碎片拼接复原技术研究
2014-12-23陆佳浩
詹 烨 陆佳浩
(杭州师范大学,浙江 杭州 311121)
1 研究背景与意义
传统的拼接复原工作需要由人工完成,虽然准确率较高,但效率很低,不适合运用于大量拼接。随着计算机技术的发展,破碎纸片的自动拼接技术运用而生,使其在司法物证复原、历史文献修复以及军事情报获取等领域获得更加广泛、便捷的应用。但是,目前研究较多的自动化拼接一般都是利用碎片边缘的面积特征、尖点特征、尖角特征等几何特征,探索与之相匹配的相邻碎纸片进行拼接。这种基于边界形状的拼接方法并不适用于边缘形状相似的碎纸片。由于规则碎片其每一片碎片的大小、形状都是相同的,因此,利用形状、轮廓进行拼接不是很实际。通常情况下,文档是被手或者碎纸机撕碎的。其中手撕的文件将会产生不规则的碎纸片。而一种碎纸机将文件切成成条状,在这种情况下,产生的文档被称为条形文档。当然也有从水平和垂直方向来进行的碎纸机,这种类型的机器就会产生正交分解文档。关于重建的问题,这些文件可以被认为是一个特殊的拼图。给定N 碎片,每个二进制位图的大小都是W×H 像素,并假设碎片放在正确的方向,重构分解文档就是找到这些碎片的正确定位使得它们组成原始文档。在重建条形文档的这个问题所能参考的研究很少。Prandtstetter 和Raidl 提出邻域搜索方法,它使用一个特定的变量的方法来重建文件,涉及用户在过程中进行人工干预从而提高正确率。Ukovich 等人提出了一个算法重建条形粉碎文件,特别重视使用MPEG7 描述符的可能性。如Marques 和Freitas 使用边界颜色和利用最近邻算法来计算对应的特征向量之间的欧几里得距离等特征。
通过建立的模型,我们能够研究利用计算机进行不规则和规则碎片的拼接,帮助人们快速地获得大致的拼接结果。在此基础上,再加以人工干预,更快得到拼接的结果,提高拼接的速率和正确率。
2 碎纸片拼接模型的建立
中文规则碎纸片的拼接模型:
在对碎纸片进行了二值化处理之后,我们试着建立一个碎纸片拼接的数学模型来解决这个问题。在此之前,我们先给出模型的基本假设:
假设一:整张纸张切割完整,碎片内没有丢失部分像素并且在切割之后所得碎纸片都全等;
假设二:字与字之间的行间距都是相等的,没有发生突变的行为。
在建立模型之前,我们需要看一下实际的问题:对于给定的来自同一页印刷文字文件的碎纸机破碎纸片(仅纵切),建立碎纸片拼接复原模型和算法,并针对附件1 给出的中文文件的碎片数据进行拼接复原。如果复原过程需要人工干预,请写出干预方式及干预的时间节点。复原结果以图片形式及表格形式表达。①
除去文字本身,我们可以把每张碎纸片看出只有黑白两种颜色的图像。通常遇到这种情景的图像可以用二值法来表示图像。一幅二值图像[3]的二维矩阵仅有{0,1}两个值构成,“0”代表黑色,“1”代表白色。将图像中的像素点分别用{0,1}表示,把文字图像数字化,便于拼接修复。二值图像通常用于文字,线条图的扫描识别OCR,本文尝试运用二值图像修复碎纸片。
本文定义每个像素点的颜色δij,1≤i,j≤1980,其中:

在中文文章中,我们一般会在文章的四周留下页边距,则完整的文章周围应该全是白色,用{0,1}表示文章的边界处应该全为1。那么在寻找边界纸片时,我们是否可以认为:当碎纸片的某条边界全为1时,此碎纸片可能位于文章的边界处。
(1)建立E 矩阵
为了存储碎纸片的边缘特征,我们建立一个19×n 的矩阵E[i,j]。其中i 表示碎片的编号,当表示左侧的像素点时j=1,当表示右侧的信息时j=2。例如,E[i,j]储存001 号碎片左侧边缘像素点信息。
(2)建立S 矩阵
根据已经建立的E[i,j]矩阵,我们通过计算得到一个19×2 的S[i,j]矩阵,这个矩阵储存的是每一条碎片边缘取值为0 的像素点(即为黑色的像素)的数量。例如,S[i,j]=350 表示001 号碎片的左侧边缘有350 个黑色像素点。
(3)选取shred with white left
根据S 矩阵,若S[i,1]=0,即在这个碎片的最左端没有任何的像素点,那么我们就认为该碎片在原始文件中处最左端,即为选取的shred with white left。
(4)提取碎片的行特征
根据观察,原始图像的文字特征较为明显,尤其是行特征,因此我们采取提取碎片的行特征的形式(具体的我们在下面阐述)。首先我们需要确定一个上界,确定依次向下取w 为行宽(调整结果发现取w=40 pixels 可以较好的保证能容纳每一个 文字,也不至于太宽)直至下边缘,得到每条碎片的行数为{n1,n2,…,n19};然后取n=max{n1,n2,…,n19}确定为最终的行数,然后以该条碎片的行化方式为基准,来对每一条碎片进行行化,最终每一条碎片被划分为28 行。
(5)匹配度的建立
基于上述的分析和操作过程,得到的S 矩阵已经提取了一个碎纸片边缘蕴含的大部分文字信息。据此我们建立两个碎纸片的匹配度,其计算公式如下所示:
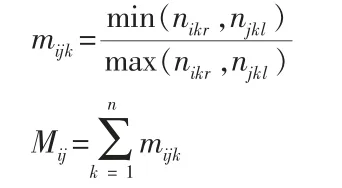
这里的n 就是上文的总行数,而mijk表示碎片i 和碎片j 第k 行之间的匹配度;Mij表示碎片i 和碎片j 之间的匹配度。我们之所以不采用全部像素点进行匹配的原因是因为无法体现行之间的差别,会造成部分信息的流失,影响匹配质量。
(6)数学模型的建立
根据上述定义的匹配度,我们可以计算得到19 个矩阵两两匹配的匹配度,所以拼接碎纸片的问题就演变成下列模型的求解:寻求一个序列,使得这个序列的匹配度在所有序列中最大。如右图1 所示:
这是一个典型的TSP 问题,权值就是我们上部分求出的匹配度,所以
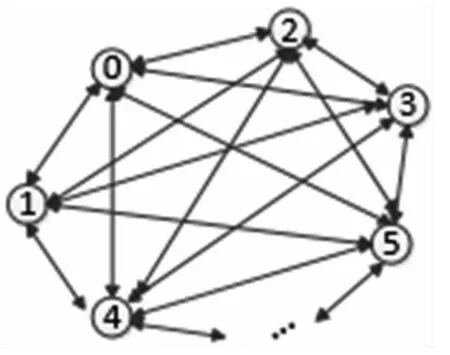
图1 TSP 模型示意图
(1)用图中的节点表示碎片,其中的有向线段wij,且wij=1-Mij,箭头的由A 指向B 就是将A 的右边缘和B 的左边缘进行匹配的费用。
(3)现需要寻找一条回路遍历所有的节点使得总费用最小。回路的开端是我们之前寻找的shred with white left。
总结整个过程,图中(i,j)边的权重为wij,设决策变量为xij=1 说明弧(i,j)已经在当前的Hamilton 回路中,则线性规划模型可表达我们给出下列的线性规划方程:
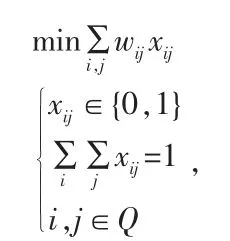
(7)模型的求解
模型的求解过程如下所示:
1)将所有碎片放入地址池中组成集合Q;
2)选取shred with white left 作为基准碎片,记为Si,记录下编号,然后将其从Q 中剔除;
3)分别计算Si右侧边缘与Q 其他碎片Sj左侧边缘的匹配度Mij;
4)选取使得Mij最大的那个碎片St作为Si的右侧碎片,记录下编号,从Q 中剔除Si后令i=t;
5)重复过程3)-4)使得Q 为空集;
由此过程得到的编号序列即为所求的最终解。
现在将此算法应用于2.2.1 开头所提的问题,得到如下序列。

表1 中文纸片拼接顺序
利用matlab 设计程序得到下列的拼接图像,考虑其清晰度,利用photoshop 进行了更为清楚的还原,原文是苏轼的《题淮山楼》,具体如下所示。

图2 Matlab 拼接

图3 Photoshop 拼接
(8)模型分析
此模型在碎纸片边缘信息量较为丰富之时,应用效果令人满意。此次进行19 张碎片的复原,耗时简短,复原效果能达到100%,完全不需要人工干预。此模型同样试用于单进行横向切割的碎纸片复原。
当边缘信息量减少,即碎纸片的数量变多,切割的方式变得复杂时,模型的满意度就会下降,可能会需要人工干预。当边缘信息量继续减少,模型的求解会变得繁琐,导致人工干预的大量增加。
[1]司守奎,孙玺菁.数学建模算法和应用[M].北京:国防工业出版社,2011,8:193-206.
[2]姜启源,谢金星,叶俊.数学模型[M].北京:高等教育出版社,1987,04:13-16.
[3]占君,张倩,满谦,等.MATLAB 函数查询手册[M].北京:机械工业出版社,2011,1:19-20,74-152.
[4]Christian Schauer,Matthias Prandtstetter,and Günther R.Raidl.A Memetic Algorithm for Reconstructing Cross-Cut Shredded Text Documents[J].Institute of Computer Graphics and Algorithms Vienna University of Technology,Vienna,Austria.
[5]Johannes Perl,Markus Diem,Florian Kleber,and Robert Sablatnig.Strip Shredded Document Reconstruction Using Optical Character Recognition[C]//Imagingfor Crime Detection and Prevention 2011(ICDP 2011),4th International Conference on,pages 1-6,nov.2011.
[6]Azzam Sleit·Yacoub Massad.An alternative clustering approach for reconstructing cross cut shredded text documents[J].Telecommun Syst(2013).
注释:
①2013 高教社杯全国大学生数学建模竞赛B 题.
