基于MFCC和HMM 的腭裂语音辅音省略识别算法
2014-12-23袁亚南何凌龚晓峰
袁亚南,何凌+,龚晓峰,尹 恒,李 杨
(1.四川大学 电气信息学院,四川 成都610041;2.四川大学 华西口腔医院,四川 成都610041)
0 引 言
近年来,语音信号处理技术被越来越多的应用于病理语音的研究。由于腭裂语音数据采集的瓶颈,目前国内外对腭裂语音信号处理技术仅局限于少量语音样本的简单分析,如频谱与共振峰分析[1]、儿童腭裂语音的自动评估[2]等。其中对于高鼻音化的语音分析已经有了相对较为成熟的理论基础[3-5],但在腭裂语音辅音发音错误方面只有一些听觉感官上的,或是声学上的主观研究,如腭裂语音辅音的声学特征[6]等。
从临床表现和语音学常识可知,元音的形成不依赖于口腔压力,而辅音必需口腔压力形成,因此辅音的表现是患者发音方法和腭咽功能的反映,辅音发音的正确率直接映射患者语音的清晰度。常见的腭裂语音辅音发音错误为辅音省略,即音节中辅音被省去,只剩下元音的现象。
目前国际各唇腭裂治疗中心通用的腭裂语音评估 “金标准”为语音师主观判听,但这种诊断方式过多的依赖于语音师的主观经验和判定,周围环境也会对判定结果造成一定的影响。基于上述背景,临床上迫切需要一种非人为执行的判定方式,以期获得对腭裂语音客观、准确的判定。本文提出自动腭裂语音识别系统,以实现对腭裂语音辅音省略的自动识别,为临床语音师提供客观、非侵入性、经济便捷的辅助诊断,具有重要的临床意义和广泛的社会应用前景。
1 腭裂语音辅音特征分析
汉语普通话共包含有21个辅音,包括/b/,/p/,/m/,/f/,/d/,/t/,/n/,/l/,/g/,/k/,/h/,/j/, /q/,/x/,/z/,/c/,/s/,/zh/,/ch/,/sh/,/r/, 其 中 只 有/m/,/n/,/l/,/r/有声带振动,即为存在语音周期的浊音,另外17个辅音则是无明显声学特性的清音。如图1所示的语音信号时域波形图,可以看出/ma/在辅音和元音上并无清浊音分界,而/ha/可以明显的看出/h/和/a/的清浊音分界。

图1 语音信号时域波形
这种特性对于音节中含有浊音辅音的元辅音分离有一定的困难,目前并没有一种算法可以比较准确的做到元辅音分离,而人工分离又会造成不必要的误差,降低系统识别率。基于以上的腭裂语音辅音特性,本文提出的自动识别算法以字 (普通话中,通常一个汉字即为一个音节)作为识别单位。
常见的腭裂语音的辅音发音错误为辅音省略。图2所示为正常发音 (发音/na/)和辅音省略 (即/n/被省略,只剩下/a/)情况下的语谱图。
在语谱图上,横杠表现出了元音的共振峰变化的声学特征,而辅音在语谱图上的声学特征则由冲直条、空白间隙和擦音乱纹这3种基本纹样的任意组合展现。腭裂患者由于腭部存在裂隙,导致其构音功能障碍,但相当一部分腭裂患者在手术修复治疗后仍存在腭部发音障碍。造成这种现象的原因是虽然修补了裂隙肌肉,但腭咽功能并未修复,在口腔内气流需要产生并保持一定压力的时候,就不能蓄足充足的口腔气流,使得辅音的成阻和持阻能量不足,表现在语谱图上就是冲直条不明显,空白间隙减少。

图2 正常发音和辅音省略情况下的语谱
由图2可以看出,/na/的两种发音 (正常发音、辅音省略)表现在语谱图上,除了横杠的不同 (这可能是由于腭裂语音的高鼻音或鼻漏气所造成),在冲直条和空白间隙上也展现出了在时间和频率上的很大区别。由于选用的鼻音n,所以擦音乱纹并没有明显体现。
2 基于MFCC和HMM 的腭裂语音辅音省略自动识别算法
本文旨在将腭裂辅音的特征通过语音特征表现出来,并建立一个适用的声学模型,实现对腭裂语音辅音省略的自动识别。
图3所示为提出的腭裂语音辅音发音错误识别系统流程图。训练语音信号以及典型的辅音缺省发音经过预处理后,提取美尔频率倒谱系数 (mel frequency cepstrum coefficient,MFCC)特征参数,经过隐马尔科夫模型 (hidden markov model,HMM)训练建立腭裂语音模型。测试用语音信号经过同样的预处理、MFCC 参数提取及HMM 模型训练后,与已经得到的模型进行viterbi匹配,以实现辅音发音错误类型的识别。
2.1 语音信号预处理
由于实验所用信号为患者在语音诊疗室所录制,且录制地点为保证少儿的精神放松,以达到其最真实、自然的语音数据供后期治疗,所以录音中会含有部分杂音、噪音,包括患儿的口齿不清及吞咽声等,也会包括语音师的领读声、仪器声等,所以在对语音信号进行特征参数提取之前需要先经过预处理。
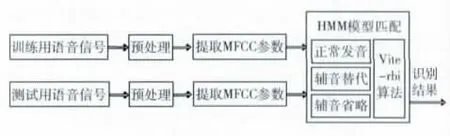
图3 基于MFCC腭裂语音辅音发音错误识别系统
由于上述噪声干扰的不规则性,不可用简单地带通滤波器进行滤波。对于人为的噪声,例如吞咽声及语音诊断师的领读声,在实验中大多采取人工切割的方式将这些干扰切割掉;对于仪器声等,考虑到其不可预测性,系统采用自适应滤波器实现去噪处理。自适应滤波器可以在噪声情况不可知的情况下根据输入信号的时变性随时调整参数,从而得到最优的输入信号。本文采用LMS 滤波器算法实现滤波。
经过滤波后的语音信号还需要进行预加重处理。一般通过传递函数为H(z)=1-az-1的一阶FIR 高通数字滤波器来实现预加重。本文中预加重系数为0.9375。
由于语音信号的短时平稳性,所以通常对其进行加窗分帧处理。本文选择汉明窗,帧长为24ms,帧移为12ms。
预处理的最后一步是对语音信号进行端点检测,其目的是在一段含有语音的信号中区分出语音的起止点和终止点,从而将语音分离出来。在腭裂语音识别中,语音信号本身就具有很多腭裂儿童所发出的不必要的口唇音,而端点检测可有效地去除这些干扰。本文采用短时能量和过零率相结合的端点检测算法。
2.2 MFCC特征参数提取
美尔频率倒谱系数 (MFCC),是一种根据人耳听觉特性构造的一种语音特征参数。由于人耳所听到的声高与频率并不是线性对应关系,而Mel频率尺度更能准确的对应人耳的听觉特性。Mel频率尺度与实际频率大体上呈现出对数分布关系,其转换关系可近似为式 (1)
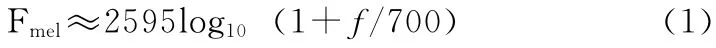
美尔频率倒谱系数计算步骤如下:
(1)原始语音信号S(n)经过一系列预处理后得到帧信号x(n),对帧信号进行离散傅里叶变换。得到其线性频率谱X(k)

其中,0≤K ≤N ,N 为傅里叶变换的点数。
(2)求帧信号能量谱,即上式求得的离散频率普的平方。通过M 个美尔尺度的三角型滤波器对能量谱进行带通滤波。M 通常取24~40个,在本文中M 取24。
(3)求滤波器组输出的对数能量
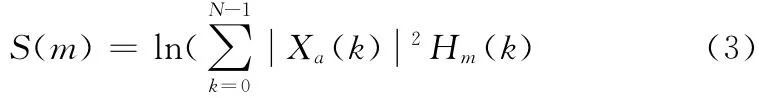
其中,0≤m ≤M ,Hm(k)为滤波器传递函数。
(4)经离散余弦变换 (DCT)得到MFCC系数
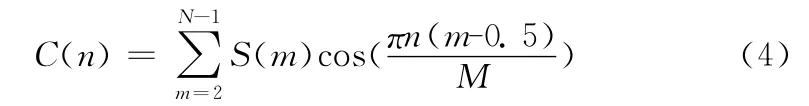
其中,0≤n≤M 。
将MFCC选作腭裂语音的特征参数进行分析,是因为MFCC不依赖于全极点形式的语音产生模型,对于含有噪音的语音信号有较好的鲁棒性,可以在一定程度上消弱腭裂语音中各种可能性的语音干扰。文献 [7-9]同时对于非特定人的语音识别系统也有减小因不同人之间的说话差异而可能造成的系统精确度下降[10]。
2.3 HMM 语音模型
HMM,即隐马尔科夫模型。隐马尔科夫链的状态形式,也即隐马尔科夫模型的拓扑结构,决定了状态间转移的方式。从语音信号来考虑,信号中的音素是按照从左至右的方式发出的,所以使用自左至右的状态间转移方式相对合理。且在汉语中,音素省略现象很少出现,尤其是针对于本文所处理的单音节发音中则几乎不存在。所以在本文中采用的是无跳转状态模型[11],如图4所示。
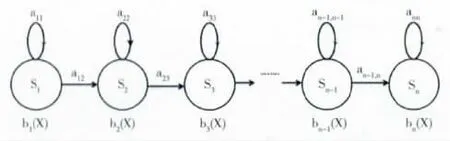
图4 HMM 无跳转状态模型
状态转移矩阵A= [aij],1≤i,j≤N,其中i>j时,aij=0。
状态输出概率函数矩阵B= [bj(x)],1≤j≤N。
采用GM (gaussian mixtures)来计算状态输出概率函数矩阵,计算式如下
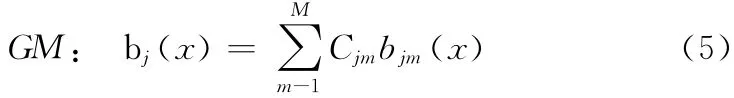
其中,bjm(x)符合N [x,μjm,Ujm]的正态多维高斯分布。
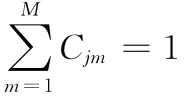
高斯混合的作用本质为求各个混合概率的加权,起到包络平滑的作用。混合数M 的选取需要考虑到两方面的要求:其一是要均匀分布模型数据,另外是需考虑不同长度的语音信号帧数不同引起的消极影响。经过实验比对,本文选取M=3。
考虑到本文实验所用的实验数据量相对较大,传统Baum-Welch算法的高运算量和所需的巨大存储空间使其并不适用于本实验,本文选择了分段K 平均算法进行模型训练。步骤如下:
(1)将训练数据的语音信号进行状态的初始分割。
(2)对状态相同的语音特征矢量挑选出来,使用Kmeans方法对这些矢量求其B矩阵的模型估计。
(3)根据模型估计,对训练数据语音信号进行状态重新分割。
(4)将旧的模型替换为新的模型,并根据模型是否收敛判断选连是否结束。若不收敛,则转步骤 (2)。
2.4 模型匹配
模型训练完毕就可以对实验数据进行模型匹配,得到系统识别结果了。本文采用viterbi算法,viterbi是一种运算简便,正确率较高的识别算法,可以同时得到概率和状态序列。
设已知模型序列O=O1,O2,……,OT和HMM 模型λ= [π,A,B],定 义δi(i)是 时 刻t 沿 路 径q1,q2,……,qt,且
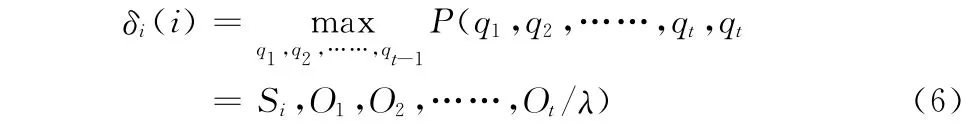
算法步骤如下:
(1)初始化
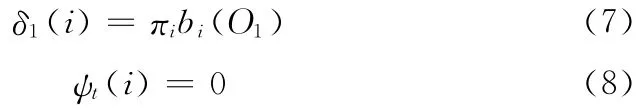
其中,1≤i≤N 。
(2)递归

其中,2≤i≤T,1≤j≤N 。
(3)终止

(4)回溯最佳路径

其中,1≤t≤T-1。
3 实验及结果分析
3.1 数据来源
本文所用语音信号采集于四川大学华西口腔医院唇腭裂外科。四川大学华西口腔医院唇腭裂外科是国内最大唇腭裂专科,其 “腭裂术后语音治疗中心”,长期开展腭裂术前术后的腭咽功能和语音评估,有着成熟的标准化的评估流程和评估机制。
实验所用的训练和测试语音信号的选取见表1和表2。
训练语音为正常发音状态下的语音信号。其中,/a/是选取的为由于辅音缺省而导致的只有元音/a/的情况。
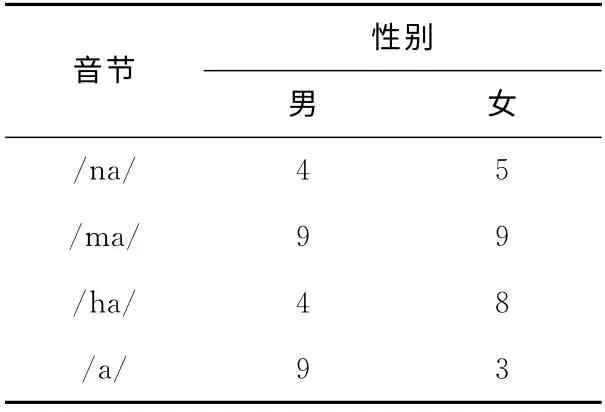
表1 所选取的训练语音信号

表2 所选取的测试语音信号
3.2 实验结果及分析
腭裂语音辅音错误类型识别正确率如表3至表5所示。

表3 发音正常情况下自动语音识别正确率

表4 辅音省略情况下自动语音识别正确率

表5 发音正常及发生辅音省略情况下自动语音识别系统正确率
从表3和表5可以看出,系统对于发音正常的语音有较高的识别率。实验所采用的辅音省略的测试数据,为临床语音师多次判听后进行标注。从表4和表5的实验结果可知,提出的自动腭裂语音辅音发音错误识别算法,对辅音省略的识别率较高,可有效辅助临床语音师实现对腭裂患者语音发音错误的类型判别及矫正。系统对于发音正常的/a/音识别率高于辅音省略的/a/音原因是:辅音省略后的/a/音中个别还含有听觉系统不能察觉的微少辅音信息反映在提取出的MFCC 参数上,从而造成系统的错误识别。而这种错误识别也相应的可以为临床语音师提供判断患儿的腭咽功能的恢复程度的参考。
4 结束语
针对国内外研究者由于信号数目不足而导致的腭裂语音研究缺漏的问题,通过腭裂语音辅音发音错误的特征进行分析,本文提出了基于MFCC 和HMM 的腭裂语音辅音发音错误的自动识别算法。实验结果表明,提出的自动识别系统能较好的实现对辅音发音正确率、发音错误的辅音名称的自动识别。说明该系统可实现对腭裂语音发音的辅助评估,为临床语音师提供一种非主观性的诊断辅助措施。
[1]SHI Xinghui,CHEN Ning,XING Shuzhong,et al.Study on spectrum features of speech before and after repair in cleft palate patients[J].Stomatology,2008,28 (2):65-69 (in Chinese).[施星辉,陈宁,邢树忠,等.腭裂患者手术前后语音频谱特点的研究 [J].口腔医学,2008,28 (2):65-69.]
[2]Andreas Maier,Florian Honig,Christian Hacker,et al.Automatic evaluation of characteristic speech disorders in children with cleft lip and palate [C]//Proc of Interspeech,2008:1757-1760.
[3]S Murillo,J R Orozco,J F Vargas,et al.Automatic detection of hypernasality in children [G].LNCS 6687:New Challenges on Bioinspired Applications.Berlin:Springer Berlin Heidelberg,2011:167-174.
[4]Pruthi T,Wilson C Y.Acoustic parameters for the automatic detection of vowel nasalization [C]//Proc of Interspeech,2007:1925-1928.
[5]Vijayalakshmi P,Ramasubba M,O'Shaughnessy D.Acoustic analysis and detection of hypernasality using agroup delay function [J].IEEE Trans,2007:54 (4):621-629.
[6]CHEN Xin,TANG Enyi,LU Yong,et al.Acoustic characterristics of the consonants in patients with post-palatoplasty velopharyngeal incompetence [J].Shandong Medical Journal,2011,51 (42):6-7 (in Chinese). [陈欣,唐恩溢,鲁勇,等.腭裂术后VPI 患者的辅音发声特点 [J].山东医药,2011,51 (42):6-7.]
[7]Arias-Londoo J D,Godino-Llorente J I,Sáenz-Lechón N,et al.Automatic detection of pathological voices using complexity measures,noise parameters and mel-cepstral coefficients [J].IEEE Trans,2011,58 (2):370-379.
[8]Orozco J R,Murillo S,Vargas J F,et al.Nonlinear dynamics for hypernasality detection [G].LNCS 7015:Advances in Nonlinear Speech Processing.Berlin:Springer Berlin Heidelberg,2011:207-214.
[9]FENG Xiaoliang,MENG Zihou.Distinctive parameter survey of mandarin consonants for speech evaluation [J].Technical Acoustics,2010,29 (3):297-305 (in Chinese). [冯晓亮,孟子厚.面向普通话辅音检测的区别特征参数测量 [J].声学技术,2010,29 (3):297-305.]
[10]Orozco J R,Murillo S,lvarez A,et al.Automatic selection of acoustic and non-linear dynamic features in voice signals for hypernasality detection [C]//Proc of Interspeech,2011:529-32.
[11]Mikhajlovich V E,Stanislavocich D S,Viktorovich L D,et al.Method of detecting pathology of voice leading speech[P].RU Patent:2010104610,2011-08-20.
