基于Ceph的分布式存储节能技术研究
2015-01-01沈良好吴庆波杨沙洲
沈良好,吴庆波,杨沙洲
(国防科学技术大学计算机学院,长沙410073)
1 概述
能耗管理是数据中心面临的重要挑战。一方面,随着基础架构规模的扩大,数据中心需要为日益剧增的能源消耗买单,在数据中心总体总拥有成本(Total Cost of Ownership,TCO)中,用于能源的费用已经成为重要的组成部分。另一方面,随着数量的增加与规模的扩大,数据中心所消耗的能源,在整个社会能源消耗中所占的比重也越来越大,据统计,全球数据中心在2010年对电能的消耗超过了2×1011千瓦时,约占全球总用电量的1.3%,且呈逐年上升的趋势在数据中心的组件中,存储系统是能源消耗主要来源之一,仅次于计算资源,约占30%。因此,降低存储系统的能耗是达到数据中心节能目的的重要手段。近年来,存储系统节能技术受到了广泛关注,从单个磁盘到磁盘阵列,再到分布式存储,均出现了大量的研究工作[2-5]。
分布式存储是目前大部分数据中心所采用的存储形式。作为近年热门的分布式存储,Ceph[6]因具备了高扩展性、高性能、高可靠性的特点,而备受关注。因此,本文基于开源项目Ceph,进行分布式存储系统节能技术的研究。本文的工作主要有:以节能为目的的Ceph数据布局优化;多级功耗管理策略;功耗管理框架的设计与实现。该框架结合了上述数据布局优化方法、多级功耗管理策略以及硬件的节能功能,实现了Ceph分布式存储的动态功耗管理。
2 相关工作
分布式存储系统的节能技术近年来受到了广泛的关注,是存储领域热门的研究方向之一。
微软剑桥研究院的Thereska E等人设计并开发了Sierra[7]分布式存储系统,该系统使用了能耗感知的数据布局和基于负载预测的节点状态管理,在系统低负载时,关闭部分节点,从而增加系统的能源利用率。为保证系统的容错能力以及数据的一致性,Sierra使用了分布式虚拟日志(DVL)技术。经过测试,该系统在作为Hotmail和Windows Messenger服务的后端存储时能够节省23%以上的能耗,且性能的损失相当微小。
UIUC的Kaushik R等人基于标准的HDFS提出了其节能的衍生版GreenHDFS[8]。在GreenHDFS中,数据节点最初被划分为热区和冷区,处于热区的数据(约70%)有着更高的访问频率,所以为保证性能,热区的节点是一直处于活跃状态的;而冷区的数据(约30%)使用率非常低,所以冷区的节点将会进入省电模式。一个自适应的划分策略用来动态地指定节点所属的区,并使得冷区节点能够达到一定的数量,进而增加整个集群节能的程度:在Yahoo的一个真实负载环境中,GreenHDFS在3个月的测试时间内,节省了26%的能耗。
此外,针对Ceph分布式存储的节能技术也受到了关注,文献[9]提出了一种Ceph OSD(对象存储设备)的自适应的磁盘降速算法。该算法针对单个OSD,在其低负载时降低所对应的磁盘速度,进入节能状态。他们的工作针对的只是部分OSD上磁盘的节能,所以对整个系统能耗的影响十分有限。
3 数据布局优化
分布式存储中的数据放置算法及其产生的数据布局是影响系统可靠性、扩展性的重要因素之一。Ceph存储系统基于CRUSH算法的数据布局是其具备可靠性、高性能、高扩展性的基础,但同时也限制了系统节能的能力。
3.1 Ceph数据布局
作为Ceph存储的关键技术之一,CRUSH算法由Weil S A于2006年提出[10]。CRUSH基于伪随机的哈希算法产生确定的均匀的数据分布。CRUSH有多个输入,包含了对象id,Crushmap和放置规则。其中,对象id一般用于区别需要存放的数据对象,实际运行时对象会被映射到不同的放置组(PG),所以作为输入id的实际是PG的id。Crushmap描述了数据节点的层级关系,用树形结构表示,包含bucket和device类型的节点,其中bucket节点可以包含其他类型的bucket和device节点,通常用于描述故障域(failure domain),如主机、机架、机柜等,把副本分布于不同故障域,是Ceph保证数据可靠性的重要措施;而device节点只能作为叶子节点,表示对象存储设备(OSD)。放置规则用于指定副本放置的策略,包含了take,select,emti等语句,其中select可以指定副本个数和副本放置的故障域。在一个包含4台主机的集群中,副本分布策略为:select(2,host),即数据的2个副本放置于不同的主机上,则通过CRUSH算法产生的数据布局如图1所示。
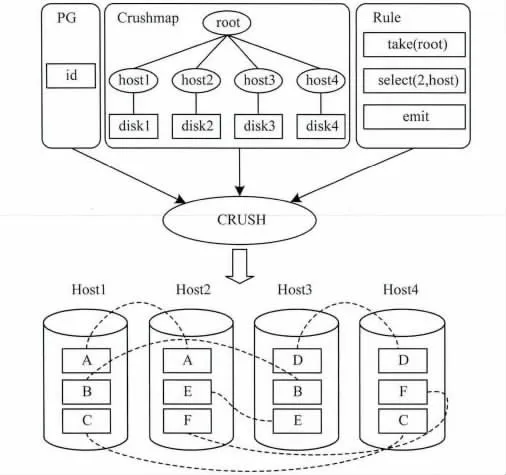
图1 Crush算法数据布局
3.2 存储系统存在的不足
很多应用场景中都存在低负载时期,此时,为了节省系统的能耗,可以关闭部分数据节点。出于以下考虑,关闭节点时应保证数据全集是可用的(即任意的数据对象至少有一个以上副本是未被关闭的):一方面,如果发生不可用数据的访问,则会产生非常大的访问延迟;另一方面,频繁开启相应的节点会产生不可忽视的额外能耗。在Ceph存储系统中,数据节点数为N,被划分为n个故障域fd,副本分布策略为select(r,fd),则在系统低负载系统时期最多可以关闭的故障域的个数为n'<r,因为任何大于或者等于r个故障域的组合中,必然包含了某些数据的所有副本。如图1中,可以关闭的主机个数为1台,当关闭2台以上主机时,A个~F个数据块必然有一个无法访问。随着集群规模的增加,最多只能关闭r-1个故障域的节点,可以达到最大节能比例为(r-1)/n,当集群规模较大时,节能的效果微乎其微。
3.3 节能优化
结合CRUSH的特性,在Crushmap中引入了功耗组(PowerGroup)的bucket,用于对故障域集合进行再次划分,即数据副本在放置于不同故障域前,将首先被分布于不同的功耗组。同一个功耗组的节点处于相同的能耗状态,功耗组的个数等于副本个数r。优化算法的描述如下:

以图1中场景为例,则经过优化的数据布局如图2所示。
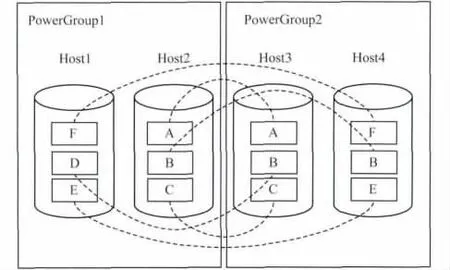
图2 优化后的数据布局
此时,可以关闭的节点为2个,且所有数据仍然可用。经过优化的数据布局中,数据的副本分别位于r个不同的功耗组中,在保证数据集可用的情况下,则最多可以关闭r-1个功耗组的节点,系统能够达到的节能比例为r-1/r,当集群规模较大时,节省的能耗是非常可观的。同时,由于很好地实现了副本的分布,可以关闭的功耗组个数可以是1~r-1的任何一个,从而为系统的多级功耗管理提供了基础。
4 多级功耗管理
基于对数据副本分布的优化,使得系统中活跃的功耗组个数可以根据系统I/O负载的情况按需调整,让系统处于不同的功耗级别,从而实现系统的多级功耗管理,减少能耗。
4.1 多级功耗模型
在Ceph中,系统的主要能耗来自于OSD节点。在一个包含n个OSD节点的Ceph集群中,副本个数设置为r,经过数据布局优化后,节点被划分至r个功耗组,若单个OSD节点的功耗为p,则单个功耗组的功耗为:
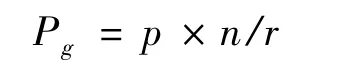
系统中活跃(未关闭或休眠)的功耗组个数为ractive,则系统功耗为:
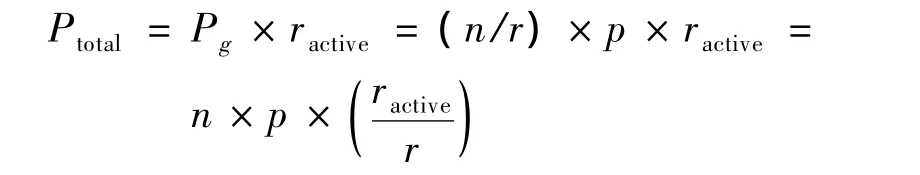
其中,ractive的取值可以为1~r,即系统可以处于P1,P2,…,Pr不同的功耗级别。在一段时间T内,系统所消耗的能耗为:

其中,ti是系统处于相应功耗级别的时间;Et是系统用于级别切换所消耗的能耗之和。
4.2 功耗级别管理
功耗级别管理的主要任务是根据I/O负载状态动态调整功耗级别,在保证服务质量的同时,尽量减少功耗。I/O负载状态可以通过统计分析或者预测的方式确定,本文采用的是前者,即收集并统计系统在一定时间内的I/O数据如I/O次数、I/O数据量等,并以此确定系统的I/O负载状态。为描述不同场景下的I/O负载状态,需要对随机I/O和顺序I/O都进行收集与统计,因此,在可配置的时间窗口W内,对系统的I/O状态数据可统计为:
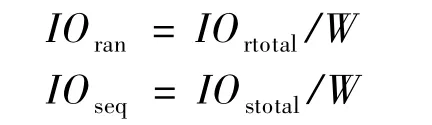
其中,IOrtotal为W时间内发生的随机I/O的次数;IOstotal为W时间内顺序I/O请求的数据量。两者分别与预先测得的系统峰值I/O能力对比,得出系统I/O状态的量化描述,即I/O负载率L:
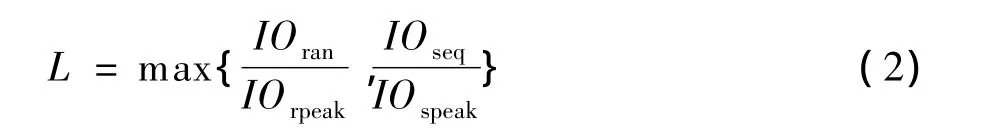
其中,L被用于与当前功耗率Pl=ractive/r比较,确定系统下一阶段所处的功耗级别:当系统的I/O负载率高于能耗率时,活跃的功耗组已经不能满足I/O负载的要求,需要更多的功耗组提供服务;当系统的I/O负载率低于能耗率时,则系统中有部分功耗组可以被关闭,以达到节能的目的。功耗级别确定的伪代码为:

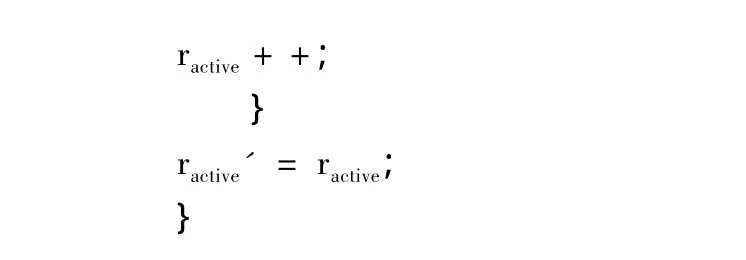
输出的ractive'将作为下一个W时间段内的系统所处的功耗级别,此时需要关闭/开启的功耗组的个数为|ractive'-ractive|。为保证系统的高可用性,可以设置允许的最少活跃的功耗组个数为2,即允许系统数据副本至少有2个是可用的。
5 系统实现与实验评估
基于第3节、第4节所述的优化方法,结合Ceph自身技术特点,本文设计并实现了一个能耗管理框架,并进行了实验评估。
5.1 系统架构
如图3所示,该功耗管理框架由4个模块组成,其中Layout Optimizer模块实现针对CRUSH的数据布局的优化算法,并生成新的Crushmap和放置规则;I/O Tracer模块用于跟踪与统计系统的I/O数据,即以一定的频率采集分析Ceph Log中的I/O相关信息记录;Lever Shifter则是管理系统功耗级别的模块,根据跟踪统计到的I/O数据,分析当前系统的I/O负载状态,基于所选择的的策略确定是否需要切换功耗级别;Status Manager模块负责功耗级别切换的执行,首先利用Ceph的OSD状态管理工具设置OSD在Ceph集群中的状态为noout,保证不会因主动停止OSD而发生数据迁移,接着通过远程休眠/网络唤醒(WOL[11])等技术控制OSD所在的服务器电源管理状态,基于休眠/唤醒的方式比传统的关闭/开启服务器的方式更为节能,式(1)中用于级别切换的能耗对系统的总能耗的影响几乎可以忽略不计,且响应时间更短。
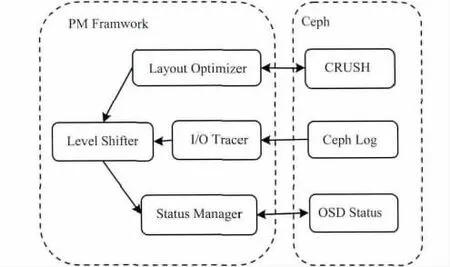
图3 系统架构
5.2 实验评估
在一个有6个OSD节点的Ceph系统中进行了该功耗管理框架的实验评估。Ceph版本为0.80.5,操作系统为Kylin3.2,每个节点上配置一个OSD,副本策略为select(3,host)。为模拟不同的负载场景,用fio[12]测试工具进行测试。
如图4所示内容为连续8 h测试(级别切换的超时时间设置为10 min,通过thinktime参数使得系统约4 h处于低负载时期)中,系统分别处于各能耗级别的次数。
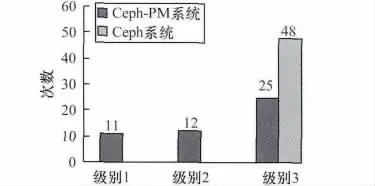
图4 系统所处功耗级别的次数
在未使用节能框架时,系统运行8 h的能耗约为48×6×10 min×400 W,在开启了节能框架(Ceph-PM)后,系统运行8 h的能耗约为(11×2+12×4+25×6)×10 min×400 W,系统达到的节能比例约为25%,如果系统规模增大,节省的能源开支将会非常可观。但需要注意的是,在真实环境中,系统负载的变化可能更为频繁、剧烈,所以需要更精确、复杂的负载级别切换策略,这也是本文未来的工作内容之一。
图5、图6描述的是系统在低功耗状态下对随机I/O和顺序I/O的响应时间的影响,总体上,读操作平均响应时间有略微变化,但不会太大地影响服务质量。
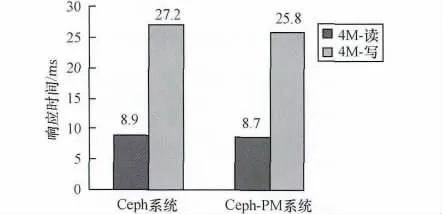
图5 随机I/O的平均响应时间
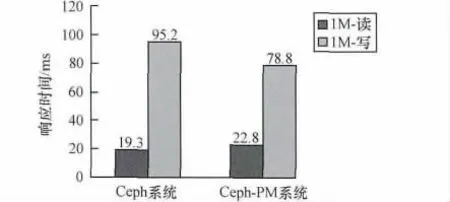
图6 顺序I/O的平均响应时间
而写操作时,由于低功耗状态下需要写副本的次数变少,对于客户端来说,响应时间反而更小一些,且对于顺序写影响更为明显。
6 结束语
本文基于Ceph系统,研究分布式存储技术,分析基于CRUSH算法的数据布局存在的不足,提出以节能为目的的优化算法和系统多级功耗管理策略,并实现了Ceph的多级功耗管理框架。实验结果表明,该能耗管理框架能够根据系统负载变化动态地调整系统功耗级别,有效地降低系统能耗。
[1]Koomey J.Growth in Data Center Electricity Use 2005 to 2010[EB/OL].(2011-10-11).http://www.analytic spress.com/datacenters.html.
[2]Gurumurthi S,Sivasubramaniam A,Kandemir M,et al.DRPM:Dynamic Speed Control for Power Management in Server Class Disks[C]//Proceedings of the 30th Annual International Symposium on Computer Architecture.San Diego,USA:IEEE Press,2003:211-219.
[3]李海东.磁盘阵列节能技术研究与实现[D].武汉:华中科技大学,2009.
[4]Verma A,Koller R,Useche L,et al.SRCMap:Energy Proportional Storage Using Dynamic Consolida-tion[C]//Proceedings of FAST’10.San Jose,USA:USENIX Association,2010:148-155.
[5]廖 彬,于 炯,孙 华,等.基于存储结构重配置的分布式存储系统节能算法[J].计算机研究与发展,2013,50(1):3-18.
[6]Weil S A,Brandt S A,Miller E L.Ceph:A Scalable,High-performance Distributed File System [C]//ProceedingsofOSDI’06.Seattle,USA:USENIX Association,2006:269-277.
[7]Thereska E,Donnelly A,Narayanan D.Sierra:Practical Power-proportionality for Data Center Storage[C]//Proceedings of EuroSys ’11.Salzburg,Austria:ACM Press,2012:153-161.
[8]Kaushik R T,BhandarkarM.Greenhdfs:Towardsan Energy-conserving, Storage-efficient, Hybrid Hadoop Compute Cluster[C]//Proceedings of USENIX Annual Technical Conference.Boston,USA:USENIX Association,2010:159-167.
[9]Bisson T,Wu J,Brandt S A.A Distributed Spin-down Algorithm for an Object-based Storage Device with Write Redirection[C]//Proceedings of the 7th Work-shop on Distributed Data and Structures.Santa Clara,USA:ACM Press,2006:459-468.
[10]Weil S A,Brandt S A,Miller E L,et al.CRUSH:Controlled, Scalable, Decentralized Placement of Replicated Data[C]//Proceedings of 2006 ACM/IEEE Conference on Supercomputing.Tampa,USA:ACM Press,2006:367-378.
[11]Wake-on-Lan[EB/OL].(2013-10-10).http://en.wiki pedia.org/wiki/Wake_on_lan.
[12]Fio[EB/OL].(2013-10-10).http://freecode.com/pro jects/fio.
