基于相关系数的决策树优化算法*
2015-01-05董跃华
董跃华,刘 力
(江西理工大学信息工程学院,江西 赣州 341000)
基于相关系数的决策树优化算法*
董跃华,刘 力
(江西理工大学信息工程学院,江西 赣州 341000)
通过分析ID3算法的基本原理及其多值偏向问题,提出了一种基于相关系数的决策树优化算法。首先通过引进相关系数对ID3算法进行改进,从而克服其多值偏向问题,然后运用数学中泰勒公式和麦克劳林公式的性质,对信息增益公式进行近似简化。通过具体数据的实例验证,说明优化后的ID3算法能够解决多值偏向问题。标准数据集UCI上的实验结果表明,在构建决策树的过程中,既提高了平均分类准确率,又降低了构建决策树的复杂度,从而还缩短了决策树的生成时间,当数据集中的样本数较大时,优化后的ID3算法的效率得到了明显的提高。
ID3算法;相关系数;决策树;泰勒公式;信息增益
1 引言
数据挖掘是指从大量数据中挖掘知识的过程,是一种新的高级数据分析技术[1]。数据分类是数据挖掘中重要的研究方法之一[2],其中有决策树分类器、贝叶斯分类器等基本技术。20世纪80年代初期,机器学习研究者Quinlan J R[3]提出了一种新的决策树分类算法,即ID3算法。在各类决策树算法中,ID3算法的影响力最大。
然而ID3算法也存在一些缺陷[4]:(1)信息熵的计算方式易使ID3算法产生多值偏向问题;(2)数据集样本个数的增多使算法对应计算量的增幅变大;(3)训练集的增减变化会影响算法对应决策树的生成。
针对ID3算法的多值偏向问题,自Quinlan J R提出C4.5算法[5]以来,许多学者进行相关改进工作:文献[6~9]将用户兴趣度参数引入信息熵公式,虽在一定程度上能解决多值偏向问题,但该参数需要用户具有丰富的先验知识和领域知识以及需要在进行大量的实验后才能给出;文献[10]通过引入单调递减的修正函数对信息熵值进行修正,以达到对ID3算法进行改进的目的,但修正函数是人为主观选取的,因此在一定程度上会影响决策结果的正确性和客观性;文献[11]将概率统计中的相关系数概念引入决策树中,将条件属性和决策树属性之间的相关系数值作为选择分裂属性的标准。条件属性和决策属性之间的相关系数越大,表明该条件属性和决策属性之间的相关性程度越高、联系越紧密,该条件属性对分类的重要性越大[12],但因为其脱离信息熵理论的计算方式,所以在分类准确率上会低于ID3算法;文献[13]在用户兴趣度参数的研究基础上,使用灰色关联度取代用户兴趣度,虽在一定程度上能克服多值偏向问题,但若实际操作中出现灰度较低或属性取值个数较多等情况,则难以界定灰色关联度的范围。
本文在文献[10,11]的基础上,结合修正函数的修正思想和相关系数,提出了基于相关系数的决策树优化算法。区别于文献[10]中对信息熵值的修正,本文通过引入相关系数对划分子元组的期望信息量进行修正,以完成对ID3算法的改进。另外,通过利用泰勒公式和麦克劳林公式得到近似转化公式,以完成对信息熵公式的近似简化,简化后的公式已完全消除了复杂的对数运算,从而提高了信息熵公式的计算效率。实验结果表明,基于相关系数的决策树优化算法,既能够克服多值偏向问题,提高分类精度,又能降低决策树的生成时间。
2 理论基础
2.1 ID3算法[14]
设训练集S有s个样本,将训练集分成m个类,第i类的实例个数为si,ID3算法基于信息熵计算的计算公式定义为:
(1)
其中,pi是S中属于第i类的概率,pi=si/s。
若选择属性A划分训练集S,设属性A有属性值{s1,s2,…,sk},则sj中属于第i类的训练实例个数为sij,则有:
(2)
其中s1j+…+smj=sj。
(3)
其中,pij为sj中第i类样本的概率,pij=sij/sj。
从而得到划分属性A的信息增益为:
Gain(A,S)=Info(S)-InfoA(S)
(4)
2.2 相关系数
2.2.1 相关系数的定义[15]
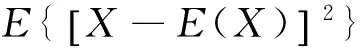

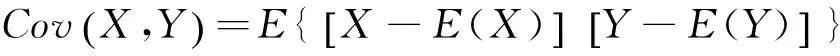
则随机变量X与Y的相关系数ρxy定义为:
(5)
其中,D(X)和D(Y)分别为X和Y的方差。
2.2.2 相关系数的含义[15]
用X的线性函数a+bX来近似表示Y,以均方误差e来衡量以a+bX近似表示Y的好坏程度。其中,
2abE(X)-2aE(Y)
(6)
而e的值越小,则表示a+bX与Y的近似程度越大。因此,给a、b赋值,使e取最小值。令e分别求关于a、b的偏导数,并使它们等于零,则有:
解得:
将a0、b0代入式(6)得:
(7)

2.3 ID3算法公式简化的理论基础
本文通过运用泰勒公式和麦克劳林公式对信息熵计算公式进行近似转换,以达到简化ID3算法公式的目的。
2.3.1 泰勒中值定理[16]
如果函数f(x)在含有x0的某个开区间(a,b)内具有直到(n+1)阶的导数,则对于任意x∈(a,b),有:
(8)
其中ξ是x0与x之间的某个值。
2.3.2 麦克劳林公式[16]

(9)
由此得到近似公式:
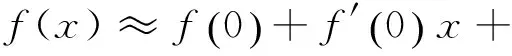
(10)
由此可得:
(11)
因此有:
(12)
当x∈(0,1)时,
(13)
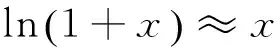
3 基于相关系数的决策树优化算法
3.1 ID3决策树优化算法的实现方案
本文针对“多值偏向问题”和“信息熵计算公式”两个方面,分别对ID3算法进行算法改进和公式简化,提出了基于相关系数的决策树优化算法DTCC(Optimized algorithm of Decision Tree based on Correlation Coefficient),DTCC算法由ID3算法改进和ID3算法公式简化两部分组成。
(1)ID3算法改进。用户兴趣度之类的主观参数主要取决于用户的先验知识和相关领域知识,决策结果更倾向于用户的主观思维。为避免此类主观参数不具说服力,本文引入概率统计中的相关系数对ID3算法进行改进。相关系数客观反映条件属性和决策属性之间的相关程度,使分裂属性的选择不受属性取值个数的影响,从而克服其多值偏向的缺陷,还因无较多主观的参与或干扰从而避免了决策结果受用户主观思想的影响。
(2)ID3算法公式简化。本文在泰勒公式和麦克劳林公式的基础上得到近似转换公式,通过利用近似转换公式对信息熵公式进行近似简化。简化后的公式以信息熵理论为基础,因而保留了较高的分类精度,又能消除信息熵公式中复杂的对数运算,提高算法计算效率。
3.2 ID3算法的改进
ID3算法对属性进行分类时,通常以信息增益值作为属性选择度量,将具有最大增益值的属性作为最优分裂属性。ID3算法造成多值偏向问题的本质是:信息熵的计算特点会使属性的重要性程度与属性的取值个数成正比,但通常取值个数较多的属性不一定是最优分裂属性,最终可能会导致做出不适合实际情况的决策,为此本文引进相关系数对ID3算法进行改进。
3.2.1 属性之间相关系数的引入
假设训练集S由r个条件属性和一个决策属性Y构成,将r个条件属性字段看成随机变量Xp(p=1,2,…,r),决策属性看成随机变量Y,则某个属性的属性值分布即为某个随机变量的取值分布,令随机变量Xp的取值为xq(q=1,2,…,k),则Xp取到各个值的概率P{Xp=xq}=pq(q=1,2,…,k)称为随机变量Xp的概率分布,此时可将训练集S转变成若干个随机变量的集合。
借鉴定义1和定义2,将变量间的相关系数引进到ID3算法中,使其成为重新定义条件属性与决策属性之间紧密相关程度的性能指标。令k、m分别为随机变量Xi与Y的取值个数,则随机变量Xp(i=1,2,…,r)与Y的协方差为:
其中,pq t为(q=1,2,…,k;t=1,2,…,m)为Xp和Y的联合概率分布。Xp和Y的联合概率分布如表1所示。

Table 1 Joint probability distribution of Xp and Y表1 (Xp,Y)的联合概率分布
重新定义随机变量Xp与Y的相关系数为:
(14)
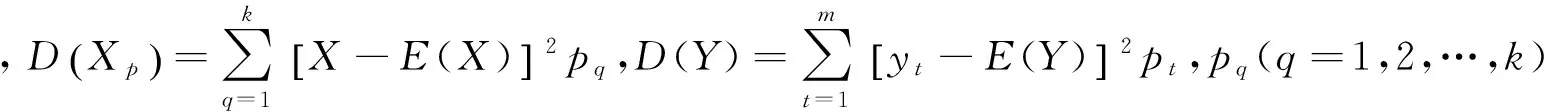
令:
(15)
从公式(15)中可看出0≤ωp≤1,而ωp成为了衡量条件属性集Xp与决策属性Y之间紧密相关程度的一种度量标准。
当ωp较大时,说明Xp与Y属性之间联系的紧密程度较高;当ωp较小时,说明Xp、Y属性之间联系的紧密程度较低;当ωp=1时,称Xp和Y属性之间以概率1存在着紧密的联系;当ωp=0时,称Xp和Y属性之间没有联系。
3.2.2 引入相关系数对ID3算法进行改进
相关系数对ID3算法公式(4)进行改进后,得到新的信息增益公式(16):
(16)
属性相关系数客观反映条件属性和决策属性之间联系的紧密程度,且不受属性取值个数的影响。
3.2.3 ID3算法改进后的多值偏向分析
(1)ID3算法多值偏向分析。
假设存在一个属性值个数较多且重要性低的条件属性B,则条件属性B与决策属性Y之间联系的紧密程度必然低,其相关系数ωB较小;存在一个属性值个数较少且重要性高的条件属性A,则条件属性A与决策属性Y之间联系的紧密程度必然高,其相关系数ωA较大。相对于决策属性Y,条件属性A的重要性高于条件属性B,因此很显然有:ωA>ωB。
从文献[10]中可知:由于信息熵的计算特点,它会偏向于属性取值个数多的属性,文献[17]也证明在该情况下的公式(17)恒成立。
Gain(A,S)≤Gain(B,S)
(17)
由此可知公式(17)的恒成立是造成多向偏值问题的本质,所以要解决多向偏值问题只要避免公式(17)恒成立即可。
(2)ID3算法改进后的多值偏向分析。
ID3算法被改进后,比较信息增益Gain(A,S)′和信息增益Gain(B,S)′两者之间的大小关系:
若Gain(A,S)′≤Gain(B,S)′恒成立,说明该算法有多值偏向问题;若能避免其恒成立,则说明该算法能克服多值偏向问题。
将公式(17)进一步等价推导可得:
Gain(A,S)≤Gain(B,S)⟺
Info(S)-InfoA(S)≤Info(S)-InfoB(S)⟺
InfoA(S)≥InfoB(S)
(18)
由公式(16)可得算法改进后,属性A和属性B的子元组期望信息分别为:
和
从公式(18)中可知:公式(17)恒成立等价于InfoA(S)≥InfoB(S)恒成立。但是,因为在各自的子元组期望信息中分别乘以1/ωA和1/ωB,且由ωA>ωB可得1/ωA<1/ωB,所以可避免公式(19)的恒成立。
(19)
由公式(19)进一步可推导出如下等价关系:
⟺
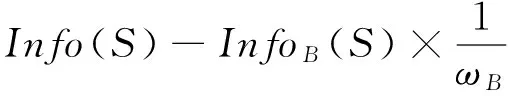
Gain(A,S)′≤Gain(B,S)′
(20)
从公式(20)中可知:能够避免公式(19)的恒成立,即等价于避免Gain(A,S)′≤Gain(B,S)′的恒成立。能够避免Gain(A,S)′≤Gain(B,S)′的恒成立,则表明多向偏值问题已经得到解决。
因此,采用公式(16)作为新的属性选择标准作,能够降低属性取值个数较多且重要性低的属性的重要程度,克服了ID3算法多值偏向的缺陷。
3.3 ID3算法的公式简化
将ID3算法的信息增益公式完全展开后,变形为公式(21):
(21)
公式(21)中常数m为训练集类别数,Info(S)为一个定值,因此公式(21)只保留后一项也不会影响最终比较结果,则取后一项可得公式(22):
(22)
从公式(22)中可看出:对数运算是计算中主要的耗时部分,因而消去对数运算能够降低计算量并提高计算效率。
sj中属于第i类的训练实例个数为sij,pij是sj中属于第i类的概率,pij=sij/sj,且s1j+…+smj=sj,因此公式(22)可进行如下转化:
使用近似简化公式(13)可进一步化简为:
ln 2和样本个数s均为常数项,去掉后不影响结果的比较,将其去掉后进一步简化得到公式(23):
(23)
从公式(23)中可看出:公式中已完全消除复杂的log对数运算,只需对函数进行有限次数的加、减、乘、除四种基本运算即可,计算效率得到很大提高。
3.4 DTCC算法的提出
DTCC算法包括ID3算法改进和ID3算法公式简化两个部分的工作,将ID3算法改进公式(16)和ID3算法简化公式(23)相结合得到DTCC算法公式(24):
(24)
DTCC算法采用公式(24)作为新的属性选择标准。DTCC算法既能克服多值偏向,又能简化ID3算法公式,降低计算量并提高计算效率。
4 实验及结果分析
4.1 实验说明及评价标准
本实验在标准数据集UCI上进行,采用UCI提供的若干个标准数据集(如表2所示)进行数据分析。数据集中2/3样本作为训练集,1/3作为测试集。采用文献[18]中的方法先对数据集中的连续性属性进行离散化操作。
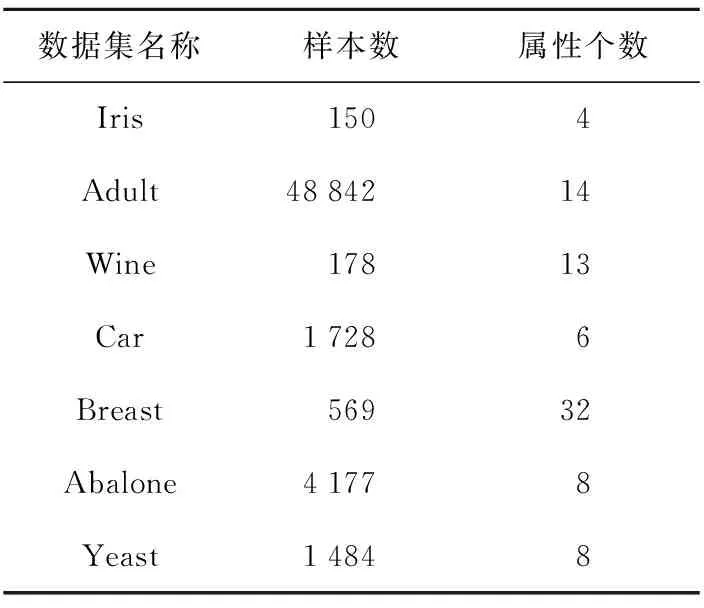
Table 2 Dataset表2 数据集
采用商务购车顾客数据库(如表3所示)作为训练集D,对数据进行选取、预处理和转换操作后得到样本集合,该集合包含四个条件属性:喜欢的季节(含四个属性值:春天、夏天、秋天、冬天)、是否商务人士(含两个属性值:是、否)、收入(含三个属性值:高、中、低)、驾车水平(含两个属性值:良好、一般)。样本集合根据类别属性“是否买车”(含有两个属性值:买、不买)进行划分。

Table 3 Dataset D of the customer database表3 顾客数据库训练集D
本实验采用WEKA平台,实验使用的计算机配置:CPU为酷睿i5 2300系列,主频为2.8 GHz,内存为4 GB,操作系统为Windows 7,仿真软件为Matlab 2012。
分类准确率是分类问题中常用的评价标准,能体现出分类器对数据集的分类性能。分类准确率指分类器中被正确分类的样本个数在总的检验集中所占的比例[19],将其定义为公式(25):
(25)
其中,s为总的样本个数,m为分类类别个数,si为训练集中属于第i类的实例个数。
4.2 DTCC算法的实例验证与分析
以训练集D为例,先计算出各个条件属性与决策属性的相关系数,然后再根据公式(4)计算ID3算法信息增益,根据公式(24)计算DTCC算法的信息增益,根据公式(23)计算ID3算法公式简化后的信息增益,最后按照决策树建树规则,构建各自的决策树,分别如图1~图3所示。
4.2.1 相关系数的计算
(1)条件属性“喜欢的季节”与决策属性“是否买车”之间相关系数的计算。
条件属性“喜欢的季节”X1与决策属性“是否买车”Y的联合分布律如表4所示。

Table 4 Joint probability distribution of X1and Y表4 X1与Y的联合概率分布
通过表4中数据计算可得:
(2)条件属性“是否商务人士”与决策属性“是否买车”之间相关系数的计算。
条件属性“是否商务人士”X2与决策属性“是否买车”Y的联合分布律如表5所示。

Table 5 Joint probability distribution of X2 and Y表5 X2与Y的联合概率分布
通过表5中数据计算可得:
(3)条件属性“收入”与决策属性“是否买车”之间相关系数的计算。
条件属性“收入”X3与决策属性“是否买车”Y的联合分布律如表6所示。

Table 6 Joint probability distribution of X3and Y表6 X3与Y的联合概率分布
通过表6中数据计算可得:
(4)条件属性“驾车水平”与决策属性“是否买车”之间相关系数的计算。
条件属性“驾车水平”X4与决策属性“是否买车”Y的联合分布律如表7所示。

Table 7 Joint probability distribution of X4and Y表7 X4与Y的联合概率分布
通过表7中数据计算可得:
4.2.2 ID3算法及其对应生成的决策树
首先计算属性的期望需求:
则相应属性的信息增益为:
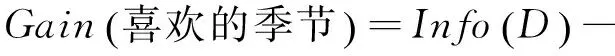
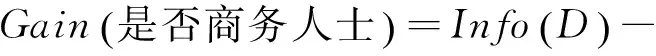
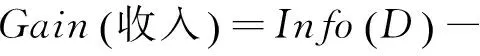

其次,由计算结果比较可知:
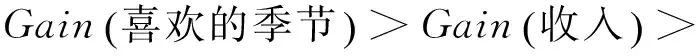
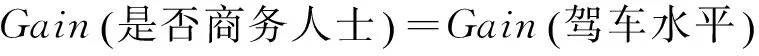
因此,依照ID3算法分裂节点的原则将“喜欢的季节”属性作为决策树的根节点,对样本元组进行分类。对分类后形成的子集,用递归的方法对其计算熵值并进行分裂属性的选择,最终得到的决策树如图1所示。
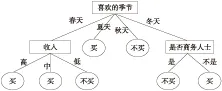
Figure 1 Decision tree produced by the ID3 algorithm
4.2.3 DTCC算法及其对应生成的决策树
DTCC算法公式为:
表1中实例有两个类,即m=2,则公式(20)可变形为:
按照变形后的公式分别计算属性的信息增益:
Gain(X1=喜欢的季节)′=
Gain(X2=是否商务人士)′=
Gain(X3=收入)′=
Gain(X4=驾车水平)′=
比较结果可知:
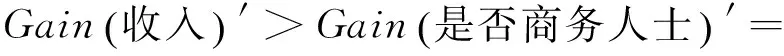

因此,将“收入”作为DTCC算法生成的决策树的根节点,对样本元组进行分类。对分类后形成的子集,用递归的方法对其计算熵值并进行分裂属性的选择,最终得到的DTCC算法生成的决策树如图2所示。

Figure 2 Decision tree produced by the DTCC algorithm图2 DTCC算法生成的决策树
4.2.4 只进行简化操作后的ID3算法及其对应生成的决策树
简化后的ID3算法公式为:
表1中实例有两个类,即m=2,则公式(19)可变形为:
按照变形后的公式分别计算属性的信息增益:
Gain(喜欢的季节)3=
Gain(是否商务人士)3=
Gain(收入)3=
比较计算结果可知:
按照ID3算法分裂节点的原则将“喜欢的季节”属性作为决策树的根节点,对样本元组进行分类。对分类后形成的子集,用递归的方法对其计算熵值并进行分裂属性的选择,最终得到的决策树如图3所示。
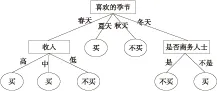
Figure 3 Decision tree produced by the ID3 algorithm with its simplified formula
4.2.5 DTCC算法的实例分析与总结
通过将图1~图3进行综合对比发现:
(1)比较图1和图2。属性“喜欢的季节”属性值个数最多,多值偏向使其成为决策树的根节点。“喜欢的季节”是一种主观想法,不是购车的决定性因素。现实生活中,“收入”在一定程度上更能决定是否购车。从图2可看出,DTCC算法令“喜欢的季节”属性离决策树根节点的距离变远,降低其重要性;令“收入”属性作为决策树根节点,提高其重要性,符合实际情况,因此DTCC算法在一定程度上克服了多值偏向问题。
(2)比较图1和图3。从图3中可看出,ID3算法公式简化后生成的决策树与原ID3算法生成的决策树完全一致。表明本文中对原ID3算法进行近似转化的简化公式精度较高,能够与原ID3算法生成的决策树基本保持一致。
4.3 实验及分析
(1)分类准确率和叶子节点数的比较。
在表2提供的数据集进行实验数据测试,每一个数据集上进行10次实验。在分类准确率的实验结果中,去掉最大数据和最小数据,再求出平均分类准确率作为最终实验数据,可使实验结果具有普遍性。
将每一个数据集分成10个数据组,每个数据组中分别用ID3算法、C4.5算法、文献[10]算法、文献[11]算法和DTCC算法构建决策树,每个数据组上均构建10次。在叶子节点数的实验结果中,去掉最大数据和最小数据,再求出平均叶子节点数作为该数据组的最终数据。每个数据集里以数据组为最小单位进行类似操作,求出其平均叶子节点数作为该数据集的最终实验数据。实验结果如表8和表9所示。
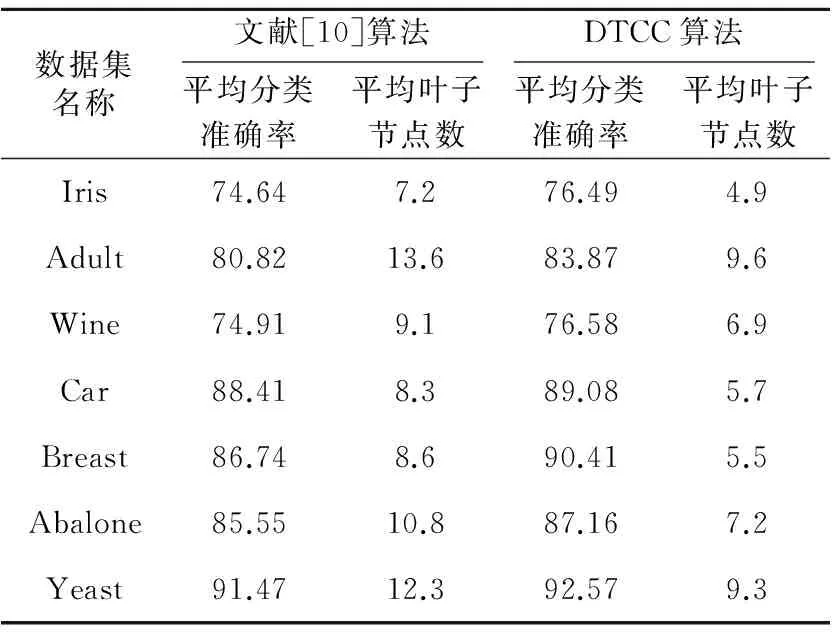
Table 8 The first part of the experimental results表8 实验结果1
从表8和表9的实验结果中可看出:相比于ID3算法、文献[10]算法、C4.5算法、文献[11]算法,DTCC算法具有较高的分类准确率和较少的平均叶子节点数,并降低了构建决策树的复杂度。

Table 9 The second part of the experimental results表9 实验结果2
(2)决策树生成时间的比较。
采用实例表3中提供的训练集D,分别对ID3算法、文献[10]算法、C4.5算法、文献[11]算法和DTCC算法进行10次计算时间的测试,在实验结果中去掉最大数据和最小数据,再求出平均时间作为构建决策树所花费的时间。实验结果如图4所示。图4中横坐标表示训练集样本的取值个数,纵坐标表示构建决策树所花费的时间。
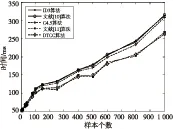
Figure 4 Time comparison of building the decision tree among the five kinds of algorithms
从图4中可看出:(1)样本个数偏少时,五种算法花费时间相差不大。(2)从整体上看文献[10]算法所花费的时间与ID3算法的时间基本相同。(3)当样本个数相同时,DTCC算法和文献[11]算法构建决策树所花费的时间较少。(4)当样本个数达到一定数量时,DTCC算法所节省的时间随着样本个数的递增而变多,这表明:在构建大规模数据集的决策树时,使用DTCC算法能够节约更多的时间。
4.4 实验结论
结合图1~图3可看出:(1)本文提出的DTCC算法能够克服多值偏向问题;(2)DTCC算法中对ID3算法公式简化的部分,并未降低原ID3算法公式的精度,DTCC算法生成的决策树与原ID3算法生成的决策树基本保持一致。
结合表8、表9、图4可看出:(1)文献[10]算法和C4.5算法虽然分类精度较高,但决策树建立时间较长。(2)文献[11]算法决策树建立时间较短,但分类精度较低。(3)本文提出DTCC算法,继承了以上各算法的长处,实验结果分析表明:DTCC算法具有较高的分类精度;平均叶子节点数较少,使构造的决策树有较低的复杂性,因而使决策树建立时间较少;此外还能克服ID3算法的多值偏向问题。
5 结束语
本文通过引进概率论中相关系数的概念,基于相关系数提出了一种新的决策树优化算法——DTCC算法,相关系数能够客观反映条件属性和决策属性之间联系的紧密程度,既不受属性取值个数的影响,且不需要用户提供先验知识或领域知识,又能避免因为主观的人为因素所受到的干扰和影响。本文用相关系数代替依靠先验知识的用户兴趣度之类的权值参数,以克服ID3算法的多值偏向问题。再利用泰勒公式和麦克劳林展开公式得到近似公式,以完成对信息增益公式的近似转换,这样既保证简化后的算法保留较高的精度,且以信息熵计算为基础,又能够消除函数中复杂的对数运算,提高算法执行效率。
实验结果分析表明,相比于原ID3算法以及ID3相关的改进算法,DTCC算法具有更高的平均分类精确度,较低的决策树构建复杂度,更少的决策树生成时间。当数据集的样本数偏大时,DTCC算法的效率和性能能够得到明显的提高。
[1] Ji Xi-yu,Han Qiu-ming,Li Wei,et al.Data mining technology application examples[M].Beijing:Mechanical Industry Press,2009.(in Chinese)
[2] Chen An, Chen Ning, Zhou Long-xiang, et al.Data mining technologies and application[M].Beijing:Science Press,2006.(in Chinese)
[3] Quinlan J R. Induction of decision trees[J]. Machine Learning,1986,1(1):81-106.
[4] Wang Miao,Chai Rui-min.An improved decision tree classification attribute selection method[J] .Computer Engineering and Applications,2010,46(8):127-129.(in Chinese)
[5] Li Xiao-wei,Chen Fu-cai, Li Shao-mei. Improved C4.5 decision tree algorithm based on classification rules[J]. Computer Engineering and Design,2013,34(12):4321-4325.(in Chinese)
[6] Wang Yong-mei,Hu Xue-gang.Research of ID3 algorithm in decision tree[J]. Journal of Anhui University (Natural Science Edition),2011,35(3):71-75.(in Chinese)
[7] Wang Yong-mei,Hu Xue-gang.Improved decision tree algorithm based on user-interest and MID3[J].Computer Engineering and Applications,2011,47(27):155-157.(in Chinese)
[8] Liu Yu-xun,Xie Niu-niu. Improved ID3 algorithm[C]∥Proc of the 3rd IEEE International Conference on Computer Science and Information Technology (ICCSIT 2010),2010:465-468.
[9] Qu Kai-she,Cheng Wen-li,Wang Jun-hong. Improved algorithm based on ID3[J].Computer Engineering and Applications,2003,39(25):104-107.(in Chinese)
[10] Zhang Chun-li,Zhang Lei.A new ID3 algorithm based on revised information gain[J]. Computer Engineering & Science,2008,30(11):46-47.(in Chinese)
[11] Zhao Xiang,Qi Yun-song,Liu Tong-ming.Application of covariace and correlativity coefficient to the designing of decision trees[J].Journal of East China Shipbuilding Institute (Natural Science Edition),2003,17(5):57-60.(in Chinese)
[12] Zhang Ming-wei,Wang Bo,Zhang Bin,et al.Weighted naive Bayes classification algorithm based on correlation coefficients[J].Journal of Northeastern University(Natural Science),2008,29(7):952-955.(in Chinese)
[13] Ye Ming-quan,Hu Xue-gang.One improve decision tree algorithm based on grey relation degree[J].Computer Engineering and Applications,2007,43(32):171-173.(in Chinese)
[14] Huang Yu-da,Fan Tai-hua.ID3 algorithm for decision tree analysis and optimization[J]. Computer Engineering and Design,2012,33(8):3089-3093.(in Chinese)
[15] Sheng Zhou,Xie Shi-qian,Pan Cheng-yi.probabitity theory and mathematical statistics[M]. Beijing:Higher Education Press,2008.(in Chinese)
[16] Department of Mathematics’ Tongji University.Mathematics:Volume One[M]. Beijing:Higher Education Press,2007.(in Chinese)
[17] Han Song-lai, Zhang Hui, Zhou Hua-ping. Decision tree classification algorithm based on correlate degree function[J].Computer Application,2005,25(11):2655-2657.(in Chinese)
[18] Hu X,Cercone N.Data mining via generalization,discrimination and rough set feature selection[J].Knowledge and Information System:An International Journal,1999,1(1):21-27.
[19] Huang Yu-da, Wang Yi-ran. Decision tree classification based on naive Bayesian and ID3 Algorithm[J]. Computer Engineering,2012,38(14):41-47.(in Chinese)
附中文参考文献:
[1] 纪希禹,韩秋明,李微,等. 数据挖掘技术应用实例[M].北京:机械工业出版社,2009.
[2] 陈安,陈宁,周龙骧,等. 数据挖掘技术及应用[M]. 北京:科学出版社,2006.
[4] 王苗,柴瑞敏. 一种改进的决策树分类属性选择方法[J]. 计算机工程与应用,2010,46(8):127-129.
[5] 李孝伟,陈福才,李邵梅. 基于分类规则的 C4. 5 决策树改进算法[J]. 计算机工程与设计,2013,34(12):4321-4325.
[6] 王永梅,胡学钢. 决策树中ID3算法的研究[J]. 安徽大学学报(自然科学版),2011,35(3):71-75.
[7] 王永梅,胡学钢. 基于用户兴趣度和 MID3 决策树改进方法[J].计算机工程与应用,2011,47(27):155-157.
[9] 曲开社,成文丽,王俊红.ID3 算法的一种改进算法[J].计算机工程与应用,2003,39(25):104-107.
[10] 张春丽,张磊. 一种基于修正信息增益的ID3算法[J]. 计算机工程与科学,2008,30(11):46-47.
[11] 赵翔,祁云嵩,刘同明. 协方差及相关系数在决策树构造中的应用[J]. 华东船舶工业学院学报(自然科学版),2003,17(5):57-60.
[12] 张明卫,王波,张斌,等. 基于相关系数的加权朴素贝叶斯分类算法[J]. 东北大学学报(自然科学版),2008,29(7):952-955.
[13] 叶明全,胡学钢.一种基于灰色关联度的决策树改进算法[J]. 计算机工程与应用,2007,43(32):171-173.
[14] 黄宇达,范太华. 决策树 ID3 算法的分析与优化[J]. 计算机工程与设计,2012,33(8):3089-3093.
[15] 盛骤,谢式千,潘承毅. 概率论与数理统计[M].北京:高等教育出版社,2008.
[16] 同济大学数学系.高等数学:上册[M].北京:高等教育出版社,2007.
[17] 韩松来,张辉,周华平. 基于关联度函数的决策树分类算法[J]. 计算机应用,2005,25(11):2655-2657.
[19] 黄宇达,王迤冉. 基于朴素贝叶斯与 ID3 算法的决策树分类[J]. 计算机工程,2012,38(14):41-47.

董跃华(1964-),女,河北乐亭人,副教授,研究方向为数据挖掘、软件工程和软件测试。E-mail:4490367@qq.com
DONG Yue-hua,born in 1964,associate professor,her research interests include data mining, software engineering, and software testing.

刘力(1990-),男,湖北黄冈人,硕士生,研究方向为数据挖掘。E-mail:931667596@qq.com
LIU Li,born in 1990,MS candidate,his research interest includes data mining.
An optimized algorithm of decision tree based on correlation coefficients
DONG Yue-hua,LIU Li
(School of Information Engineering,Jiangxi University of Science and Technology,Ganzhou 341000,China)
Aiming at the problem of multi-value bias in ID3 algorithm, we propose an optimized algorithm of decision tree based on correlation coefficients. Firstly, the correlation coefficients between the attributes are introduced to improve the ID3 algorithm, and in turn the multi-value bias problem is overcome. Then the properties of Taylor formula and Maclaurin formula are adopted to simplify the information gain formula. The concrete data of examples prove that the optimized ID3 algorithm can overcome multi-value bias problem. Experiments on the standard UCI data sets show that the optimized algorithm of decision tree not only improves the accuracy of average classification, but also reduces the complexity in building decision trees and thus reduces the generation time of decision trees. Besides, the efficiency of the optimized ID3 algorithm increases significantly for large scale samples.
ID3 algorithm;correlation coefficient;decision tree;Taylor formula;information gain
1007-130X(2015)09-1783-11
2014-08-25;
2014-12-29
TP301.6
A
10.3969/j.issn.1007-130X.2015.09.030
通信地址:341000 江西省赣州市章贡区红旗大道86号江西理工大学信息工程学院
Address:School of Information Engineering,Jiangxi University of Science and Technology,86 Hongqi Avenue,Zhanggong District,Ganzhou 341000,Jiangxi,P.R.China
