基于目标匹配的道路网增量信息的识别和提取
2015-01-11丁宇虹
丁宇虹
(山西省交通科学研究院,山西 太原 030006)
随着我国城市建设速度的加快,道路新建、改建、扩建等情况时有发生,现在电子地图更新的速度远远满足不了用户需求。如何使变化及时准确地反映到电子地图数据中,成为制约电子地图发展应用的一个难题[1]。
传统的地图数据更新方法数据重复加载,效率低。地图测绘工作的重心已经从数据生产转变为数据更新,如何利用已有的工作成果和数据快速准确地更新电子地图,减少地图更新中的重复劳动,提高地图数据更新的效率,是目前研究的一个重要方向。不同时刻道路数据更新主要是提取增量信息,提取方法会直接影响道路网数据更新的准确率和效率。本文采用基于目标匹配的方法结合语义匹配来识别和提取同比例尺道路网数据的增量信息。
1 目标匹配方法
本文的增量信息是同一区域范围内的同比例尺不同时刻道路网的变化信息,其识别和提取其实是一个目标匹配的过程。语义匹配主要是通过道路属性信息来判断匹配,完成匹配的道路不用再进行目标匹配。目标匹配是通过缓冲区面积迭置率和最大类间方差法实现,这里的重点是面积迭置率阈值的确定。通过语义匹配和目标匹配二者结合实现导航道路网增量信息识别和提取。
由于数据属性信息并不完全一致,语义匹配只能完成一部分道路的匹配,还有很大一部分道路还需要进行增量信息提取。对于这部分数据通过面积迭置率和最大类间方差法相结合来处理。此处面积迭置率定义为2个道路缓冲区的相互重叠部分的面积占各自总面积的比值[2],是通过对2条道路线要素根据试验情况建立一定宽度的缓冲区,对两者的缓冲区进行计算。
首先定义面积迭置率指标。假设Ai和Bi是2个待匹配线实体的面状缓冲区,Sim(Ai,Bi)和Sim(Bi,Ai)是各自的面积迭置率。则:

Sim(Ai,Bi)和Sim(Bi,Ai)中必须至少有一个大于某个阈值(0.3),才说明两者有匹配的可能;且当Sim(Ai,Bi)接近于1的时候,说明Ai是整体和Bi匹配的;对于Bi也是这样;当Sim(Ai,Bi)和Sim(Bi,Ai)都同时接近1的时候,说明Ai和Bi是1∶1匹配的。
2 基于类间方差的阈值计算
图像分割就是指把图像分成具有特殊含义的区域,并提取出感兴趣的目标的过程,本文采取的方法是基于阈值计算的图像分割方法。阈值计算方法本文采用最大类间方差阈值法,是由Ostu提出的。Ostu法的图像模型是:把图像分为目标和背景两类,处于目标和背景交接处两边的像素灰度值有较大的差别,它的灰度直方图可以看成是由对应目标和背景的2个单峰的直方图混合构成。如果这2个分布大小相隔很近且均值相距足够远,而且2个部分的均方差也足够小,则直方图表现为较明显的双峰,如图1,这类图像适用最大类间阈值法[3]。用类间方差阈值法来进行图像分割可以使图像错分概率最小。Ostu法的不足是当目标与背景灰度差不明显时,分割得到的图像误差较大,甚至会丢失整幅图像的信息[4]。利用最大类间方差法,使2个数据集的差异达到最大的值便是最佳阈值。

图1 迭置率灰度直方图(适用Ostu方法)
3 实验验证
为了验证上述的方法是否可行,采用ESRI公司的ArcGIS Engine SDK和Visual Studio.NET 2008开发工具进行验证。本文研究的数据源为北京房山区2007和2010年的1∶10 000道路矢量数据。将2010年和2007年道路矢量数据进行叠加分析后得到这2年道路数据的交集数据表,在进行目标识别和提取前可以根据计算的阈值把小于阈值的从交集数据表中删除。
3.1 面积叠置率计算阈值
下面用面积迭置率的方法对本文的数据进行分析。在进行匹配前,先要对2年的数据建立缓冲区,缓冲区的大小与比例尺有关。通常选为对应比例尺最小许可间隔距离的2倍[5]。因此此处设定的缓冲区宽度为D=10 000×0.2 mm×2=4 m。
在ARCGIS9.3中生成缓冲区的叠加分析图层,在新图层的属性表中会自动生成两列数据,记录每个要素对应的2007年和2010年道路要素ID,如表1。其中第一列为系统ID,第二、三列为2007、2010道路要素ID,第四列“Have07”代表相交面积Area(07∩10)/Area(07),第五列“Have10”代表相交面积Area(07∩10)/Area(10)。对这些数据根据面积迭置的计算方法进行处理,分别得到2007的迭置率集合和2010年的迭置集合:
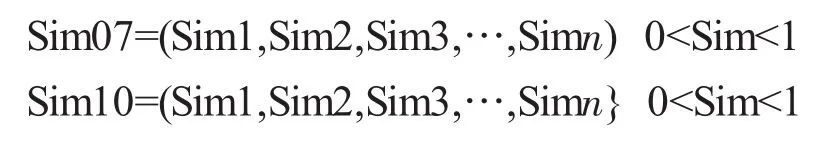

表1 道路网缓冲区叠加分析属性数据
对2个集合分别按大小排序后生成它们相关的折线图如图3所示。
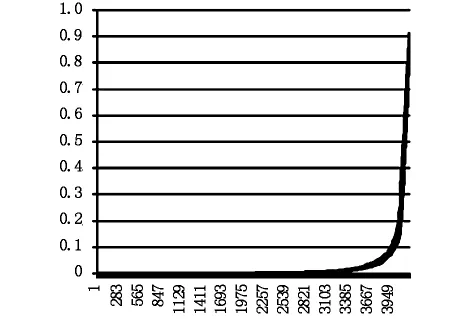
图2 迭置率统计图
图2中纵坐标代表面积迭置率,横坐标代表重新排序后的自动生成的序号。从图2中可以看出这2年的面积迭置率基本重合,2个的面积迭置率介于0~0.9之间,其中在折线拐点左侧0~0.2之间的元素占了很大的比例,但并不能确定阈值的大小。为了进一步找出数据的分布规律,在Matlab中做出数据的灰度直方图,如图3所示。
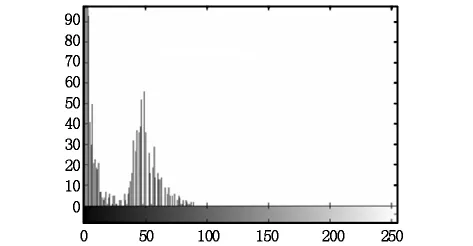
图3 迭置率灰度直方图
图3中横坐标表示面积迭置率,纵坐标表示面积迭置率的某个值的要素个数,可以看出数据呈明显的双峰分布,在25处出现了一个较明显的峰谷。为了分析数据这种分布的原因,把值域分为(0~5)、(5~30)、(30~100)3 组来进行抽样分析,每个样本个数为30。发现值域为(0~5)的要素主要是多条相交线段结点缓冲区重合引起的叠加分析误差导致,值域在(5~30)的要素主要是由于地图数据误差造成。值域30以上的要素是2条线要素存在匹配关系形成的。由此可知整个数据集大致有两类:一类为非匹配关系产生的冗余非匹配数据,另一类是由匹配关系产生的有效匹配数据。接下来用最大类间方差法来计算图像的最佳阈值,把图像进行分割。
3.2 最大类间方差法计算阈值
用最大类间方差法得到2007年匹配阈值是29,2010年的是30,2个值非常接近。如果选择30为最佳匹配阈值,删除的数据要比阈值是29时要多,为了避免个别匹配的数据被删除,这里选取29为最佳匹配阈值,即2条道路的面积迭置率达到29%,认为这2条道路是匹配的。
为了确定29是最佳的匹配阈值,本文选取了不同阈值统计了不同阈值的匹配准确率,如表2所示。不同阈值抽样统计的道路个数不同,实验阈值取10、20、29、40、50,对应的抽样道路个数依次为 155、191、237、207、150。通过人工匹配数和阈值匹配数计算匹配的准确率,判断29是否为最佳阈值。从表2可以发现,当实验阈值较小时,阈值匹配的道路个数要略比人工匹配的道路个数大,这是因为阈值较小时被选取的道路要相对多一些;当实验阈值较大时则反之。阈值大小会影响匹配的准确率,发现阈值取29时,匹配准确率最高。试验发现通过面积叠置率和最大类间方差计算的阈值对同比例尺电子地图道路数据增量信息进行识别和提取的效果比较好。

表2 不同阈值匹配精度
4 结语
本文通过对目标匹配提取增量信息,发现面积叠置率结合最大类间方差的方法有很好的数据针对性,提取的效果比较好,且算法简单容易实现。但该方法在实际应用中还存在不完善的地方有待改进。如当数据没有明显差异,在数据直方图上没有单峰出现,计算得到的匹配阈值匹配效果不能满足要求,在下一步的工作中对该方法进行改进,提高该方法的通用性。
