基于遗传算法及概率论的文本分类算法
2015-01-17宋倩王东明
宋倩王东明
(1.华东师范大学,上海 200241;2.成都理工大学,四川 成都 610059)
基于遗传算法及概率论的文本分类算法
宋倩1王东明2
(1.华东师范大学,上海 200241;2.成都理工大学,四川 成都 610059)
本文意在提高文本分类的准确度和速度。利用tf算法对特征项进行初步赋予权值,再使用屏蔽词对特殊非实意词进行屏蔽。本文独创概率论分布法,使用L-E算子进行加权,使得特殊位置与分布广泛的特征项,呈指数形式加权,较优结果能更快收敛。本文利用遗传算法,采用交叉算子和变异算子,采用适宜的目标函数,加快了检索速度,并有更大概率得到最优结果。采用混合算法,可以排除同义词和非特征项的干扰。
遗传算法;文本分类;特征项
1 引言
文本分类就是在指定的分类模型下,由计算机根据文本内容,自动判别文本类别的过程。当今社会是一个信息高速膨胀的社会,我们希望能在纷繁的信息中迅速找到对自己有用的信息,而不是对所查找的对象逐个浏览筛选。
对于文本分类的研究大约经历了50多年,从1958年至今,经历了文本分类的可行性研究阶段、实验阶段和实用化阶段。国外的主要研究单位有斯坦福大学、麻省理工大学和CMU等,这些单位在理论研究上有很高的水平。国内的研究机构主要有复旦大学、东北工业大学、哈尔滨工业大学、中国科学院等。中文文本分类还处于试验阶段,正确率大约在60%至90%之间。采用聚类粒度原理的VSM分类方法的分类器,正确率可达99.8%[1]。
通过对文本分类的研究,可以加速检索结果,使得用户可以以最快的速度获得对自己最有用的信息,从而满足需求。文本分类的研究,将为信息查询、加工、过滤提供坚实基础。
2 文本预处理
对文本分类首先要对文本进行预处理。它对文本挖掘的效果影响至关重要。预处理的主要目的是抽取代表文本特征的中间表示形式。文本预处理通常包括如下几个环节:去除标记;进行数字合并、词根还原;进行数据清洗以去除不合适的噪声文档或文档中的垃圾数据。
首先,根据代码所用测试文章,进行粗扫描,去除网页标记、特殊符号、参考文献及公式等信息。这些只是文章在完成自己所需要的必要陈述时,所做的带有引用性质步骤。我们完全有理由认为,这些不能表示这篇文章,可以被剔除。
其次,将文本读入。将标题段单独存储为一段;按回车键区分段落,即遇到回车键则系统默认文章进入下一段;按空格号区分词语,即遇到空格符则默认此特征项已输入完毕。
再次,将仅首字母大写的单词小写后存储;将至少有两个字母大写的单词保留大写格式保存,作为不同的特征词。
最后,去除非句号标点符号,例如逗号、引号、冒号等。对特殊位置进行标记,主要指标题、段首、段尾等。这样标记有利于下一步特征项词频统计。
3 特征项抽取
我们以特征项作为文本表示的基本单位。特征项,即关键词,是指一篇文本中相对重要而能表现文本特征的词语。我们用权值来衡量不同的特征项在文本中的重要程度。权值越大,对应于该特征项对于该文本越重要。权值体现了该特征项对于文本内容的反映能力。由于不同的词汇在文本中出现的频率与统计特性会不一样,我们可据此抽取关键词并衡量其权值。
3.1 权值计算
3.1.1 tf算法
tf即特征项频率,是指某个特征项在文本中出现的次数。出现次数越多,则赋予更大的权值;不常出现的词语,则被赋予较低的权值。这种方法简单、效率高,在文本篇幅很长的情况下普遍适用,是最初文本分类常用的方法。但其与信息论中“出现频率越低的信息,其信息量越大”的思想有所出入。事实上,在某些情况下,频率低的词语常常含有对文本非常重要的信息。因此这种方法不够完善。
3.1.2 idf算法
idf即倒排序算法。仅仅使用tf算法会出现一个问题,文档中出现的大量禁用词会干扰特征项抽取。例如英文文本里的“is”、“are”等。
倒排序算法着眼于文档集合,计算含有相同特征项的文本数量。其数量越多,则该特征项对于辨别相似文本的作用越低。若某一特征项在所有的文本中含有,则此特征项的权值将置0。
倒排序的核心是,认为在少数文本中出现的关键词比在大量文本中出现的关键词重要。倒排序算法能够有效减少禁用词的影响,以便抽取到更准确的特征项。
3.1.3 词频统计与L-E线性指数加权因子
首先,我们对于文章按段为单位,对每一个特征项在每段(包括)标题出现的次数做统计。期间,标记标题出现的词语,以及段首段尾出现过的词语,以及在标题出现的次数和在段首段尾出现的次数。
其次,对于均匀分布的特征项进行权值加权。但均匀分布的标准是什么呢?每段出现特征项次数差不多,是均匀分布吗?显然不是,因为一般情况下,文章的段落有长有短,而特征项出现的次数将受限于段落的长度。特征项在每段(不包括标题段)出现频率比较相似,波动不大,比较符合均匀分布的概念。
使用方差去评价似乎很合理。但使用方差有一个问题。对于某些特殊文章,第一二段可能只是作为文章的引入,这时出现特征项的概率非常小。而使用方差计算,这时一个低概率的项会对整体计算产生巨大影响。在此,我们提出了L-E线性指数加权因子。
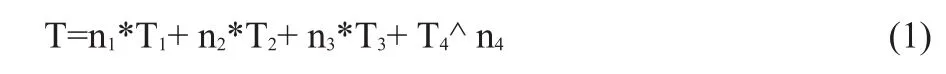
其中,T为该特征项在整个文章中的加权总次数;T1为该特征项在整篇文章出现过的次数;T2为该特征项在标题中出现的次数;T3为该特征项在文章段首段尾处出现过的总次数;T4为该特征项在整个文章中的T4段都出现过。
n1为一个由文章篇幅决定的常数,文章越短,值越大,本文取1;n2为一个由标题相对文章长度比值决定的常数,比值越小取值越大,本文取10;n3的取值由文章段落字数大小决定,文本取5;n4的取值影响分布广泛的特征项的收敛速度,本文取2。通过这种方法,可以既排除了部分特殊情况对方差影响较大的情况,又使得收敛加快。例如,仅在文章一段中出现的词语,最末项加权后仅为1;而出现在5段中的特征项最末一项加权为25,大大加快了分布广泛的特征项的收敛速度。
特征选择一般是通过设置阈值来控制的。当某一特征项的权值大于阈值时,我们将该特征项作为参考特征项;如果特征项的权值低于阈值,则忽略该特征项的作用。我们特征项选择,利用屏蔽词来进行。我们利用屏蔽词容器,可以屏蔽掉大部分非实意词。当然,我们的屏蔽词容器以宁缺毋滥为原则,不包含绝大多数的名词和动词,主要为介词、情态动词等非实意词,最后的特征项的概率分布如图1。

图1 文本特征项概率分布
4 基于并行遗传算法的文本特征项提取
遗传算法是对达尔文生物进化理论的简单模拟,其遵循“适者生存”、“优胜劣汰”的原理。遗传算法模拟一个人工种群的进化过程,并且通过选择、杂交以及变异等机制,经过若干代以后,总是达到最优(或近最优)的状态。其主要步骤如下:
4.1 二进制编码
染色体中的每一位对应原始特征词集合中的一个特征词,当该特征词被提取时对应染色体位置为1,不被提取时置0。这种方法即使在特征词集合很大时,占用的空间也很小。例如,有一个数量为8的特征项群。选取第2、4、5、7、8个特征项,则其编码为:01011011。
我们设置最初始的染色体个数为2,其基因序列值是随机产生的,通过之后的一代代繁殖产生新个体,满足遗传规律。
4.2 遗传算子
4.2.1 选择算子
选择算子用于对目前这一代的种群,进行配对,以繁殖产生下一代的操作。遵循客观生物遗传规律,选择算子应符合随机原则。具体操作如下:
确定某一代种群,随机产生两个随机数(数字应小于该代种群数量),则编号为相应数字的两个染色体被配对。准备进入交叉操作。对各代分别进行以上操作,即不允许出现不同代个体之间进行配对的情况。
4.2.2 交叉算子
具体操作如下:
1)随机产生一个[0,1]之间的数r,如果r<=Pc(Pc为交叉概率,本项目取0.6),则转(2),否则直接退出交叉。
2)随机产生一个[1,8]之间的自然数,作为交叉位。将两父个体从交叉点处进行基因交叉互换,形成子代个体。
例如,两个序列分别为1011101和1100001的染色体,随机产生交叉概率大于0.6时,则对这两个个体进行交叉。当符合交叉条件时,产生一个随机数确定交叉位置。例如这个数是2,则交叉后的产生的新的染色体为1000001以及1111101。
4.2.3 变异算子我们选择简单的变异算子来使用。具体操作过程如下:
1)随机产生一个[1,8]之间的自然数C,作为变异点个数。
2)随机产生一个与上一轮不重复的[1,8]之间的自然数,作为变异点。
3)随机产生一个[0,1]之间的数r,如果r<=Pm(Pm为变异概率,本项目取0.6),则转(4),否则直接转(5)。
4)将父体在变异点出进行基因变异(即0变为1,1则变为0)。c=c+1。
5)如果c>C,退出变异,否则转(3)。
4.3 适应度函数
我们用欧氏距离来衡量文本的相似度。关键问题是如何计算不同特征项所组成的染色体表示的一个文本的相似度。为解决欧氏距离计算问题,我们采取下面的办法:
1)将两个染色体提取的特征词进行扩充,取两者的交集,使得两者表示的文本向量维数变为一致。
2)用两个染色体分别表示同一文本。此时要注意:对两个染色体来说,如果某一个特征词在该染色体中没有被提取,则将该染色体表示的文本向量在对应位上置0。举例说明一下。现在有两条染色体,分别为GA1=101111000,GA2=001111001,原始文本向量为{0.09,0.08,0.04,0.22,0.08, 0.24,0.14,0.03,0.08},则GA1的文本向量为{0.09,0.04,0.22, 0.08,0.24,0},GA2的文本向量为{0,0.04,0.22,0.08,0.24,0.08},最后,利用公式即可得到欧氏距离。
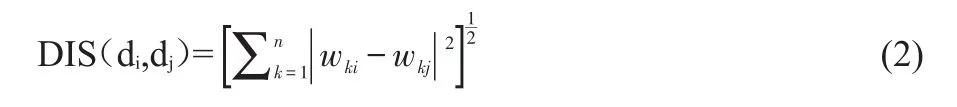
其中di是指第i个文本;wki指第i个文本的第k个特征词的出现概率。通过这种计算,三代间最佳染色体基因序列一致,或者繁殖已达10代,则退出遗传算法计算,得出结果。
需要说明的是,我们为防止染色体畸变,设置了染色体性状显隐形阈值。也即,染色体里显性性状与隐性性状都不得低于35%。显性性状,是指染色体基因序列上取1的性状;隐性性状,是指染色体基因序列上取0的性状。这样可防止染色体收敛于全0或全1。
5 对文本进行分类
排除文本同义词的影响,将最终选择的特征项赋给文本对象。输出数据包括文章各段落的读入内容,以及该段的主要词汇;每个关键词,它是否在标题出现,是否在段首段尾出现,以及出现的次数;分布的段落以及在文章中出现的次数;该特征词加权后的出现概率;参考文档的特征向量;得到的染色体通过遗传交叉变异处理,进行分类判断。
6 结束语
本文利用遗传算法及概率分布,提取文本特征项并对其进行抽取以得到对文本进行分类的目的。在信息检索这个领域已有理论成果的基础上,我们加入了概率论的知识提取关键词。若关键词在文本中分布较为均匀,则加大其权值。通过测试,我们发现这种算法可以提高文本分类的速度与准确度,最后的利用染色体序列计算欧式距离来判断文本相似度,结果如表1。
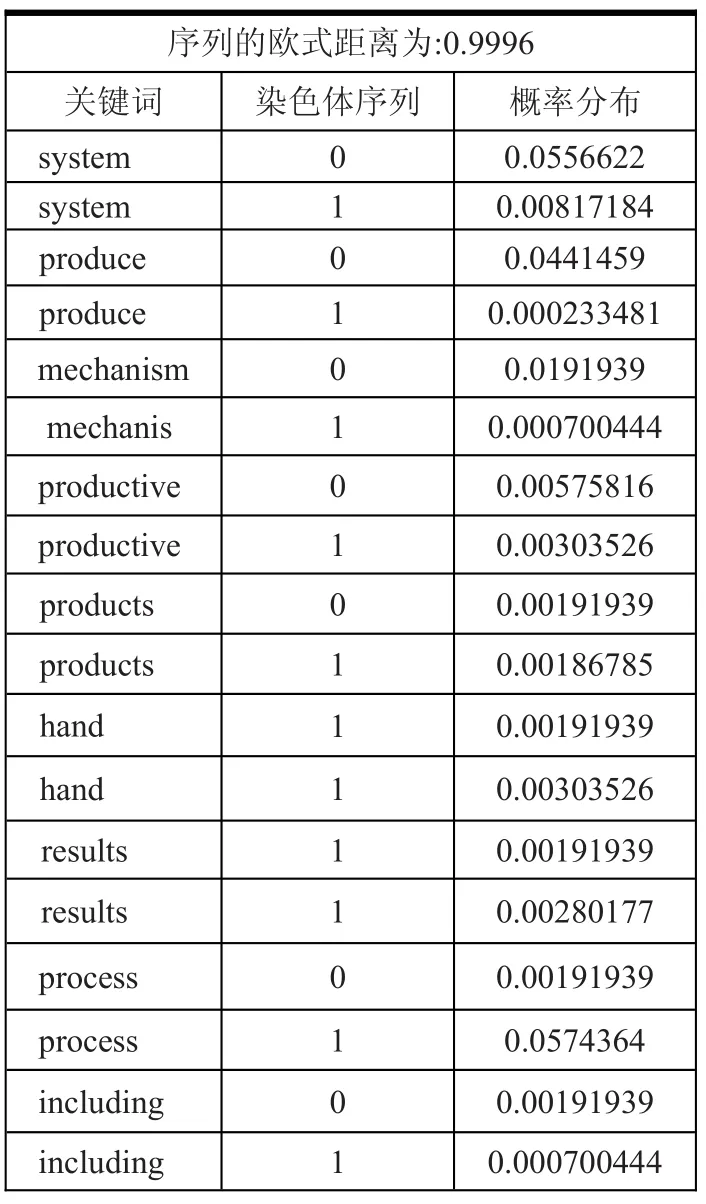
表1 文本相似度
[1]戴文华.《基于遗传算法的文本分类及聚类研究》[M].北京:科学出版社,2008,14-67.
[2]Salton G,Buckley B.Term-Weighting approaches in automatic text retrieval[J].Information Processing and Management,1988,24(5):513-523.
[3]Fodor I K.A survey of dimension reduction techniques[R].Technical report UCRL-ID-148494,LLNL,2002.
[4]Lewis D D.Features selection and feature extraction for text categorization[J].Pattern Anal Applic,2003,6:301-308.
Text ClassificationAlgorithm Based on GeneticAlgorithm and Probability Theory
Song Qian1Wang Dongming2
(1.East China Normal University,Shanghai 200241; 2.Chengdu University of Technology,Chengdu 610059,Sichuan)
act】This article aims to improve the accuracy and speed of text classification.T*f algorithm is used to initially weigh the feature item,then stop words is used to shield specially meaningless words.Original probability distribution method and weighted L-E operator enable the features in the special positions or widely distributed to weight in exponential form,so that the better results converge faster.In this paper,by using the genetic algorithm,crossover operator and mutation operator,and adopting appropriate objective function,the retrieval process speeds up,and has a greater probability to get the optimal result.Hybrid algorithm is proposed,which can eliminate the synonyms and the characteristics of interference.
genetic algorithm;text classification;term
TP301.6
A
:1008-6609(2015)03-0049-04
宋倩,女,四川南充人,学士,研究方向:电磁通讯。
大夏基金项目,项目编号:2013DX-241。
