面向海量空间数据的分级存储模型研究
2015-01-06杨文晖袁进俊1b
杨文晖,袁进俊*,苗 放,1b,2
(1.成都理工大学a.地球探测与信息技术教育部重点实验室,b.地质灾害防治与地质环境保护国家重点实验室,成都 610059;2.成都大学模式识别与智能信息处理四川省高校重点实验室,成都 610106)
面向海量空间数据的分级存储模型研究
杨文晖1a,袁进俊1a*,苗 放1a,1b,2
(1.成都理工大学a.地球探测与信息技术教育部重点实验室,b.地质灾害防治与地质环境保护国家重点实验室,成都 610059;2.成都大学模式识别与智能信息处理四川省高校重点实验室,成都 610106)
空间信息技术和遥感遥测等技术的飞速发展,产生了海量的遥感、地灾等行业空间信息数据。如何对海量空间数据进行合理的分级存储,以满足大数据时代下空间信息、地理信息等行业应用,这已成为日益紧迫的问题。海量空间数据分级存储作为一种全新的存储模式,为解决该问题提出了新的思路。结合海量空间数据的特点和日常数据应用的规律,提出了基于访问热度和聚类关联的海量空间数据分级存储模型,该模型主要包括热点数据分级、关联数据分级、数据的迁移三部分。最后通过嫦娥2号遥感数据模拟访问试验,优化了数据升级阀值,证明了分级存储模型用于海量空间数据的可行性。
空间数据;遥感遥测;分级存储;密度聚类算法;数据关联
0 引言
空间数据已广泛应用于社会各行业、各部门,如城市规划、交通、银行、航空航天等。随着空间信息技术和遥感遥测等技术的飞速发展,产生了海量、实时、异构的空间信息数据。如何对海量空间数据进行合理的分级存储,以使海量空间数据能够满足不断变化的地理信息等应用的需要,这已成为日益紧迫的问题[1]。海量空间数据分级存储模型的提出基于四点因素:①数据分级方面,空间数据和所有数据一样具有2-8效应,即一段时间内只有两成左右的数据被系统经常用到,所以常被用到的数据应该备份存储在能被系统快速获取的设备上[2-3];②数据存储方面,数据存储设备的I/O性能和价格相差很大,比如内存、固态硬盘SSD、磁盘阵列RAID、机械硬盘等,所以应当根据不同数据读写速度需求的不同,选择不同的存储设备以节约成本提高效率[4-5];③数据迁移方面,数据本身的价值和使用率也处在不断变化之中,所以就要求存储的数据根据其价值和使用频率的变化动态调整其存储位置[6-7];④数据关联方面,空间数据本身具有地理坐标的特殊属性,热点数据的关联与地理坐标密不可分。基于以上四点因素,海量空间数据分级存储模型的研究势在必行。
1 空间数据分级存储模型基本内容
1.1 空间数据的特点
空间数据表现了地理空间实体的位置、大小、形状、方向以及几何拓扑关系。空间数据的组织表达采用栅格数据和矢量数据作为两种最基本的形式。
遥感影像数据是一种以栅格形式表示的数据。随着所描述范围的扩大和空间分辨率的提高,数据量呈几何级数地增长。
栅格数据是以二维矩阵的形式来表示空间地物的数据组织方式,每个矩阵单位称为一个栅格单元(cell)。栅格的每个数据表示地物或现象的属性数据,而矢量数据结构是利用点,线,面的形式来表达现实世界。然而不论是栅格数据还是矢量数据,它们都有个共同的地理坐标属性。因此我们在对空间数据进行分级存储时,应当充分利用空间数据的地理坐标属性。这里在对关联空间数据进行分级时,就充分利用了空间数据的坐标属性,采用空间数据密度聚类算法来对关联的空间数据进行分级。
1.2 密度聚类算法介绍
基于密度聚类算法[8]来判断热点数据区域,从而对关联的热点数据进行分级。密度聚类算法认为,在整个数据样本空间中,各目标类族是由一群稠密样本点组成的,而这些稠密样本点被低密度区域(噪声)分割,而密度聚类算法就是要滤过低密度区域,发现样本稠密的样本点。
DBSCAN(Density-based Spatial Clustering of Applications with Noise)[9]是一种基于高密度联通区域的聚类算法,它将类簇定义为高密度相连点的最大集合,它本身对噪声不敏感,并且能发现任意形状的类簇。
1.3 空间数据分级存储模型
本模型采用3级分层结构:硬件层、管理层、应用层(图1)。
1.3.1 硬件层
硬件层是空间数据的存储实体,具体的数据迁移操作都实际发生在硬件层。硬件层根据所存储的数据热度优先级不同,以及存储设备自身访问速度的不同,将数据和存储设备都由高到低分为一一对应的1级~3级。分别是:存储1级数据的内存DDR、存储2级数据的固态硬盘SSD、存储3级数据的机械硬盘。
所有数据一开始都放置在最低优先级的3级存储设备上,系统运行中新写入的数据一开始也都存储在第3级存储设备中。当最低级3级设备中的数据优先级提高,需要迁移到较高级别的设备中时,都采用复制的方式把数据拷贝到高优先级的设备中。当高级别的设备(即1级、2级)之间进行数据迁移时,都采用移动的方式进行数据迁移。

表1 设备优先级和数据热度优先级对照表Tab.1 Equipment priority and data heat priority table
1.3.2 管理层
管理层存储着所有空间数据的标识,负责整个系统模型的数据访问管理、数据分级管理和数据迁移管理,管理层的具体功能通过数据管理中心实现。
数据管理中心包含一个数据访问单元,用于管理数据的访问操作(图1)。
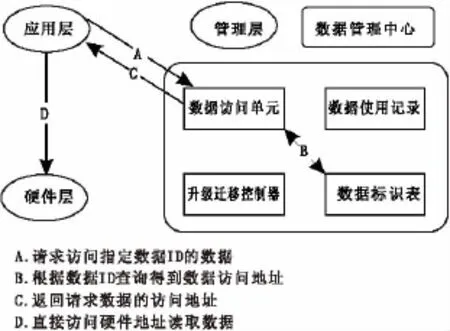
图1 数据访问示意图Fig.1 Schematic diagram of data access
数据管理中心记录了最近一月甚至更久的数据使用记录。数据使用记录的格式如表2所示。

表2 数据使用记录格式Tab.2 The format of Data using record
数据管理中心存储着所有空间数据的数据标识,这些数据构成一个数据标识散列表中。数据标识的结构如表3所示。
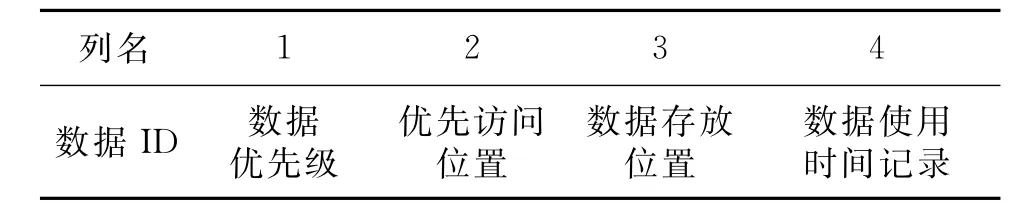
表3 数据标识结构Tab.3 Data identification structure
数据管理中心包含一个分级迁移控制器,它负责数据升级和数据迁移操作。当数据标识的数据使用记录达到某个热度升级阀值时,分级迁移控制器对数据进行迁移,并修改该数据标识的优先级和优先访问位置。
1.3.3 应用层
应用程序根据不同的业务需求对数据进行不同的处理,实现多种多样的功能。硬件层和管理层对应用层是透明的。当应用层需要请求数据时,直接给管理层发送所请求数据的ID,并从管理层得到该数据的访问位置。然后应用层再直接从硬件层读取数据,模型结构图见图2所示。
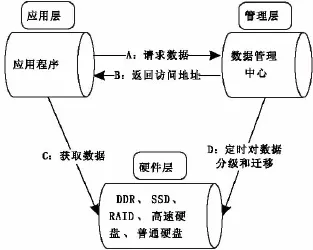
图2 空间数据分级模型结构图Fig.2 The spatial data classification model
2 基于访问频率和密度聚类的空间数据分级策略
2.1 分级策略思想
该分级策略是一种基于访问频率和密度聚类的空间数据分级策略[10],该策略采用两套分级规则,①用于调整被访问数据的优先级;②用于调整关联数据的优先级。
首先对于被访问数据,每次数据使用时,数据管理中心都会增加一条数据使用记录,并定时将该记录写入数据标识中,从而使得分级迁移控制器根据该数据最近的使用频率,判断该数据是否需要升级或者降级,并将优先级发生变化数据迁移到新的优先级对应的存储设备中。
其次对于热点关联数据,鉴于空间数据具有显著地地理坐标特性,当有数据提升到较高优先级时,数据管理中心的分级迁移控制器根据空间数据密度聚类算法,可以找到该被访问数据的关联数据,从而将热点数据区域中的关联数据进行热度升级,并将其迁移到新的优先级对应的存储设备中,以此满足系统对高密度访问的热点数据进行快速访问的需求。
2.2 分级策略实施规则
2.2.1 数据分级存储规划
将空间数据的优先级分为1~3级,数字越小优先级越高,数据初始放置的时候,将所有数据的优先级都定为最低优先级别3级。按1~3优先级从高到低的顺序,不同优先级的数据分别存储在内存DDR、固态硬盘SSD、机械硬盘中。
2.2.2 基于访问频率的热点数据分级方法
当数据标识表中某个数据标识的使用记录的频率达到某个阀值时,就需要变更该数据的优先级,并对该数据做迁移,再将迁移后的优先访问位置存入该数据标识中(图3)。
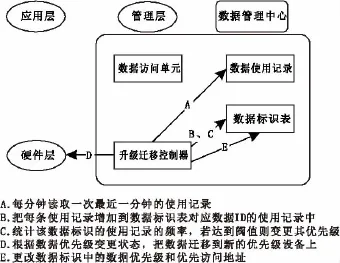
图3 热点访问数据分级示意图Fig.3 Classification of hotspot access data
具体步骤:每次应用层使用数据时,管理层的数据管理中心都会在数据使用记录表中增加一条使用记录。数据使用记录表里面存放了一个月甚至更长时间的数据使用记录,以便以后系统功能扩展使用。数据管理中心的分级迁移控制器,每隔一分钟定时读取最近一分钟的数据使用记录,再把这一分钟内的数据使用记录增加到对应数据ID的数据标识表中,同时删除该数据标识中一周以前的数据使用记录,然后统计该数据标识中使用记录的频率,再根据以下数据优先级分级规则决定该数据的分级变化,若该数据优先级发生变化,升级迁移控制器则向硬件层下达数据迁移指令,迁移完成后再将新的数据优先访问地址写入该数据表示中。
热点数据优先级分级规则:设定一个数据访问频率分级阀值K,对于每分钟使用次数达到K1次的数据,将优先级直接提升为最高级1级;对于每小时使用次数达到K2次的数据,若当前优先级未达到2以上,则将其优先级直接提升为2级表(表4)。

表4 热点数据优先级分级规则Tab.4 Hot data priority classification rules
2.2.3 基于密度聚类算法的关联数据分级方法
当某个数据的优先级被提升到较高级别时,需要查找其关联数据,然后将得到的关联数据的优先级也相应提高(图4)。
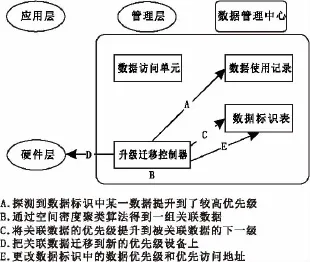
图4 关联数据升级示意图Fig.4 Associated data upgrade
具体步骤:当数据管理中心的升级迁移控制器,检测到某个数据的优先级被提升到较高级别时,升级迁移控制器就通过空间数据密度聚类算法得到其关联数据的一组数据ID,并将这组数据ID对应的数据优先级提升为该数据优先级的下一级别,并将这些数据依次迁移到新的存储设备中,然后将新的优先访问位置更新到数据标识中。
关联数据优先级分级规则:因为第2级数据的下一级别为最低级3级,所以对第2级数据进行聚类算法查找关联数据是没有意义的;同时也因为聚类算法会占用大量计算资源,所以只有当数据的优先级被提高到较高的优先级时,才对该数据进行空间数据密度聚类算法找出其关联数据,并提升其关联数据的级别。具体规则为:当某一数据的优先级被提高到1级时,对该数据进行一次空间数据密度聚类算法,对于聚类算法得到的相关数据,若这些相关数据的级别未达到2级以上,则将这些相关数据的优先级提升为2级。
3 空间数据分级存储模型实验
3.1 实验数据及实验环境
实验数据对象选择的是嫦娥2号遥感数据(1T)。作为空间数据的一种,嫦娥2号遥感数据具有量大、数据结构复杂的特点,处理起来速度非常慢。通过对数据进行分级存储实验,验证该方法的效率。
实验环境部署在三台DELL PowerEdge 2950服务器上面,一台部署应用程序用于请求遥感数据;一台部署数据管理中心用于分级和调度遥感数据;一台部署为硬件层用于存储数据,并额外挂载了多种存储设备,实现数据分级存储(表5)。
3.2 热点访问数据分级策略数据迁移实验
该实验通过模拟高频率数据调用,得到了各数据升级阀值K值在不同取值下的设备利用率,收据访问命中率及数据平均访问延迟曲线。

表5 实验环境Tab.5 Experimental environment
3.2.1 实验结果
由图5可以看出,随着应用程序对数据的持续访问,一级设备的利用率会不断增加并逐渐趋于稳定;其中当K1取值10次/s时,设备率利用率最高。
由图6可以看出,随着应用程序对数据的持续访问,数据访问在一级设备中的命中率不断增加;但是当K1取值10次/s时,由于设备使用率满负荷导致命中率陡然降低。

图5 一级SSD设备利用率在不同K1值的变化曲线Fig.5 Change curve of level 1SSD equipment utilization in differentvalues of K1
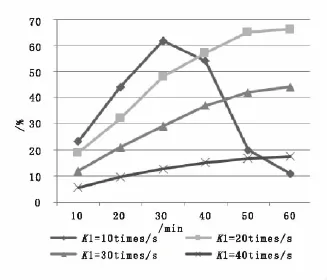
图6 一级SSD设备数据访问命中率在不同K1值的变化曲线Fig.6 Change curve of level 1SSD equipment data access shot in differentvalues of K1
由图7可以看出,随着应用程序对数据的持续访问,数据访问的平均延迟逐渐减小,分级存储的优势不断显现,但是当K1取值10次/s时,由于设备很快满负荷,导致数据延迟陡然增加。
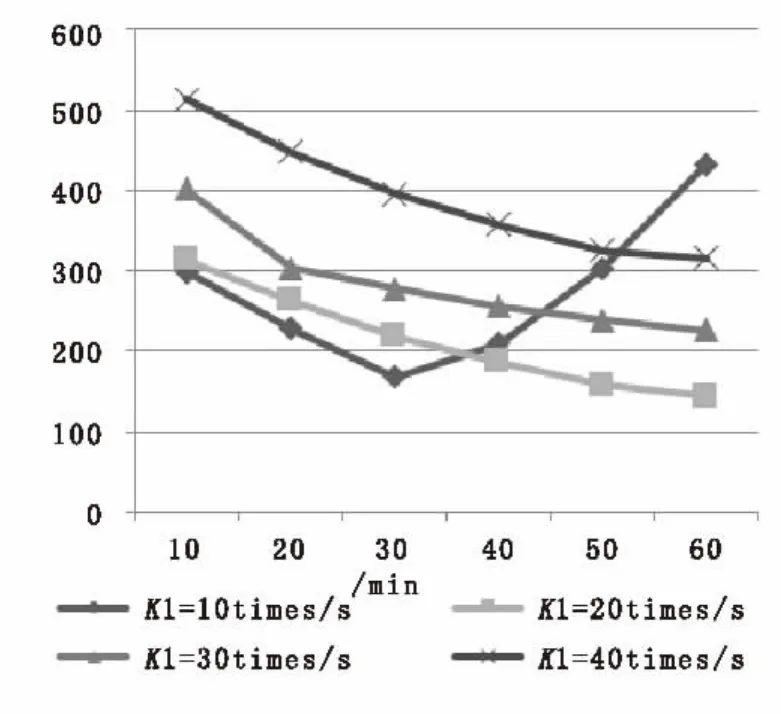
图7 数据平均访问延迟在不同K1值的变化曲线Fig.7 Change curve of average data access delay in different values of K1
3.2.2 实验分析及结论
综合以上三个实验指标,可以发现当K1取值10次/s时,设备利用率最高,但由于设备很快满负荷运转,会导致系统运行缓慢,影响数据命中率和数据访问速度;当看取值20次/s时,数据命中率和数据访问延迟最佳。综合分析可以知道,当数据升级阀值K1取值20次/s时,系统的综合性能最佳。
3.3 关联数据分级策略数据迁移实验
该实验通过对关联数据的迁移测试,在实验一中得到的最佳升级阀值K1取值20次/s的情况下,对有无运用关联数据分级策略二者之间的数据访问延迟进行比较,以及对二者数据迁移量的大小进行比较,以此验证关联数据迁移策略的优势。
热点数据升级阀值K1取最佳值20次/s,随着系统的运行,高级设备中的热点数据慢慢增加,数据更多的在高速存储设备中访问,使得数据访问的整体延迟逐渐减小,并且在采用了基于空间数据密度聚类算法的关联数据分级策略后,数据的访问延迟总体减少,加快了数据的访问速率。
从图9可以看出,随着数据访问的继续,系统单位时间内的数据迁移量由高到低逐渐趋于平稳。采用了关联数据分级策略后,系统的数据迁移量会有所减少,从而缓解了系统的性能。
4 结束语
大数据时代,带来了海量遥感遥测,地质灾害等空间信息数据存储的问题。作者提出了一种基于热点访问频率的数据分级策略和一种基于空间数据密度聚类算法的数据分级策略。通过对嫦娥2号数据进行模拟实验,提升了数据升级阈值,大大加快了热点数据的访问速率,并充分利用了高级存储设备的利用率。由于关联数据分级策略的贡献,使得设备的数据迁移量明显降低。整体的分级存储策略及模型,实现了空间数据的高效存储,为海量空间信息数据存储提供了一个可行解决方案。
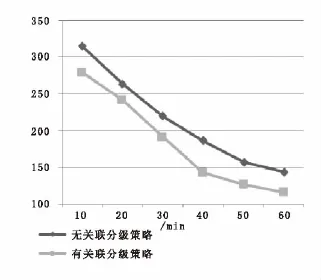
图8 有无关联数据分级策略的数据访问延迟比较Fig.8 Data access delay compareof associated data and no associated dataclassification strategyin best upgrade threshold

图9 有无关联数据分级策略下的单位之间数据迁移量对比Fig.9 Data migration quantity between unitscontrast ofassociated data and no associated datain best upgrade threshold
[1] 百度百科.面向数据的体系结构[OL].http://baike.baidu.com/subview/649092/12822804.htm. Baidu Encyclopedia.DOA[OL].http://baike.baidu.com/subview/649092/12822804.htm.(In Chinese)
[2] 聂雪军,秦磊华,周敬利.内容感知存储系统中自动分级存储模型研究[J].小型微型计算机系统,2011,32 (6):1151-1156.
NIE X J,QIN L H,ZHOU J L.Research on auto-tiering storage model in content aware storage system [J].Journal of Chinese Computer Systems,2011,32 (6):1151-1156.(In Chinese)
[3] 刘晓然.基于文件的数据分级存储的研究与实现[D].昆明:昆明理工大学,2013.
LIU X R.Research and implementation of data-based hierarchical storage of files[D].Kunming:Kunming University of Science and Technology,2013.(In Chinese)
[4] MEI H,LING X,LI G B,A data migration strategy for HSM based on data value[J].Journal of Information &Computational Science,2011,8(2):312-319.
[5] ZOLGHADRI M J,MANSOORI E G.Weighting fuzzy classification rulesusing receiver operating characteristics(ROC)analysis[J].Information Sciences,2007,177(11):2296-2307.
[6] 敖莉,于得水,舒继武,等.一种海量数据分级存储系统TH-TS[J].计算机研究与发展,2011,48(6):1089-1100.
AO L,YU D SH,SHU J W,et al.A tiered storage system for massive data:TH-TS[J].Journal of Computer Research and Development,2011,48(6):1089-1100.(In Chinese)
[7] 吕帅.基于对象的分级存储系统数据迁移技术研究[D].长沙:国防科学技术大学,2009.
LV SH.Research on object-based data migration technology of hierarchical storage system[D].Changsha:National University of Defense Technology,2009.(In Chinese)
[8] 王芳,张顺达,冯丹,等.对象存储系统中的柔性对象分布策略[J].华中科技大学学报:自然科学版,2007,35 (3):46-48.
WANG F,ZHANG SH D,FENG D,et al.Hybrid object allocation policy for object storage systems[J].Journal of Huazhong University of Science and Technology:Natural Science Edition,2007,35(3):46-48.(In Chinese)
[9] 聂跃光.基于密度聚类的空间数据挖掘算法研究[D].太原:太原科技大学,2008.
NIE Y G.Study of spatial data mining algorithm based on density clustering[D].Taiyuan:Taiyuan University of Science and Technology,2008.(In Chinese)
[10]冯少荣,肖文俊.DBSCAN聚类算法的研究与改进[J].中国矿业大学学报,2008,37(1):105-110.
FENG SH R,XIAO W J.An improved DBSCAN clustering algorithm[J].Journal of China University of Mining &Technology,2008,37(1):105-110.(In Chinese)
[11]于彦伟,王沁,邝俊,等.一种基于密度的空间数据流在线聚类算法[J].自动化学报,2012,38(6):1051-1058.
YU Y W,WANG Q,KUANG J,et al.An on-line density-based clustering algorithm for spatial data stream[J].Acta Automatica Sinica,2012,38(6):1051 -1058.(In Chinese)
Research of tiered storage model for massive spatial data
YANG Wen-hui1a,YUAN Jin-jun1a*,MIAO Fang1a,1b,2
(1.Chengdu University of Technology a.Key Lab of Earth Exploration &Information Techniques of Ministry of Education,Chengdu University of Technology,b.State Key Laboratory of Geohazard Prevention and Geoenvironment Protection,Chengdu 610059,China;2.Key Lab of Pattern Recognition and Intelligent Information Processing of University of Sichuan Province,Chengdu College,Chengdu 610106,China)
With the rapid development of space information technology and remote sensing technology,vast amounts of spatial information data like remote sensing and geological disasterwere produce.How reasonable tier stored massive spatial data to make meet the needs of applications like spatial information and geographic information is becoming an increasingly urgent problem.Hierarchical storage massive spatial data as a new model for solving the problem put forward new ideas.Combined with the characteristics of massive spatial data and rule of daily data application,put forward the data presented hierarchical data storage model and the associated heat-based access massive spatial clustering,the model includes hot data classification,association data classification,data migration in three parts.Finally,simulation access testing on Change 2remote sensing data optimized the threshold of data upgrade;it proved the feasibility of the tiered storage model for spatial data.
spatial data;remote Sensing;tiered storage;density clustering algorithm;data association
TP 301
:A
10.3969/j.issn.1001-1749.2015.06.19
1001-1749(2015)06-0783-07
2014-11-11改回日期:2015-04-19
国家自然科学基金项目(61071121);成都市经信委科技专项项目(201102153)
杨文晖(1969-),女,副教授,从事计算机技术及应用方向的研究,E-mail:ywhui@cdut.edu.cn。
*通信作者:袁进俊(1989-),男,硕士,从事分布式存储与计算、空间信息技术及应用方向的研究,E-mail:373611905@qq.com。
