基于联合定价模型的奖惩因子的扩展与比较
2015-01-01谢远涛李政宵
谢远涛,李政宵
(1.对外经济贸易大学 保险学院,北京100029;2.中国人民大学 统计学院,北京100872)
一、引 言
在非寿险产品定价过程中,保险公司通常需要考虑两类风险信息:一类是已知的风险特征信息,如保单持有人的性别、职业以及居住地等。对该类风险信息的定价通常使用分类费率厘定技术。由于分类信息中并没有保单潜在的风险信息,会导致同一风险类别下个体风险并不完全同质,分类费率厘定就会出现偏差,这就需要第二类风险信息,即潜在的个体风险信息对保费进行调整。个体风险信息通常包含在保单经验索赔数据中,保险公司不仅需要根据费率因子厘定分类费率,还需考虑保单经验索赔数据,这样保费具有合理性。
信度理论源于20世纪初,主要用于解决保单分类时出现的风险异质性问题。信度理论认为预期保费是个体风险与整体风险的加权平均值,权重表示为信度因子[1]。信度理论的发展主要分为两个方向:Bühlmann信度和贝叶斯信度。仅当风险参数服从自然共轭分布时贝叶斯信度预测值才表现为线性形式,因此贝叶斯信度被称为最大精度信度[2];Bühlmann信度模型利用非参数统计的思想,在均方误差最小的约束条件下推导出线性信度估计量,该线性信度估计值可以作为贝叶斯信度的渐进估计值,因此也被称为最大精度信度[3]。
作为经验费率厘定的重要方法,信度理论只考虑了个体风险信息,却忽略了费率因子对保费的影响。因此,保险公司通常使用广义线性模型进行风险分类,计算出分类费率,再根据经验索赔信息进行费率调整。广义线性模型与信度模型分别利用保单已知的风险特征信息和经验信息进行风险划分,但这两类风险特征信息通常呈现出高度相关性。运用广义线性模型划分的高风险保单,经验索赔次数通常较高;划分的低风险保单,经验索赔次数通常较低,因此会造成风险信息的重复利用,使保险公司对低风险的保单收取过低的保费,而对高风险保单收取了过高的保费,从而产生了“重复奖惩”的问题[4]。
为了能够更好地制定公平费率,Frees将线性混合模型用作联合定价模型。Frees认为信度模型是线性混合模型的特例,在正态分布假设下它们的预测结果是等价的[5]。线性混合模型的固定效应用于描述保单已知的风险,信息随机效应用于描述保单个体的风险信息。线性混合模型以正态分布为基础,但保险数据通常服从厚尾分布或离散型分布,其联合定价方法往往缺乏稳健性。国外联合定价领域的主流研究是以线性混合模型或者广义线性混合模型为基础[6]。国内相关研究较少,王明高、孟生旺扩展了线性混合模型的残差正态分布假设,改善了联合定价的预测结果[7]。考虑到信度模型与广义线性混合模型的隐含关系,可以将信度模型与广义线性混合模型结合,但目前学术界还没有相关文献证明结合后的联合定价模型的优越性,也没有相关理论支持预测值具有信度模型的特性[8]。因此,联合定价方法在非寿险定价的运用仍未取得实质性进展。
本文放宽了随机效应的正态分布假设,对索赔次数的广义线性混合模型基本假设进行修正,将信度模型与广义线性混合模型相结合,提出了一种扩展的联合定价模型。扩展的联合定价模型的预测值不仅具备信度模型的“收缩估计”,还可以表示成奖惩系统因子的形式。实证研究表明,扩展的联合定价模型能够更好地解决“重复奖惩”的问题。
二、模型设定
(一)基本假设
本文将信度模型嵌套入广义线性混合模型的框架,建立联合定价模型。首先考虑具有n份保单的风险组合,每份保单之间相互独立,每份保单都包含T年的索赔次数的观测值。第i份保单在第t年的索赔次数用随机变量[Yit:i=1,2,…,n;t=1,2,…,T]来表示。保险公司在制定保费时通常使用广义线性模型,假设索赔次数在风险参数 (Θi=θi)给定条件下服从指数分布族,其密度函数表示为:
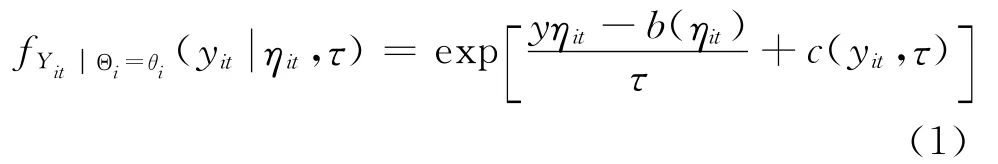
其中τ为离散参数,ηit为自然参数。
索赔次数的均值和方差可以表示为:

其中v(·)为方差函数。
通过连接函数可以建立均值与费率因子之间的关系,通常使用对数连接函数,故有:

其中expβT(x)表示第i份保单在观察期t的平均索赔频率的预测值。如果两份保单具有相同的费率结构,索赔频率具有相同的预测值,但实际上保费会因保单个体风险的差异而略微不同。对于费率结构相同的保单制定相同的费率将不再合理。
为了使模型(3)的预测更加准确,需要引入随机效应ui描述不同保单的个体风险差异。第i份保单的均值表示为:

本文将模型(4)称之为联合定价模型。如果随机效应ui服从均值为0的正态分布,即ui~,则联合定价模型本质上就是广义线性混合模型,但广义线性混合模型作为联合定价的方法存在较大的缺陷,即保单组合的总平均索赔频率的预测值μ仍然是随机效应ui的函数,总平均索赔频率仍然会受到保单个体风险的影响。
为了消除个体对总平均索赔频率的影响,本文对模型(4)进行修正,对随机效应施加约束条件:,得到扩展的联合定价模型。在约束条件下,模型(4)中的随机效应将服从非中心的正态分布,即)。这种特殊假设可以使模型对总平均损失的预测值为,对个体保单的损失预测值为,即个体保单的损失预测值可以表示为对总平均损失预测值的比例调整,调整因子为eui。该假设保证总平均损失不随个体风险改变,使保险人对相同费率结构的人收取恒定的先验保费,以确保先验定价的合理性和公平性。
(二)扩展的联合定价模型的构建
下面将模型(4)与信度模型结合,对下一期的索赔次数Yi,T+1进行预测。在广义线性混合模型框架下,用固定效应表示费率因子,随机效应表示个体风险之间的差异,索赔次数的期望与方差有下述形式:
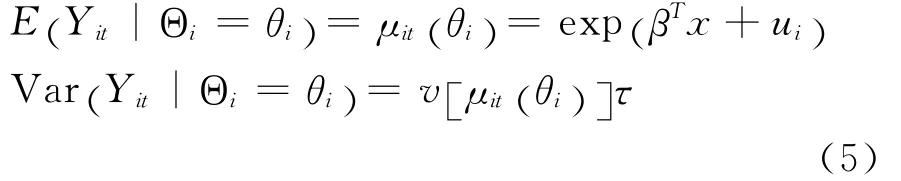

并在下式最小化的条件下求解未知参数:

在Bühlmann信度模型中,只需给出随机变量的一阶矩和二阶矩,在非参数估计的思想下就能得到信度预测值和相应的信度因子。本文将信度模型与广义线性混合模型相结合,求解相应的信度预测值与信度因子的显式解。
对损失函数L关于cit求导并令其等于零,可得式(8)和式(9)所示的方程:

将式(5)的期望与方差形式带入式(8)和式(9),整理得到:

在ci1=ci2=…=ciT:=ci的假设下,结合式(5)和式(10)即得:

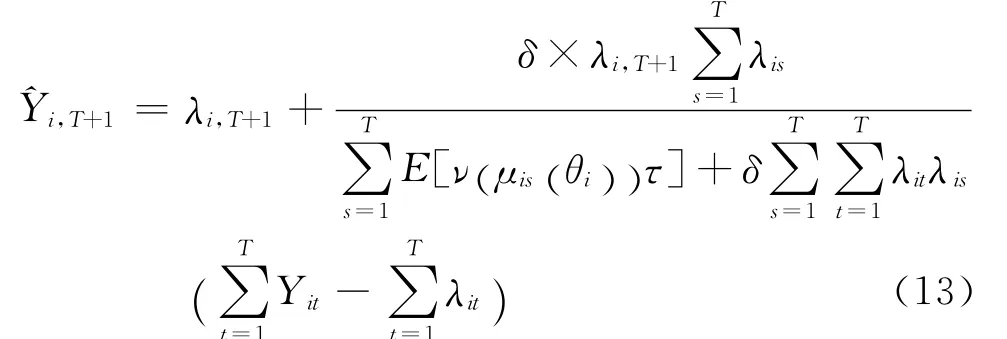
其中信度因子为:
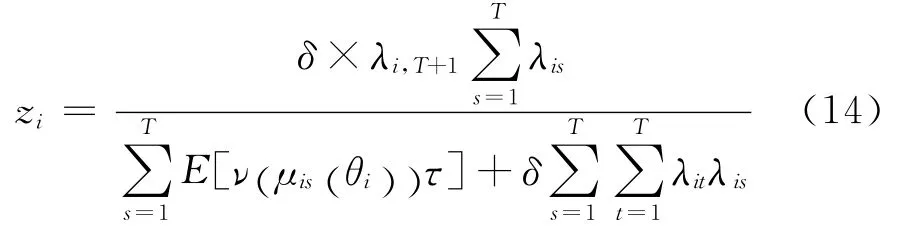
(三)奖惩因子形式
为了进一步验证扩展的联合定价模型的优势,本文将引入奖惩系统因子。在泊松分布的假设下,扩展的联合定价模型的预测值可以简化为奖惩系统因子的一般形式。
假设索赔次数服从泊松分布,即Yit~Possion(),密度函数表示为:

索赔次数的期望和方差可以简化为:
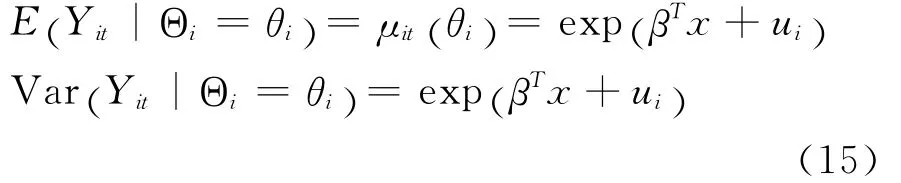
将式(15)代入式(13),预测值可以改写为更简洁的形式:
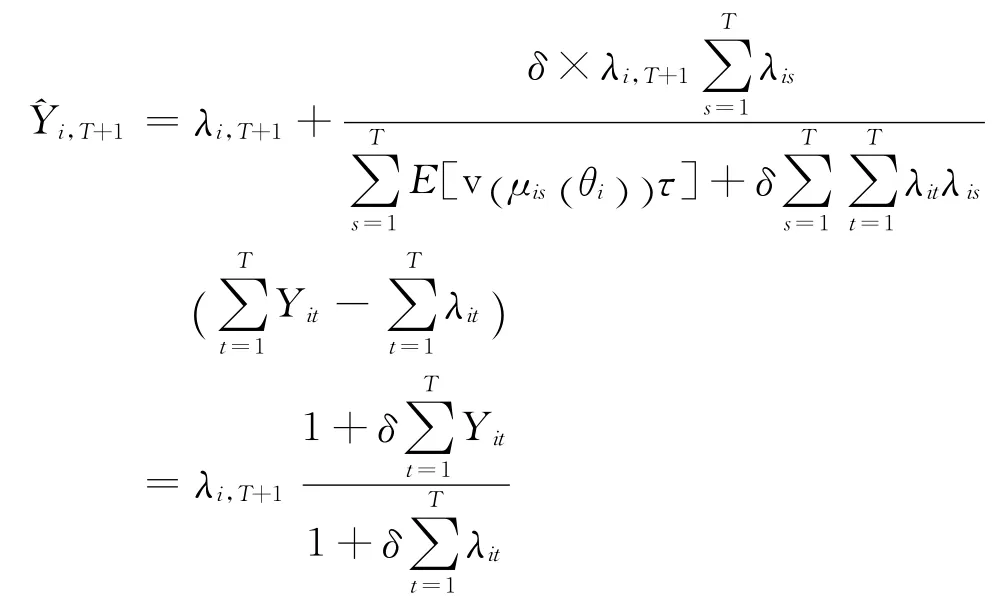
上式两边同时除以λi,T+1,得到奖惩因子的一般表达式:
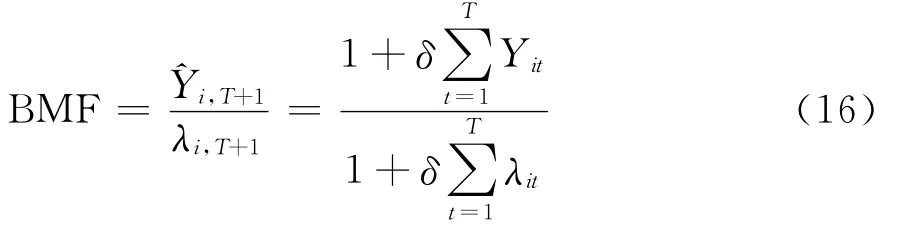
奖惩因子同时考虑了保单的费率因子结构和经验损失信息,并具备如下性质:其一,当保险事故发生次数超过总预测值时,奖惩因子大于1,保单持有人将受到惩罚,下期缴纳相对较多的保费;当个体保险事故发生次数少于总预测值时,奖惩因子小于1,保单持有人享受保费折扣优惠,下期缴纳相对较少的保费。其二,奖惩因子受到随机效应波动性的影响。在联合定价模型中,随机效应用于描述个体保单的风险差异,个体风险之间差异越小,奖惩因子值越小,保单持有人获得保费折扣的概率越大。其三,奖惩因子还受到费率因子的影响。相比于Bühlmann-Straub信度模型的奖惩系统因子,扩展的联合定价模型同时考虑了费率因子和个体风险特征的影响。
三、扩展的联合定价模型参数估计
(一)泊松-对数正态模型的参数估计
当随机效应服从正态分布时,扩展的联合定价模型退化为泊松-对数正态联合定价模型。此时,为了得到奖惩因子的预测值式,需要估计^δ和^λit。^δ的估计值与随机效应ui的指数化后的方差有关,^λit的估计值与固定效应的估计值有关。对固定效应与随机效应的估计沿用了广义线性混合模型的参数估计方法。基于联合密度函数的对数似然函数,可以表示为:

考虑到上式包含积分项,实际计算比较困难,需要采用近似算法或数值积分算法获得未知参数的极大似然估计值,通常使用的一种方法是Adaptive Gaussian Quadrature 法[9]。 例 如,SAS 软 件 的NLMIXED模块,该方法求得的似然函数值还可以用于似然比检验。
(二)泊松-伽马模型的参数估计
若随机效应经过指数变换后服从伽马分布,即exp(ui)~Gamma(α,α),扩展的联合定价模型退化为泊松-伽马联合定价模型。随机效应呈非正态分布时既有软件无法处理,考虑泊松-伽马模型的后验分布服从负二项分布的特殊性质,本文先用SAS软件中的GLIMMIX模块拟合负二项分布并估计参数,然后利用方差与期望的特性,反过来估计伽马分布的α参数。给定了某样本,其对数似然函数的贡献为:


其中,参数为负二项分布的散度参数。在参数估计中,本文使用了Miller在文献中使用的扩展的广义估计方程(eGEE)方法[10]。
四、实证研究
下面应用一组车险索赔次数数据进行实证分析。数据总体包含了国外某保险公司40 000张保单在3年期间的索赔次数数据。表1展示了保单持有人的年龄和车辆价值两个费率因子,其中年龄为分类变量,包含10个水平;车辆价值也为分类变量,包含6个水平。
假设索赔次数服从泊松分布,分别建立单独定价模型与联合定价模型。单独定价模型首先运用广义线性模型拟合索赔次数,得到索赔频率的总平均预测值,见式(3);然后运用信度模型,结合经验索赔次数,对索赔频率的预测值进行调整。联合定价模型是直接运用式(4)进行模型拟合,运用式(16)进行预测。扩展的联合定价模型的均值表示为:

其中若随机效应ui随保单编号改变而改变,若ui服从正态分布N(-σ2/2,σ2),联合定价模型就扩展为泊松-对数正态联合定价模型;若exp (ui)服从伽马分布Γ(α,α),联合定价模型就扩展为泊松-伽马联合定价模型。

表1 数据说明及符号表示
随机抽取10个保单样本,比较联合定价与单独定价模型奖惩因子的预测值,见表2。从整体趋势分析,索赔记录为0的保单奖惩因子远远小于1,当发生1次保险事故后,奖惩因子变动到1之上,说明该保单因发生保险事故缴纳了额外的保费,发生2次保险事故的保单受惩罚程度大幅增加;比较费率结构相同的保单6和7,当历史索赔次数由0增加到2时,单独定价下的奖惩因子远远高于联合定价下的奖惩因子,说明单独定价模型确实存在过度惩罚的现象(见表2)。
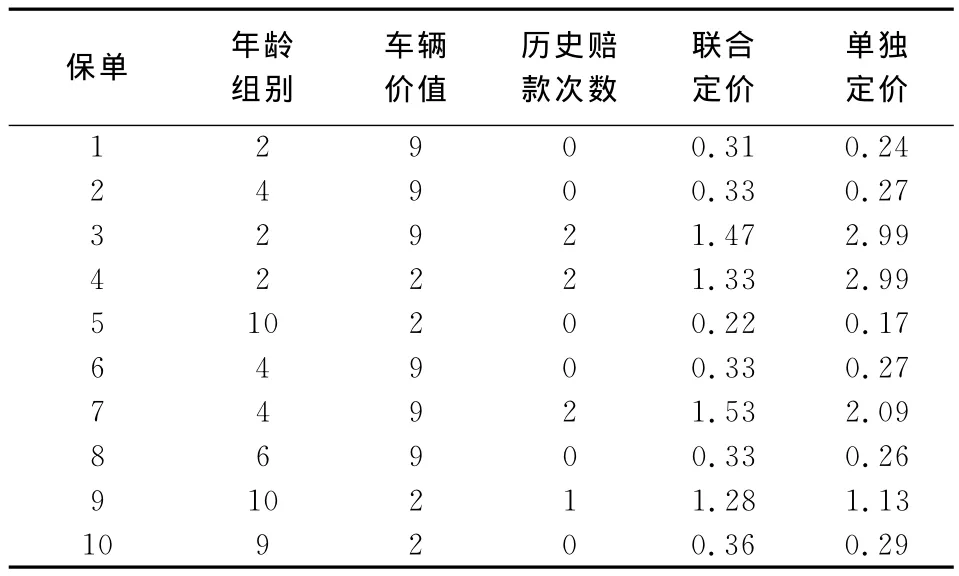
表2 奖惩因子预测值表
本文将奖惩因子大于1的保单归为高风险,将奖惩因子小于1的保单归为低风险。图1比较了随机抽取的30个样本的奖惩因子的预测值。对于同质性的高风险保单,联合定价下的奖惩因子预测值高于单独定价的奖惩因子,原因在于单独定价的保单重复利用了先验风险特征信息与经验索赔信息,而对于同质性的低风险保单,两种方法下对奖惩因子预测结果差异不大。以上联合定价模型是在随机效应服从正态分布的假设下的预测值,即泊松-对数正态模型。实证结果表明,扩展的联合定价模型(泊松-对数正态)能够更好地解决对高风险保单的“过度惩罚”问题,但处理低风险保单的“重复奖惩”问题并没有预想的充分。

图1 联合定价与单独定价模型的奖惩因子比较图
基于此,本文将扩展的联合定价模型(泊松-对数正态)扩展到联合定价模型(泊松-伽马),调整后的奖惩因子预测值见图2。联合定价模型(泊松-伽马)的奖惩因子在高风险区域与联合定价模型(泊松-对数正态)的高风险区域重复性较高,认为以上两种联合定价模型在处理高风险类别时,都能够解决“重复惩罚”问题。联合定价模型(泊松-伽马)在低风险区域的奖惩因子更接近1,认为联合定价模型(泊松-伽马)能更好地解决“重复奖励”问题。从模型本质分析,联合定价模型(泊松-对数正态)实质是随机效应服从对数正态分布下的估计值,联合定价模型(泊松-伽马)实质是随机效应服从伽马分布的估计值。在联合定价模型中,由于随机效应表示的是保单个体风险特征,伽马分布比对数正态分布更适合于描述保单的个体风险信息。
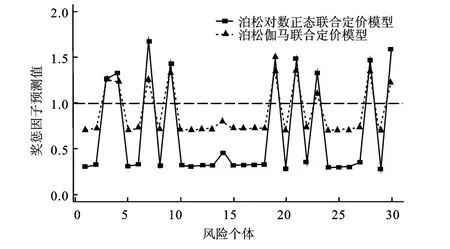
图2 联合定价模型(泊松-对数正态)和联合定价模型(泊松-伽马)预测值图
表3比较了几种联合定价模型的拟合效果。扩展的联合定价模型无论在AIC、对数似然值还是均方误差下都优于广义线性混合模型。其中联合定价模型(泊松-伽马)的预测均方误差低于联合定价模型(泊松-对数正态),认为联合定价模型(泊松-伽马)的拟合度更高,误差更小。由于保险赔款次数通常具有过离散性,联合定价模型(泊松-伽马)本质上可以等同于负二项分布,在处理过离散的保险数据的方面效果较好,得到的奖惩系统有更大的实用价值,同时也验证了孟生旺的结论[4]。

表3 联合定价模型预测精度表
此外,扩展的联合定价模型的奖惩因子还具有信度模型“收缩估计”的性质。图3比较了扩展的联合定价模型和Bühlmann-Straub模型的信度因子估计值,图4显示了奖惩因子在整体均值与经验均值之间“收缩”。单独定价模型的信度因子整体偏大,原因在于Bühlmann-Straub信度因子只考虑经验损失数据对奖惩因子的影响,即信度因子赋予经验索赔信息的权重较高。联合定价模型事先对保单进行风险分类,根据同类风险划分风险单位,继而再考虑个体历史索赔信息对保费的调整作用,实质上信度因子赋予经验信息的权重降低,预测风险类别的信息增加,这为联合定价提供了更为合理的解释。

图3 扩展的联合定价与信度模型信度因子比较图
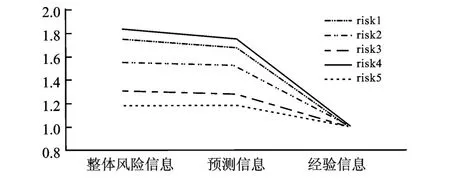
图4 联合定价模型的收缩效应图
为了防止本研究过分依赖数据,本文使用了Bootstrap技术重抽样1 000次,每次抽取初始样本的80%进行密集实验。为了重点关注尾部,每次实验都筛选出信度因子大于1.5或小于0.5部分(以单独定价模型为基准)进行显著性检验。每次抽样对单独定价模型、广义线性混合模型、联合定价模型(泊松-对数正态)和联合定价模型(泊松-伽马)的双尾数据进行F检验。1 000次抽样检验中F检验显著的有927次,按照二项分布来构建检验,伴随概率<0.000 1,因此认为4个模型之间的差异具有显著性。综合奖惩因子进行分析,认为本文构建的模型确实有利于解决“重复奖惩”问题,联合定价模型(泊松-伽马)下的奖惩因子效果更佳。
五、结 论
广义线性混合模型作为联合定价中的常用的模型,能够解决单独定价模型存在的风险信息重复叠加的问题,但是随机效应满足均值为零的正态分布的假设,会造成对个体保单的费率估计有偏,预测误差偏高。在广义线性混合模型的基础上,通过扩展随机效应的假设,引入信度模型,就能得到本文中扩展的联合定价模型。该模型将信度模型中隐含的正态分布假设扩展到泊松分布,对索赔次数的描述与预测更加合理。
扩展的联合定价模型根据随机效应假设的不同,可以分为联合定价模型(泊松-对数正态)和联合定价模型(泊松-伽马)。研究发现,联合定价模型(泊松-对数正态)能更好地解决“过度惩罚”问题,但在解决“过度折扣”问题上表现并不明显。若将随机效应扩展到伽马分布,泊松-伽马模型下的奖惩因子能更好地解决“过度奖惩”问题,且预测精度和拟合效果都优于其他模型。
扩展的联合定价模型还具有信度模型的“收缩效应”,本文从理论和实证上都证明了联合定价的估计值写成信度因子形式具有必然性。联合定价模型在进行费率厘定研究中的另外一大优势是,能通过选择不同的随机效应协方差矩阵来刻画风险单位之间的相关性,这也是今后需要继续研究的一个方向。
[1] Whitney A W.Theory of Experience Rating[C].Virginla Proceedings of the Casualty Actuarial Society,1918(4/5).
[2] 谢远涛,王稳,谭英平,等.广义线性混合模型框架下的信度模型分析[J].统计与信息论坛,2012(10).
[3] Bühlmann H.Experience Rating and Credibility[J].Astin Bulletin,1967,4(3).
[4] 孟生旺.考虑个体保单风险特征的最优奖惩系统[J].数理统计与管理,2013,32(3).
[5] Frees E W,Young V R,Luo Y.A Longitudinal Data Analysis Interpretation of Credibility Models[J].Insurance:Mathematics and Economics.1999,24(3).
[6] Antonio K,Beirlant J.Actuarial Statistics with Generalized Linear Mixed mModels[J].Insurance:Mathematics and Economics,2007,40(1).
[7] 王明高,孟生旺.基于贝叶斯偏态线性混合模型的费率厘定[J].统计与信息论坛,2015(1).
[8] 康萌萌,孟生旺.基于MCMC模拟和伪似然估计法的交叉分类信度模型费率厘定[J].统计与信息论坛,2014(2).
[9] Pinheiro J C,Bates D M.Approximations to the Log-Likelihood Function in the Nonlinear Mixed-Effects model[J].Journal of computational and Graphical Statistics,1995,4(1).
[10]Miller M E,Davis C S,Landis J R.The Analysis of Longitudinal Polytomous Data:Generalized Estimating Equations and Connections with Weighted Least Squares[J].Biometrics,1993,49(4).
[11]De Jong P,Heller G Z.Generalized Linear Models for Insurance Data[M].London:Cambridge University Press,2008.
