数据中心网络快速反馈传输控制协议
2015-01-02苏凡军牛咏梅
苏凡军,牛咏梅,邵 清
(上海理工大学光电信息与计算机工程学院,上海200093)
1 概述
随着云计算的发展,数据中心已成为实现云计算、云存储的重要基础设施。由于数据中心可以为大型信息系统提供海量数据处理和存储服务,现今建立起了许多大型服务数据网络,如 Amazon,Google和Yahoo等大公司都拥有了自己的数据中心,且随着数据中心网络的快速发展,其服务器的数量也呈指数级增长。但是数据中心网络在实现数据中心的通信时,数据流一般具有高带宽和低延迟的特点,容易引起许多问题的出现,如拥塞通知问题、能量消耗问题以及TCP Incast问题等。针对这些问题,许多研究者们进行了研究,如卡耐基梅隆大学的PDL Project和加州大学伯克利分校的RAD Lab的2个实验项目,国内清华大学的任丰原等人对TCP Incast问题的实验研究和分析等。
为了避免TCP Incast问题造成的性能恶化,国内外已经展开了这方面的研究工作[1-3]。例如数据中心网络 TCP 协议(DCTCP)[1,4]利用了 ECN 的显式拥塞通知功能,交换机在拥塞时做拥塞标记,接收端将拥塞信息反馈给发送端,发送端估计拥塞程度从而调整拥塞窗口,但该算法存在反馈慢、拥塞估计不准确等问题。此外,还有ICTCP(Incast Congestion Control for TCP)[5]。ICTCP通过计算接收端的流量来估计链路可用带宽的变化,然后通过调节接收窗口进行速率控制。相比于传统的TCP协议,ICTCP能够有效地避免拥塞,缓解TCP Incast问题,但其应用场景很有限,只适用于很简单并且固定的TCP Incast场景。Alizadeh M等人提出了在数据中心网络链路层进行拥塞控制的QCN(Quantized Congestion Notification)算法[6],QCN 可以有效地控制链路速率,但是在TCP Incast场景下性能很差。
针对以上算法的缺点,本文提出一种可快速反馈的数据中心网络TCP协议。该协议的设计思想是交换机直接判断拥塞情况发送拥塞反馈给发送端;发送端根据反馈信息快速准确地调整拥塞窗口。最后采用NS2[7]的模拟实验对算法性能进行验证。
2 TCP Incast问题与解决方案
2.1 数据中心网络TCP Incast问题
如图1所示的“多对一”的工作模式在现在的数据中心中已经变得越来越普遍。其中,A1,A2,…,An表示数据中心的n个服务器。

图1 TCP Incast模型示意图
主机C请求的数据信息称为SRU(Server Request Unit),分别存储在各个服务器上。比如,SRU1存放在A1服务器上,为响应主机请求,各个服务器将各自的数据发送到服务器B,组成完整的SRU,再反馈给主机C。这个通信过程中,A为发送端,C为接收端。典型例子如Google利用MapReduce技术处理搜索请求[8-10]。
当这种“多对一”并发工作模式的多个发送者同时给服务器B发送数据块时,容易在服务器B处形成瓶颈,造成网络拥塞,引起瓶颈链路吞吐量急剧下降,产生大量丢包。另外,在并发传输过程中,当某个服务器发生了传送超时而其他服务器已经完成了传输,则客户端在接收到剩余SRU之前必须等待至少RTOmins。等待期间客户端的链路很有可能处于完全空闲状态,亦容易导致吞吐量显著下降且总的请求延迟急剧增加,产生吞吐量崩溃现象,这个现象就是常说的 TCP Incast问题[11-12]。
2.2 DCTCP协议原理分析
TCP Incast问题被提出后,国内外的研究者从不同角度提出了解决该问题的方案。DCTCP[1]是近年来提出的一个改进TCP协议的算法。该算法需要发送端、接收端、中间交换机三者的协作。如图1所示,交换机B检测队列长度,当队列长度大于某个阈值K时,认为网络处于拥塞状态,在数据包中做显式拥塞通知(Explicit Congestion Notification,ECN)的CE标记;接收端C收到带有ECN标记的包后,在每个反向ACK包中做ECN-echo标记;发送端收到ACK后,利用式(1)估计拥塞程度,其中,α为发送端测量被标记的包的部分,α在每一个RTT中被更新。α的值代表了缓冲区占用大于阈值K的可能性,即α接近于0表示可能性很小(缓冲区占用小)。F表示被标记的ACK在所有的ACK中的比例。发送端再按式(2)调整拥塞窗口。
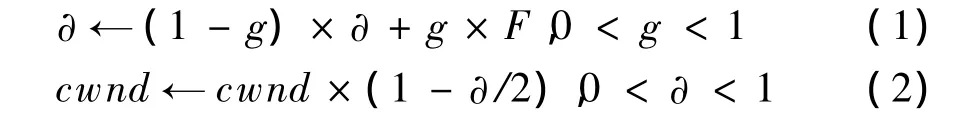
DCTCP协议比较简单,在一定程度上明显改善了TCP Incast问题。但是通过分析,其存在如下缺点:
(1)反馈慢。整个反馈过程需要交换机做标记,数据到了接收端C后,C在反向ACK中再次做标记发送到发送端An,发送端再根据式(1)估计拥塞程度,并按式(2)调整拥塞窗口。这种算法环节多,尤其是接收端主机位于普通网络中,延迟较大。
(2)拥塞估计不准确。一个原因是由于反馈信息滞后;另外一个原因是拥塞信息太简单,只是根据一个队列阈值发送单值拥塞信息。
3 FFDTCP协议
针对DCTCP存在的问题,本文提出了FFDTCP协议。如图1所示,该算法在交换机B根据当前队列长度判断网络拥塞程度后,直接将拥塞信息利用反向的ACK包发送给发送端A,发送端不需要估计算法直接根据拥塞反馈信息调整拥塞窗口,因此节省了交换机B到接收端C这段的时延。而且为了准确反馈拥塞信息,使用了3个比特位标识拥塞程度,提供了更准确的拥塞反馈。
3.1 中间交换机的快速拥塞反馈
中间交换机可以根据队列长度直接判断拥塞情况。本文假设交换机使用 RED(Random Early Detection)算法[4,8]。该算法在当前交换机、路由器中广泛实现,是基本队列算法。RED算法认为缓冲区队列长度超过一定的阈值是拥塞即将出现的征兆,故RED算法通过检测缓冲区队列长度来发现拥塞的征兆,及时采取措施来防止拥塞,这就避免了拥塞对业务性能的不利影响,同时也避免了振荡。在RED算法中,对每个队列设置2个门限 minth和maxth,avq为平均队列长度。FFDTCP新添加一个队列阈值midth,设为minth和maxth的中间值。不同的队列长度对应不同的拥塞程度,交换机在反向ACK包上做标记。这些标记使用了网络层包头保留的8 bit的区分服务字段中的3个比特位,初始值为000,标记的含义如表1所示。

表1 拥塞标记的含义
3.2 发送端拥塞窗口的调整
假设收到的拥塞程度标记值用θ表示,当发送端收到交换机发送来的反馈信息后,根据标记值的不同,按照不同的方式调整拥塞窗口:
(1)当θ=000时:如表1所示,θ=000表示网络不拥塞,因此TCP的拥塞窗口按照标准TCP的算法调整。每收到一个ACK,按式(3)增加拥塞窗口。

(2)当θ=001时:如表1所示,θ=001表示网络虽然不拥塞但是即将面临拥塞,因此保持拥塞窗口大小不变,窗口变化如式(4)所示。

(3)当θ=011时:如表1所示,θ=011表示网络处于严重拥塞状态,发送端将按照标准TCP的方式即式(5)调整拥塞窗口。

(4)当θ=010时:如表1所示,θ=010表示网络处于拥塞阶段,但是还没有严重到(3)的程度,因此:

由于这时网络拥塞程度介于(2)和(3)之间,因此 0.5≤k≤1,本文取一个中间值0.75。
3.3 发送端拥塞反馈通知
发送端收到中间交换机的拥塞通知后,为了防止中间交换机不停地发送反馈信息,可以发送一个拥塞反馈通知消息,标记值为111。交换机收到该通知后,停止发送拥塞通知。当拥塞程度发生变化的时候(比如从拥塞变为严重拥塞),再重新发送新的拥塞通知。
3.4 协议的理论分析
通过以上分析可知,FFDTCP协议相对简单,在保证低时延的情况下同时具有高吞吐量,具体特点如下:
(1)反馈迅速、准确。中间交换机通过用3个比特位判断拥塞信息可以快速地给发送端反馈。其延迟分析如下:在图1中,DCTCP时延用 λ表示,λ1为A到B的链路时延,λ2为交换机B处的排队时延,λ3为B到接收端C处的链路时延,λ4、λ5分别为反馈信息C到B和B到A的链路时延,由分析可知λ=λ1+λ2+λ3+λ4+λ5;用Ω表示FFDTCP的时延,则知道Ω=λ1+λ5;对λ和Ω进行比较,显然Ω<<λ,所以,FFDTCP能够使反馈更迅速和准确。
(2)简单。相比于DCTCP,FFDTCP算法只需要交换机判断拥塞情况,发送端不需要估计计算;另外借助拥塞确认,使交换机能够准确地收到发送端发来的确认拥塞信息,并且发送端窗口已经做了相应的调整。
(3)不额外占用网络带宽。交换机B给发送端A的反馈信息借助ACK包,从而节省了网络带宽。
4 模拟实验与结果分析
本文采用软件NS2进行模拟,模拟拓扑与图1相同(这是一个典型的数据中心网络),网络环境参数链路带宽设置为1 Gb/s,服务器请求单元为256 KB,交换机缓冲区大小分别为64 KB和128 KB,发送端分别运行普通 TCP,DCTCP,FFDTCP,每次模拟运行时间为100 s。
4.1 吞吐量分析
图2和图3为发送端分别运行普通 TCP,DCTCP和FFDTCP时的吞吐量大小比较。
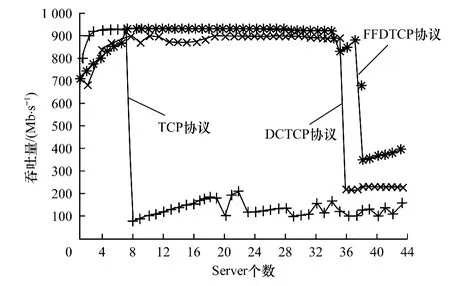
图2 缓冲区为64 KB时3种协议的吞吐量比较

图3 缓冲区为128 KB时3种协议的吞吐量比较
图2为缓冲区大小为64 KB时3种协议下的吞吐量比较。通过图2可以看出,当Server个数增大到36之前,FFDTCP一直保持着比较高的吞吐量,吞吐量在Server个数为36时有所波动,Server个数大于36时吞吐量开始急剧下降;DCTCP在Server个数约为36时就出现吞吐量急剧下降的情况;TCP在Server个数为8时吞吐量就开始明显降低了。同时可以看出当Server个数为40时,FFDTCP的吞吐量也开始急剧下降。这是由于当Server的个数增加时,即“多对一”模型中发送端数目偏大的情况下,缓冲区很快会被完全占据,造成随后的数据丢包以及数据重传,从而降低了吞吐量。但FFDTCP吞吐量下降的幅度也比DCTCP和TCP的小,最后FFDTCP的吞吐量维持在300 Mb/s~400 Mb/s之间,DCTCP维持在250 Mb/s,TCP 维持在100 Mb/s~200 Mb/s。因此当交换机缓冲大小为64 KB时,与传统TCP和DCTCP相比较,FFDTCP在吞吐量方面很好地解决了TCP Incast问题。
图3则是在交换机缓冲区大小为128 KB时进行的仿真结果。从图3可以看出,FFDTCP一直保持在900 Mb/s左右的吞吐量;DCTCP在Server超过36时吞吐量开始急剧下降;TCP在Server为16时吞吐量开始大幅度下降。可以看出在相同环境下,FFDTCP比DCTCP和TCP能保证更高的吞吐量。
从图2和图3的模拟结果中可以看出,瓶颈链路交换机缓冲区大小对解决TCPIncast问题有一定影响。在同一交换机缓冲区下,相对于 TCP和DCTCP,FFDTCP能够更好地解决TCPIncast问题。例如,在128KB的缓冲区下,当Server个数大于36时,FFDTCP仍能够保持高的吞吐量。其主要原因是FFDTCP通过中间交换机利用2个显式通知位通告4种拥塞级别,发送端可以快速准确地调整拥塞窗口,使拥塞窗口的变化不至于太激烈,加快恢复的速度;TCP在Server为16时吞吐量开始大幅度下降,主要原因是丢包导致TCP拥塞控制,发送窗口减半,降低发送速率,并且TCP拥塞控制后恢复较慢;DCTCP在Server个数为36之前能保持比较高的吞吐量,128 KB大的缓冲区起到比较关键的作用。在Server大于36时吞吐量开始大幅度下降,因为1比特位拥塞信息过于简单,使发送端不能及时准确地调整拥塞窗口。而当Server个数小于8时,3种协议吞吐量方面并无很大差异主要原因是当Server少时,总的流量小,交换机的缓冲区不容易溢出,而且缓冲区队列长度一般小于 minth(所以 DCTPC,FFDTCP检测不到拥塞),所以,3个协议的吞吐量相差不多。
4.2 时延分析
图4则为发送端分别运行普通TCP协议、DCTCP协议和FFDTCP在缓冲区为128 KB时的时延分析比较。

图4 3种协议的时延比较
由图4可以看出,当Server个数大于25时,DCTCP的时延开始增加,TCP的时延开始急剧增加。这是由于DCTCP采用显式拥塞通知功能ECN,在判断拥塞即将发生的时候,接收端通过标记反馈给发送端拥塞信息,通知即将发生的拥塞,而普通拥塞控制算法TCP是根据丢包来判断拥塞发生的。当服务器数目超过40时,FFDTCP还没有受到TCP Incast问题影响。而TCP和 DCTCP已经出现了不同程度的时延。这是由于DCTCP拥塞信息太简单,只是根据一个队列阈值发送单值拥塞信息,而且拥塞反馈慢,发送端不能及时调整拥塞窗口,从而容易造成交换机平均队列长度增加甚至缓冲溢出。而FFDTCP刚好在这方面有所改善,根据当前交换机缓冲区检测到的当前队列情况,可以发送多值拥塞信息,快速的通知发送端动态地调整拥塞窗口,让交换机队列平均长度处于一个较低的值,从而减小延时。
5 结束语
本文主要研究云计算数据中心网络中的TCP Incast问题。首先对相关背景进行介绍,包括国内外研究成果以及研究现状进行全面的综述,然后针对数据中心网络中的吞吐量急剧下降和时延问题,在研究DCTCP的基础上提出一种新的协议FFDTCP,并通过NS2仿真实验对该问题的几种解决方案进行比较分析,发现FFDTCP能够很好地解决TCP Incast问题,并能提高数据中心网络中传输协议的性能。下一步工作将增加评测的指标和环境的复杂度,并考虑增加背景流量,构建更符合实际网络的评测环境。
[1] Alizadeh M,Greenberg A,Maltz D A,et al.Data Center TCP(DCTCP)[J].ACM SIGCOMM Computer Communication Review,2010,40(4):63-74.
[2] Phanishayee A,Krevat E,Vasudevan V,et al.Measurement and Analysis of TCP Throughput Collapse in Cluster-based Storage Systems[C]//Proceedings of the 6th USENIX Conferenceon Fileand Storage Technologies,February 26-29,2008,San Jose USA.Berkeley,USA:USENIX Association,2008:1-14.
[3] Rewaskar S,Kaur J,Smith F D.A Performance Study of Loss Detection/Recovery,in Real-world TCP Implementations[C]//Proceedings ofIEEE International Conference on Network Protocols.Washington D.C.,USA:IEEE Press,2007:256-265.
[4] Alizadeh M,Javanmard A,Prabhakar B.Analysis of DCTCP:Stability,Convergence,and Fairness[C]//Proceedings of ACM SIGMETRICS Joint International Conference on Measurement and Modeling of Computer Systems.New York,USA:ACM Press,2001:73-84.
[5] Wu Haitao,Feng Zhenqian,Guo Chuanxiong,et al.ICTCP:Incast Congestion Control for TCP in Data Center Networks[J].IEEE/ACM Transactionson Networking,2013,21(2):345-358.
[6] Alizadeh M,Atikoglu B,Kabbani A,et al.Data Center Transport Mechanisms:Congestion Control Theory and IEEE Standardization[C]//Proceedings of the 46th Annual Allerton Conference on Communication,Control,and Computing,October 1-5,2008,Allerton,USA.Washington D.C.,USA:IEEE Press,2008:1270-1277.
[7] McCanne S,Floyd S.Network Simulator——NS-2[EB/OL].[2014-03-15].http://www.isi.edu/nsnam/ns/.
[8] Ghemawat S,Gobioff H,Leung Shun-Tak.The Google File System[C]//Proceedings of ACM Symposium on Operating Systems Principles.New York,USA:ACM Press,2003:29-43.
[9] de Candia G,Hastorun D,Jampani M,et al.Dynamo:AmazonsHighly Available Key-value Store[C]//Proceedings of the 21st ACM Symposium on Operating Systems Principles,October 14-17,2007,Skamania Lodge,USA.New York,USA:ACM Press,2007:205-220.
[10] 李 震,杜中军.云计算环境下的改进型Map-Reduce模型[J].计算机工程,2012,38(11):27-29,37.
[11] Vasudevan V,Phanishayee A,Shah H,et al.Safe and Effective Fine-grained TCP Retransmissions for Datacenter Communication[C]//Proceedings of SIGCOMM’09,August 17-21,2009,Barcelona,Spain.New York,USA:ACM Press,2009:303-314.
[12] Podlesny M,Williamson C.An Application Level Solution for the TCP-incast Problem in Data Center Networks[C]//Proceedings of the 19th International Workshop on Quality of Service,June 16-18,2011,San Jose,USA.Washington D.C.,USA:IEEE Press,2011:1-23.
