基于移动终端的博客搜索引擎系统研究与应用
2015-01-18陈建峡李志鹏
陈建峡,李志鹏
(1湖北工业大学计算机学院,湖北 武汉430068;2湖北工业大学电气与电子工程学院,湖北 武汉430068)
博客(blog)已成为互联网中信息传播的重要途径之一,但博客进入的零门槛和缺少监管也导致它很容易变成新的信息垃圾场[1]。现有的众多博客平台利用了传统的搜索引擎,不仅检索速度慢,而且在服务、管理以及价值导向等方面往往忽略了用户体验[2]。为此,本论文研究并实现了一个博客搜索引擎,从博客内容相关度、论文内容的实时性等方面对博客信息进行排序筛选,为用户提供有价值的信息和良好的用户体验做出积极探索。
博客网站的内容大部分是以RSS文件格式发布的,RSS(简易信息聚合,也叫聚合内容)是一种描述和同步网站内容的格式,RSS文件是非常标准的XML文件,具有标签明确、易于解析等特点,RSS/XML是目前使用最广泛的XML应用[3]。随着RSS技术的发展,必将有更多的信息由RSS来描述,博客搜索引擎也必将会有更大的应用范围和空间。
1 主要技术原理
1.1 Heritrix
Heritrix是开源的Web网络爬虫,其最大的优点是,它可以扩展,开发者们能够扩展它的各部分组件,从而实现各自的抓取目的和逻辑[5]。Heritrix设计非常严格,Heritrix按照robots.txt文件来排除指示和META robots标签。Heritrix的工作过程见图1[6]。
Heritrix主要部件及功能简介如下:
1)Heritrix拥有:a)范围部件:根据规则判定把哪个URI放入队列。b)边界部件:追踪被收集的预定计划的URI,以及已经被收集的URI,挑选下一个URI,将处理过的URI进行去除处理。c)处理器链:包括一些处理器获取的URI,对结果进行分析,将URI回传给边界部件。
2)其余部件:a)WEB管理控制台:绝大部分都是基于单机的WEB应用,内嵌JAVA HTTP服务器。操作人员通过选择Crawler命令的方式来操作控制台。b)Crawler命令处理部件:包括创建要爬的URI的足够的数据信息。c)处理器缓存(Server cache):存放持久的服务器的信息,可以随时搜索到被爬行的部件,包含机器人策略,IP地址以及历史记录。d)预取链:是做一些准备性的工作,例如,对延迟进行重新处理,否定随后的操作。e)提取链:获得数据资源,转换DNS,请求以及响应表单填写。f)抽取链:完成数据资源提取之后,抽取目标HTML,JavaScript,通常那里有符合要求的新的URI,这时URI只是被发现,并不会被评估。g)写链:将爬行的结果进行存储,将抽取的特性和内容进行返回,过滤完后存储。h)提交链:进行最后的维护操作,例如,不在范围内的进行测试,提交至边界部件。
1.2 Lucene
ISE(Iycos Search Engines)中文全称为全文检索引擎,其中Lucene作为开源的ISE工具包。可以说,Lucene仅仅是ISE整体的架构,不能说是比较完整的ISE,它能够给应用程序开发者提供比较完整的查询引擎、索引引擎、少量的文本解析引擎[7]。它以给开发人员提供简单易用的工具包为目标,对应用程序开发人员开发实现全文检索的应用程序提供了很大的便利,同样也能够以Lucene为基础去实现更加完整的ISE。Lucene体系结构见图2。
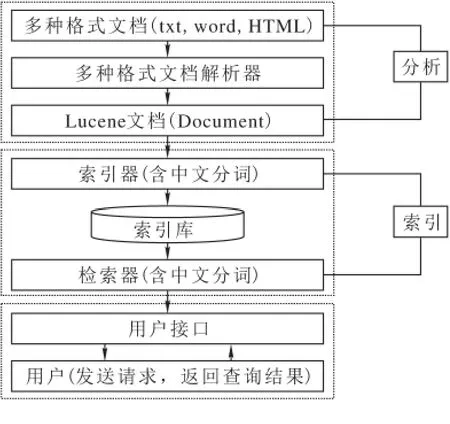
图2 Lucene体系结构图
从图2可以看出,Lucene具有很清晰的整体结构,能够给应用程序的开发人员提供非常好的代码支持,同时Lucene也具备非常良好的可扩展性。Lucene同样对于文件的索引操作进行了良好的封装,尤其是对中文语言的词语分割操作进行了很好的扩展,程序开发人员对于Lucene更加容易理解,更加容易使用。
1.3 Android
Android是以Linux操作平台为基础的开放源代码的手机操作系统,Google公司在2007年11月的时候宣布了该移动终端操作平台的名称,该操作平台主要由操作系统、中间件、用户界面以及上层的应用软件组成。Android操作系统的底层主要是基于Linux内核,采用C语言进行开发,提供的仅仅是一些最基本的功能;Android平台的中间层主要涵盖了虚拟机库以及API库,采用C++语言进行编写;最上层是一些不同形式的应用程序,有SMS程序,软件公司自己开发的相关软件,采用java进行开发。Android平台被称为首个开源的、结构完整的面向移动终端的操作平台。
从软件分层视角出发(图3),Android系统由顶层到底层分别为:应用程序、应用程序框架、Android运行器、系统库、Linux内核这五个模块组成。
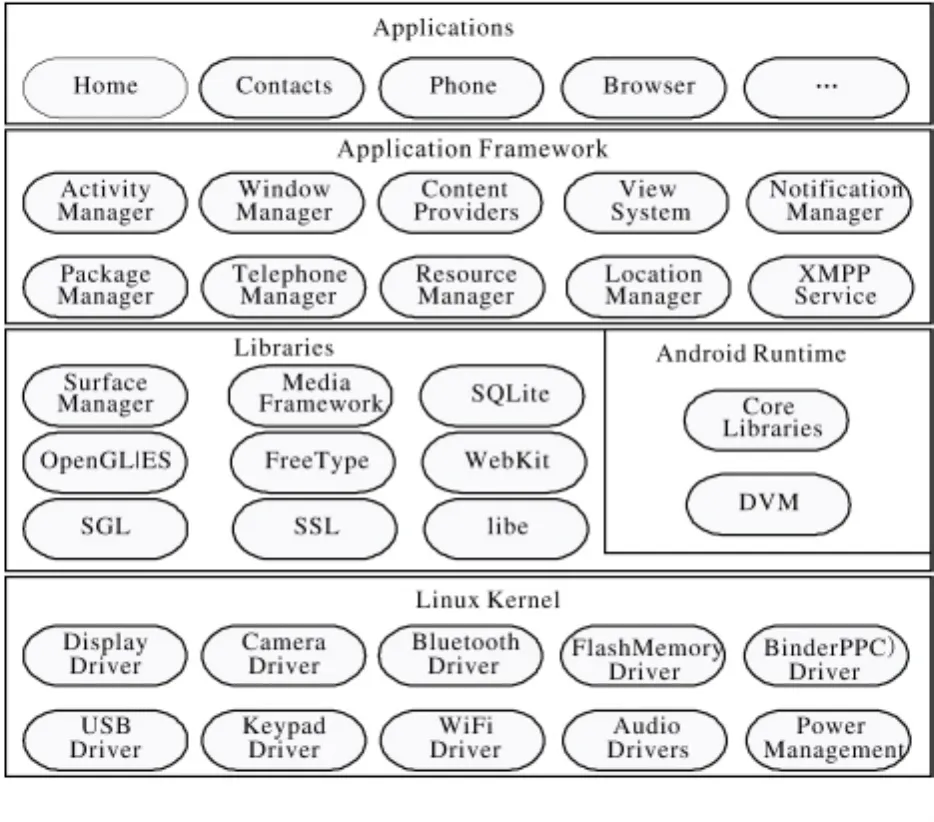
图3 Android系统架构图
1)应用层。最上层的是应用模块,也是一般的Android开发工程师操作的模块,比如打电话、发微博等应用都处于该层;
2)应用程序部件。该部件为Android研发的核心基础,研发人员绝大部分情况下和该部件打交道。该层主要含有管理器、视图系统、电话管理器以及资源管理器等九大部分;
3)Android运行器。Android中应用程序编写采取Java语言,但是,并不采取J2ME运行,相反,是采取Android自带的Android程序进行运行;
4)系统库层。由图3可以看出,Android函数库位于内核层之上,函数库是应用程序框架的基础。函数库中有媒体函数库,SurfaceManager,Webkit,SGL,openGLES,FreeType以及媒体框架,SQLite和Libe等库。
2 RSS博客系统分析与设计
2.1 系统总体设计
基于Android开发的RSS博客搜索引擎,能够完成从RSS博客数据的爬取、RSS博客数据索引、Android用户检索博客的功能,系统总体设计架构图见图4。
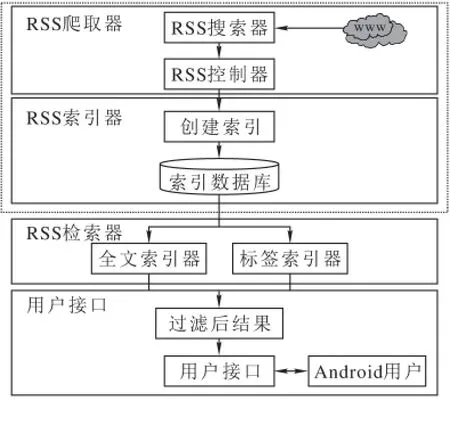
图4 系统总体架构图
2.2 RSS博客数据爬取
2.2.1 RSS博客数据处理 将RSS/XML文件进行切分,并且以博客为单位进行切分,那么在文件中就是对item进行切分。切分完成之后再进行解析并加以索引。
2.2.2 RSS文件的分析与解析 将RSS文件爬取下来,将RSS/XML文件进行切分,并且以博客为单位进行切分,在文件中就是一个item进行切分。切分之后会按照这个文件的文件名形成一个文件夹,文件夹内保存了本论文按照item切分后的文件,切分后也是XML文件。切分完成之后再进行解析并加以索引。
这个RSS文件并没有遵从RSS 2.0标准。在这里本论文自己定义了RSS结构,去除了RSS2.0原本的一些无用信息,只保留了以下几种信息:1)源信息TITLE,相当于站点名;2)源博客链接,也就是源博客地址链接;3)源博客的更新时间;博客内容没有任何改动,从其中可以看到包括博客标题,博客地址,博客内容,博客作者,博客标签,博客评论地址,博客发表时间等信息。
2.3 中文分词的实现
在英文措辞中,单词之间的空格是一种自然的分隔符,而中文只有句、段落由明显的分隔符简单地划分,但是词却没有正式的分隔符,虽然划分问题也存在于英语短语,但这一层的中文比英语要复杂得多,困难得多。目前,常用的Paoding中文分词器、JE中文分词器和IK Analyzer,本论文采用IK Analyzer中文分词工具包,它是一个开源的、基于java语言开发的轻量级的工具包。
IKAnalyzer分词采用从左向右取待切分汉语句中的m个字符作为匹配字段,m为机器词典中最长词条个数,查找词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。Lucene自带分词器和IK分词器的分词效果对比见图5。
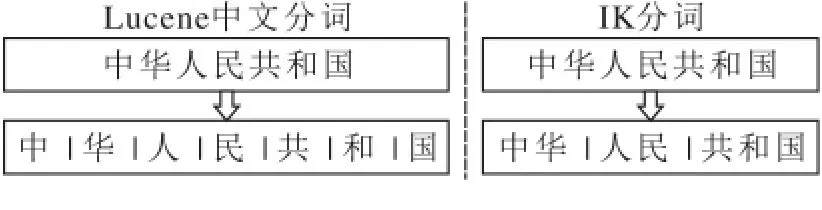
图5 Lucene/IKAnalyzer分词效果对比
由此可见,IK分词器分词准确率明显高于Lucene自带分词器。
2.4 RSS博客索引
有了Lucene[7]的帮助,检索就变得很简单了,只需要调用Lucene自带的API就能轻松的实现RSS检索。索引数据主要步骤为:1)将RSS数据切分成一篇篇独立的博客;2)将XML文件解析成CLASS便于按类别索引;3)利用第三方中文分词器(例如IK分词器)进行中文分词;4)按Title和Description分别进行索引。
3 博客搜索排序优化算法设计
排序优化算法的设计是搜索引擎系统的重点也是难点。由于Lucene自带的网页排序算法仅仅考虑了网页自身的内容,忽略了网页间的关系,导致搜索精确度不高,不能充分体现网页的重要性。本论文利用改进后的PageRank算法对Lucene原有的排序算法进行了优化。
3.1 Lucene排序算法
任何一个搜索引擎给用户最重要的体验绝不在于给用户提供更多的结果,而在于将最重要的结果优先展现给用户。在Lucene排序算法中,所需获取的重要信息并不是用户所查询的关键词在包含的文档中所出现的位置,而是该文档所包含的这个关键词的个数。假如在该文档中所包含的该关键字的个数越多的话,那么这个文档的score就会越高;需要注意的是,如果在该文档当中,和关键词关系不大的词语越少的话,那么该文档的score也会越高。
3.2 PageRank排序算法
前文提及了Lucene的网页排序算法只考虑他们自己的内容,没有考虑网页之间的关系,使得检索精度不高,不能完全反映页面的重要程度。通过对比众多排序算法,本文采用PageRank排序算法对Lucene自带的排序算法进行改进。
PageRank网页排名算法的基本思想最初来源于谷歌的排序算法,它的特点是重视网页的重要程度,只有高度重要的网页在PageRank算法中才会得到较高的评分,运算出web页面的权值,即网页排名,网页排序就会变得更为准确。PageRank的本质是网页排序算法,主要通过数值的形式来表示任意网页在Internet中的重要程度。PageRank算法的原理:通过在Internet中爬取的众多的网页链接中,挑选出来的权值较高的网页链接中所链接到的其他网页,可以认定这些被链接的网页同样也是优质的,根据这个原理对网页的重要程度进行判断[8]。PageRank算法的原理和引用文献的原理差不多,假如一篇文献被引用的次数越多,很显然可以认定这篇文献越有用;假如这篇文献被比较高等级的文献引用,同样能够说明这篇文献越重要。PageRank网页排名算法的特点是,该算法对Internet上所有的网页都有一个全局的权重值排序。而且,PageRank算法中,网页的权重值的计算是离线计算的,对于响应用户请求是非常有利的。PageRank网页排序算法的不足之处在于,很显然,旧网页权重值会比新网页权值大,这就是文中使用时间因子对PageRank算法进行改善的原因。
其计算公式如
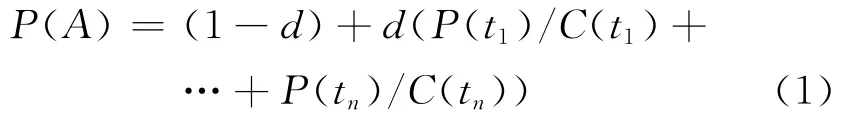
式中,各个参数含义如下:
P(A):网页A的PageRank评分。tl-tn:网页A的被链接的网页。C:网页A的出度值。d(damp factor):阻尼系数(Google d=0.85)。
从公式(1)可以发现,网页的排名权重也就是PageRank值与页面之间的关系是非常紧密的,PageRank网页排名算法采取的是迭代的方法来运算网页排名权重值,也就是说,页面初值选择以及迭代数量,会对计算结果的准确性产生影响。初始值取为1时,加入了阻尼系数d可以保证在实际计算过程中运算的收敛。图6即为PageRank(网页排名)算法流程图。
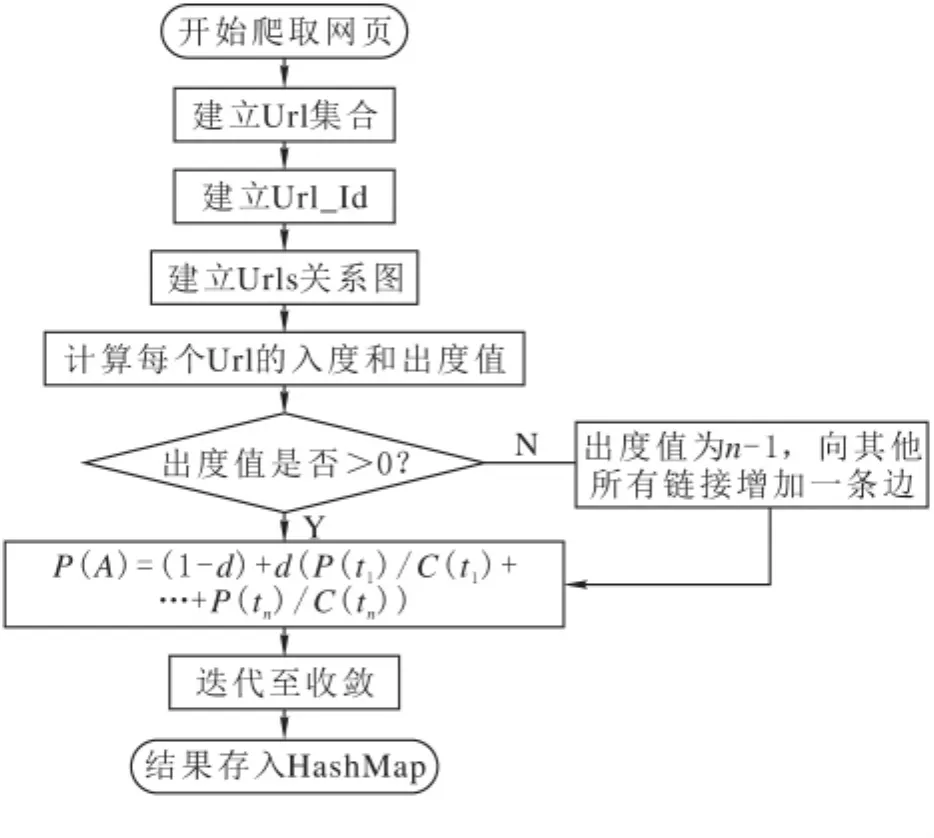
图6 PageRank排序算法流程图
3.3 改进的PR排序优化算法
仔细理解PageRank算法,会发现该算法初期也是有缺点的,对本论文中检索的结果影响非常大的一个关键因素是时间因子,就是本文需要的是最新网页提供的最新消息,也就是人们常说的实时性。假设:一个网页被搜索到的时间与其最近一次被修改时间的差值越大,则网页内容的价值越低,权威性就越低。在这个假设下,引入一个与时间有关的权值t,与网页的权值呈反比。其中,时间因子的取值为t,

改进后的PR排序优化算法流程见如图7。改进后,PR排序得分公式为
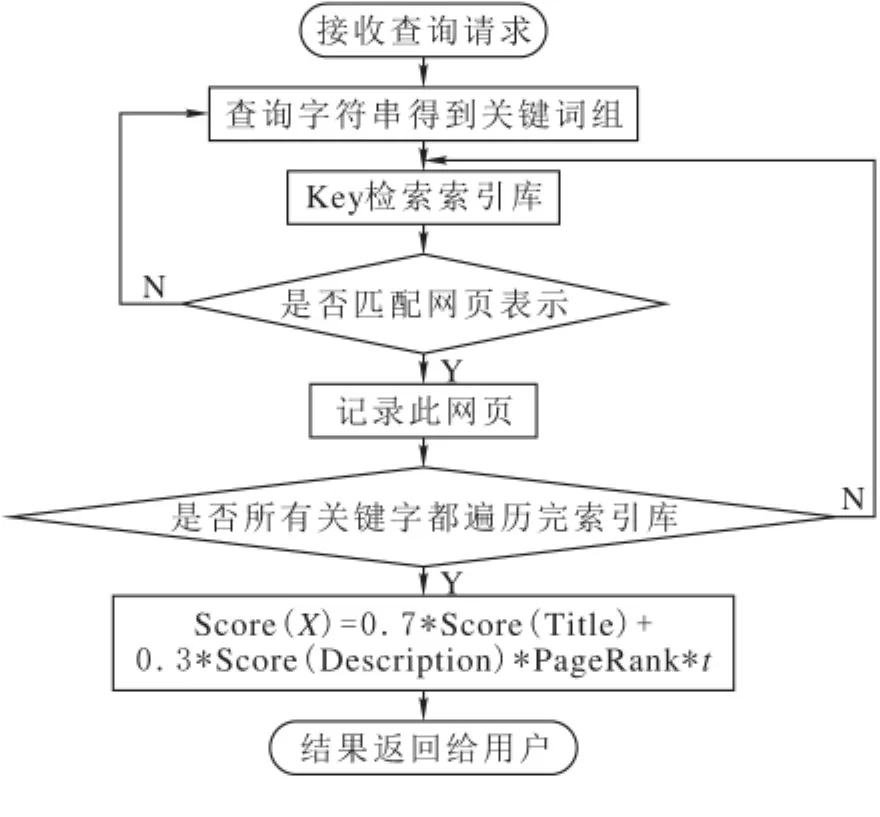
图7 PageRank排序优化算法流程图

公式(2)中的Score(Title)和Score(Description)为Lucen排序对返回结果的标题和内容的评分,PageRank为由Hertrix抓取的链接计算的页面的PageRank值,t为时间因子。
4 实验结果及分析
为进行添加优化后的PageRank算法的Lucene网页排序算法的效果测试,本论文在搜索引擎系统中进行了Lucene排序算法改进前后的性能测试。用两种排序算法对不同的关键词进行查询,然后,分别用改进前后的Lucene排序算法进行测试,搜索“科比”测试结果见表1。需要指出的是为了提高排序的准确度,在计算PR优化后的排序值时,本论文放大了1000倍。
4.1 PR优化算法与Lucene排序算法比较
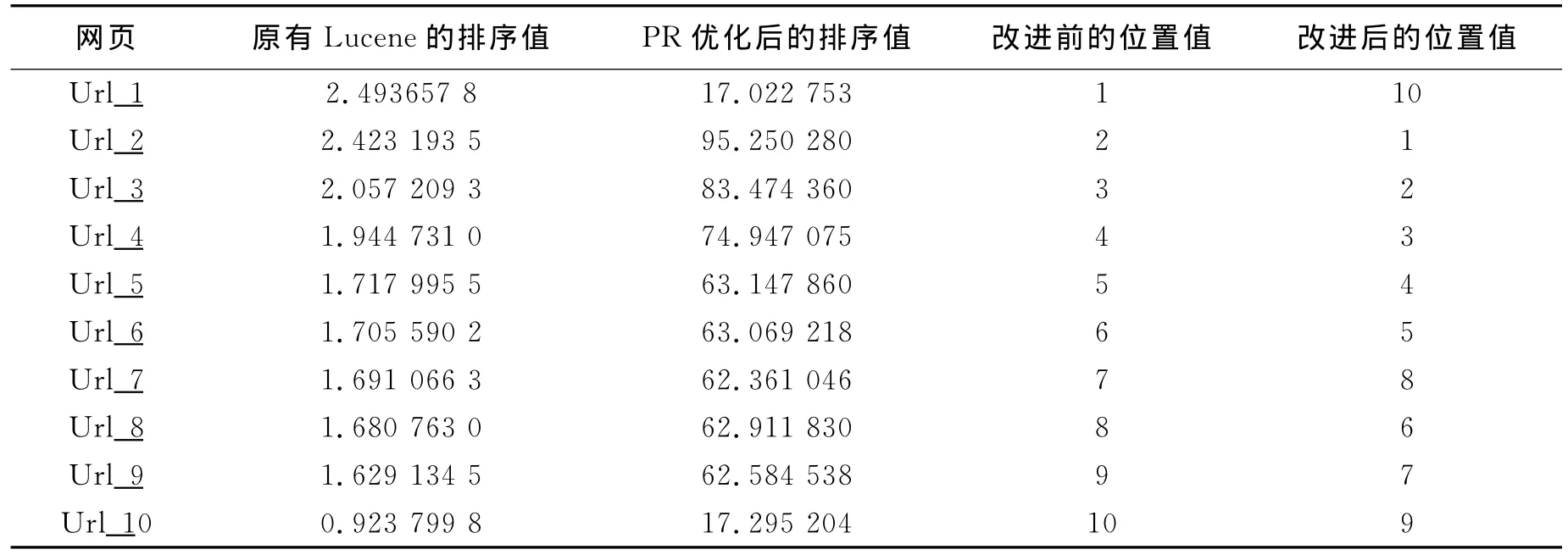
表1 PR优化算法与Lucene原有排序算法的搜索比较
4.2 用户评测结果比较
因为搜索引擎是为网民们提供检索服务,因此,用户的满意度,也就是说,搜索引擎系统返回的检索记录显得尤为重要。本文中,这项工作选择10个测试人员,分别为RSS的博客主题搜索引擎(Lucene排序算法改进前后的系统)进行了测试。测试人员随意选取关键字、单词、短语测试20次,测试用户满意度以前十位作为评价标准,计算满意度
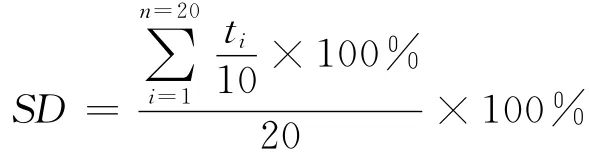
上式中,ti为第i次查询结果集中,测试者认为对自己问题有帮助的信息数量。
4.3 搜索主界面
移动客户端在与PC服务器端成功建立通信之后,就可以进行搜索了。图8就是RSS博客搜索主界面以及搜索界面。
图8 Android客户端运行界面以及搜索界面
5 总结与展望
在深入研究搜索引擎及相关技术的基础上,设计并实现了爬取博客网站的RSS种子连接、提取RSS信息并索引等;并研究了切分XML文件;设计并实现了检索器,并在之上提出了自己的排序优化算法。使用了速度较快的快排算法。未来的工作将会深入研究用户兴趣,完善系统,如收藏博客等。
[1] Dean J.Blog theory:Feedback and capture in the circuits of drive[M].New Jersey:John Wiley & Sons Inc,2013.
[2] 陈建峡,黄 日,马忠宝.基于PageRank的Lucene排序算法优化与实现[J].计算机工程与科学,2012,34(10):123-127.
[3] Cohen E,Kaplan H,Milo T.Labeling dynamic XML trees[J].SIAM Journal on Computing,2010,39(05):2 048-2 074.
[4] Meier R.Professional Android 4application development[M].New Jersey:John Wiley & Sons,Inc.,2012.
[5] Chen,Jianxia,Ri Huang."A price comparison system based on Lucene."2013 8th International Conference on Computer Science & Education [C].Colombo:IEEE-ICCSE,2013.
[6] 吴 伟,陈建峡.基于 Heritrix的web信息抽取优化与实现[J].湖北工业大学学报,2012,27(02):23-26.
[7] Zhao S,Li C,Ma S,et al.Combining pos tagging,lucene search and similarity metrics for entity linking[M].Berlin:Springer,2013:503-509.
[8] Langville A N,Meyer C D.Google's PageRank and beyond:The science of search engine rankings[M].New Jersey:Princeton University Press,2011.
