一种改进的基于大数据集的混合聚类算法*
2015-01-09张晓,王红
张 晓,王 红
(1.山东师范大学信息科学与工程学院,山东 济南 250014;2.山东省分布式计算机软件重点实验室,山东 济南 250014)
一种改进的基于大数据集的混合聚类算法*
张 晓,王 红
(1.山东师范大学信息科学与工程学院,山东 济南 250014;2.山东省分布式计算机软件重点实验室,山东 济南 250014)
针对k-means算法过度依赖初始聚类中心、收敛速度慢等局限性及其在处理海量数据时存在的内存不足问题,提出一种新的针对大数据集的混合聚类算法super-k-means,将改进的基于超网络的高维数据聚类算法与k-means相结合,并经过MapReduce并行化后部署在Hadoop集群上运行。实验表明,该算法不仅在收敛性以及聚类精度两方面得到优化,其加速比和扩展性也有了大幅度的改善。
k-means;超网络;频繁项集;超图划分;MapReduce
1 引言
大数据聚类是当前聚类研究的重点。在海量数据的聚类中,现有的聚类算法在时间复杂性和空间复杂性上都存在一定的局限,解决这个问题的一种途径就是引用并行处理技术,设计出高效的并行聚类算法,来提高算法性能。目前,MapReduce是最主流且实用的并行化模型。
k-means算法是传统的经典聚类算法,但是该算法对初始值具有很强的依赖性[1],即算法的鲁棒性不高。此外,k-means算法在串行计算方法中的时间复杂度比较高,处理能力难以满足需求。目前,对与k-means算法相结合的混合聚类算法及其并行化方面已经取得了较为理想的研究成果。赖玉霞等人[2]提出的一种优化的基于密度的算法有效地解决了k-means算法过度依赖初始值的问题。田森平等人[3]提出了自动获取最佳k值的算法。毕晓君等人[4]提出一种结合人工蜂群和k-均值的混合聚类算法,使得聚类效果有了明显改善。Fagin R等人[5]提出了一种结合遗传算法和k-means的混合聚类方法,该方法能有效地解决k-means过于依赖初始值的瓶颈问题,但是串行依然会增加算法运行的时间复杂度。Ngazimbi M等人[6]利用Apache Hadoop MapReduce框架实现了k-means、Greedy Agglomerative和Expectation Maximization聚类算法。
针对k-means聚类算法应用在大数据集上的不足,本文提出一种新的针对大数据集的混合聚类算法super-k-means,首先,将高维数据映射到一个大规模带权超网络中;其次,定义超网络中边的权重;再次,采用优化的超图划分方法划分带权超网络;最后,将得到的k个划分作为k-means算法的k个初始聚类中心,通过MapReduce并行化后部署在Hadoop集群上运行。这样既能有效地过滤掉聚类中的噪声数据,又克服了传统k-means算法稳定性差的缺点。实验表明,本文提出的算法super-k-means行之有效。
2 相关工作
2.1 k-means算法的基本原理
k-means算法是1967年由MacQueen首次提出的一种经典算法, K-means算法的处理流程[7]如下:
(1)在所有的n个数据点中随机选取k个点作为初始簇中心;
(2)将k个选择点之外的每个数据点,根据它们与k个初始簇中心的相似度(欧氏距离),分别分配到与其最相似的(欧氏距离最小)簇;
(3)重新计算得出新聚类的中心对象(均值);
(4)迭代该过程至聚类质量检测函数收敛。
k-means聚类算法的伪代码如下所示:
算法k-means
输入:数据集D,划分簇的个数k;
输出:k个簇的集合。
(1)Initially choosekpoints that are likely to be in different clusters;
(2)Make these points the centroids of their clusters;
(3)FOR each remaining pointpDO
(4) find the centroid to whichpis closest;
(5) Addpto the cluster of that centroid;
(6) Adjust the centroid of that cluster to account forp;
(7)END;
k-means算法通常使用误差平方和SSE(Sum of Squared Error)[7]来检测聚类质量。其形式化的定义如下所示:
(1)
其中,d()表示两个对象之间的距离(通常采用欧氏距离)。k值相同时,SSE越小说明簇內对象越集中,对于不同的k值,k值越大对应的SSE值越小。
2.2 基于超网络的数据聚类算法流程
对于大规模的高维数据,由于维度灾难的影响,若采用传统的基于降维的算法进行聚类,会出现的一个共同问题是损失一部分有用的信息,而这会影响聚类结果。利用超网络方法进行高维数据聚类,能有效过滤掉聚类中的噪声数据,保证数据聚类的质量。超网络的拓扑结构即超图。
一个超图[8]:
H=(V,E)
(2)
由一个顶点集(V)和一个边集(E)构成。权重超图就是带权图的扩充,超边可以连接多于两个以上的顶点。在这类图模型中,顶点集V表示将要聚类的数据类的集,而每个超边e∈E连着相关类的集。
聚类实现步骤如下:
步骤1使用经典的 Apriori 算法挖掘出所有频繁的超边,即找出所有支持度大于设定的最小阈值的超边。对每条超边,找到其频繁项集中包含的支持度和置信度分别满足最小阈值的关联规则,从而计算每条超边的权重。这里将采用支持度与置信度的乘积作为权重。
步骤2通常采用的超图分割算法是hMETIS。其基本思想:将建立的超图模型通过粗化、初始划分、迁移优化三个阶段寻找权重最小的边并将它切割,不断反复直到得到k个有效划分。hMETIS能在几分钟内在包含超过100 000个点的大规模线路中找到非常好的划分。特别对k方式划分来说,hMETIS的复杂性是O((|V|+|E|)lgk),其中|V|是顶点数,|E|是边数。
步骤3由上个步骤得到k个簇,然后通过评价函数来确定符合要求的聚类结果。

Figure 1 Basic flowchart of the algorithm
2.3 改进的两阶段混合聚类算法
本文提出的这种聚类算法super-k-means,先通过第一阶段的超图聚类得到k个簇,作为第二阶段k-means聚类算法的k个初始中心进行聚类,通过两阶段的混合聚类既克服了k-means算法过度依赖初始聚类中心、稳定性差的缺点,又汲取了超图模型适用于大规模的高维数据聚类的优点。同时,基于Hadoop平台的并行化处理也大大缩短了程序的运行时间。该算法的主要流程如图2所示。
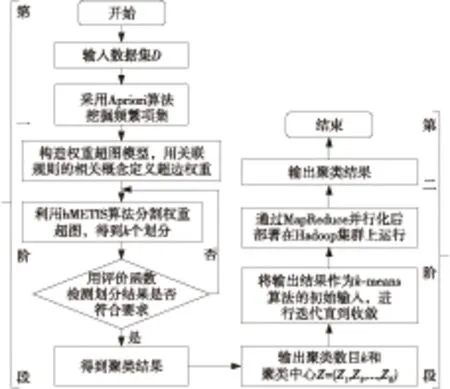
Figure 2 Flowchart of the super-k-means algorithm
3 super-k-means算法的MapReduce并行化实现
由上述super-k-means的实现流程可见串行实现算法的时间复杂度比较高,与O(super-k-means)、N(数据记录总个数)、N(期望得到的聚类的个数)、N(算法迭代次数)、T(计算待分配的数据到中心点距离)等变量之间存在线性关系。如果要将M个数据对象聚成N个簇,那么在一次迭代中就需要完成MN次记录到中心点的距离的计算操作,虽然这类计算操作最耗时,但也最容易并行处理:各个记录与k个聚类中心的距离进行比较的操作可以同时进行。
从k-means算法流程中可以看出,主要的计算工作是将每个数据对象分配到跟其相似度最高(距离最近)的簇,并且该操作是相互独立的,所以在每次MapReduce job中,这一步骤super-k-means算法可以通过分别执行相同的Map和Reduce操作得到并行处理。
3.1 MapReduce模型
MapReduce编程模型[9]的基本思路:Hadoop MapReduce是当前最主流的分布式计算框架,基于该框架的应用程序能够运行在由数台普通计算机组成的大型集群上,并能容错地并行处理大规模数据。MapReduce框架运行在〈key,value〉上,Map是把原始输入数据分解成一组中间的〈key,value〉对,Reduce把结果合成最终输出。
这样一项包含若干项任务(Task)的工作在MapReduce中被称为作业(Job)。任务又包含若干map任务和若干reduce任务,先由map任务并行地处理这些〈key,value〉键值对,然后MapReduce框架会将map的输出结果进行一系列复制、分组、排序等处理之后输出给reduce任务。
Map函数和Reduce函数[10]是由程序员提供的, map和reduce任务分布在集群节点上运行,并把结果存储在分布式文件系统上。整个MapReduce对任务进行调度和监控,以及重新执行失败的任务。MapReduce框架是由一个主JobTracker和分布在每个集群节点的一个个从属的TaskTracker组成。如图3所示。

Figure 3 MapReduce job schematic
3.2 Map函数和Reduce函数的设计
Map函数:计算各个数据对象到中心点的距离并对该数据属于的新类别重新标记。将所有数据对象和上一轮Job的聚类中心作为Map函数的输入,输入数据键值对形式为〈row number,record number〉;按照读入的簇中心记录文件,Map函数计算出到每个输入数据记录距离最近的簇中心,并作出新的标记;输出中间结果键值对的形式为〈cluster category ID,records attribute vector〉。
Reduce函数:通过Map函数得到的结果计算出新的聚类中心,供下一轮Job使用。输入数据键值对的形式为〈cluster category ID,{record attribute vector set}〉所有key相同的记录送给同一个Reduce,累加key相同的点个数和各记录分量并求出各分量的均值,并生成新的簇中心记录;输出结果键值对的形式为〈cluster category ID,mean vector〉。
Job结束之后,计算该轮新的聚类中心偏离误差并进行判断。如果小于给定的阈值则算法结束;反之,用新的簇中心记录文件覆盖上一轮的文件,并启动新Job。
super-k-means算法在MapReduce框架下的运行流程及算法伪代码如下所示。

Figure 4 Super-k-means parallel implementation based on MapReduce
算法伪代码如下:
Job:计算新的聚类中心
Map阶段:
输入:〈Object,一条数据〉
输出:〈所属类Ci,数据〉
public voidmap(Objectkey,Textvalue,
OutputCollector〈IntWritable,Text〉output,Reporterreporter) {
Stringline=value.toString().trim();
intsort=0;//聚类类别
doubleminDis=Double.MAX_VALUE;
for (inti=1;i<=k;i++) {
doubletmpDis=calDis(i,line);/*数据和类i间的距离*/
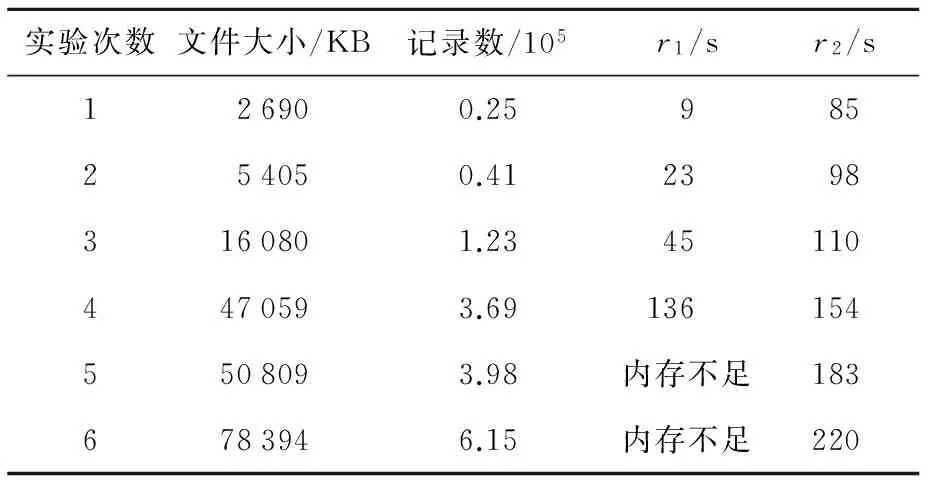
if (tmpDis sort=i; minDis=tmpDis; } } output.collect(new IntWritable(sort),value); } Reduce阶段: 输入:〈Ci,相应数据的集合〉 输出:〈Ci,新的聚类中心〉 public voidreduce(IntWritablekey,Iterator〈Text〉values,OutputCollector〈IntWritable,Text〉output,Reporterreporter) { introws=0,i=0;//rows表示数据条数 doublerecords[]=new double[COLS];/*COLS为全局变量,表示属性的个数*/ while (values.hasNext()) { rows++; Stringtmp=values.next().toString(); StringTokenizeritr=newStringTokenizer(tmp); i=0; while (itr.hasMoreTokens()&&i records[i++] += Double.parseDouble(itr.nextToken()); } } Stringline=""; for (i=0;i line+=records[i]/rows+ " "; } output.collect(key,newText(line)); 迭代Job,直至连续两次聚类中心偏离距离小于给定的阈值。 实验环境:本文采用由九台普通PC机搭建的Hadoop集群进行实验,测试super-k-means并行聚类算法,其中一台作为master,其他8台作为slaves。软件配置如下: JDK 1.6.0.29;Hadoop 0.20.2,master节点上部署Hadoop的NameNode和JobTracker,slaves节点上部署TaskTracker和DataNode。每台节点的硬件配置如下:CPU为双核2.4 GHz;物理内存为4 GB;硬盘为2 TB。实验数据集主要是人工数据以及联合聚类算法的标准测试数据集(http://www.datatang.com/data/44245)。数据维度为6。每组实验均采用平均执行多次取平均值的方法作为实验结果。 4.1 单机处理对比实验 4.1.1 聚类精确度对比 实验内容:在处理相同数据的条件下,super-k-means 聚类算法与k-means聚类算法各自完成聚类结果的精确度对比。从实验数据中构造数据记录数依次为500、2 000、5 000的数据集Data1、Data2、Data3。分别采用三种算法进行聚类,用6次的平均值作为最终实验结果。如表1所示。 Table 1 Accuracy comparison of different clustering algorithms表1 聚类精确度对比 由表1可以看出,在处理小的数据集时,k-means算法所得到的结果也不太理想,而在用改进后的super-k-means(超网络聚类与k-means相结合)算法后聚类效果明显得到了改善。采用并行super-k-means后,随着处理的数据集规模的不断增大,所得到的聚类结果和串行的算法相比较也进一步有了明显的改善。这主要是因为超网络聚类算法在较大规模数据聚类方面具有一定的优势,并且通过超网络聚类算法帮助k-means确定了初始聚类中心,从而收敛到了较好的结果。 4.1.2 单机处理对比实验 实验内容:在相同配置环境下处理相同规模数据时,比较集群中的一个节点与单机super-k-means算法完成聚类所需要的时间。本实验中Java虚拟机JVM(Java Virtual Machine)的内存设置为1 GB。实验结果如表2所示。 Table 2 Single processing experimental results表2 单机处理实验结果 其中,r1为单机上使用super-k-means聚类算法所用的时间;r2为集群中一个节点完成super-k-means聚类算法所用时间。实验中,随着数据量的急剧增大,super-k-means算法的时间复杂度会急剧增大并会产生内存溢出。实验表明,当数据规模很小时,单机运行的super-k-means 聚类算法的运算能力要大大高于Hadoop集群中单节点,这是因为与实际的计算时间相比较而言,MapReduce 每次启动 map 和 reduce 占据的时间比例较大。但是,当单机super-k-means聚类算法因为内存不足而停止计算时,Hadoop单节点仍能正常完成聚类运算,由此初步可见, super-k-means聚类算法在经 MapReduce并行化之后在处理大数据方面有了一定的优势。 4.2 小型集群加速比实验 实验1加速比(Speedup)。 (3) 其中,Sn是加速比。 从实验数据中构建大小依次为60 GB、40 GB、20 GB的DataA、DataB、DataC三个用于并行算法的大规模数据集。 将集群中所有节点按需要逐渐参与计算,并观察每个节点的加速比。实验中,集群中每个节点上运行时的最大map数和最大reduce 数可以根据数据规模大小调节,可以更大限度地调用 Hadoop集群的能力。实验结果如图5 所示。从图5中可以看出,随着节点数的增加,每个Job运行的时间降低,对相同规模数据来说,随着节点数的增加,系统的处理能力有了显著的提高,这说明集群在处理super-k-means算法时具有良好的加速比。可针对各种指标对不同聚类算法进行对比验证分析。 Figure 5 Super-k-means acceleration ratio experiment based on MapReduce 实验2分别进行三组实验测试super-k-means聚类算法的扩展性:第一组,数据集大小为2 GB、4 GB、8 GB、16 GB对应1、2、4、8个节点;第二组,数据集大小为4 GB、8 GB、16 GB、32 GB对应1、2、4、8个节点;第三组,数据集大小为8 GB、16 GB、32 GB、64 GB对应1、2、4、8个节点。实验结果如图6所示。从图6中可以看出,当节点数和数据规模同比例增长时,算法的整体扩展性是逐渐降低的,主要是因为随着节点数的增加,系统节点间的通讯开销增大,从而导致算法的整体运行速度变慢。但是,随着数据规模的逐渐增大,算法的扩展性越来越好,是由于数据规模越大越能充分调动集群中每个节点的处理能力,此时节点间的通讯开销减少的比例也越来越高。因此,第三组中算法的扩展性大于第一组和第二组,更适合处理大规模数据集。 Figure 6 Super-k-means scalability experiment based on MapReduce 将两种不同的聚类算法相结合可以互相取长补短,从而提高聚类效果,但同时又会产生算法时间复杂度高的问题。Super-k-means算法在Hadoop平台下的并行化设计和实现,不仅提高了算法运行的时间效率而且也改善了算法运行的结果。 对于如何改进基于超网络的聚类算法从而提高超网络模型的划分精确度,以及对k-means算法中如何确定最佳的k值从而避免陷入局部最优,加快收敛速度,这些都是有待于以后进行研究的问题。 [1] Li Qun,Yuan Jin-sheng. Optimal density text clustering algorithm based on DBSCAN [J]. Computer Engineering and Design,2012,33(4):1409-1413.(in Chinese) [2] Lai Yu-xia,Liu Jian-ping. Optimal study on initial center ofk-means algorithm [J]. Computer Engineering and Applications,2008,44(10):147-149. (in Chinese) [3] Tian Sen-ping,Wu Wen-liang. Algorithm of automatic gained parameter valuekbased on dynamick-means [J]. Computer Engineering and Design,2011,32(1):274-276.(in Chinese) [4] Bi Xiao-jun,Gong Ru-jiang.Hybrid clustering algorithm based on artificial bee colony andk-means algorithm [J]. Application Research of Computers, 2012,29(6):2040-2045.(in Chinese) [5] Fagin R,Kolaitis P G,Pops L. Data exchange:Getting to the core[J]. ACM TODS,2005,30(1):147-210. [6] Ngazimbi M.Data clustering using MapReduce[D]. Idaho:BosieState University,2009. [7] Sun Ji-gui,Liu Jie. Clustering algorithms research[J]. Journal of Software,2008,22(19):48-61.(in Chinese) [8] Wang Zhi-ping,Wang Zhong-tuo. Super network theory and its application[M]. Beijing:Science Press,2008.(in Chinese) [9] Verma A,Llorae X,Goldberg D E.Scaling genetic algorithms using MapReduce[C]∥Proc of International Conference on Intelligent Systems Design and Applications,2009:1. [10] Jin C,Vecchiola C,Buyya R.Mrpga:An extension of MapReduce for parallelizing genetic algorithms[C]∥Proc of IEEE the 4th International Conference on Science,2008:214-221. 附中文参考文献 [1] 李群,袁金生. 基于DBSCAN的最优密度文本聚类算法[J]. 计算机工程与设计,2012,33(4):1409-1413. [2] 赖玉霞,刘建平.k-means算法的初始聚类中心的优化[J].计算机工程与应用,2008,44(10):147-149. [3] 田森平,吴文亮.自动获取k-means聚类参数k值的方法[J]. 计算机工程与设计,2011,32(1):274-276. [4] 毕晓君,宫汝江. 一种结合人工蜂群和k-均值的混合聚类算法[J]. 计算机应用研究,2012,29(6):2040-2045. [7] 孙吉贵,刘杰. 聚类算法研究[J]. 软件学报,2008,22(19):48-61. [8] 王志平,王众托. 超网络理论及其应用[M]. 北京:科学出版社,2008. 张晓(1988-),女,山东莱芜人,硕士生,CCF会员(E200037819G),研究方向为复杂网络和大数据。E-mail:970790885@qq.com ZHANG Xiao,born in 1988,MS candidate,CCF member(E200037819G),her research interests include complex network, and big data. 王红(1966-),女,天津人,博士,教授,研究方向为复杂网络和大数据。E-mail:1456029328@qq.com WANG Hong,born in 1966,PhD,professor,her research interests include complex network, and big data. An improved hybrid clustering algorithm based on large data sets ZHANG Xiao,WANG Hong (1.School of Information Science and Engineering,Shandong Normal University,Jinan 250014;2.Key Laboratory of Distributed Computer Software in Shandong Province,Jinan 250014,China) Aiming at the following three problems of thek-means algorithm:excessive dependence on the initial clustering center, slow convergence speed and insufficient memory when dealing with huge amounts of data, we present a new hybrid clustering algorithm called super-k-means for large data sets. The algorithm combines thek-means algorithm with the improved high-dimensional data clustering algorithm based on the super-network. We run it on the Hadoop clusters after the MapReduce parallel processing, and an ideal effect of clustering is achieved. Experimental results show that the algorithm not only improves the convergence and the clustering accuracy but also has high speedup and scalability performance. k-means;super network;frequent itemsets;hypergraph partitioning;MapReduce 1007-130X(2015)09-1621-06 2014-09-28; 2014-12-16基金项目:国家自然科学基金资助项目(61373149,61472233);山东省科技计划项目(2012GGX10118,2014GGX101026) TP391 A 10.3969/j.issn.1007-130X.2015.09.003 通信地址:250014 山东省济南市历下区文化东路88号山东师范大学信息科学与工程学院 Address:School of Information Science and Engineering,Shandong Normal University,Jinan 250014,Shandong,P.R.China4 实验



5 结束语


