电力企业应对大数据时代的技术策略研究
2015-02-14谢珍贵陈振宇
谢珍贵,陈振宇
(1.福建水利电力职业技术学院电力工程系,福建 永安 366000;2.广东财经大学信息学院,广东 广州 510320)
一个基于物联网—云计算—大数据开发的巨大产业链即将形成,一个新的推动世界经济发展的科技革命将会诞生,国际经济即将进入一个新的发展阶段.自2008年《自然》杂志推出一期名为“大数据”的封面文章,详细讲述了“数据”在数学、物理、生物以及社会经济中所扮演愈加重要的角色以来,美国政府在2009年由总统科学技术顾问委员会、能源部、国防部、参议院和数十所大学的著名教授酝酿,在2012年4月发表了“大数据开发计划(Big data research and development initiative)”,很快在国际上掀起了新一轮信息革命的热潮[1].在全球经济经历了近10年危机的情况下,经过多年的酝酿,信息处理技术和各行业企业信息化程度已经达到一定高度,在世界经济面临何处去、如何突破困境的拷问时,大数据开发将给世界经济复苏带来一线曙光,许多经济学家将它称为“大数据时代”的到来.2013年11月,我国首个行业——电力行业发布了《中国电力大数据发展白皮书》[2].中国电力出版社策划总编肖兰在发布仪式上评价说:“《中国电力大数据发展白皮书》是我国首个行业大数据白皮书,首次提出了电力大数据的定义和特征.”电力信息化专委会作为我国唯一的电力行业信息化专业协会,充分听取了行业内外专家意见,完善了白皮书编制思路,对推动我国电力大数据事业的发展、实现我国电力科学跨越具有极大的现实意义.
电力系统的数据已告别以往数据类型较为单一、增长较为缓慢的时代,随着SG-ERP 和智能电网建设的开展和深入,数据量以几何级数增长,数据来源也更加复杂和多样(结构化、非结构化和半结构化).如何充分利用这些巨量的多样化数据,对其进行深入分析以便提供大量的高附加值服务,需要应用大数据的理念与技术.
1 规范采集数据的源头,加强数据管理,提高数据质量
在电力行业,随着坚强智能电网建设以及“三集五大”管理体系的决策部署,企业信息化程度不断提高,数据量正在迅速膨胀,数据类型逐渐多样化,电力大数据的环境正在形成.但在数据采集方面存在不足,如采集的数据质量不高,采集过程不够规范,采集数据重复,管控相对滞后等.为了后续工作的更加有效,有必要在源头上对要采集的数据进行统一规范,避免重复、遗漏现象的发生,提高后续对数据处理的效率.
针对上述问题,应对策略是建立统一的数据质量评价指标体系,甚至是数据质量评价模型[3],分析大数据环境下数据质量的主要影响因素,按照数据的一致性、准确性、完整性、及时性4 个关键特性建立数据质量评价指标,夯实数据基础,提升数据质量,保障数据的准确、及时、有效和可信,为数据的集成和挖掘应用提供有力保障.同时,局部数据与全局数据、非共享与共享数据应实行分级管理,切实做好数据备份、灾难恢复等工作机制,实现实时监控、在线考评,强化数据质量,实现事前监测、事中控制、事后评价、问题整改,提高决策分析依据的准确性和实用性.
2 提高数据的高速存储管理能力
电力大数据具有4V 特点,即Volume(数据体量大)、Variety(数据类型多)、Velocity(处理速度快)和Value(价值密度低).除了数据量庞大之外,第二个特点就是数据类型多,不但有结构化数据,还有半结构化数据和非结构化的数据;不但有数值、文本、图形信息,还有音频、视频等信息.据IDC 公司统计,2011年全球数据总量的75﹪来自于非结构化数据,至2012年末,非结构化数据占有比例超过75﹪.
针对如此海量、复杂的电力数据信息,应对的策略是通过构建NoSQL 数据库[4]、HDFS(Hadoop Distributed File System)分布式文件系统及实时数据库等3 种存储方式,从存储结构上初步实现信息与应用系统的分类、融合、互动,做到信息、能量与业务流的高度一体化,并根据信息处理的技术要求来提高数据的存储管理能力[5].
传统的关系型数据库具有非常好的通用性和非常高的稳定性.毫无疑问,对于绝大多数的应用来说它都是最有效的解决方案,特别是在处理传统结构化数据方面.但在处理大容量、非结构化数据上,传统的关系型数据库显得不足.这说明单纯使用传统的关系型数据库已无法适应大数据时代的要求.NoSQL 数据库属于非关系型、分布式数据存储系统,它让数据库具备了非关系、可水平扩展、可分布和开源等特点.NoSQL数据库可通过集成分布式系统、集群、分区等技术实现分布式存储,以Key -Value 数据格式、面向文档方式以及图数据方式存储,具有极高的并发读写性能、良好的查询性能和弹性的扩展能力.由于未来数据发展趋势是半结构化数据(电子邮件、XML 等)和非结构化数据(文档、图片、视频等)占用的比重越来越高,针对每秒数万次的读写请求,NoSQL 数据库应付自如.从结构上看,NoSQL 数据存储系统有两种架构:master -slave 结构和P2P 环形结构.Master - Slave 结构的系统设计简单,可控性好,通常采用基于水平分区实现数据分布,将master 节点和slave 节点的功能分开,以减轻节点的功能负载,由master节点维护其管理的slave 节点,但master 中心节点易成为瓶颈.P2P 环形结构的系统无中心节点,各节点平等,自协调性好,扩展方便,基于Hash 分布数据,负载均衡性好,但不利于支持范围查询,并且系统设计复杂,可控性较差.由于上述两种体系结构有很大差别,它们所采用的支持技术也不同,导致了不同体系结构的系统所支持功能也有一定的局限性.Cloudy 为用户提供了一个可配置采用master-slave 或DHT 体系结构的Demo 系统.在电力系统中,支持数据存储系统的体系结构应结合P2P 分布式结构和master -slave 集中式结构两者的优势,如Chord 和master-slave 的结合、CAN 与master -slave 的结合等,侧重采用面向组件的灵活可配置的体系结构,结合两者的优势,综合考虑数据存储的全局性和局部性.
HDFS 是一个分布式文件系统.HDFS 有高容错性特点,可以部署在低廉的硬件上.HDFS 放宽了POSIX 的要求,这样可实现以流的形式访问文件系统中的数据,提供高吞吐量,适合那些有着超大数据集的应用程序.在时效性要求较高的场合,可以使用实时数据库提高对数据的处理速度.必须对系统中的大数据根据性能和分析处理的要求进行分类存储:对核心业务数据使用传统的并行数据仓库系统;对非结构化的数据采用NoSQL 数据库系统,对大量的历史和非结构化数据采用HDFS 分布式文件系统;对处理速度与时效性要求高的数据采用实时数据库系统.
3 提高异构数据信息的整合、分析和处理
未来智能电网要求贯通发电、输电、变电、配电、用电、调度等多个环节,实现信息的全面采集、流畅传输和高效处理,支撑电力流、信息流、业务流的高度一体化.目前电力系统中仍存在监测监控、能量管理、配电管理、市场运营等各类信息系统,它们之间有些相互独立,数据信息不能共享[6].同时,传统数据分析以结构化数据分析为主,业务分析更是以被动式信息接受为主.大数据时代下,随着数据的累积和增加,可做的分析和对比也越来越多.通过对大量数据进行分析,揭示数据之间隐藏的关系、模式和趋势,通过结构化数据、半结构化数据、非结构化数据的融合关联分析,实现文本分析、数据挖掘、图形分析、空间分析等数据分析模式,为决策者提供不同角度、不同形式的分析判断依据.
因此,首要措施是实现大规模多源异构信息的整合,解决系统间信息孤岛的现象,同时加强对不同信息的分类分析和处理能力.
规范采集数据的源头,提高采集数据的质量,实际上就解决了数据的大量冗余,保证了数据的唯一性;建立分级、分类的存储系统,实际上就对原数据进行了分类预处理.借助于云计算平台,实现对数据的抽取、转换,比如通过MapReduce 的编程模型对输入的数据按行并行处理,对每个文件的每一行数据进行操作.在MapReduce 的操作函数中加入对数据格式的检查,实现数据的不完整处理、不一致处理以及噪音处理,完成数据清洗,实现数据不一致转换、数据粒度转换和商务规则计算[7-9].MapReduce 中的数据转换模块(ETL)在没有大型并行数据库时也可以提高其对数据的并行访问速度,降低系统操作成本和对大型数据库的维护成本.在处理过程中,无需关注数据分散、任务分配、数据收集等子任务,可在不熟悉分布式系统的基础上实现分布式数据处理.
面对海量的图片、视频等智能电网数据,如何在有限的屏幕空间下,以一种直观、容易理解的可视化方式展现给用户,也是一项非常有挑战性的工作.可视化方法已被证明为一种解决大规模数据分析的有效方法,并在实践中得到广泛应用.它是通过一系列复杂的算法将数据绘制成高精度、高分辨率的图片,并提供交互工具,有效利用人的视觉系统,并允许实时改变数据处理和算法参数,对数据进行观察和定性及定量分析,通过可视化算法的可扩展性、并行图像合成算法、重要信息的提取和显示等技术来实现对该类型数据的处理.
根据上述数据采集、存储、处理的思想,借助于云计算平台,可实现对数据的集中处理,构建该系统的模型如图1所示.
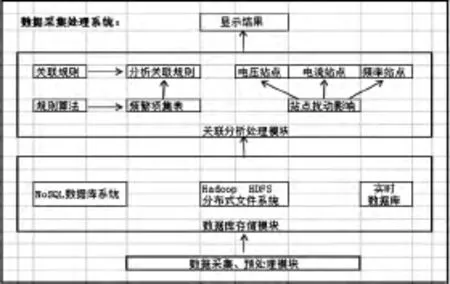
图1 数据采集、存储、处理模型
4 提高数据挖掘能力,开辟更多增值服务
如何驾驭大数据,如何在海量数据中挖掘有价值的信息是重点.因此,企业应专注于数据中隐藏的价值,通过应用大数据技术分析,充分挖掘数据的核心价值,不断优化业务流程,降低管理成本,辅助企业做出科学的决策,为企业的持续创新与发展积蓄力量.
目前电网的业务数据大致分为3 类:
一是电力企业生产数据,如发电量、电压稳定性等方面的数据.对于电力企业的生产数据,可以通过一定的关联规则,采用新型挖掘技术获取信息.这在检测故障、恢复电网运行稳定方面,以往的研究中也取得过较好的成果.如文献[10]中,采用基于FP-T 的多层关联规则并发挖掘技术,利用混沌与分形数据、约简的基本原理,实现电力系统高频暂态波形的特征识别等.文献[11]采用智能多代理技术,借助广域量测系统(WAMS),实现对大电力系统故障的快速分析、诊断,提高了广域电网运行的稳定性;同时,可利用最新数据挖掘技术,在线计算输送功率极限,实时考虑电压等因素对功率极限的影响,从而合理设置系统输出功率,有效平衡系统的安全性和经济性.
二是电力企业运营数据,如交易电价、售电量、用电客户等方面的数据.在电力营销环节,针对“大营销”体系建设,以客户和市场为导向,借助于客户服务、计量检定配送业务属地化管理的营销管理体系和24 小时面向客户的营销服务系统,通过数据分析改善服务模式,提高营销能力和服务质量.同时,以分析型数据为基础,优化现有营销组织模式,科学配置计量、收费和服务资源,构建营销稽查数据监控分析模型.建立各种针对营销的系统性算法模型库,发现数据中存在的隐藏关系,为各级决策者提供多维、直观、全面的分析预测数据.
三是电力企业管理数据,如ERP、一体化平台、协同办公等方面的数据.如能充分利用这些来自配电、用电、客户、天气等数据,经过一定规则的转换、整合,按照电力交易数据、气候数据与客户家庭年龄结构、生活习惯等因素融合分析,了解客户的用电行为,满足客户的差异化需求,通过探寻深层需求开辟新的增值业务空间,可以提供大量的高附加值服务.这些增值服务将有利于电网安全检测与控制(包括大灾难预警与处理、供电与电力调度决策支持和更准确的用电量预测),有利于电力企业进行精细化运营管理,实现更科学的需求管理.
[1]徐立,田文盛.大数据开发将引发新一轮信息革命[N].人民邮电,2012 -06 -22 (7).
[2]李胜永.掀起新一轮电力信息化高潮[N].中国电力报,2013 -12 -05(7).
[3]张磊.油田数据质量监督与控制模型研究[D].大庆:东北石油大学硕士论文,2010.
[4]高丹丹.基于NoSQL 的电力系统大数据管理[J].科技创新导报,2014(6):190.
[5]曹军威,万宇鑫,涂国煜,等.智能电网信息系统体系结构研究[J].计算机学报,2013,36(1):143 -167.
[6]宋亚奇,周国亮,朱永利.智能电网大数据处理技术现状与挑战[J].电网技术,2013,37(4):927 -935.
[7]曲朝阳,朱莉,张士林.基于Hadoop 的广域测量系统数据处理[J].电力系统自动化,2013,37(4):92-96.
[8]曲朝阳,陈帅,杨帆,等.基于云计算技术的电力大数据预处理属性约简方法[J].电力系统自动化,2014,38(8):67 -71.
[9]胡牧,李勇,孔震,等.数据拓扑及其在电网数据处理分析中的应用[J].电力系统自动化,2013,37(3):83-86.
[10]何友全.数据挖掘方法及其在电力系统故障诊断中的应用研究[D].成都:西南交通大学博士论文,2004.
[11]陈振宇.基于MAS 的广域故障诊断及保护系统的研究[D].广州:华南理工大学博士论文,2009.
