为了应用而阅读
2015-01-14冯善亮
冯善亮

PISA阅读素养测评框架自PISA2000提出之后一直在调整,尤其是PISA2009增设作为可选项的电子阅读(electronic reading)1 测评后,对测评框架的基本要素更是作了较大调整。本文拟根据经合组织官方网站公布的《PISA2012评估和分析框架》和《PISA2015框架草案》来介绍PISA阅读素养测评框架,希望能让读者掌握最新信息。
一、PISA阅读素养的界定——测评框架的基点
在PISA中,“素养”(1iteracy)是指学生应用学校教育和生活环境中获得的知识和技能对实际生活中遇到的现象进行分析、推理并有效沟通以及在各种情境中解释和解决问题的能力。因此,PISA更多从日常生活中的现象出发,关注学生如何运用知识技能应对现实的挑战,以评估学生掌握与他们将来生活有关的基本知识和技能的程度。
遵循这一基本理念,PISA阅读素养的定义侧重于阅读的应用性。PISA2012和PISA2015沿用了PISA2009 对“阅读素养”的定义:“阅读是理解、运用、反思并积极参与阅读书面篇章,以增进知识,发挥潜能,参与社会,实现个人的目标。”2 这里包含了三层含义:一、阅读的对象是“书面篇章”;二、阅读不仅仅要“理解”,更要“运用、反思并积极参与”;三、阅读的目的或功能不仅在“增进知识,发挥潜能”,更在于“参与社会,实现个人的目标”。这三层含义实际上直接呼应着PISA阅读素养测评框架中的三个基本维度(详见下文)。可以说,这其中的核心定位就是要为了应用而阅读,做到“读以致用”。这一定位,确立了整个阅读素养测评框架的基点。
与PISA2000阅读素养的定义相比较,PISA2009阅读素养的定义加入了“积极参与”的元素。这一元素突出阅读中读者情感和行为两方面特征,包括阅读的兴趣、愉悦感,自控读物,参与社会阅读,进行多样化、经常性的阅读等。学生“积极参与”的阅读具有主动、愉快、多样、持久的特点。
传统意义上对阅读素养的认识偏向于认知角度, 认为阅读能力是解码、理解书面文字的能力。而PISA认为,阅读素养不仅是阅读的认知能力, 更要培养良好的阅读态度, 并通过经常性、多样化的阅读方可形成。这种理念就将人们对培养学生阅读能力的关注引向学生非认知因素及教育环境方面,进一步扩大了人们对阅读素养的认识。3
二、PISA阅读素养的三个维度——测评框架的内容
基于上述对阅读素养的定义,PISA从阅读的情境(situation)、文本(text)、层级(aspect)4等三个维度来设计测评框架。这三个维度实质上分别指向三个问题:为什么阅读;阅读什么;如何阅读。
(一)阅读情境——为什么阅读
阅读总是在某种场合、为了某种意图而发生的,读者总是在某一特定情境中进行阅读活动。PISA将阅读情境分为以下四类:
1. 个人的(Personal)。即为了个人用途而阅读(reading for private use),为了保持或发展与他人的联系,或满足个人的兴趣需要而阅读。内容一般包括个人信件、小说、传记以及为满足好奇心而阅读的信息性材料。这种阅读是休闲、娱乐活动的一部分。
2. 公共的(Public)。即为了公共用途而阅读(reading for public use),为了满足个体参与更大范围社会活动的需要而阅读。内容一般包括官方的文件和关于公共事务的信息等,如通知、布告、规章、计划、方案、小册子、表格等。
3. 教育的(Educational)。即为了教育而阅读(reading for education),通常是为了获取知识而阅读,是更大范围的学习任务的一部分。这里的阅读材料通常不是由阅读者自己选择的,往往是由教师为了教学的需要而选择、指定、设计的,包括课本、地图、纲要等。
4. 职业的(Occupational)。即为了工作而阅读(reading for work),为了满足工作的需要而阅读,利用阅读的技能来完成实际的工作任务。阅读的材料一般包括说明书、手册、计划表、报告、备忘录、项目表等。
(二)阅读文本——阅读什么
阅读的文本,可以从不同的角度进行分类。PISA2009开始,PISA从文本媒介(medium)、文本环境(environment)、文本形式(format)、文本类型(type)四个角度对阅读文本进行分类。
1. 从文本媒介角度,把文本分成印刷文本(print text)和数码文本(digital text)两大类:
印刷文本通常出现在纸上,如单张、小册子、杂志和书籍。印刷文本是一个有明确边界的固定文本, 在本质上是静态的存在,其内容、外显形状、规格和边界都是固定不变的,读者一般来说是按照确定顺序进行阅读。
数码文本一般被定义为显示在电子设备上的文本。在PISA测试中,数码文本就是超文本,一种具有导航功能的可以(甚至是要求)按照非线性阅读的文本。其内容是动态的、可扩展的,边界是模糊的,存在是复合、多重的,阅读是自主的、可交互的。每一个读者可以通过自主选择链接来阅读,从而建构一个属于读者个人的独特文本。
PISA阅读素养测评开始尝试增加数码文本阅读测试,作为一个可选做的内容。不过,根据《PISA2015框架草案》,PISA2015阅读素养评估会使用计算机进行测试,但只是采用印刷文本,不涉及数码阅读。
2. 从文本环境角度,把数码文本分成写定文本(authored text)、基于信息文本(message-based text)和混合文本(mixed text)三种。这是PISA2009增加数码阅读后针对数码文本而进行的分类:
写定文本,是不受读者影响的受控文本,内容是固定的,是在相对孤立的网络环境中由商业公司、政府部门、组织机构或个人控制或出版。使用这些网站的读者主要是获取信息。如网站主页、网站宣传资料或广告、政府信息网站、为学生提供资料的教育网站、新闻网站和在线图书馆目录等。
基于信息文本是指材料主要由参与其中的人提供的,这些人既是材料的提供者,又是材料的读者。如博客、微信、论坛跟帖等。
混合文本,则是上述两者兼而有之,其中一部分材料是受控制的,读者没有改变的权限,但另一部分材料是由读者主动提供的。
(3)从文本形式的角度,把阅读文本分成四种类型:
连续文本(continuous text)。其特点是由句子构成,句子组成段落,段落又可组成更大的结构,如篇、章、书等。
非连续文本(non-continuous text)。非连续文本与连续文本的组织结构不同,依据格式可分为表格、目录、设计图、地图、曲线图、广告等。
混合文本(mixed text)。由若干连续文本段落和非连续文本构成的单篇文本。如带有图表的调查报告、配上插图的小说等。
多重文本(multiple text)。由几篇相对独立的文本构成,这些文本可以是连续文本,也可以是非连续文本,文本与文本之间的关系比较松散或不明显,甚至可以互相矛盾。如报刊杂志围绕一个话题编的专辑等,例如围绕一本图书的包括简介和书评的一组文本。
4. 从文本类型的角度,把文本分为六类:
描述(description),涉及对象的空间特性,一般回答“什么(what)”的问题,如游记中对一个地方的描述、地图等。
叙述(narration),涉及对象的时间特性,一般回答“何时(when)”的问题,如小说、故事、新闻报道等。
说明(exposition),把信息作为综合概念或心理结构呈现出来,一般回答“如何(how)”的问题,如学术论文、统计图、概念图等。
议论(argumentation),介绍概念或命题之间的关系,一般回答“为什么(why)”的问题,如时事评论、在线论坛跟帖、书评等。
指示(instruction),为完成一项任务而对某些行为提供指导,告知“做什么”,如消防指示图、操作指南等。
交流(transaction),用与读者互动的方式交换信息,如分享信息的个人信件、安排会议的文本信息等。
(三)阅读层级——如何阅读
PISA阅读素养测评中,对受测者在阅读过程中处理文本信息的行为和任务进行了分析,将其界定为五个层级:检索信息、形成整体理解、解释文本、反思和评价文本内容、反思和评价文本形式。这五个阅读层级实际上是在真实社会生活中进行阅读常常需要完成的由低级到高级的几类任务。为了便于分析测评结果,这五个阅读层级被归纳、集约成三个层级:访问与检索(检索信息)、整合与解释 (解释文本、形成整体理解)、反思与评价(反思与评价文本的内容、反思和评价文本的形式)。(如下图)
1. 访问和检索。就是要在文本中锁定相应的位置,以检索出一个或多个的信息。比如从招工广告中找到待聘岗位的有关条件;从酒店须知中弄明白拨打国际电话的步骤;从资料中找出有关事实来支持或反驳索赔的人。
2. 整合和解释。主要涉及所阅读文本内部的信息。整合重在形成关于文本的连贯性理解,要把文本的各种信息联系起来,识别信息之间的异同,比较其中的程度差别,明白其中的因果关系,以形成一个新的意义。解释则是指把文本中没有表明的意义阐释清楚,识别文本整体或部分中潜在的假设,明白言外之意。
“整合和解释”要形成理解,这要求读者深化自己对文本粗略的初始印象,形成更深刻、更具体、更完整的理解。整合的任务包括从文本中确定和列出支撑事实或观点的证据,把相关联的两个或更多的信息进行比较。为此,读者必须从一个或多个来源的或隐或显的信息中推断出其中隐含的联系。解释的任务涉及到根据上下文语境进行推理,例如解释一个词或短语在文本中的细微的、特别的意思。当然,这其中也包括要求学生对作者意图进行推断并确定推断意图的根据。
3. 反思和评价。主要是在阅读中利用文本之外的知识、观点、态度来思考,对文本提供的信息和自己的感受、观点进行研究。“反思”是要求读者参照自己的经验或知识对文本进行比较、对比,“评估”则是让读者超越文本,作出判断。
“反思和评价文本内容”,要求读者把来源于文本外部的知识与文本的信息连接起来。读者必须评估文本对自己关于世界的知识提出的挑战,往往被要求表达并捍卫自己的观点。为此,读者首先必须能够了解所读的文本究竟是在说什么;其次,他们必须会辨别——自己观点是不是源于自己以前就知道的或是在其他文本中获得的信息。读者必须使用一般或具体的知识以及抽象思维能力,来比较源于所读文本的信息和其他来源的信息,从而找出支持自己观点的证据。
“反思和评价文本形式”,要求读者跳出文本,客观地思考并恰如其分地评价文本形式的好坏。在完成这类任务时,关于文本结构、各类文本的典型风格等方面的潜在知识发挥着重要作用。当然,要评价作者是如何成功地写出特色或说服读者,这不仅仅取决于上面述说的具体知识,也取决于读者对于语言细微区别的洞察能力。
在数码文本阅读中,“评价”的重点可能稍有不同。数码文本格式(视窗、菜单、超链接等)的同质性使得各类数码文本的区别越来越模糊。数码文本的这类新特性要求读者更加关注信息提供者的身份以及信息的准确性、可信度和质量。鉴于在网络环境中人们可利用的信息是海量的,批判性的评价便显得越来越重要。
在某种程度上,读者每次做出一个重要判断都需要依赖自己的经验;另一方面,某些种类的反思,却不需要评估的参与(例如把自己的亲身经历和所读文本中的某些描述作比较)。从这个角度看,评价可以被视为反思的一个部分。
上面分别阐述的三个阅读层级实际上是相互关联和相互依存的,不能被认为是各自完全独立的。要完成任何一个印刷文本或数码文本的阅读任务,都不可能只是单纯运用一个层级的阅读技能。
三、PISA阅读素养试题分布——测评框架的量化
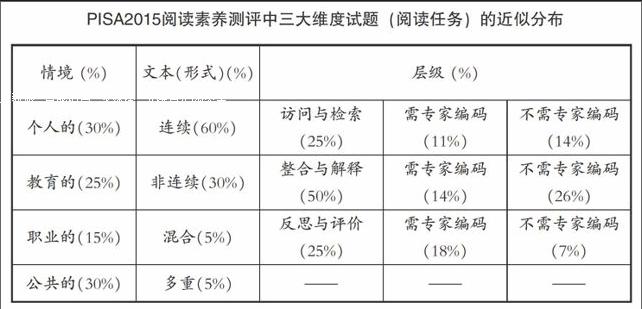
PISA阅读素养测评根据上述的三大维度来命制阅读试题。每一次的PISA测评框架文件都规定了试题(阅读任务)的近似分布,历次的比例略有调整,最终试题也会稍有不同。2013年颁布的《PISA2015框架草案》规定了PISA2015阅读素养测评中三大维度试题(阅读任务)的近似分布,具体见下表。
表中按阅读层级分布的试题又按照试题的评分是否需要专家编码再次分为两类。PISA阅卷过程是对学生作答的试题本进行编码而不是直接评分,阅卷者给出的不是实际分数而是代码,实际的分数要等数据库提交后再统一核算。PISA阅读试题有五种题型:单项选择题、多项选择题、封闭式问答题、简答题、开放式问答题。单项选择题、多项选择题可直接输入计算机统计,不需专家编码。简答题、开放式问答题需要专家编码,才能直接输入计算机统计。封闭式问答题的答案是确定的,用数字或简短的文字来回答,部分不需要专家编码,部分需要专家判断对错后进行编码。
注:
1. “电子阅读(electronic reading)”在PISA2012文件中改为“数码阅读(digital reading)”,故下文采用最新提法。
2. OECD :PISA 2009 ASSESSMENT FRAMEWORK——KEY COMPETENCIES IN READING, MATHEMATICS AND SCIENCE,第23页。
3. 廖先、祝新华《从国际阅读评估项目的最近发展探讨阅读评估策略》,《全球教育展望》2012年第12期,第54页。
4. PISA 文件中的原文“aspects”,当前国内一般直译为“方面”,让人不易理解。笔者根据其实质内容,借用国内语文教学中阅读能力评价中的常用术语,意译为“层级”。
