基于信任度的并行化社区发现算法
2015-01-02余紫丹虞慧群
余紫丹,虞慧群
(1.华东理工大学计算机科学与工程系,上海200237;2.上海市计算机软件评测重点实验室,上海201112)
1 概述
社交网络作为人类最复杂的网络之一,与其他的网络的不同之处在于,它是由多个社区组成的。社区形成的原因多种多样,但社区最重要的基础,是信任关系。信任是人类社会活动的基石,社区内的信任关系维系了社区的存在、发展。
目前社会性网络中对信任的研究还处于起步阶段,研究成果较少,鲜有提供准确计算信任度的度量方法。文献[1]提出利用FOAF(Friend of a Friend)在基于Web的社交网络中计算没有直接联系用户之间的信任度关系,但是其信任度仅有信任、不信任两种取值使其很难用于现实的社交网络环境中;文献[2]提出了在基于地理位置的社会性网络中结合链接关系与社会声誉来决策信任度的机制,但该机制只适用于特定的网络,缺乏普适性。文献[3]提出的PGP(Pretty Good Privacy)模型把信任的主动权留给用户自己,通过基于推荐者的网状信任模型来进行信任等级的判断。
然而,在PGP的信任模型内,信任链的长度最大为2,信任度衡量粒度也只有信任、不信任2种选择,难以应用在社交网络上。针对于此,目前已有不少根据信任推荐模型的社交网络信任度计算方法,例如文献[4]提出一种如何挑选可信赖用户进行信任推荐的算法。文献[5]利用节点之间的链接关系来发现2个目标用户之间的最优可信信任路径,但未考虑次要信任路经对两者信任关系带来的影响。但是,由于社交网络中用户的组织关系比较复杂,多数由PGP模型发展而来的基于信任推荐的算法,对信任推荐的路径复杂度予以回避,或者只考虑一个中间推荐者的情况,没有对存在多个中间推荐者、形成多信任推荐路径组合的情况进行考虑;又或者只能适用于小规模数量的网络。为了解决在大规模社交网络下的多信任推荐路径组合的复杂情况,必须利用并行化的计算方法,统一考虑所有信任推荐路径的情况。
Hadoop是Apache基金会基于MapReduce计算模型而完成的一个处理大规模数据的分布式系统架构。它提供了高可靠的分布式存储系统HDFS和一种分布式计算平台,用户只要实现相应的 Map、Reduce函数即可实现高性能的分布式算法,而不必过多了解底层细节。函数必须满足Map函数的输出与Reduce函数的输入类型相同。
本文根据社交网络内社区的特点,在现有的点对点之间信任模型的基础上,结合传统在P2P领域的经典算法,提出计算社交网络上用户间信任度的方法,并在此基础上进行社区扩散,最终所有节点所属社区趋于稳定,并得到最终的社区划分结果。由于计算机内存限制及算法复杂度较高,本文利用MapReduce计算框架来解决这一问题。
2 算法设计
本文是针对大规模社交网络而提出的一种并行化的基于信任度的社区划分算法,用途在于分析类似于微博这样的社交网络内部的社区结构,以帮助发现网络隐藏规律和预测变化。在此首先介绍信任度的计算方法,然后描述算法整体框架,针对框架中每个模块涉及到的MapReduce过程,给出对应设计及伪代码实现。
2.1 信任度的传播与计算
首先构建一个社会网络有向无权图G=(V,E),其中V表示顶点(用户)集合,且共有|V|=n个用户节点,E表示用户有向关系的集合,eij表示连接vi,vj2个顶点的边。若eij=1,则说明节点vi到节点vj之间存在着一条边,也就说明用户i对用户j进行了关注,用户i对用户j有一个信任关系。
目前关于社交网络内的信任及其一些特性并没有权威的定义,本文首先对信任作如下假设:
假设1一个用户节点在初始时,共有总和为1的信任额度,且平均分配给其所有关注着的用户;
假设2任意2个用户之间的信任度,是由他们之间的所有信任推荐路径决定的。一条路径上的信任度会逐渐衰减,多条信任路径上的信任度会叠加。
根据这两条假设,易得如下推论:
推论1若用户i对用户j进行了关注,而用户i共关注了个用户,则i对j的初始信任度为:
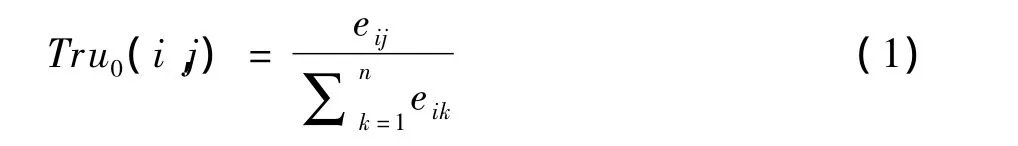
特殊的,不考虑用户自己对自己的信任情况,即Tru0(i,i)=0。
推论2信任度能以2种方式传播:串联,并联。串联会随着中间节点的增加而衰减,以图1中第1种传播方式为例,得到用户1对用户4的信任度为:
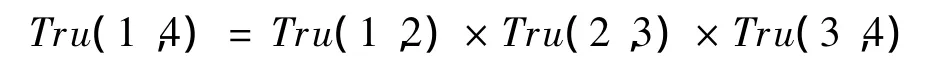
并联会导致信任度随着路径的叠加而增加,以图1中第2种传播方式为例,得到用户1对用户8的信任度为:

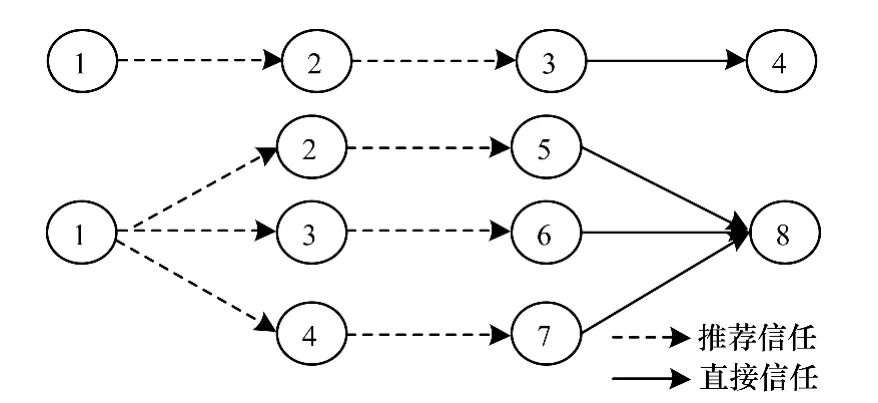
图1 信任度传播方式
所以,对于任意2个节点,必须先找到这2个节点之间所有可能的信任推荐路径,然后再根据串行、并行的不同给出信任度最终结果。
然而,在真实的社交网络中,信任推荐路径并不是可以任意长度的,根据六度分隔理论,人们最多通过5个中间人就能互相认识,事实上,现实世界中的信任随着信任链的长度的增长而迅速衰减[6]。本文假设信任推荐路径的长度最大为4,也就是最多经过3个中间人的信任推荐是有效的。尽管对路径长度的限制缩小了信任推荐路径的可能性,但针对任意2个用户,通过深度优先搜索,来穷尽他们的所有可能的信任推荐路径,从算法复杂度来讲是不可取的。
对于之前描述的社交网络图而言,若将该网络G分成k份,分别为k个节点集合φ={N1,N2,…,Nk}。若该划分具有对于每个Ni∈φ,都满足Ni内的节点信任链密集、与Ni外信任链稀疏的特性,则称φ为G的基于信任链的社区划分。
从上面关于信任度的概念可以知道,最初始的信任度矩阵只与图的邻接矩阵有关,由于邻接矩阵为:
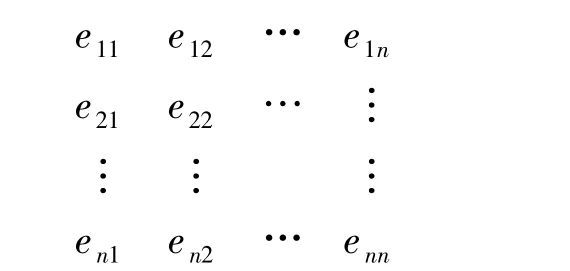
因此可以得到初始信任度矩阵为:
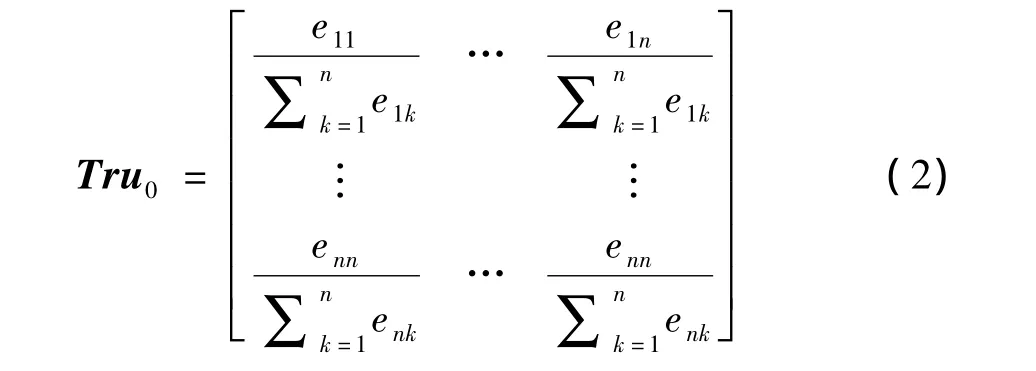
接下来考虑存在着一个中间推荐者来进行信任度间接传播的情况,用户 i,j,考虑经过节点{1,2,…,n}信任链路径,可得:
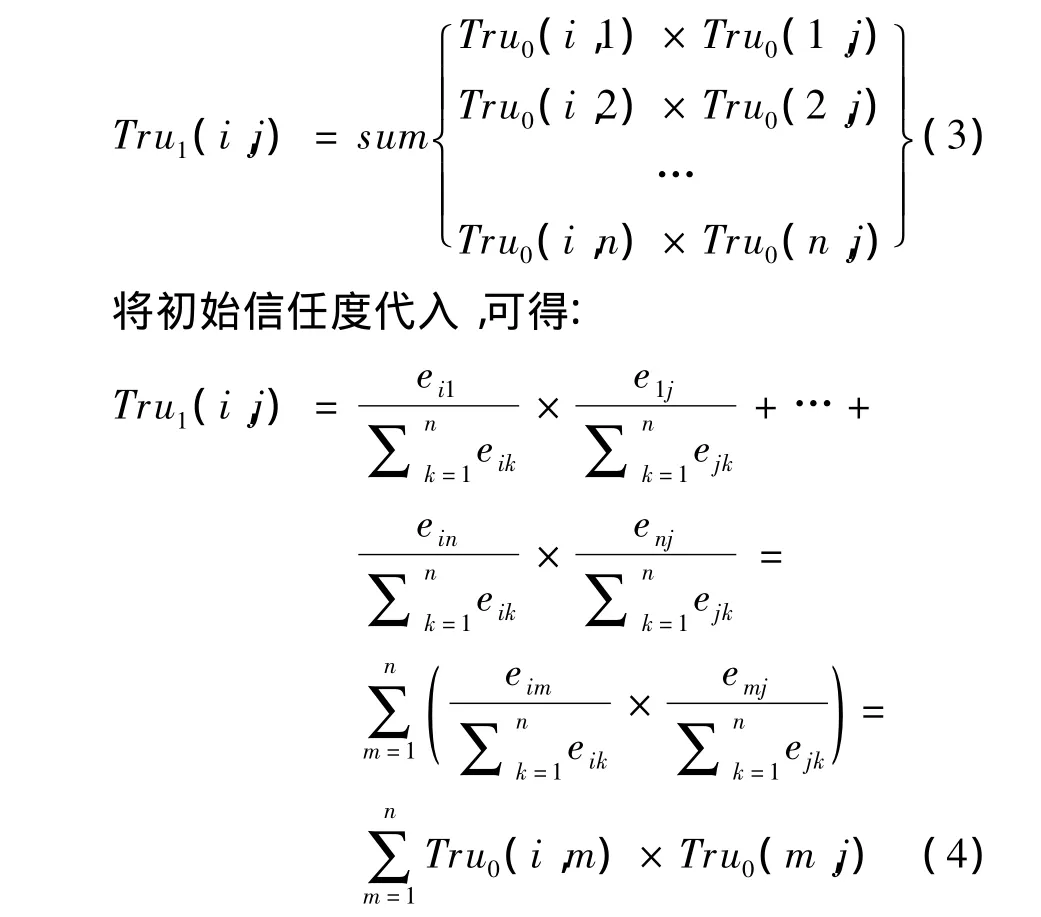
这等价于2个初始信任度矩阵相乘后的矩阵上[i,j]元素,直观的角度来看,初始信任度表示了用户之间的信任关系,可以画成一个二部图,而当2个初始信任度矩阵相乘时,可以将这样的信任传播过程可以画成如图2所示的三部图。Tru1(i,j)的几何含义,便是节点i到节点j之间所有可能的信任推荐路径上的权值之和。类似的,若考虑用户i,j存在着2个中间推荐者来进行信任度间接传播的情况,则如图3所示。
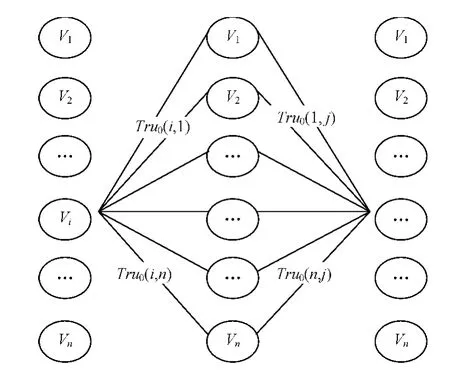
图2 初始信任度矩阵相乘时形成的传播图

图3 存在2个中间推荐者时的信任传播图
用户i,j需要寻找2个中间节点来做信任推荐,可以得到:
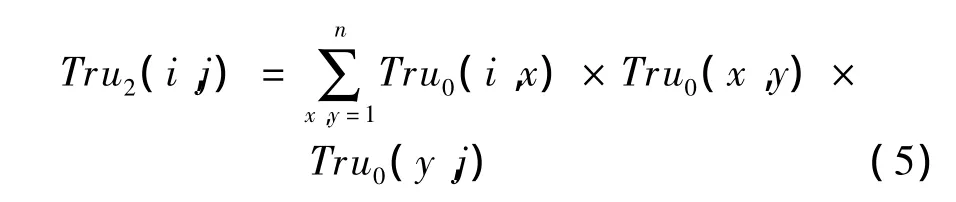
这等价于3个初始信任度矩阵相乘后的矩阵上[i,j]元素。
以此类推,可以得到:Truk=(Tru0)k+1。
这样,就得到了最终的信任度计算公式:
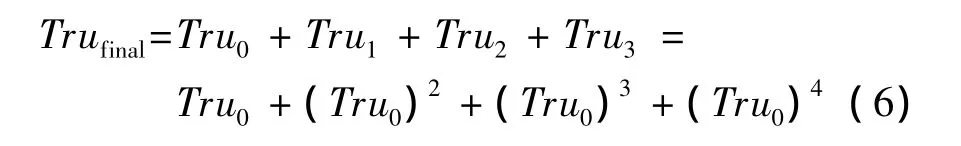
这样,问题就从路径搜索问题,转换为大矩阵相乘问题。
2.2 算法整体框架
在得出如何求解任意2个用户之间的信任度后,给出如下的算法框架,对基于信任度的并行化社区算法予以描述。
如图4所示,该算法首先通过用户之间的关注关系构造初始信任度矩阵,并且通过信任度的两种传播方式来更新信任度矩阵,然后在最终形成的信任度矩阵上,通过社区标签的迭代扩散,得到最终的社区划分矩阵。
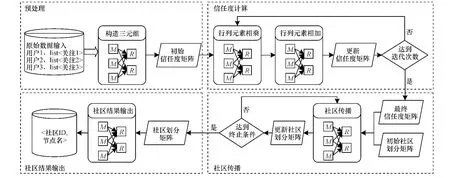
图4 算法整体框架
图4中M和R表示MapReduce过程中的Mapper和Reducer。下面对这4个步骤的算法作简要说明。
2.2.1 数据预处理模块
一般从社交网络上得到的数据是以<User ID,follower 1,follower 2,…>这样的格式存储在文本中的,每一行都是一个用户及他所关注的所有对象。社交网络的矩阵维度一般在千万级别,其内部十分稀疏。故利用MapReduce并行化处理文本,转为初始信任度矩阵,采用三元组存储。伪代码如下所示:

2.2.2 信任度更新模块
信任度矩阵公式本质是大矩阵的乘法运算,参考文献[7]及式(7):
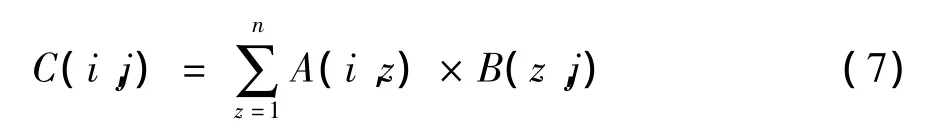
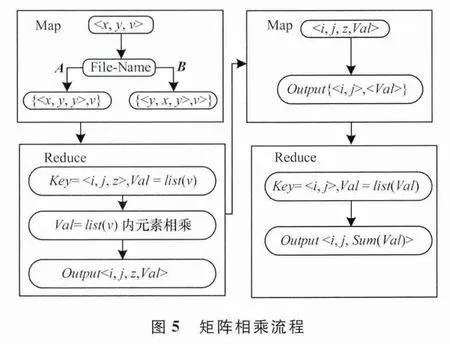
给出一种大规模矩阵乘法算法,通过2轮MapReduce,在第1轮中,将矩阵A的行元素与矩阵B的对应列元素相乘,在第2轮中,将相乘的结果累加起来,形成更新后的信任度矩阵。大规模矩阵乘法的流程如图5所示。
在这样的矩阵乘法基础上,给出如下伪代码,以进行信任度矩阵的迭代计算,并通过累加,得到最终信任度。

2.2.3 社区传播模块
在得到用户两两之间的最终信任度后,这里给出一种社区划分的算法,首先赋予每个节点一个独立的社区id,在每一轮迭代时,每个节点的社区id由其信任的那些节点决定,信任度越大对该节点的影响越大。通过这样的社区id更新,相互信任度较高的节点集合会迅速对社区id达成共识,形成社区。每轮迭代只依赖于上一轮的社区id分配结果,利用三维数组<User id,Community id,w>将社区分配存储下来,w是用户被分配到该社区的强度,初始值为1,在迭代过程中与信任度相乘,并更新。若每一条数据分配12个字节,可以表示三维数组每维范围为[1~232],足以记录千万用户数量级时的社区分配情况,在数据规模千万级时需要百兆级别的内存,故可以在每轮迭代前将用户的社区id分配结果放在内存中,通过get-Social-Id(User id)这样的方法读取。然后在Mapper端计算一个节点所有可能的社区id,并更新其对应的权重,在Reducer端完成对社区id的选择,当各用户的社区id分配稳定后(更改社区id的用户数量小于用户总数n×10-3)循环终止,在得到最终的社区id分配,并将其输出。用户节点更新社区id的伪代码如下:

2.3 算法分析
算法采用信任度推荐者模型迭代计算任意2个用户的信任度,然后在此基础上采用社区传播的方式进行社区划分,相较于传统的直接在网络关系图上进行图聚类的算法而言,本文算法在第一轮的迭代过程中,加强了簇内用户之间链接关系,而在第2轮的迭代过程中,处在簇内中心位置、与周围信任度都较高的节点,会迅速将簇标签信息(社区ID)传播到整个簇内用户节点,使得社区结构自然地呈现出来。
本文算法的复杂度,主要取决于迭代过程中计算大矩阵乘法的复杂度。通过针对矩阵乘法设计的伪代码可知,若令No[Ai]代表矩阵A的第i行中非零值的个数,则本文所用稀疏矩阵相乘算法的时间复杂度为,与矩阵的实际稀疏程度相关。
3 实验与结果分析
3.1 实验环境及实验数据
本文实验在由10个节点组成的Hadoop集群上进行,集群中每台机器硬件环境相同,配置信息如表1所示。

表1 集群基础配置
清华大学唐杰教授通过随机抽取100个新浪微博用户,抓取他们的关注者和粉丝,并最终发布了一个有1 787 444个用户节点、308 489 739条关注关系的社交网络数据[8]。
此外,还有一些经典的小型社交网络数据集[9],Zachary数据集为美国一所大学的空手道俱乐部成员间关系的网络;LesMis数据集为《悲惨世界中》人物关系网络;Dolphin数据集为62只海豚组成的种群中,各成员交流频度的社交网络[10]。
3.2 精准度对比
首先在数据集上证明本文算法划分社区的准确性,针对各类数据集,应用本文算法与传统的Label-Propagation算法、Random-Walk算法和 Fast-Greedy算法进行实验[11],以证明本文算法社区划分的准确度。这3种传统算法均是针对单机环境设计完成的。由于Random-Work算法需要计算任意2个节点之间的距离,而Fast-Greedy算法需要迭代计算整体网络图的模块度值,随着节点数目的增加,这2种算法导致的时间耗费越来越大,在面对大规模微博数据集时,不能够在有限的时间内完成。相对的,LP算法由于有着接近线性的时间复杂度,不需要计算复杂的优化公式,因而在微博数据集下,只令本文算法与LP算法进行比较。
社区划分并无准确的判断标准,现行的常见做法是采用Q函数[11]来评判社区的质量,具体结果如表2所示。由实验结果可知,本文算法在Q函数评价标准下,较LP,RW,FG算法而言,有着更好的社区划分效果。
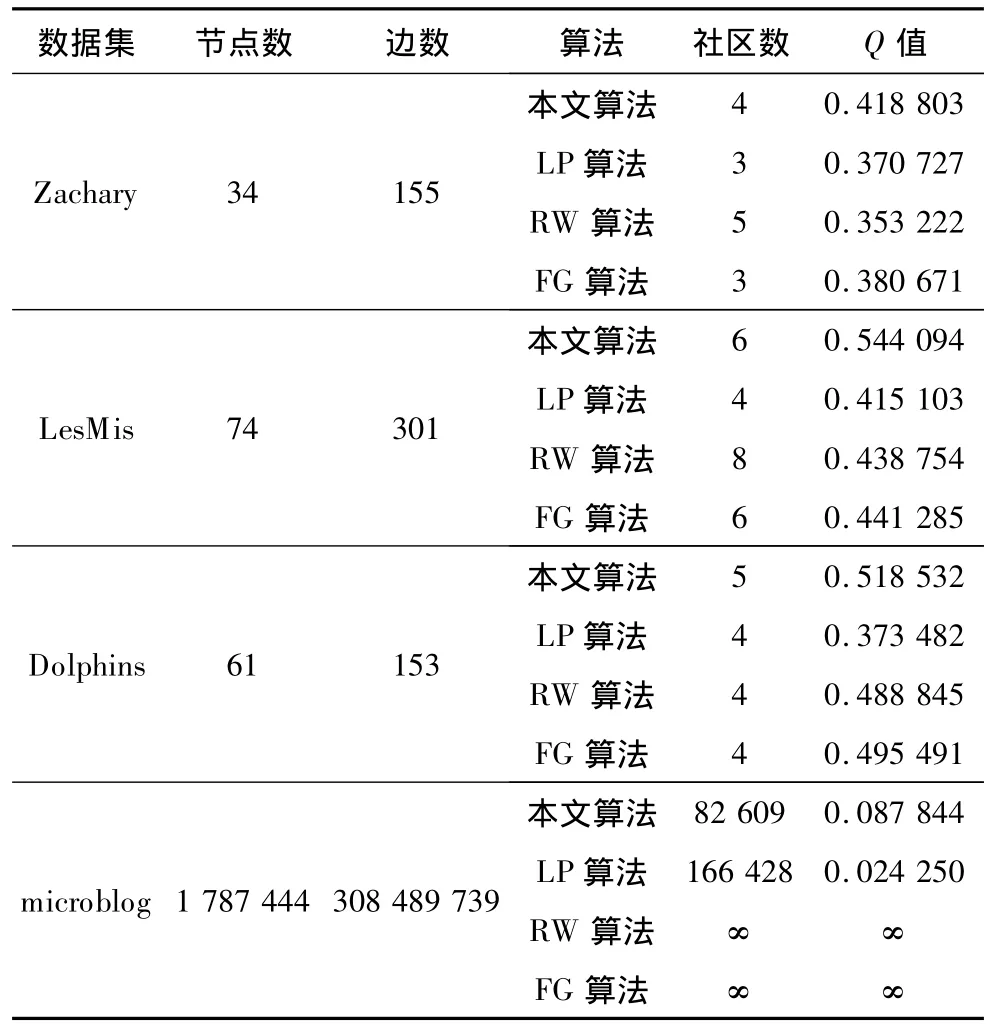
表2 各数据集上实验结果比较
3.3 可扩展性
3.3.1 运行时间随数据集大小的变化
将微博数据集上所有的节点分为10份,每轮实验分别输入1份 ~10份数据,观察算法随数据规模变化所耗费的时间,实验结果如图6所示。其中,输入数据比例=输入数据量/总数据量。
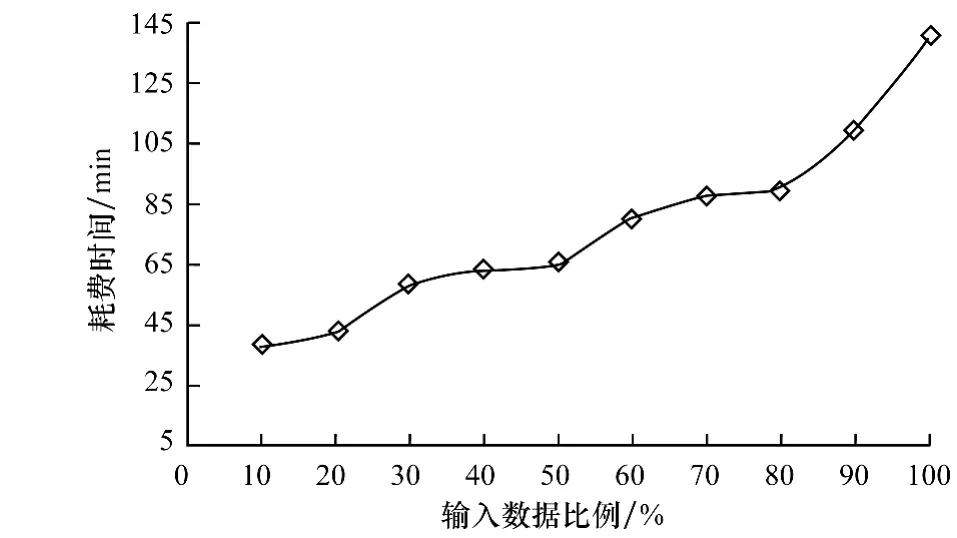
图6 不同输入数据量下算法执行时间
实验结果表明,本文算法在千万规模的数据集上,未存在计算时间急剧增多的问题,有较强的处理大规模社交网络的能力。
3.3.2 运行时间随节点数目的变化
将集群机器的数目改变,观察算法运行时间与机器数量的关系。
从图7可以看出,随着机器数目的增加,算法的运行时间相应减少,这证明算法有很强的可扩展性。从上面的分析中可以看出,本文算法无论是在算法效率还是所得社区模块度上都要明显好于基准算法的效果,原因在于本文在第一步迭代信任度的过程中,加强了不直接相邻节点相互关联的潜在信息,避免直接进行社区扩散时可能导致的局部最优问题,取得了较好的结果。
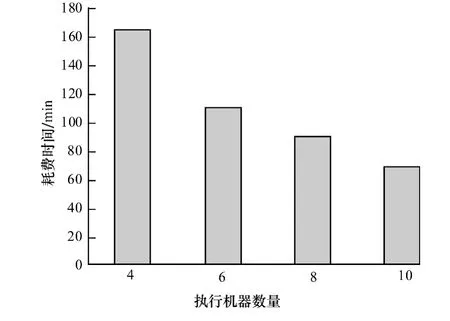
图7 不同执行机器数目下算法执行时间
4 结束语
本文设计并实现了一种并行化的社区发现算法。该算法首先参考PGP算法里的推荐者信任模型,提出一种根据链接关系计算用户之间信任度的方法,并在此基础上,进行社区扩散,将处在社交网络潜在社区内中心位置、与周围信任度都较高的节点的社区ID传播到整个潜在社区中,得到社区划分的结果。本文还利用了Hadoop集群对算法进行并行化设计,使得算法具有较好的可扩展性。在数据集上的实验结果表明,本文算法既在准确度上有所提高,也有处理大规模社交网络的能力。然而,在真实的社交网络中,可能还存在着重叠部分,本文的算法无法适用于社区重叠的情况,需要作进一步的改善。
[1] Jennifer G,James H.Inferring Binary Trust Relationships in Web Based Social Networks[J].ACM Transactions on Internet Technology,2006,6(4):497-529.
[2] Symeonidis P,Ntempos D,Manolopoulos Y.Locationbased Social Networks[M]//Symeonidis P,Ntempos D,Manolopallos Y.Recommender Systems for Location-based Social Networks.New York,USA:Springer,2014:35-48.
[3] Zimmermann P.Pretty Good Privacy User’s Guide[Z].1993.
[4] Jiang W,Wu J,Wang G.RATE:Recommendation-aware Trust Evaluation in Online SocialNetworks[C]//Proceedings of the 12th IEEE International Symposium on Network Computing and Applications.Washington D.C.,USA:IEEE Press,2013:149-152.
[5] Liu G,Wang Y,Orgun M A,et al.Finding the Optimal Social Trust Path for the Selection of Trustworthy Service Providersin Complex SocialNetworks[J].IEEE Transactions on Services Computing,2013,6(2):152-167.
[6] 田俊峰,鲁玉臻,李 宁.基于推荐的信任链管理模型[J].通信学报,2011,32(10):1-9.
[7] Buluc A,GilbertJR.ParallelSparse Matrix-matrix Multipli-cation and Indexing:Implementation and Experiments[J].SIAM Journal on Scientific Computing,2012,34(4):170-191.
[8] Zhang Jing,Liu Biao,Tang Jie,et al.Social Influence Locality for Modeling Retweeting Behaviors[C]//Proceddings of IJCAI’13.Menlo Park,USA:AAAI Press,2013.
[9] Fortunato S.Community Detection in Graphs[J].Physics Reports,2010,486(3):75-174.
[10] Lusseau D,Newman M E J.Identifying the Role that Animals Play in Their Social Networks[J].Proceedings of the Royal Society of London Series B-biological Sciences,2004,271(6):477-481.
[11] 杨 博,刘大有,刘际明,等.复杂网络聚类方法[J].软件学报,2009,20(1):54-66.
