393个岩体结构面数据进行多参数优势分组。其中算法参数与第4 节中相同。不同的分组数对应的聚类有效性指标计算结果见图5。由图可知,最佳分组数为3。表4 给出了分组数为3 时的聚类中心。图6为分组结果的极点图。图7为寻优过程图。

图5 实测结构面数据聚类有效性指标计算结果Fig.5 Results of clustering validity measurement for field discontinuities data

表4 实测结构面数据分组结果Table4 Classification results of field discontinuities data
根据表4 并结合图6 分析可知,实测的393个岩体结构面被清晰地分为3 组,其中,缓倾结构面(第1 组)约占总数的一半,平均迹长约为1.34 m,表面形态为波状粗糙。两组近直立结构面(第2 组和第3 组)约各占总数的1/4,第2 组平均迹长为1.07 m,表面形态为波状稍粗;第3 组平均迹长为1.28 m,表面形态为平直粗糙。这3 组结构面的张开度约为1.1 mm,均属于低连续性(迹长1~3 m)中等张开(张开度1~5 mm)的结构面。而且根据图6 不难看出,划分出的这3 组结构面间的产状边界是没有重叠的。查看结构面原始数据可知,393个结构面的迹长和张开度是比较均匀的,随机性不强,仅表面形态这一性质差异略大,这就使得计算两结构面之间的距离时,结构面产状之间的距离占了主要地位。换言之,两结构面之间的差异主要是产状间的相似程度决定的。这就是图6 显示的分组结果与仅考虑产状的分组结果几乎一致的原因。表4 给出的分组结果也揭示了实测结构面的迹长、张开度和表面形态的这种分布规律。由此可见,本文所提出的方法可用来进一步揭示结构面的几何特征,其分组结果可详细反映与岩体结构面力学性质与水力学特性密切相关的多个结构面参数的发育特征和分布规律。这是仅根据结构面产状进行优势分组的传统分组方法做不到的。
此外,当结构面的迹长、张开度和表面形态数据差异较大,直接利用式(6)衡量结构面之间相似程度进行多参数优势分组时,结构面之间的距离会综合迹长、张开度和表面形态间的差异从而导致分组结果中各组间产状边界交叉重叠的现象。若想要避免这种现象而突出产状因素的控制作用,可在式(6)中计算迹长、张开度和表面形态距离前加上一大于0 小于1 的系数,具体数值可根据读者自身需要进行选择。特别地,将计算这3个性质距离的系数设置为0 时,该方法将变成结构面产状数据的优势分组方法。

图6 实测结构面数据分组结果极点图Fig.6 Clustering results of field discontinuities data
岩体结构面多参数优势分组问题属于高维数据聚类问题。前文提到的K 均值聚类法、模糊C 均值聚类法属于动态聚类算法,初始聚类中心的选取对聚类结果影响很大。当岩体结构面分布具有较强的随机性,分布规律不明显时,应用此种聚类算法解决岩体结构面多参数优势分组问题时,无法有效选取恰当的初始聚类中心,虽然本文给出的实例中结构面的迹长和张开度是比较均匀的,但以上两种方法依然面临如何选取合适的初始聚类中心的难题。而且这两种算法较易陷入局部最优,从而使得聚类结果的可靠度大大降低,因此,这两种方法存在较大缺陷。
根据人工蜂群算法的计算过程可知,与这两种方法相比,本文提出的方法随机选取初始聚类中心,避免了选取初始聚类中心的困难。且人工蜂群算法收敛于全局最优解这一重要特征确保本文提出的方法能够获得全局最优解。因此,本文提出的方法具有很大的优势。

图7 寻优过程图Fig.7 Process of searching optimal solution
图7 显示出该方法具有较快的收敛速度,因此,在实际应用中可大幅降低计算的时间,便于进行重复计算。应用本文提出的方法对松塔水电站坝址区平硐结构面进行多参数优势分组分析,可深入分析坝址区岩体结构面的分布发育规律,为分析坝址区岩体稳定性提供了依据,也证实此方法具有较高的适用价值。
6 结论与建议
岩体结构面优势分组是岩体力学领域一个重要的研究课题。仅根据产状进行优势分组的传统方法无法对影响岩体物理力学性质的其他参数进行分析,而现有的结构面多参数优势分组的分析方法又存在一定的缺陷。为此,本文提出了基于人工蜂群算法的岩体结构面多参数优势分组分析方法,通过分析可以得出以下几点结论和认识:
(1)应用人工生成的分离性较好的6 组结构面数据,验证了本文方法是可靠的。将计算结果与已知参数进行对比可知,该方法具有较高的求解精度。
(2)应用该方法对松塔水电站坝址区岩体结构面数据进行分析,结果表明,该方法在解决大规模工程岩体结构面数据优势分组问题时能够获得理想的分组结果,且具备较高的运行效率,为解决岩体结构面多参数优势分组问题提供了有效方法。
(3)另外,值得注意的是,对人工生成结构面数据与实测结构面数据进行优势分组时,算法参数的取值均为算法作者的建议取值,这说明该方法对参数的设置是不敏感的。在实际运算时,操作人员无需对参数进行调整而省去大量的参数测试时间,这一点是十分重要的。
[1]刘佑荣,唐辉明.岩体力学[M].武汉:中国地质大学出版社,1999.
[2]MAHTAB M A,YEGULALP T M.A rejection criterion for definition of clusters in orientation data[C]//Proceedings of the 22nd Symposium on Rock Mechanics.New York:American Institute of Mining Metallurgy and Petroleum Engineers,1982:116-123.
[3]SHANLEY R J,MAHTAB M A.Delineation and analysis of clusters in orientation data[J].Journal of the International Association for Mathematical Geology,1976,8(1):9-23.
[4]陈剑平,石丙飞,王清.工程岩体随机结构面优势方向的表示法初探[J].岩石力学与工程学报,2005,24(2):241-245.CHEN Jian-ping,SHI Bing-fei,WANG Qing.Study on the dominant orientations of random fractures of fractured rock masses[J].Chinese Journal of Rock Mechanics and Engineering,2005,24(2):241-245.
[5]HAMMAH R E,CURRAN J H.Fuzzy cluster algorithm for the automatic identification of joint sets[J].International Journal of Rock Mechanics and Mining Sciences,1998,35(7):889-905.
[6]蔡美峰,王鹏,赵奎,等.基于遗传算法的岩体结构面的模糊C 均值聚类方法[J].岩石力学与工程学报,2005,24(3):371-376.CAI Mei-feng,WANG Peng,ZHAO Kui,et al.Fuzzy C-means cluster analysis based on genetic algorithm for automatic identification of joint sets[J].Chinese Journal of Rock Mechanics and Engineering,2005,24(3):371-376.
[7]卢波,丁秀丽,邬爱清.岩体随机不连续面产状数据划分方法研究[J].岩石力学与工程学报,2007,26(9):1809-1816.LU Bo,DING Xiu-li,WU Ai-qing.Study on method of orientation data partitioning of randomly distributed discontinuities of rocks[J].Chinese Journal of Rock Mechanics and Engineering,2007,26(9):1809-1816.
[8]BEHZAD T,HOSSEIN M,BEHZAD Mo,et al.Investigating the validity of conventional joint set clustering methods[J].Engineering Geology,2011,118(3):75-81.
[9]徐黎明,陈剑平,王清.多参数岩体结构面优势分组方法研究[J].岩土力学,2013,34(1):189-195.XU Li-ming,CHEN Jian-ping,WANG Qing.Study of method for multivariate parameter dominant partitioning of discontinuities of rock mass[J].Rock and Soil Mechanics,2013,34(1):189-195.
[10]ZHOU W,MAERZ N H.Implementation of multivariate clustering methods for characterizing discontinuities data from oriented boreholes[J].Computers &Geosciences,2002,28(7):827-839.
[11]ZHOU W,MAERZ N H.Multivariate clustering analysis of discontinuity data:Implementation and applications[C]//Proceedings of the 38th U.S.Rock Mechanics Symposium.Washington D C:American Rock Mechanics Association,2001:861-868.
[12]夏才初.岩石结构面的表面形态特征研究[J].工程地质学报,1996,4(3):71-78.XIA Cai-chu.A study on the surface morphological features of rock structural faces[J].Journal ofEngineering Geology,1996,4(3):71-78.
[13]HAMMAH R E,CURRAN J H.On distance measures for the fuzzy k-means algorithm for joint data[J].Rock Mechanics and Rock Engineering,1999,32(1):1-27.
[14]KARABOGA D.An idea based on honey bee swarm for numerical optimization[R].Technical report-tr06,Erciyes University,Engineering Faculty,Computer Engineering Department,2005.
[15]KARABOGA D,BASTURK B.A powerful and efficient algorithm for numerical function optimization:Artificial bee colony(ABC)algorithm[J].Journal of Global Optimization,2007,39(3):459-471.
[16]KARABOGA D,BASTURK B.On the performance of artificial bee colony(ABC)algorithm[J].Applied Soft Computing,2008,8(1):687-697.
[17]BRAJEVIC I,TUBA M.An upgraded artificial bee colony(ABC)algorithm for constrained optimization problems[J].Journal of Intelligent Manufacturing,2013,24(4):729-740.
[18]KARABOGA D,OZTURK C.A novel clustering approach:Artificial bee colony(ABC)algorithm[J].Applied Soft Computing,2011,11(1):652-657.
[19]AKAY B,KARABOGA D.Artificial bee colony algorithm for large-scale problems and engineering design optimization[J].Journal of Intelligent Manufacturing,2012,23(4):1001-1014.
[20]陈剑平,肖树芳,王清.随机不连续面三维网络计算机模拟原理[M].长春:东北师范大学出版社,1995.
