一种基于领域本体的资源反馈检索模型研究
2015-01-17林丽姝
林丽姝
(海南经贸职业技术学院,海南 海口 571127)
一种基于领域本体的资源反馈检索模型研究
林丽姝
(海南经贸职业技术学院,海南 海口 571127)
针对现有资源平台无法互通共享资源,资源库检索系统仅依靠用户输入的单词关键字描述检索资源而无法挖掘用户需求中的语义信息的问题,提出了一种基于本体的资源反馈检索模型。该模型通过构建本体、概念相似度计算、查询关键字扩展等关键技术,利用了用户多次反馈中的包含语义知识,满足了用户的查询需求。实验表明,该模型能够有效提高检索的性能。
领域本体;资源检索;知识反馈
1 引言
现代信息的发展引起了资源的爆发,同时为了更好地使用资源、利用资源,很多机构特别是教育部门都积极地建立起资源检索平台,以达到资源共享的作用。每个资源检索平台都“各自为政”,资源的重复不可避免,但又因为自身建设特色所限,无法囊括所有的特色资源,没法给用户一个“一站式”搜索的体验。所有用户有时为了满足自己的需求,甚至要登陆多个信息检索平台多次搜寻,造成了时间和精力的浪费。
在传统的资源检索系统中,只能针对某个资源库平台来进行。而资源存放目录、学科分类等分类方式掺杂了太多人为的主观意念。往往同一个资源在不同的资源库平台中的存放规则不同,资源所属的分类也会有差异,这样就造成用户也不能通过相同的搜索规则来进行查询同一类的资源。资源库平台之间的共享共用也几乎成了一句空话。即使是使用关键字进行资源检索,如果用户不能准确地使用关键字来描述目标资源,那么检索系统更难以理解用户的意图,更不能通过知识推理来进行关键字的语义匹配,无法实现智能化的资源检索。
针对目前高校建立的教学资源库平台存在的资源难以共享和检索效率低下问题,提出一种基于本体的资源反馈检索模型。该检索模型尝试基于领域本体来构建,用户可以通过该检索平台同时连接检索各高校教学资源平台。用户不需要多次登录,即可同时在多个教学资源平台中找到合适的资源。该模型的特色在于借助概念相似度算法和查询关键字扩展,并将用户在检索过程中的语义反馈反映到检索模型当中,能够解决目前高校资源平台存在的信息鸿沟和信息重用等问题,提高检索效率,使信息资源得到有效的利用和科学的管理。
2 资源反馈检索模型
在进行资源检索时,用户不但希望能够过滤掉无用的干扰信息,也希望能够高效率地得到有价值的、符合自身要求的资源,以便帮助自己解决问题。本体(Ontology)能够准确地描述资源的语义含义,使用基于领域的本体模型,可以在语义层次上描述资源,从而能够实现Web语义检索。
通过领域本体的构建,利用本体作为一种能够实现语义理解的有效方法的优势,对用户的查询请求进行相似度计算、语义扩展,使得用户每次的反馈得到不断优化,最后检索到的结果能够通过反映出用户语义层次上要求的信息。同时,基于本体的构建方式,不同资源库平台的资源的共享工作不再受限于资源存放规则,只要描述关键字能够准确体现出资源的内容和特点,那就可以达到在检索平台“一站式”检索到多个资源库平台有价值资源的效果。
整个检索模型的框架如图1所示。
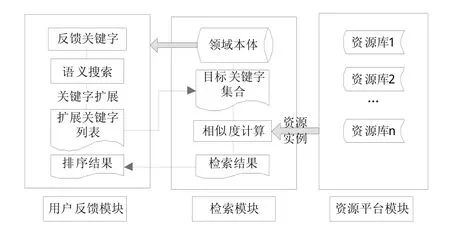
图1 检索模型框架
基于领域本体的资源反馈检索模型与传统的检索模型的区别和优势在于语义的运用,现在使用一个例子进行说明。例如用户需要搜索关于会计统计方面的Excel函数用法资料,但是又不是很清楚到底是哪个Excel函数,这样在传统的教育资源检索模型中,用户大多只能通过以下方式进行搜索:
(1)通过学科目录查找到计算机类资源的存放目录,然后看着一堆的课程资源目录,猜想资源存放的位置来挨个查看。
(2)使用关键字“会计Excel函数”查询,不能得到检索系统任何的提示而进一步地明确自己的检索内容。
而采取基于领域本体的资源反馈检索模型,则用户无需查找资源的目录分类和学科归属,只需要一步步地根据提示信息进行反馈即可,检索流程如下:
(1)用户输入关键字“会计Excel函数”,则检索系统进行语义扩展,在人机界面给用户展示“会计”类和“统计”类中最常用excel函数如“PV函数”和“Count If函数”等关键字,并给出与这些关键字匹配的资源列表。
(2)用户根据资源列表查询,如果觉得Count If函数更加贴切自己的表达需求,则可以再次输入关键字为“Count If函数”和“统计”,则系统再次进行语义检索,查找统计类函数中所有和“Count If”函数相似度最大的资源,并给用户列出。
由此可以看出,基于领域本体的资源反馈检索模型通过用户反馈的方式,能够利用用户的语义信息进行扩展,从而避免了用户在庞大的资源库大海捞针的茫然搜索。
3 关键技术
3.1 语义检索
语义检索模块是整个模型的核心,重点在于确定查询关键字与资源实例的描述关键字之间的相似度,进而确认该资源是否符合用户的需求。语义检索建立在教育领域本体的基础上,通过对教育领域本体的有效利用,计算查询关键字与资源的描述关键字之间的相似度并进行对比,以满足用户和智能检索系统的需求。
需要注意的是,资源实例的描述关键字要遵循针对性和独立性两个原则,即关键字之间没有明显的包含关系,并且能够正确地描述实例的特点。描述关键字的粒度划分关系到用户对资源实例的搜索,因此资源拥有者正确设置资源实例的描述关键字尤其重要。
定义C={G,Q}描述资源库中的所有资源实例,其中:
描述关键词列表:G=(g1,g2,…,gi),gi为描述资源实例C的第i(4≥i≥1)个关键字。在实际应用中,每个资源实例的描述关键字一般为2至4个就可以很好地描述该资源的特点和内容。
权值列表:Q=(q1,q2,…,qi),qi表示gi关键字在描述资源实例C中的相关度,或是权值,q1+q2+…+qi=1。
同理,定义R={T,Y}描述目标资源实例,其中T={t1,t2,……,tk},Y=(y1,y2,…,yk)(4≥k≥1),tk为目标资源实例的第k个描述关键字,yk为tk的权值,y1+y2…+yk=1。
在人机交互页面,用户可以通过机构分类、学科分类等方式进行初步的资源检索,还可以通过关键字进行查询。使用关键字进行语义匹配检索的流程图如图2所示。
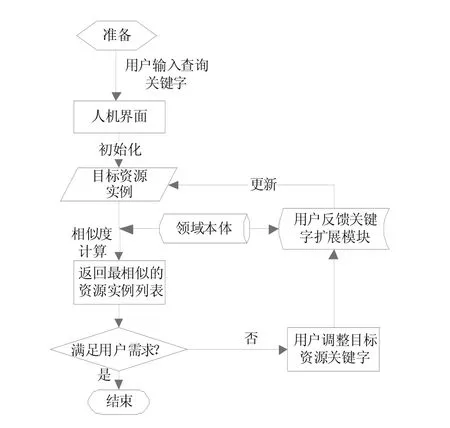
图2 语义匹配检索的流程
以下是语义匹配检索的步骤:
Step1用户在人机交互页面输入一个可以描述目标资源R的属性关键字t,即目标资源R={T,Y},其中T={t},Y={1}。
Step2查找系统中所有的教育资源,计算教育资源与用户需求的相关度,定义Sim(tk,gi)为关键字tk和gi的相似度,根据相似度计算公式[],则可以得到资源实例C和目标实例R的相似度
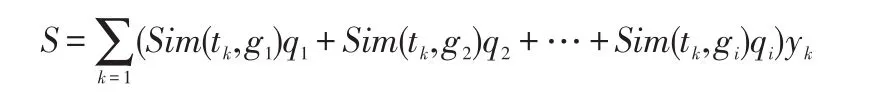
Step3按照相似度S的大小顺序将符合要求的资源实例返回给用户。
Step4检索结果符合预期目标,则用户结束检索,下载需要的资源;否则用户在输入框中重新调整描述关键字为t1,进入用户反馈关键字扩展模块进行处理,检索平台更新目标资源实例R={T',Y'},继续Step2。
本体可以看作是一个有向图,概念是图中的节点,概念间的语义关系是图中的有向边。直觉上,本体上语义关系中蕴含着一定的语义相关度,所以本体上语义相关度的计算应该和有向边上的语义关系联系起来[2]。要计算本体网络中概念之间的相似度Sim(tk,gi),应该利用它们之间的语义关系,综合使用基于结构的概念相似度计算方法和基于属性的概念相似度计算方法[3]。
对于以上两种相似度计算方法都设置一个权值,最终得到一个综合的概念相似度。
3.2 用户反馈关键字扩展
用户再次输入描述目标资源实例的关键字时,反馈关键字扩展模块的任务就是进行语义关系计算,以深层次地挖掘语义内涵,更加贴切地表达用户的需求,从而产生扩展关键字列表和对应的权值列表来进一步描述目标资源实例。
语义关系计算包含了语义等价关系、语义父子关系和语义关联关系,对前后两次描述目标资源实例的关键字t和t1之间的每一种语义关系采取不同的扩展关键字搜索策略,将指定搜索范围内的关键字纳入候选扩展关键字集合W,并对候选扩展关键字集合中的关键字进行概念相似度计算。
提取概念相似度值最大前4个扩展关键字组成最终的扩展关键字列表T'={t'1,t'2,……,t'k},权值列表为Y'={y'1,y'2,…,y'k}(4≥k≥1)。其中,y'k权值按照t'k/∑t'k进行分配,以此来更新目标资源实例R={T',Y'}。
4 结语
资源库的建立是为了能够达到资源共享共建共用,提出的基于本体的资源反馈检索模型采用了领域本体的统一表示方式,多个资源信息平台通过检索模型得到了整合,同时以将用户反馈的关键字进行语义分析后得到概念相似度为依据,进行目标资源描述关键字扩展,从而使得逐步得到检索结果更加贴近用户的需求,实验证明,检索模型的查全率和查准率都有了一定的提高,验证了该检索模型的可靠性。
但是,概念相似度计算是检索模型的核心,相似度计算算法仍需不断地挖掘关键字属性之间的语义关系进行完善,引入自然计算到检索模型中将是下一步的重点工作。
[1]邓志鸿,唐世渭,张铭.Ontology研究综述[J].北京大学学报:自然科学版,2002,38(5):730-738.
[2]田首,杜小勇,李海华.一种基于语义关系计算领域本体中概念间语义相关度的方法关[J].计算机科学,2007,34(10):172-173.
[3]李荣,杨冬,刘磊.基于本体的概念相似度计算方法研究[J].计算机研究和发展,2011,48(增刊):312-317.
[4]Ehring M,Sure Y.Ontology mapping-an integrated approach// LNCS 3053:Proc of the 1st European Semantic Web Symp.Berlin:Springer 2004:76-91.
[5]石林,徐飞,徐守坤.基于用户兴趣建模的个性化推荐[J].计算机应用与软件,2013,30(12):211-214.264.
[6]苏雪阳,左万利,王俊华.基于本体与模式的网络用户兴趣挖掘[J].电子学报,2014,42(8):1556-1563.
[7]Bin Tan,et al.Mining long-lasting exploratory user interests from search history[C].CIKM'12 Proceedings of the19th ACM international conference on Information and knowledge management.New York,USA,2012:1477-1481.
[8]张沪寅,张铭洋,李鑫.基于领域本体的电子学习资源库模型[J].计算机应用,2012,32(1):191-195.
[9]林丽姝,林珍,刘露思.基于本体与粗糙集的教育资源检索模型的关键技术研究[J].实验技术与管理,2012,29(10):123-125.
[10]蒋勇,谭怀亮,李光文.基于量子遗传算法的XML聚类方法[J].计算机应用,2011,31(2):446-449.
Research on Resource Feedback Retrieval Model Based on Ontology
Lin Lishu
(Hainan College of Economics and Business,Haikou 571127,Hainan)
act】Focused on the problems of poor efficiency of the traditional retrieval systems which can not detect semantic information from user's keywords,a resource feedback retrieval model is proposed in this paper.The main idea of the model is to use the technology of ontology construction and semantic annotation and expansion keywords which can use semantic knowledge form user's feedback to meet user's needs.The experimental results show that the retrieval performance can be improved effectively.
domain ontology;resource retrieval;knowledge feedback
TP391
A
1008-6609(2015)03-0031-03
林丽姝,女,海南临高人,硕士,副教授,研究方向:知识工程、创新设计。
海南省教育科学规划课题,项目编号:NO.QJY125048。
