各省人力资源状况研究
2014-12-30范艳玲
范 艳 玲
(中北大学 理学院 数学系,山西 太原 030051)
0 引言
近年来,可持续发展的战略性思想已深入人心,其中区域经济的可持续发展则是其中的重中之重.而人力资源是推动经济走上可持续发展轨道的原动力,是现代经济增长和发展的决定性因素,因此关注人力资源的投资、形成和积累,促进人的全面发展,已逐渐成为政府关心的焦点问题之一[1].
人力资源状况是指一个国家或地区在某一时间段内能够投入社会经济活动的劳动人口状况.虽然我国人力资源的总量非常丰富,但是各省市的人力资源的总体状况却各不相同.目前国内学术界对我国局部区域内人力资源的研究较为充分,但是对各省市的人力资源状况的对比研究尚且较少[2-5].本文就是要考察各项人力资源指标在不同地区的差异以及隐藏在这种差异背后的经济现象与规律.
本文通过主成分分析法,同时采用聚类分析,计算出了我国31 省市的人力资源状况的总体得分,结合不同分析得出的结论来描绘出人力资源分布的地域类别特征.
1 人力资源指标体系的构建
本文主要从人力资源的投资和人力资源的存量两个方面进行考察,来构建人力资源的主要评价指标体系.
从人力资源投资角度来看,人力资源投资将从教育水平、教育设施、科技投资、医疗保健和劳动力迁移5个方面来进行衡量;其中教育水平方面的代表性指标包括人均教育支出X1、教育经费支出占GDP 的比重X2和从事教育行业的人口比重X3;教育设施方面的代表性指标包括公共图书馆个数X4和总藏书量X5;科技投资方面的代表性指标包括R&D 支出占GDP 的比重X6、R&D 项目数X7和R&D 人员全时当量X8;医疗保健方面的代表性指标包括每千人口医院和卫生院床位X9、每千人口卫生技术人员数X10和人均医疗保障费X11;劳动力迁移方面的代表性指标主要是职业介绍机构数X12.
从人力资源的存量角度来看,将从人力资源的知识水平、技能状况、健康水平和行业从业人员数量这4个方面来进行衡量;其中知识水平方面的代表性指标主要是平均受教育年限X13;技能状况方面的代表性指标包括科学技术人员数X14、就业人员大专及以上学历比例X15和2009年专利授权数X16;健康水平方面的代表性指标包括人口平均预期寿命X17、人口出生率X18、人口死亡率X19和自然增长率X20;从业人员方面的代表性指标包括第二产业从业人员比例X21和第三产业从业人员比例X22.
2 人力资源的样本聚类实证分析
2.1 数据来源及其处理
本文根据中国统计年鉴(2010)的数据[6],选取了我国31 个省(自治区、直辖市)作为分析样本,得到了人力资源和人力资源存量的指标数据.
由于实际数据的单位往往不一致,因此对数据进行无量纲化处理,即对数据进行标准化处理,使得数据的均值为0,方差为1.然后采用主成分分析方法对人力资源状况指标进行描述,再采用综合评价的方法得到各个省市的人力资源状况的综合得分.
2.2 提取主成分
按照上述步骤,本文用SAS9.2[7-8]进行数据处理,得到的结果如表1 所示.

表1 相关矩阵的特征值
从表1 可以看出,原始数据中提取前5 个主成分特征值的累积总方差贡献率已达到85.19%,可以用这5个主成分来代替原来的22 个指标对各地区的人力资源状况进行衡量,从上表中,我们还注意到,最后一个主成分的特征值为0,可以认为最后一组变量的观测值是无用的,它完全包含在了前21 组变量中了.这一点也可从第22 组变量的贡献率为零来得出.因此,选择舍弃第22 组变量的观测值.
本文将用5 个主成分对数据进行分析.第一主成分为:
上式中,第一主成分中的变量系数为其所对应的特征向量的分量.其中,(i=1,2,…21)为标准化变量.同样我们可以写出第二主成分为:
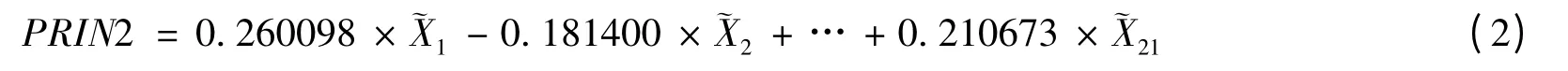
其余主成分可类似给出.
2.3 主成分的命名
根据前5 个主成分所对应的特征向量,给出了各个主成分的名称,第一主成分命名为“综合性成分”;第二主成分命名为“科技投资和劳动力迁移”成分;第三主成分:人口基础和财政支持;第四主成分:文化性因素;第五主成分:很难给出明显的解释.
2.4 人力资源状况数值的计算
为了给出具体的人力资源状况的计算公式,首先用SAS 软件求出每个主成分的值,每个主成分的权重以各自的方差贡献率占总体累积贡献率的比重来确定,进而得到各个省市人力资源状况的综合得分公式:

将5 个主成分的值代入式(3),即可求出我国31 省市人力资源状况的总体评价值,如表2 所示.

表2 我国31 省市区人力资源总体状况得分及排名
2.5 我国人力资源总体水平的地域聚类分析
为了便于分析各省市的人力资源状况的相同点和不同点,更加确切地描述我国的人力资源状况,在综合评价的基础上,本文利用5 个主成分做进一步的聚类分析.聚类方法采用系统聚类法,类间距离采用类平均距离,以欧氏距离平方法作为样品之间的距离进行聚类,将31 省市分为3 类或者5 类较为合适,本文中将其分为5 类进行聚类研究,最终得出了分为5 类时的聚类结果.

表3 分为5 类时的聚类结果

表4 分为5 类时的聚类结果的对比
第1 类中,涵盖了东部、中部和西部地区的14 个省区,其中河南、四川等人口大省在人口总量上的优势较为明显;河北、湖北、福建、陕西和黑龙江等省在科技投资和劳动力迁移指标上占据明显优势地位,其按第二主成分排序知,它们的得分都较高;中部九大省市当中,山西、内蒙、重庆、安徽、江西、湖南六省市在5 个主成分上的得分都较为均衡,但人力资源总体水平处于中等偏后的位置.
第2 类中,包括广西、海南、贵州、云南、甘肃、青海、宁夏和新疆8 个地区,其中贵州、云南和甘肃在教育投资、医疗保健和劳动技能方面得分较大,优势明显;青海、宁夏、新疆和广西在第三主成分上的优势明显;宁夏和新疆还在第四、第五主成分上的得分值都很大,但由于衡量总体水平的第一主成分的值很低,所以其总得分和排名均处于落后的地位,人力资源开发的任务最为艰巨.
第3 类中,山东是我国的人口大省,历来也是我国的人才大省,近年来,山东省在其人才大省的基础上,加大了科技投资,其在第二主成分中的表现占优,使得其优势地位不断加强;天津和辽宁地区由于开发历史悠久,地理位置优越,劳动者的文化素质较高,技术力量较强,工农业基础雄厚,所以其人力资源水平也有不俗的表现;江苏、浙江和广东等沿海发达地区,这三个省份在衡量人力资源水平的各项主成分中其得分都很高,因此,其总得分和排名均靠前列,但是在人口持续能力第五主成分上的值得分不高,尤其是江苏和浙江其人口持续能力排名均靠后,又展现出了人力资源发展的不足.
第4 类中有北京和上海两个地区,北京地区在总体各项主成分中占据优势地位,其各项人力资源潜能已能得到较好的利用,并逐步转化为人力资本投入到经济社会的发展之中;虽然上海的人口持续能力得分很靠后,但上海地处沿海城区非常发达,吸引了各种投资和各行各业的人才,其它各项优势明显,使得其总体排名非常靠前,弥补了其人口持续能力低的状况,由于其独特的地理和经济优势,使得其展现出了人力资源发展的巨大潜力.
第5 类中,只有一个地区——西藏,自2000年西部大开发战略实施以来,使得西藏在科技投资、医疗保健卫生服务和教育投资等方面均站在全国前列,但因其开发较晚,使得西藏这一地区在第一、第二和第五主成分上的得分均处于全国落后水平,特别是人力资源的技能水平和健康水平低,人均受教育年限等方面低,使得其人力资源水平处于全国最低水平.
3 结论与建议
3.1 结论
将我国31 省区人力资源状况主成分分析的综合得分和聚类分析结果相结合,可得出以下结论:区域之间人力资源发展水平存在巨大的差异;区域内部省区之间人力资源状况也存在较大差异;人力资源向人力资本的转化不足;区域人力资源水平的分类与区域经济发达程度高度相关.
3.2 建议
西藏地处西部较为偏远地区,其各项指标均远远落后于其它地区,但由于西部大开发战略的实施,使得西藏等西部地区重新焕发出生机.尽管实施了西部大开发,但要加强其人力资源水平,提高其经济增长速度,关键是提高其人力资源水平.由于其原有水平低,现在虽加大了投入,但其现有的人力资源存量依旧处于较低水平,特别是人力资源的技能水平和健康水平,人均寿命偏低,受教育年限低,其中西藏地区的人均受教育年限仅为4.55年,要提高这些地区的人力资源水平,还需要在提高现有的教育基础的同时,大力开展成人培训和教育,改善其生存条件,提高创新能力.
由于教育投资需要一段时间才能见效,尽管其现有人力资源投资较高,但要快速改变现状,除了号召人才到西部创业外,还必须营造吸引人才的软硬环境,形成良好的用人机制,构筑良好的经济发展空间,为人才创造好的环境,体现人才的价值,从而提高现有人力资源的存量.
而广大的中部地区,要想具备北京、上海、天津、广东、江苏、浙江和辽宁这样的发展水平,就必须提高现有人力资源水平,除加大教育和科技投资外,还必须提高人力资源的素质,增加高精尖人才的储备.由于中部地区经济发展水平普遍不能与东部地区相比,要想在人才争夺中取胜,还必须花大力气搞经济建设,从而吸引更多的人才.
由于西部地区较为落后,对西部地区实施大开发战略,在大开发的同时开展成人培训和成人教育,号召人才去西部创业,营造人才所需的软硬环境.广大中部的落后地区要在加大教育和科技投资的同时,提高人力资源的素质,增加高精尖人才的储备;东部地区还应大力搞好经济建设,吸引更多人才.
[1]刘英.基于SPSS 分新的人力资源梯度分布研究[J].决策与信息(下旬刊),2010(12).
[2]Mclacchlan G.Mixture models:Inference and application to clustering[M].New York,Marcel Dekker,1988.
[3]MSYang,KL Wu.Unsupervised possiblistic clustering[J].Pattern recognition,2006(39):5-21.
[4]R Krishnapuram,J Keller A.possibilistic approach to clustering[J].IEEE Trans.On FuzzySystems,1993,1(2):98-110.
[5]陆远权,马垒信,何倩倩.我国31 省区人力资源状况比较研究-基于因子分析和聚类分析[J].科技与管理,2010,12(5):75-78.
[6]国家统计局.中国统计年鉴2010[M].北京:中国统计出版社,2010.
[7]邓祖新.数据分析方法和SAS 系统[M].上海:上海财经大学出版社,2006.288-389.
[8]范金城,梅长林.数据分析(第二版)[M].北京:科学出版社,2010.
