基于时间因子的个性化推荐系统的算法改进
2015-01-16浙江工业职业技术学院
浙江工业职业技术学院 方 杰
基于时间因子的个性化推荐系统的算法改进
浙江工业职业技术学院 方 杰
如何根据用户自身特征准确地向其反馈个性化的推荐,一直是学术界和产业界研究的重点和热点。本文提出了一种新的个性化推荐方法,该方法在计算两个资源相似度时考虑了标签的时间因子,设计了合理的时间衰减函数,并以此对已有的推荐算法进行了改进,并在实际数据集中对改进前后的个性化推荐算法结果进行了对比,最终的结果表明了我们提出的方法具备可行性和优越性。
时间因子;个性化推荐;社会标签系统
0 引言
目前,社会标签已经成为web2.0的主要应用之一,用户可以自由地对网络上各种类型的资源,比如视频、照片等做出个性化的标签。这些标签可以在一定程度上反映用户的兴趣爱好和操作习惯。而个性化推荐系统恰恰是针对用户的特点给予推荐,不同的用户会得到不同的推荐。因此,用户标注的标签在个性化推荐系统中的地位举足轻重,国内外的一些论文对此已经做了较深入的研究,并提出了许多有价值的算法。
目前的个性化推荐系统大多是基于资源、标签和用户的三元关系,并以此设计了多种不同的推荐系统。通常,这些推荐系统都是根据用户对资源的评价情况,来获取用户的特征,从而做出对用户兴趣的判断并反馈推荐。但仅凭资源、标签和用户所设计的个性化推荐系统存在着一定的局限性,因为用户对一个资源的态度和评价通常会随着时间的推移而改变。比如用户几年前对某一地区房价的价格评价是“较低”,而现在的评价是“较高”,其实该用户更关心的是当前的价格;再比如用户对某一部科幻电影几年前的评价是“效果很好”,而随着特技特效的快速发展,该用户对该电影的评价换成了“效果一般”。所以标签能够反映用户的兴趣和特点的变化,而这个变化是由时间的推移而造成的。
受到这一思想的启发,在这篇文章中,我们提出了一个新的个性化推荐方法,把时间因子与标签绑定,在已有的个性化推荐系统的基础上,融入“最新的标签最能反映用户的特征”的想法,从而在一定程度上提高推荐的准确度。
本文的主要贡献有:
(1)提出了个性化推荐系统加入时间因子的思想。
(2)设计了加入时间因子后的推荐系统模型。
(3)使用真实数据集,对所设计的模型进行验证。
本文第二节介绍了相关的基础工作,第三节详细描述了本模型的设计过程,第四节给出了实验的方法和结果,第五节介绍了文章的结论和下一步的工作思路。
1 相关工作
当前的标签系统大多是由用户、标签和资源这三个实体组成,并且这三个实体间互相关联,即用户对资源注释标签,我们把这种关系记为A,那么标签系统可以描述为一个四元组,即存在一个用户集U,标签集T,资源集R,以及对用户来说,一个注释集合A。这样可以用D来表示整个标签系统,并定义。注释集合A定义为一个三元组的集合,其中包含用户,标签,以及资源,即:

个性化推荐系统由标签系统演化而来,秉承“以用户为中心”的原则,重点研究用户兴趣的获取方式和获取效果。在获取了用户兴趣以后,建立用户模型,以方便把用户兴趣和资源对应起来,最后通过该用户模型和资源的匹配,进行个性化的推荐。
基于经典的余弦相似度的算法,Durao和Dolog[1]提出了一个个性化推荐的计算方法,把一些标签的自身因素融入到了算法中,如标签的代表性和标签的流行度等等。此外,他们的文献中还给出了两个资源A和B之间的相似度计算公式:

其中cos_similarity(TA,TB)是根据标记在A和B两个资源上的标签所计算的余弦相似度,而TA={TA1,TA2,TA3……TAn}。DA和DB是资源的评分,其计算方式为:

其中weigh(Tagi)表示标签的权重,与该标签在数据集中出现的次数成正比。而其中的representativness(Tagi)表示标签的典型度,类似与资源检索中的词频概念。
2 基于时间因子的个性化推荐方法
基于时间因子的个性化推荐方法就是在使用标签时考虑到每个标签的时间因子,因此我们提出了如下资源相似度的计算方法:

这与(2)中DA的计算方法有所不同,这样能够防止同一标签出现次数过多而导致该标签在相似度的计算过程中起到过度决定性作用的情况。
而(3)中的cos_similarity(XATA,XBTB)所表示的是带有时间因子的余弦相似度计算方法,其计算方式为:
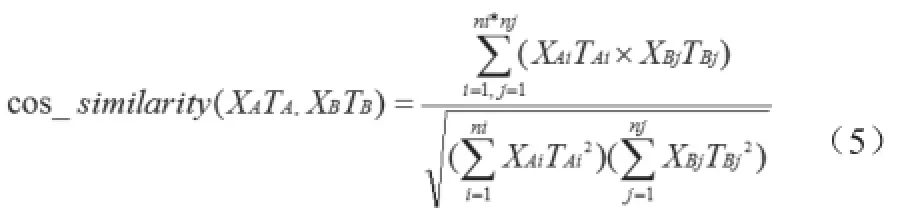
其中XAi的表示所对应标签的时间因子取值。
对于个性化推荐系统中的所有标签,它们之间的标注时间肯定是有差异的。因此,如何合理设计时间因子是我们工作的重点。
遵循“最新的标签最能反映用户的特征”的思想,我们为时间因子X设计了一个衰减函数:
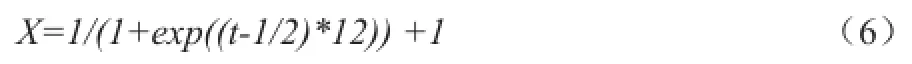
其函数曲线如下:

其中通过函数计算所得的时间因子X的值的范围为[1,2],即函数能把最新的标签所产生的效果翻倍,而最旧的标签的保持不变。t表示一个时间值,其可取值的区间为[0,1]。为此,我们需要把个性化推荐系统中每个标签的时间戳si对应到t的[0,1]区间中,数据中最新的时间戳记为s0,对应到[0,1]区间中的0;而最旧的时间戳记为sn对应到1。则系统中的某一时间戳si对应到[0,1]区间中的值ti的计算方法为:

下面的例子能直观的说明该方法的效果:

上面的例子描述了三部电影之间的关系,它们分别为《木乃伊》、《木乃伊归来》和《加勒比海盗:黑珍珠的诅咒》。前两部电影有3个相同的标签:“John Hannah”、“egypt”和“mummy”,而后两部的电影有4个相同的标签:“sequel”、“action”、“adventure”和“comedy”。按照改进前的方法,《木乃伊归来》和《加勒比海盗:黑珍珠的诅咒》的相似度比《木乃伊》和《木乃伊归来》的相似度要高。而加入时间因子改进以后,《木乃伊》和《木乃伊归来》的相似度则相对更高,符合它们是同一系列更相似的常理。
3 实验
为了验证本论文提出的方法,我们用Movielens数据展开实验。MovieLens是历史最悠久的推荐系统。它由美国Minnesota大学计算机科学与工程学院的GroupLens项目组创办,是一个非商业性质的、以研究为目的的实验性站点。MovieLens主要使用Collaborative Filtering和Association Rules相结合的技术,向用户推荐他们感兴趣的电影。Movielens数据集中的每一个标签均带有时间戳,为我们的研究提供了条件。
MovieLens数据集包含有10000054个评分,10681部电影,以及71567个用户对这些电影的所做的95580个标签。由于标签是用户凭自己的喜好所标注,因此对标签的研究存在着很多的局限性,比如用户拼写的错误、多义词等都会对实验带来噪音。因此我们必须通过适当的过滤来提高标签的有效性,提高数据的质量。这里,定义了两个过滤条件,以提高实验中数据的质量。首先,只考虑标签数量至少有15个的电影,其次,只有至少对10部电影做过评价的用户才会认为是有效的用户。按照这样的条件,最终采用的数据的统计信息如表四所示,即有3390部电影,1151个用户,以及他们所做出的2645个标签,如表2所示。

表1 实验数据集统计
在通过我们提出的方法计算完所有电影之间的相似度以后,便采用信息检索领域的标准度量来评价本文所提出的方法。把数据集分成训练集和验证集两部分,对每一个用户,我们选取了带有时间因子的相似度的最高的N部电影作为推荐。然后与该用户数据集中的电影做对比,来计算推荐的精度。在我们的实验中,N的取值为5。
基于以上的方法,我们对两种方法进行了对比:

表2 两种方法的整体精度
其中 TBR-CS是通过简单余弦相似度的计算方法:
Similarity(A,B)=(DA+DB)*cos_similarity(TA,TB)。
TBR-TF是基于时间因子的相似度计算方法:
Similarity(A,B)=(DA+DB)*cos_similarity(XATA,XBTB)。
4 结论
实验比较了两种方法下,个性化推荐系统的推荐准确度。
从实验的结果来看基于时间因子的个性化推荐方法有一定的优越性。在今后的工作中,我们将进一步改进时间衰减函数,并考虑更多的影响因素,采用更先进的方法来展开研究。
[1]F.DuraoandDolog,Apersonalizedtag-basedrecommendationin socialwe systems,WorkshoponAdaptationandPersonalizationforWeb2.0,UMAP,09,2009.
[2]F.GedikliandD.Jannach,Ratingitemsbyratingtags,RecSys,10,2010.
[3]S.Zhao,N.Du,A.Nauerz,X.Zhang,Q.Yuan,andR.Fu,Improvedrec ommendationbasedoncollaborativetaggingbehaviors,IUI,08,2008.
[4]A.Shepitsen,J.Gemmell,B.Mobasher,andR.Burke,Personalize drecommendationinsocialtaggingsystemsusinghierarchicalclustering,R ecSys’08,2008.
[5]G.Xu,Y.Gu,P.Dolog,Y.Zhang,andM.Kitsuregawa,SemRec: ASemanticEnhancementFrameworkforTagbasedRecommendation,A AAI’11,2011.
[6]C.Leung,S.Chan,F.Chung,andG.Ngai,Aprobabilisticratinginferencefra meworkformininguserpreferencesfromreviews,www’11,2011.
[7]J.Wiebe,T.Wilson,R.Bruce,M.Bell,andMMartin,Learningsubj ectivelanguage,Comput.Linguist.,Vol.30,pp.277–308,2004.
[8]C.Whitelaw,N.Garg,andS.Argamon,Usingappraisalgroupsfors entimentanalysis,CIKM’05,pp.625–631,2005.
[9]J.KampsandM.Marx,Wordswithattitude,InProc.oftheFirstInte rnationalConferenceonGlobalWordNet,pp.332–341,2002.
[10]B.Pang,L.Lee,andS.Vaithyanathan,Thumbsup?sentimentclass ifcationusingmachinelearningtechniques,InEMNLP,2002.
[11]B.Liu,M.Hu,andJ.Cheng,Opinionobserver:analyzingandcom paringopinionsontheweb,InWWW,pp.342–351,2005.
[12]C.Scaffidi,K.Bierhoff,E.Chang,M.Felker,H.Ng,andC.Jin,RedOpal:product-featurescoringfromreviews,Proceedingsofthe8thAC MconferenceonElectroniccommerce,2007.
[13]L.Zhuang,F.Jing,andX.Zhu.Moviereviewminingandsummar ization,,InProceedingsofthe15thACMinternationalconferenceonInfor mationandknowledgemanagement,pp.43-50,2006.
[14]P.Heymann,D.Ramage,andH.Molina,Socialtagprediction, InSung-HyonMyaeng,DouglasW.Oard,FabrizioSebastiani,Tat-SengChua, andMun-KewLeong,editors,SIGIR,pp.531–538,2008.
