基于单目序列图像的车辆三维信息的获取
2015-01-25徐晓娟宋焕生赵倩倩
徐晓娟,宋焕生,赵倩倩,徐 昊
(长安大学 信息工程学院,陕西 西安 710064)
在视频交通监控系统中,获取车辆的三维信息对于目标识别、车型分类等都具有重要意义,许多文献都对此进行过研究。
1)基于图像特征的方法,包括图像的轮廓、焦点、明暗和纹理等特征,Wiktin[1]、Warren[2]和 Clerc[3]等学者都对此进行过研究。该方法要求摄像机的标定环境比较理想,图像的分辨率高,在普通的交通监控条件下很难实现。2)基于运动的方法,是指检测多幅图像中需要匹配的特征点集,通过数值分析的方法恢复摄像机参数和物体三维信息。该方法原理简单,对图像的要求不高,但是计算量比较大,Faugeras[4]提出的“几何多视图计算机视觉”理论就是基于该方法的。3)基于多目摄像机的方法,利用多个摄像机对同一个物体同步进行拍摄,通过对每一时刻的灰度图像进行密集的深度映射,从而建立具有真实感的场景模型。该方法重建效果比较好,但算法复杂度高。
本文提出了一种基于单目序列图像的车辆三维信息获取方法,通过摄像机的标定建立三维空间点与图像点的转换关系。该方法原理简单,算法复杂度低、实时性好。
1 摄像机标定
三维场景与二维图像之间的映射关系是由摄像机的内外参数共同决定的,恢复摄像机内外参数的过程称为摄像机标定。其中,内部参数是指摄像机的焦距、特征比、畸变因子等,外部参数是指世界坐标系和摄像机坐标系之间的相对旋转和平移。
1.1 摄像机成像模型
在图像上定义直角坐标系uv和图像坐标系 xy,(u,v)表示像素位于图像数组中的行数和列数,(x,y)表示像素在图像中的物理位置,如图1所示。
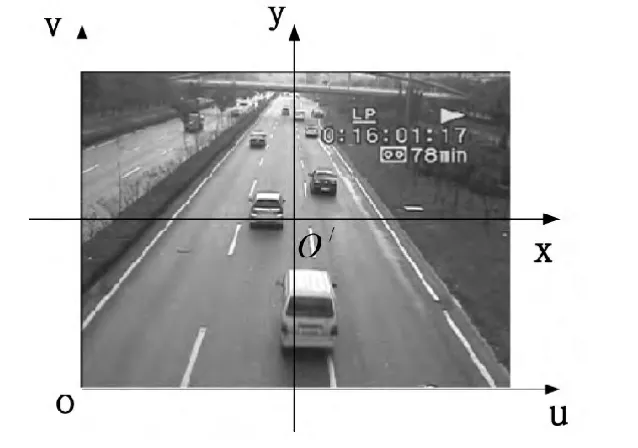
图1 图像坐标系Fig.1 Image coordinate
假设点 O′在坐标系中的坐标为(u0,v0),像素在 x方向和y方向的物理尺寸为dx和dy,则2个坐标系的转换关系为:
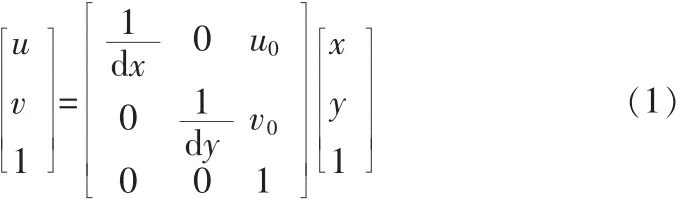
假定摄像机的成像模型为经典的小孔成像模型,即只考虑线性模型,不考虑由于摄像机导致的畸变,如图2所示。xCyCzC为摄像机坐标系,O点为摄像机光心,zC轴为摄像机的光轴,xC轴、yC轴分别与x轴、y轴平行。摄像机光轴与图像平面垂直,其交点为图像坐标系的原点O′。f=|OO′|称为摄像机焦距。

图2 摄像机成像模型Fig.2 Camera imaging model
由于摄像机可安放在环境中的任何位置,我们还需建立一个基准坐标系来描述摄像机的位置,并用它表示物体的三维位置,该坐标系称为世界坐标系xWyWzW。摄像机坐标系与世界坐标系之间的关系可以用旋转矩阵R与平移向量μ来表示:

其中,R为 3×3正交单位矩阵,μ为三维平移向量,0T=[0,0,0]。
如图 2 所示,空间点 P 的摄像机坐标为(xC,yC,zC),对应的图像坐标为(x,y),根据比例关系可得到:
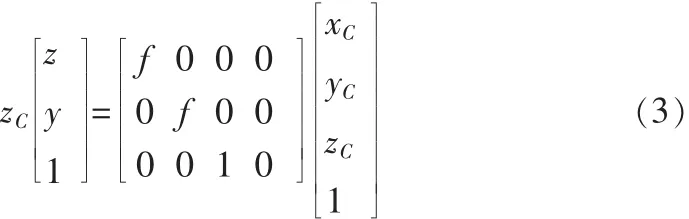
将式(1)与式(2)代入方程(3)得到空间点 PW(xW,yW,zW)与图像点 p(u,v)的关系为:
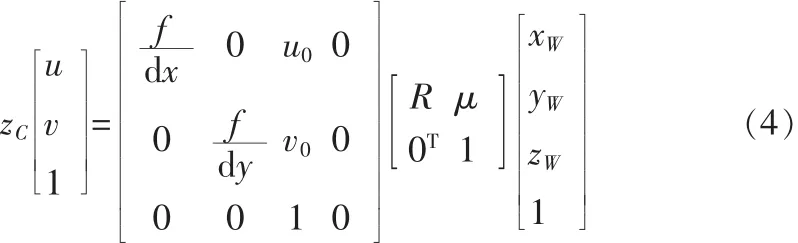
其中,f,dx,dy,u0,v0只与摄像机的内部结构有关,称这些参数为内部参数;R,μ则完全由摄像机相对于世界坐标系的方位决定,称为外部参数。
1.2 二维标定与三维标定
当摄像机及其架设位置固定时,摄像机的内外参数也随之确定,并且不会随着时间的推移和交通状况的变化而改变。因此,可将式(4)变形为:

式(5)表示空间中点到图像上点的映射关系,称为三维标定。当空间中的点位于路面上时,其高度信息为0,即zW=0,计算时并没有用到标定矩阵中的所有参数。此时,定义路面坐标系xRyR,表示点在路面上的位置。我们规定,在路面坐标系的基础上根据右手定则增加第三维坐标可形成世界坐标系,这样位于路面上的点,其世界坐标和路面坐标重合。因此,可将式(5)化简为:

式(6)表示路面上的点与图像上点的转换关系,称为二维标定。
2 车辆特征点3维坐标的获取
根据摄像机成像的原理,空间中点到图像点的映射是唯一可确定,而由图像点获取空间点的过程却是病态的、不唯一的。但是,如果能够借助辅助信息获取PW的1维(或者2维)坐标的话,余下2维(或者1维)坐标的计算便轻而易举。

图3 实时视频图像Fig.3 A real-time video image
如图3所示,点p与点q具有相同的xW和yW坐标,点q位于路面上。根据公式(6)可以计算得到点q的xR和xR坐标,也即是点p的xW和yW坐标,代入式(5)就可得到点p的zW坐标。也就是,首先获得点p的路面坐标,然后根据摄像机的三维标定矩阵计算点p的高度。
上述获取点的三维坐标的方法,主要基于两点假设:1)点p与点q具有相同的路面坐标;2)是点q位于路面上。因此,该方法的关键在于如何找到点p在路面上的投影点q。首先,要确定车辆在图像中的位置,确定车辆与路面的分界线,将车辆目标从路面背景中提取出来,本文采用帧间差分法提取目标。帧间差分法通过对视频序列中相邻两帧图像作差分来获取目标,可以很好地适用于有多个目标的场景。
假设图像序列为Ii,选取视频中连续相邻的三帧图像Ii-1、Ii和 Ii+1,相邻两帧之间进行差分获得两个二值化图像 BW(i-1,i)和BW(i,i+1)。因为实际的交通场景中存在着许多干扰,基于像素点的帧间差分法会产生许多细小的噪声。因此,本文选用基于像素块的帧间差分法,也就是将输入图像分成若干个大小相等的小块,以块为单位在相邻两帧图像之间进行差分,计算公式如下:

其中 Ii(u,v)表示第 i帧图像中像素点(u,v)的灰度值,R为像素块的大小,n为像素块内像素点的个数,T为帧间差分的阈值。当图像中有运动目标时,帧与帧之间会出现较为明显的差别,通过帧差法可以确定灰度变化明显的区域,也就是目标所在的位置。

图4 “与”操作示意图Fig.4 The diagram of“AND”operation
将得到的两个二值化图像进行相“与”操作[5],即可得到当前帧Ii的运动目标轮廓图像Fi。如图4所示,白色区域表示目标,黑色区域表示背景。“与”操作可以消除差分过程由于目标运动造成的目标轮廓增大的现象,提高目标提取的精度。帧间差分法提取目标的结果如图5所示。

图5 二值化目标与特征点Fig.5 A binary foreground mask and feature points
提取图像中目标车辆的特征角点[6],当提取到多个特征点时,对特征点进行筛选,保留位于或靠近目标边缘的点,如图6所示。假设有车辆边缘特征点p,其对应的车辆二值化目标为F。在图像坐标系中,垂直向下投影点p直到目标边缘为止,记此时边缘上的点为q。点q位于车辆与路面的交界线上,点p与点q在路面上的投影一致[7]。由前述可知,点p和点q具有相同的xW和yW坐标,查找二维映射表得到点q的xW和yW坐标,代入式(5)得点p的第3维坐标zW。当提取到了完整的车辆边缘后,计算得到位于边缘线上的特征点的三维坐标,便可恢复出车辆整体的三维信息[8]。
3 实验结果与分析
为了验证上述方法的可行性,选取帧频为25f/s(帧/秒)、分辨率为720×288大小的视频序列进行实验,得到的结果如下。
如图6所示,选取两种车型共7个点进行实验。其中,点1位于路面上,点3和点4具有相同的高度,点6和点7也有相同的高度,实验中摄像机的高度为6.73米(交通视频监控中摄像机的高度一般为4~6米)。实验结果如表1所示。
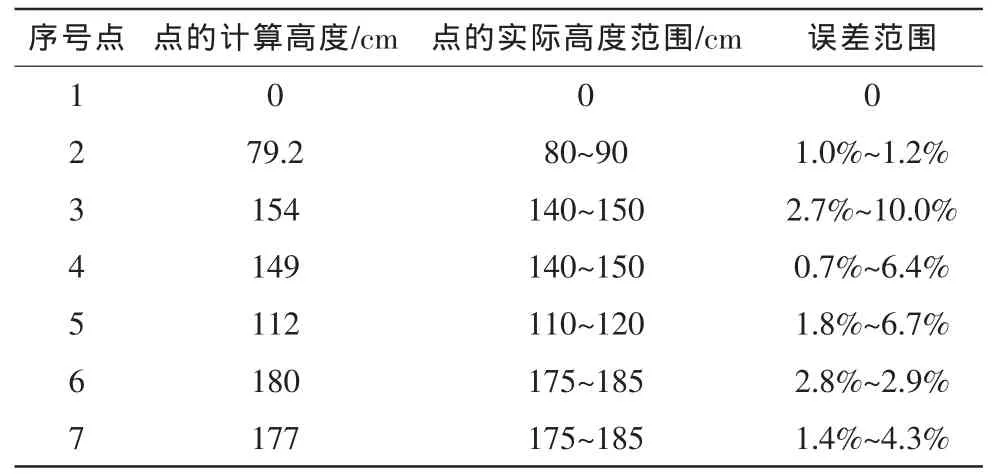
表1 实验结果Tab.1 Test results
由表1可以看出,在获取特征点高度时,图6(a)所示车辆的误差要大于图(b)所示的车辆。这是因为在求取特征点对应的路面坐标时会引入误差,而误差的大小与摄像机架设的高度和车型有关。如图7所示,实验认为点P1、P2和P3对应的路面点均为Q,而实际中只有点P3与点Q对应,利用Q获取的点P1、P2的高度比其实际值要大。并且,这个误差会随着摄像机架设高度的增大而增大。因此,该方法适用于低视角监控下的交通场景。
4 结束语
本文讨论了一种单目序列图像中车辆三维信息的获取方法,并对该方法进行了验证,实验结果较为准确,能够满足车型分类和目标识别等研究的需要。该方法利用车身上点与路面投影点的关系,结合二维标定与三维标定计算空间点的三维坐标,进而获取车辆的整体三维信息。具有计算量小、原理简单的特性。但是该方法也有其局限性,表现在:1)对于架设高度比较高的交通监控系统,该方法引入的误差较大;2)当检测到的目标为非车辆目标时,如水滩等,该方法不具备识别目标与非目标的能力,会计算出错误的高度信息。
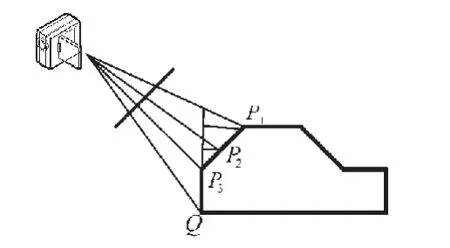
图7 误差分析Fig.7 Error analysis
[1]Witkin A P.Recovering surface shape and orientation from texture[J].Artificial intelligence,1981,17(1):17-45.
[2]Warren P A,Mamassian P.Recovery of surface pose from texture orientation statistics under perspective projection[J].Biological Cybernetics,2010,103(3):199-212.
[3]Clerc M,Mallat S.The texture gradient equation for recovering shape from texture[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(4):536-549.
[4]Faugeras O D.What can be seen in three dimensions with an uncalibrated stereo rig[C]//Computer Vision—ECCV'92.Springer Berlin Heidelberg,1992:563-578.
[5]闫爱云,李海鹏,李晶皎,等.视频运动目标提取的实现[J].东北大学学报,2011,32(11):1558-1561.YAN Ai-yun,LI Hai-ping,LI Jing-jiao,et al.Implementation of moving object extraction in video[J].Journal of Northeastern University,2011,32(11):1558-1561.
[6]shi J,Tomasi C.Good features to track in Porc[C]//IEEE Conf.Computer.Vis.Pattern Recog.,1994:593-600.
[7]Neeraj K.Kanhere and Stanley T.Birchfield.Real-Time Incremental Segmentation and Tracking of Vehicles at Low Camera Angles Using Stable Features.IEEE transactions on intelligent transportation systems,2008,9(1):148-160.
[8]方晓莹,王小君.单目图像序列中三维信息的提取算法及应用[J].电子技术应用,2006(10):34-37.FANG Xiao-ying,WANG Xiao-jun.The extraction algorithm of 3D information from monocular image sequence and its application[J].Application of Electronic Technique,2006(10):34-37.
