重庆市中文语义地址模型构建方法探讨
2015-02-06臧英斐瞿晓雯
臧英斐,王 斌,瞿晓雯
(1.重庆交通大学 土木建筑学院,重庆400074;2.重庆市地理信息中心,重庆 401121)
重庆市中文语义地址模型构建方法探讨
臧英斐1,王 斌2,瞿晓雯2
(1.重庆交通大学 土木建筑学院,重庆400074;2.重庆市地理信息中心,重庆 401121)

现有重庆市地址模型存在地址不完整、歧义、口语化等弊端。以南岸为例,针对现有数据特点,围绕地址数据库建设及地理编码的需求,归纳非结构化中文地址的特点,优化现有地址要素结构。提出了基于中文语义的地址模型构建方法,建立要素间拓扑关系,增加上下文约束力,引入支持向量机,有效避免中文自然语言表达歧义,提高地址解析的准确度和效率。
支持向量机;地址模型;中文语义;重庆市
地理编码技术是指将已存在的中文地址转化为地理坐标,利用空间分析等手段,完成对经济社会信息的分析、管理、统计、可视化表示[1]。美国是地址模型研究技术最成熟的国家,目前采用的是“拓扑集成的地址编码与参照系统(TIGER)”,该系统改进了DIME英文属性存储的方式,以关系数据库和文件系统为基础[2]。随着空间地理信息资源的开发和地理信息系统技术的研究与应用,我国各级各地政府部门已经开始逐步规范地名、地址的管理和使用。目前国内普遍认为,基于层次关系的地址要素排列模型较适合中文地址[3]。另外也有人提出,地址要素之间是一种带有固定包含指向的网状结构关系[4]。北大方正数码公司也曾推出过Map Searcher,通过人工归纳提取了近20种地址模型,但由于缺乏完备、准确的地址数据库支撑,并未形成有效的服务能力。
重庆市现有地址模型采用了传统的层次关系模型,由于人文环境和历史沿革的特殊性,存在地址命名随意无序、虚拟地址数量多、歧义现象较为严重等弊端,难以有效满足日益增长的社会经济数据空间定位需求。因此,研究基于语义的中文地址模型构建方法,具有重要的理论价值和现实意义。
1 重庆市地址结构及现有模型分析
1.1 重庆市地址数据现状及特点
与欧美国家相比,中国现有的地名、地址体系异常复杂,缺乏规律性和统一性,导致我国在地址模型构建方面的研究受到诸多限制[5]。以南岸区为例,其地址数据存在以下特点:
1)地址类型难以区分。例如“沈家塆、东坡池”等,无法通过建立“栋、楼、村”等关键词库进行分类,从名字上难以判断其地址类型。
2)标准地址的普及度不够,习惯性、口语化地址十分普遍,如“重庆交通大学”虽然早已更名,但现在很多重庆人依旧使用“交院”。
3)街路巷、门牌号比较混乱,存在有路无号、有号无建筑物等问题,这使得我们无法借鉴TIGER模型建立主地址数据库(MAF)与建筑物地理位置间一一对应的关系。
1.2 重庆市现有地址模型分析
重庆现有地址模型通过人工归纳的方法对地址要素进行分类,将地址分为市、区县、街道(乡、镇)、社区(自然村)、限定物1、限定物2、门牌号(主号附号幢号单元号),其中限定物包括地片、街巷、组、社、集贸市场、名胜古迹等,通过人工归纳的方式确定其层次关系。导致地址种类繁多,各等级地址数据相差悬殊,层次关系复杂。又由于地址本身不规范导致标准地址数据库中的地址并不“标准”。分析南岸区地址后得到重庆市现有地址模型的主要地址层次关系如表1所示。
通过对现有分类体系研究可以发现,其存在以下问题:
1)行政区划信息不完整,致使地址歧义。该分类方法中,涉及街路巷的数据行政区划等级只到区县,如作为街路巷的“正街”,在葛兰镇、洪湖镇、渡舟街道、凤城街道等都存在,缺少乡镇级的行政区划,显然会造成歧义。
2)地片概念模糊,致使分词歧义。在现有数据库中对地片的界定为:除可确定为街路巷、自然村等的其他地址都为地片,如观音桥、两路口、李家沱等。这种界定很容易将地片与行政村混淆,如长生桥,从名字判断是地片,但其实长生桥是渡舟街道下的一个社区。
3)层次关系归纳不规范,致使解析分歧。根据《地名地址数据规范》(2010),组社级别前面应该是社区村级别,表1显然不符合要求。重庆市部分社区以道路命名,而在进行地址表达时并不会带上“社区”二字,如“凤岭路1组”是指“凤岭路社区1组”,而真正的凤岭路在白石村。

表1 主要地址层次关系
2 重庆市中文语义地址模型总体设计
2.1 中文语义地址模型的优势
不同于国外地址的规则表达,中文地址没有分隔符,缺少结构形态,是由一组不特定类地址单元组成的,并在描述过程中多有冗余或缺省现象,很难建立结构化的地址模型。然而,从自然语言处理的角度考虑,根据现有地址特点建立规则,在对地址进行分词、标注、句法分析和语义解析等环节后,中文地址亦可以看作一串语义块的特定排列。
传统的地址模型如关系模型、层次模型等都是面向记录的模型,需要遵循严格的逻辑结构,如层次模型中分词结构必须与已有的层次关系一一对应。但事实上,中文地址的多样化及复杂性致使其数据模型需突破现有的结构限制。如果根据现有地址表达习惯及特点,设计一种新的数据模型,能更准确地表达地址数据间的关系。
语义地址模型是语义与普通数据模型的有机结合,能帮助计算机在不同的抽象层次上更好地理解地址结构,从而提高建模能力。因此根据中文地址的特点建立中文语义地址模型更有利于中文地址的抽象表达。
2.2 重庆市中文地址要素标注
语义地址模型应由语义块及句式共同构成,语义块通过地址分割获得,句式即语义块构成地址的规则,通过句法分析及语义解析获得,其中句法分析可帮助进行语义块标注,语义解析可推理各语义块间的空间关系与衔接顺序。
若忽略句法模式,则语义地址模型由一系列语义块组成,即地址要素,故重庆市中文语义地址模型的扁平化表达为:
地址= [地址元素](1~N)式中,N为该地址可以达到的粒度。
单独的地址要素是没有意义的,经过句法分析后得到的具有类型标识的地址要素才可用于语义解析。《地名地址数据规范》(2010)[6]规定地址要素应包括行政区划、地址、子地址[7],充分考虑了地址的通用性及扩展性。在此基础上,结合重庆市地址的特点,可将地址要素分为以下几类,如表2。

表2 地址要素分类
经过对重庆市地址数据的分析,同名街路巷问题并不会出现在同一行政村内,所以行政区划等级由原来的4层扩展到5层。详细的行政区划有利于根据区划界线消除语义上的歧义;将行政村与自然村分开,自然村与自然地名(原地片概念)都归类为限定物1,可以有效避免将行政区划与地片混淆的问题;基本地址为地址的主要构成部分,从地址要素等级的角度考虑,自然村与自然地名、街路巷的辐射范围相近,故可放在该级别。重庆市地址大多为“村社+组社”结构,而非街路巷,因此设置子地址部分,将组社、住宅小区及与其具有相似辐射范围的集贸市场、名胜古迹等判定为子地址。
2.3 重庆市中文地址句法分析
标注后的地址要素通过一定的排列顺序构成了一条地址,但此时的排列规则是随意的,并不受句法约束。句法分析即根据已有地址的特点规定地址要素的排列顺序,对于较规范的地址,一般采用词尾关键词统计法来进行识别,即对分析地址的末尾字符进行统计以确定各类型地址要素的关键词,人工归纳相应的分词规则,如街路巷中的“大道、街、路、巷”等。但重庆市很多不规则地址表达较为随意,不含通名,缺乏可统计的关键词,如“拗口坡、曾家岩”等,因此人工归纳在这类地址处理中存在一定局限性。基于支持向量机的处理方式可以将线性不可分的地址映射到高维空间,借助地址要素相对位置的约束,简化其处理过程。
2.4 重庆市中文地址语义解析
理论上,地址所描述的位置应与某个地理实体重叠,而地址要素与地理实体之间存在着包含、隶属等复杂的嵌套关系,所以普通的层次分析并不能满足中文地址表达的需求。通过对重庆市地址数据的分析可得,地址要素间存在一定的拓扑关系,大致可分为5种:①区域间的包含关系,如重庆市包含南岸区;②区域间的相邻关系,如花园路街道与南坪镇相邻;③道路间的邻接关系,如江南大道与学府大道邻接;④方位关系,点位之间的相对方向;⑤距离关系,点位之间的相对距离关系,其中后两种涉及较少。拓扑关系与地址要素类别有密切联系,根据表2的地址要素分类可得到如图1所示的地址要素拓扑关系。

图1 地址要素空间关系
3 基于支持向量机的中文语义地址模型动态构建方法
支持向量机(SVM)是数据挖掘中的一项新技术,是借助于最优化方法来解决机器学习问题的新工具[8]。给定训练集:
T={(x1,y1),(x2,y2),…,(xl,yl) }∈(X×Y)l
式中,xi∈X=Rn;X称为输入空间,输入空间中的每一个点xi由n个属性特征组成,yi∈Y={-1,1},i=1,2,…,l。
在地址模型中,输入空间X为地址串,xi即地址中第i个字。则有:

SVM是一种典型的两类分类器,即“是”或“不是”,通过f(xi)地址的句法分析问题就可以转化为对一条自然语言描述的中文地址的每一项进行标注的分类问题。将其映射到高维空间的训练集不能被线性划分时,选择合适的核函数及其参数,可以加强特征空间中两类样本集“线性可分”的程度,提高分类精度。
特征模板长度是指当前待判断字符及其左右可能相关的2个字符所组成的窗体长度,用于结合上下文判断该字符属性。经分析,重庆市中文地址中大部分地址要素的最大长度不大于5个字,故假设特征模板长度C为5,在地址模型中,如图2所示。
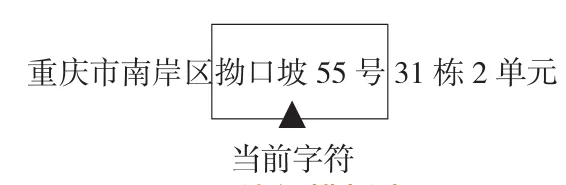
图2 特征模板窗口
传统的分词并不考虑语义解析,即忽略了地址要素间的空间关系对分词的影响,但事实上地址要素的相对位置可以辅助判断该地址要素的类别。因此一条地址应包括特征模板窗口、上下文约束规则、类别标记3个部分。以图2地址为例,其模型构建过程如图3所示。

图3 中文地址模型建立过程举例
4 重庆市中文语义地址模型构建试验
SVM是以数字为特征的分类方法,因此可以将所有地址作为语料库进行编号,以每一个字符在地址要素中出现的频率为权重,通过对语料库的训练,可提高对模型建立中不可预期情况的判断能力。一般而言,不同的核函数对SVM性能影响并不大,而核函数的参数及特征模板C才是影响SVM性能的关键因素[9]。故本文仅考虑核函数参数及特征模板对地址模型构建效果的影响。
本文采用仅有一个参数g的RBF核函数,默认值为1/k,其中k为类别数,由表2得k=15,不包括门址类信息。将南岸区现有地址作为训练语料,从中分别抽取500、1 000、2 000、4 000条地址,并依次设定不同的g值来观察,结果如表3所示。

表3 不同核函数参数下的地址解析准确度/%
由此可得,g值的选取对结果影响很大,当g=0.08时准确度最高,即采用RBF核函数作为SVM的核函数时,当g=0.08时,地址解析效果最佳。
以南岸区原始地址为例,采用中文语义模型和传统人工归纳层级模型分别对500、1 000、2 000、4 000条地址数据进行解析,两者解析的准确度及效率如图4、图5所示。
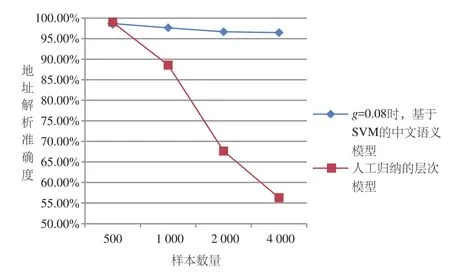
图4 地址解析准确度对比

图5 不同模型建立地址库所需时间对比
5 结 语
本文在分析重庆市地址结构及其规律的基础上,结合行业标准,总结出适合的地址要素分类方式,引入地址要素间空间拓扑关系,增加地址上下文结构约束力。在地址模型构建中,分析人工归纳层级模型的局限性,发现非结构化中文地址解析的关键在于解决歧义问题,提出利用SVM将复杂层级模型映射到高维空间构造判别函数,以提高地址解析准确度和解析效率的技术方法,并通过实验得到验证。后续还可以重点研究模型动态构建方法,进一步提高对标准地址数据建设及地址匹配的应用支撑能力。
[1] 兰小机,彭涛,王飞. 赣州市地理编码系统及其关键技术[J].测绘科学,2009(2):231-232
[2] Dueker K J. Ubran Geocoding[J]. Annals of the Association of American Gepgraphers, 1974,64(2): 318-325
[3] 李军,李琦,毛东军,等.北京市地理编码数据库的研究[J].计算机工程与应用,2004,40(2):1-3
[4] 黄颂. 中文地址编码技术的研究[D].北京:北京大学,2005
[5] 于滨. 面向全国经济普查需求的专家系统地理编码方法[D].长沙:中南大学,2010
[6] GB/T 18521-2001. 地名分类与类别代码编制规则 [S].
[7] 肖振强. 城市地址信息空间化的原理及方法研究[D].青岛:山东科技大学,2011
[8] 王静. SVM在参数选择上的优化[D]. 兰州:兰州理工大学,2008
[9] 周奇. 对支持向量机几种常用核函数和参数选择的比较研究[J].福建电脑,2009(6):42-43
[10] 于滨. 面向经济普查项目需求的模糊中文地址匹配方法研究[D].长沙:中南大学,2010
[11] 柳贺. 省级地理信息公共服务平台框架建设与应用研究[D].赣州:江西理工大学,2012
[12] 杨丽. “数字湖北”中文地理编码数据库建设与服务共享[J].地理空间信息,2013(增刊):37-39
[13] 王斌,程雪洋,林娜,等. 广域范围建筑物信息普查关键技术探讨[J]. 地理空间信息,2014,12(2):32-34
P208
B
1672-4623(2015)03-0122-04
10.3969/j.issn.1672-4623.2015.03.043
臧英斐,硕士,研究方向为地理信息技术应用。
2015-01-28。
项目来源:测绘遥感信息工程国家重点实验室开放基金资助项目(13R03);重庆市教委科技资助项目(KJ1400325);重庆交通大学博士基金资助项目(2012kjc2-011)。
