基于T-Graph算法的主题爬虫研究
2014-12-23刘乃文段会川
张 环,刘乃文,段会川
(山东师范大学 信息科学与工程学院,山东 济南250014)
0 引 言
针对通用网络爬虫查准率低、信息冗余大等缺点,主题网络爬虫应运而生。主题爬行算法主要分为基于内容分析的主题相关性算法和基于链接结构的主题相关性算法两大类。基于内容分析的主题相关性算法有Best First Search、Fish Search以及Shark Search等算法,这类算法只注重文本内容在主题搜索上的重要性,忽略了Web超链接结构的作用,易出现 “隧道”问题。基于链接结构的主题相关性算法主要有PageRank算法和HITS算法,这类算法只考虑了链接的结构特征,忽略了页面内容对爬行的影响,易出现 “主题漂移”问题。基于T-Graph (treasure graph)算法的主题爬虫策略[1]综合考虑了页面内容与链接结构对爬行的影响,通过分析候选链接的主题边缘文本预测链接的相关性,这种方法比将网页的全部内容进行预测要准确,效率更高。
T-Graph算法采用TD-IDF方法提取特征项,该方法基于关键词的出现频率对文本中的词汇进行机械的匹配,没有对词语进行语义分析就认定词语是文本的特征项;相似度计算时,没有区分网页中不同位置文本的重要程度。基于以上思考,针对传统算法存在的不足进行调整和改进,并在此基础上验证改进后算法的效果。
1 T-Graph的构建
收集特定主题的样例节点,把样例节点按层次进行链接,目标页面所在的层为第零层,链接目标页面的层为第一层,以此类推,重复这个过程,直到相当多的节点被建立。最高层的节点可以直接链接最底层的目标页面,同一层的节点之间不存在链接,任意层的节点至少有一个链接指向它的低层节点。T-Graph中存在特殊节点,对它进行相似度计算,跟随它的指向路径并不能找到目标页面,这样的节点称为死节点,在构建T-Graph时尽量避免死节点。T-Graph的工作性能用一个已知的文档进行测试,如果预期的标准没有达到,这个模型需要被重复构建。
T-Graph的节点有5种属性:主标题 (MH)、小节标题 (SH)、子标题 (ISH)、数据组件 (DC)、目标信息组件(DIC)。DC中存放候选链接的主题边缘文本信息。DIC中存放到达目标页面之前所需要下载网页的数量信息。抓取一个网页,提取网页候选链接的MH、SH、ISH 以及DC这4种属性与T-Graph节点的4种属性进行相似度的计算,如果找到匹配的节点,则按照相似度的大小将链接存入抓取队列,网页存入仓库中;如果没有找到匹配的节点,赋予链接较小的优先级存入抓取队。T-Graph的结构如图1所示。
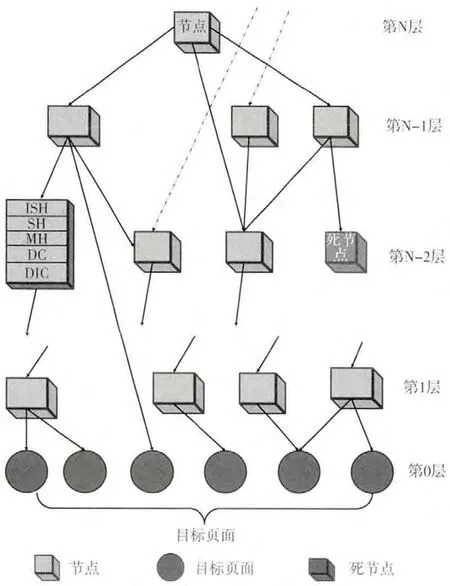
图1 T-Graph结构
2 爬行阶段
图2是基于T-Graph 的爬虫系统结构。基于T-Graph的爬虫抓取网页的事件顺序如下:
(1a)从抓取队列中抓取优先级高的链接,向Web网络发送下载对应网页的请求。
(1b)爬虫从Web获取相应的网页。
(2)爬虫将抓取的网页存放在应答队列中。
(3)、(4)从应答队列中提取网页中的链接与T-Graph中的节点进行相似度计算。
(5)若网页中的链接匹配T-Graph的节点,将此网页下载到仓库进行存储。
(6)提取网页中的链接,按照优先级的顺序放到抓取队列中。
(7)爬虫从抓取队列中选择优先级高的链接进行优先爬取。
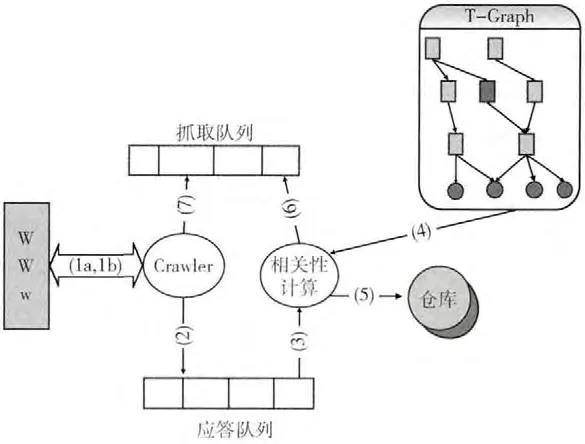
图2 基于T-Graph算法的爬虫系统结构
应答队列存放爬虫抓取的网页和HTTP 的响应。如果由于网络中断或者链接过旧,抓取的网页不能下载,系统仍然维持当前的HTTP响应的详情,执行相似度的计算。
如果T-Graph中没有节点与网页中的链接匹配,仍然将网页中的链接存入抓取队列中,但是赋予这条链接较低的优先级。这种方法在一定程度上避免了过早丢弃与主题无关但与目的页面相连接的前驱节点,提高了查全率。
3 中文图书分类法提取候选链接的主题边缘文本
3.1 中文图书分类法
中文图书分类法是赖永祥参照杜威十进制图书分类法改进的。此图书分类法更适用于中文书籍,特别是中国历史和中国文学。中文图书分类法主要分为十大类,覆盖了世界上各个领域的知识:
000 总类
100 哲学类
200 宗教类
300 科学类
400 应用科学类
500 社会科学类
600 中国史地类
700 世界史地类
800 语言文学类
900 艺术类
以上十大类中的每一类可以进一步的细分,添加小数点使分类更加明确。中文图书分类法是一种层次分类方法,每一个概念对应于一个惟一的分类号码 (如图3所示),分类号码决定2个词组是否属于同一个主题或者相关的主题。例如,关键词1,关键词2,关键词3对应的中文图书分类号分别为917.1026,917.1029和383.512,可以直观的判断出关键词1和关键词2属于同一个主题,关键词3与前2个关键词不属于同一个主题。
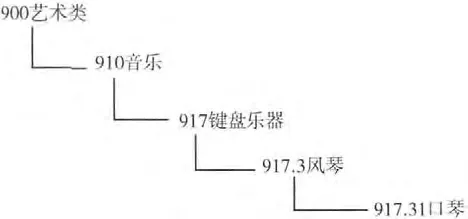
图3 口琴的分类号
3.2 主题边缘文本的提取
建立二维坐标,横坐标代表分类号码的长度,纵坐标代表分类号码。本文运用ICTCLAS3.0分词系统将文本分成关键词,由于每一个关键词有一个或者多个概念,所以每一个关键词都对应一个或者多个中文图书分类号码,在二维坐标中,对应一个或者多个点。
图4展示了运用中文图书分类法提取候选链接主题边缘文本的示例图。图中红色的点对应于锚文本的关键词,黑色的点对应于其它文本的关键词。点主要集中于圆圈内,这种现象称为星系。星系中的点对应的关键词称为候选链接的主题边缘文本。
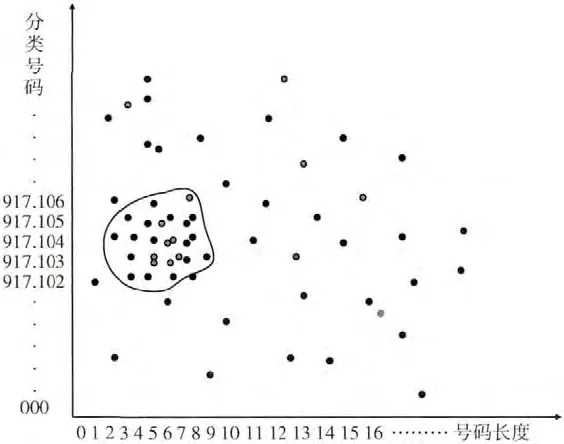
图4 主题边缘文本的提取
4 基于词义分析的相似度计算
针对传统算法的不足,对传统算法进行了改进,综合考虑了不同位置文本的权重,采用语义分析的特征项提取算法对特征项进行提取。
对ISH、SH、MH 和DC 进行相似度计算,记为simISH、simSH、simMH和simDC,根据它们在网页中所处的位置赋予不同的位置权重。候选链接CL的相似度为式 (1)

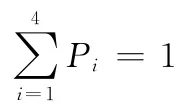
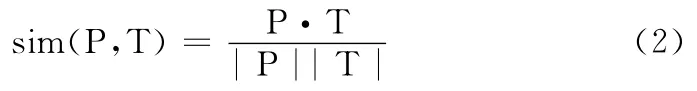
式 (2)是对文本关键词的机械匹配,存在一定的语义偏差,影响相似度的准确性,在此基础上,利用维基百科的相关知识,引入了关键词的语义计算和义原的概念,从关键词的语义层次对候选链接进行语义的相似度计算。在维基百科中,有2个重要的概念,即 “概念”和 “义原”。“概念”是对词汇语义的一种描述。义原是描述概念的最小意义单位。
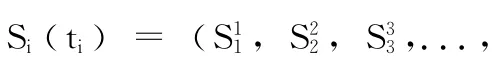
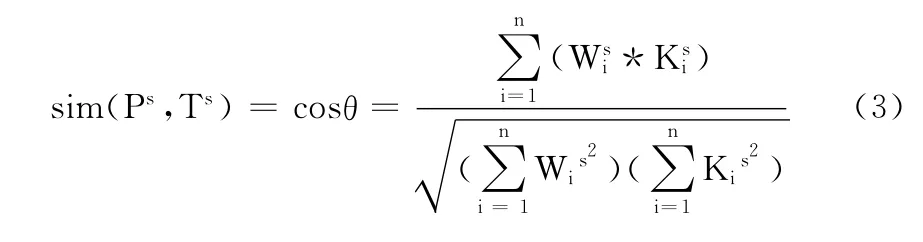
5 实验与结果分析
5.1 评估指标
主题网络爬虫常用的性能判断指标为:查准率和查全率。查准率公式为:Precision=K/N,K 为抓取的与主题相关的页面数量,N 为抓取到的全部页面数。查全率又叫召回率,计算公式为:Recall=K/R,R 为网络中存在的所有与主题相关的页面数。查全率需要知道网络中存在的所有与主题相关的页面数,而这一点很难办到,所以主要从查准率这一方面对实验效果进行评估。
5.2 实验结果分析
介绍了传统的T-Graph算法以及改进的T-Graph算法,基于理论基础,分别对2种算法进行实验验证。分词工具采用ICTCLAS 3.0版本,语料库采用维基百科语料库。设定位置权重系数P1=P2=P3=P4=1/4,模型的层数为5层,以音乐为主题,URL=http://zh.Wikipedia.org/wiki/Wikipedia:%E9%A6%96%E9%A1%B5 为种子链接进行爬取,下载页面总数为4000个,每隔500个页面统计一次获取与主题相关的页面数量。传统的T-Graph算法和改进的T-Graph算法的爬虫实验结果如图5和图6所示。
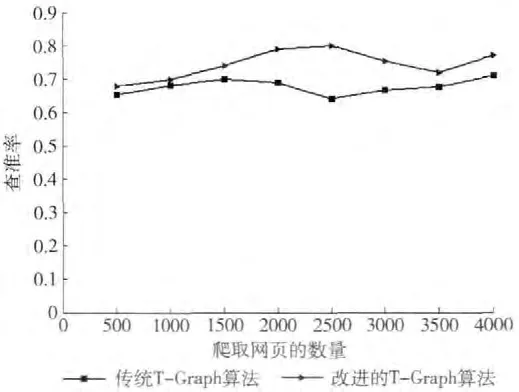
图5 2种算法的查准率实验对比
从图5可知,在查准率方面,改进的T-Graph算法优于传统的T-Graph算法。传统的T-Graph算法的查准率在0.6上下浮动,改进的T-Graph算法的查准率在0.7~0.8上下浮动,改进的T-Graph算法的查准率始终高于传统的T-Graph算法。在爬虫抓取页面的初期,2种算法查准率的差距很小,随着抓取网页数量的增多,改进的T-Graph算法的查准率与传统T-Graph算法的查准率之间的差距逐渐拉开,改进的T-Graph算法的优势越来越明显。从图6可知,在抓取相同数目网页的情况下,改进的T-Graph算法所获得的与主题相关网页要比传统的T-Graph算法获取的主题相关网页多。实验结果表明,改进后的T-Graph算法使爬虫的性能得到了提升。
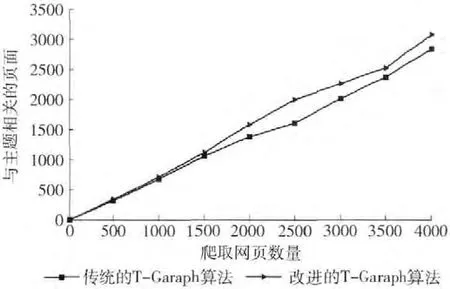
图6 2种算法抓取与主题相关页面的实验结果对比
6 结束语
基于T-Graph的主题爬虫策略,通过分析候选链接的主题边缘文本预测链接与主题的相关性,综合考虑页面内容和链接分析,使主题爬行质量得到了提高。然而传统的T-Graph算法采用传统的TD-IDF 算法进行特征项的提取,没有综合考虑不同位置文本的权重问题。针对传统算法的不足进行了改进,从语义层次对特征项进行分析和提取,综合考虑不同位置文本的权重。本文的研究工作有2个方面需要进一步深入进行:一是运用中文图书分类法获取主题边缘文本的过程需要手工进行,比较繁琐;二是需要找到一个更为有效的方法解决过早丢弃与主题无关、但与目标页面相连的前驱页面的问题。
[1]Patel A.An adaptive updating topic specific Web search system using T-Graph [J].Journal of Computer Science,2010,6(4):450-456.
[2]Sotiris Batsakis,Euripides GM Petrakis,Evangelos Milios.Improving the performance of focused Web crawlers[J].Data&Knowledge Engineering,2009,68 (10):1001-1013.
[3]LIU Jinhong,LU Yuliang.Survey on topic-focused Web crawler[J].Application Research of Computers,2007,24(10):26-29 (in Chinese).[刘金红,陆余良.主题网络爬虫研究综述 [J].计算机应用研究,2007,24 (10):26-29.]
[4]YE Yuxin,OUYANG Dantong.Semantic-based focused crawling [J].Journal of Software,2011,22 (9):2075-2088 (in Chinese). [叶育鑫,欧阳丹彤.基于语义的主题爬行策略[J].软件学报,2011,22 (9):2075-2088.]
[5]XIONG Zhongyang,SHI Yan,ZHANG Yufang.Wikipediabased focused crawling with page segmentation [J].Journal of Computer Application,2011,31 (12):3624-3627 (in Chinese).[熊忠阳,史艳,张玉芳.基于维基百科和网页分块的主题爬行策略 [J].计算机应用,2011,31 (12):3624-3627.]
[6]WANG Xiang,JIA Yan.Computing semantic relatedness using Chinese wikipedia links an taxonomy [J].Journal of Chinese Computer Systems,2011,32 (11):2332-2342 (in Chinese).[汪祥,贾焰.基于中文维基百科链接结构与分类体系的语义相关度计算 [J].小微型计算机系统,2011,32 (11):2332-2342.]
[7]Zheng Haitao,Kang Bo-yeong,Kim Hong-Gee.An ontologybased approach to learnable focused crawling [J].Information Sciences,2008,178 (23):4512-4522.
[8]HUANG Li, WANG Chengliang,YANG Zheng.Focused crawling oriented intelligent tunneling algorithm research [J].Application Research of Computers,2009,26 (8):2931-2933(in Chinese).[黄莉,王成良,杨铮.面向主题网络爬行的智能隧道穿越算法研究 [J].计算机应用研究,2009,26 (8):2931-2933.]
[9]Evgeniy Gabrilovich,Shaul Markovitch.Computer semantic relatedness using Wikipedia-based explicit semantic analysis[C]//Proceeding of the 20th International Joint Conference on Artificial Intelligence,2007:1606-1611.
[10]Franziska Bussche,Klara Weiand.Not so creepy crawler:Easy crawler generation with standard XML queries [C]//Proceeding of the 19th International Conference on World Wide Web,2010:1305-1308.
[11]CHEN Xing.Research and implementation of focused crawler using Context Graphs [J].Computer Engineering and Design,2011,32 (3):914-917 (in Chinese). [陈星.基于Context Graphs的主题爬虫研究与实现 [J].计算机工程与设计,2011,32 (3):914-917.]
