基于高层语义词袋的人体行为识别方法
2015-01-17黄少年
黄少年 施 游
(1.湖南商学院计算机与信息工程学院,湖南 长沙 410205;2.湖南师范大学,湖南 长沙 410083)
基于高层语义词袋的人体行为识别方法
黄少年1施 游2
(1.湖南商学院计算机与信息工程学院,湖南 长沙 410205;2.湖南师范大学,湖南 长沙 410083)
人体行为分析为视频监控系统、视频检索系统提供重要的研究基础。本文提出了一种基于高层语义词袋模型的人体行为识别方法。该方法根据底层词袋中词汇的相关关系,构造出一个基于词汇交互信息量的底层词汇图;然后使用层次聚类的方法对该图进行分割,得到底层词汇组模型,最后将该模型表示为高层语义词袋模型。实验结果表明,该方法可以高效地识别视频中的人体行为。
行为识别;语义词袋;视频监控
1 引言
人体行为分析是计算机视觉领域的重要分支,其在智能视频监控、视频分类和检索、人机交互等领域具有重要意义。由于视频场景的复杂性(如:遮挡、多对象交互、光照变化等),人体行为识别仍是计算机视觉领域中最具挑战性的问题[1]。
一般来说,人体行为分析的方法主要包含两部分:行为模型的表示和行为分类的方法。行为模型的表示一般可大致分为五类:基于形状的模型、运动模型、肢体几何模型、兴趣点模型和动态模型。基于形状模型的人体行为识别方法通常需要精确地估计视频中运动对象的轮廓,从而提取运动对象。这类方法通常不受运动对象的光照、颜色和纹理变化的影响,但运动对象的精确提取依旧是一个需要深入研究的问题[2]。基于运动模型的方法提取运动对象的各种行为特征,如光流、时空卷、3D局部运动特征等。基于肢体几何模型的方法通过构造带参数的集合模型进行人体行为的识别[2]。基于兴趣点模型的方法是一种研究得最为广泛的行为识别方法。该类方法使用兴趣点表示人体行为,如:时空兴趣点模型、运动立方体模型等。基于动态模型的方法需要定义每个人体行为的静态姿势以及其运动过程,是比较早期的行为识别模型。在行为分类的方法中,基于机器学习的方法应用得较为广泛,如NN分类器、SVM分类器等[2]。
本文首先提取视频的各种视觉特征,形成低级特征词袋模型,然后通过图模型构造一个高层语义的词袋模型,并以此进行人体行为的识别,实验结果表明,该词袋模型能有效地识别各种实验数据库中的各种人体行为。
2 底层特征词袋表示
词袋模型最早被提出是用于文本检索的研究[3]。人体行为识别中的词袋模型通常首先提取训练视频或训练图像的各种特征,然后通过聚类算法形成词典。而测试视频或图像通常被看成一个由词典词汇组成的文档,通过将视频或图像表示成词典直方图的形式来进行人体行为的识别。本文首先提取视频的视觉特征,形成底层特征词袋模型。本文中使用的底层特征描述子如下:
SIFT:由于SIFT特征的尺度不变性、旋转不变性和视角无关性,该特征被广泛用于视频内容分析的各个领域,如运动对象检测、视频概念检测等。本文使用高斯差分算子提取视频中的局部特征点,并通过提取特征点梯度信息,得到128维的特征描述子表示特征点。
STIP:运动特征也是视频序列中的重要信息。时空兴趣点(STIP)通过提取图像序列中在时间和空间上具有明显变化的特征点来表示视频的运动信息。本文使用Harris3D角点检测器定位时空卷,再将该时空卷划分成18个网格单元。对每个网格单元,本文计算其4维梯度直方图和5维光流直方图。通过梯度直方图和光流直方图的直接连接,得到162维的运动特征描述子[4]。
为了得到底层特征的词袋表示模型,我们使用k-mean均值聚类方法对上述特征描述子进行聚类,得到SIFT特征词典和STIP特征词典。实验阶段的每个视频序列,都表示成为词典直方图的描述形式,方便后续讨论高层语义词袋模型。
3 高层语义词袋表示
词袋表示模型由于采用数据特征的稀疏表示,结构简洁方便,已经在多种视频分析应用中展示出了良好的实际效果。但由于在构造特征词典时,忽略了视频行为中暗含的时序和结构信息,其在复杂人体行为识别中的实际效果还有待进一步提高。本文针对低级特征词袋的这一特性,根据低级特征词袋的相关性,设计了一个基于高层语义的特征词袋表示,以此进行人体行为识别。
3.1 低级特征词袋图表示
根据底层特征的相关性,我们构造了一个底层特征图来描述底层特征词袋图,并通过对图的分割,得到高层特征词袋的表示。我们将含有n个视频的训练集表示为T= {ti}n
i=1,第i个视频的SIFT特征直方图表示为h1i,第i个视频的STIP特征直方图表示为h2i,因此,第i个视频的底层特征可表示为hi={[ h1i,h2i}。通过对所有训练视频的底层特征进行均值聚类,我们得到了基于SIFT特征的词袋表示模型w1= {w1
1,w12,……w1n}和基于STIP特征的词袋表示模型w2= {w12,w22,……w2m},其中参数n,m分别表示SIFT单词和STIP单词的个数。
我们定义了一个无向图G={V,E},其中V和E分别表示顶点和边的集合。顶点V的集合表示为V=V1⋃V2,其中v1对应于模型w1中的单词,而v2对应于模型w2中的单词。边集合E中的每条边分别连接v1中的SIFT单词和v2中的STIP单词。为了度量底层特征STIP和SIFT之间的相关关系,我们基于点交互信息量来进行描述。首先我们对所有视频的特征直方图表示hi进行归一化,则图G中的任意边k,l之间的权值wkl可表示为:

其中h1k2l表示联合概率密度。通过以上定义,我们描述了底层特征之间的相关关系图,图1示意了底层特征关系图,根据此图,我们对图进行分割,并提取高层语义特征表示。

图1 低级特征词袋图
3.2 词袋图分割
为提取高层语义词袋,我们对3.1节中的特征词袋图进分割。根据图割理论[11],图割度量了不同边集合之间的差异性以及同一边集合内部的相似性。本文采用基于边集合内部的最大相似性进行图割表示[12],边集合的最大相似性定义为:

其中w(Vi,Vi)表示顶点集合中的Vi所有边权值的和,d (Vi)表示顶点集合Vi中所有顶点的度。
本文采用了一种贪婪层次聚类的方法进行图分割。我们定义了一个边的变化关联矩阵∆来进行初始分割:

其中,(u,v)表示聚类得到的顶点集合,初始聚类时,(u,v)表示边集合中的E中的顶点。在每一次聚类过程中,我们选择矩阵∆中的具有最大元素值的顶点形成新的聚类组uv*,将该新的聚类组uv*插入矩阵∆,并删除该矩阵中原有的和顶点(u,v)的行和列。新的聚类组uv*和其余顶点的边权值关系按以下公式进行更新:

按照上述方法进行层次聚类,最终得到新的特征组表示,即高层语义特征表示。
3.3 人体行为识别
通过3.2节中的图分割方法,我们得到不同的特征组表示,将不同特征组中的底层特征进行连接,即可表示为新的高层语义词袋模型w={w1,w2,……wk},其中k表示高层语义词袋模型中单词的数目。
为了进行后续的行为识别,我们需要将每个视频的特征表示池化了高层语义词袋的形式,本文采用平均池化的方法来进行底层特征的池化,并得到视频的高层语义词袋表示的直方图表示H={H1,…,Hl}。
在行为识别的方法上,由于基于SVM的方法在人体动作识别上表现出的优越性能,本文使用基于x2核的SVM方法进行动作识别:
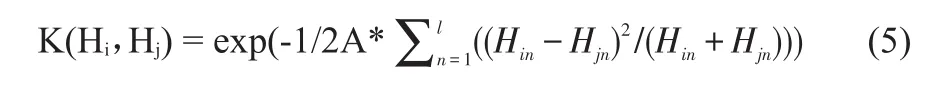
其中,Hin和Hjn表示高层词汇的频率直方图,l表示高层词袋模型中词汇的数目。
4 实验

图2 KTH数据库示例图
本节中,我们将评价本文方法及其它相关方法在实验数据库上的性能比较。我们使用人体行为识别中的常用数据库KTH数据库[5]进行性能评价。该数据库中包含六种人体行为:走、慢跑、跑、拳击、挥手和鼓掌,如图2所示。该数据库中的每种动作由25个不同的主体对象在四种场景下完成。该数据库中的视频背景相对静止、摄像机的运动比较简单。该数据库中共包含2391个视频片段。本文采用与文献中相同的实验设置,将数据库中9个主体对象的运动序列作为测试集(主体:2,3,5,6,7,8,9,10,22),余下主体对象的运动序列作为训练集。
本文采用文献中[6]的Harris3D角点检测器提取的不同时空描述子与本文提出的高层语义词袋(HC_based)方法分别在KTH数据库上进行人体行为识别的实验,并统计了不同方法在各类视频序列中的识别精度以及其平均精度(MAP),其对比结果如下:

表1 KTH数据库上基于不同方法的行为检测精度
从对比实验的结果中可看出,在基于底层特征词袋的方法中,基于HOF特征和HOG/HOF特征的检测方法在KTH数据库上取得了较好的效果,而本文基于高层语义词袋的方法在平均检测精度上则高于上述两种方法。特别地,在“慢走”和“挥手”这两类视频中,本文的方法取得了较好的识别精度,而在传统方法中,这两类视频的识别精度通常不高。由此可见,本文提出的基于高层语义词袋的视频行文分析方法有效地改进了现有的词袋表示方法,在视频行为识别的应用中有一定的实际意义。
5 结论
视频行为分析是视频监控系统中的重要内容,通过对视频中人体行为的识别,可以为视频监控系统、视频检索系统提供重要的研究基础,因此,视频行为分析已经成为机器视觉领域的一个重要研究课题。本文通过对现有的基于语义词袋方法不足的分析,提出了一种基于高层语义词袋模型的人体行为识别方法。该方法通过构造底层语义词袋图模,提取具有相关关系的底层语义词袋组,从而构成高层语义词袋。通过与现有方法的实验对比结果,可以看出,本文的方法提高了现有方法的检测精度。在以后的工作中,我们将进一步将本文方法应用到不同的实验视频中,提高本文方法的适用性。
[1]满君丰,李倩倩,温向兵.视频监控中可变人体行为的识别[J].东南大学学报:自然科学版,2011,41(3):492-497.
[2]邵延华,郭永彩.基于特征融合的人体行为识别[J].光电子.激光,2014(9):1818-1823.
[3]秦华标,张亚宁.蔡静静.基于复合时空特征的人体行为识别方法[J].计算机辅助设计与图形学学报,2014,26(8):1320-1325.
[4]雷庆,陈锻生,李绍滋.复杂场景下的人体行为识别研究新进展[J].计算机科学,2014,41(12):1-7.
[5]Schuldt C,Laptev I.Recognizing Human Actions:Alocal SVM Approach[C]//Proc.of the 17th International Conference on Pattern Recognition.Cambridge,UK:IEEE Computer Society,2004:32.
[6]Laptev I,Marszalek M,Schmid C,et al.Learning realistic human actions from movies[C].In CVPR.USA:IEEE,2008:1-8.
HumanActivity Recognition Based on High-level Semantic Codebook
Huang Shaonian1Shi You2
(1.Hunan University of Commerce,Changsha 410205,Hunan;2.Hunan Norma University,Changsha 410084,Hunan)
act】Human activity recognition is the important basis of video surveillance system.In this paper,a new activity recognition method is proposed based on the high-level codebook.We construct a code-word graph based on the mutual information of lowlevel code-words,and then partition the graph into different groups,which discover the high-level code-words patterns.Experimental result shows that the proposed method can effective recognize human activities.
activity recognition;semantic codebook;video surveillance
TP391
A
1008-6609(2015)03-0037-03
黄少年,女,湖南常德人,博士,讲师,研究方向:机器视觉、视频内容分析等。
湖南省教育厅资助科研项目,项目编号:No.13C474。
