基于类别参与度的社区问答专家发现方法
2014-11-30林鸿飞熊大平刘晓鸣
林鸿飞,王 健,熊大平,刘晓鸣
(大连理工大学 计算机科学与技术学院,辽宁 大连116024)
0 引 言
在社区问答系统中的用户形形色色,良莠不齐,通常把行为活跃且具有一定数量的回答被提问者或系统评定为最佳答案的用户称为专家用户。如果能在庞大的用户群中辨别出专家用户,提出者可以把新提出的问题推荐给专家用户从而能及时地得到准确专业的答复,同时使外部搜索的信息量能有效地得到扩充。于是,专家发现成为社区问答中一个新的重要的研究热点。
对于社区问答中的专家发现,学者们提出了很多不同的技术和方法。主要方法有建立用户模型[1,2]、基于语义主题分析方法[3-5]和链接分析算法[6,7]。基于用户模型的方法,Chen等人[1]提出了一种基于用户声誉的结构分析模型来对用户的专家得分进行评级排名。Kao等人[2]进一步综合了用户的知识领域、用户声望和链接分析来评定专家用户。基于语义主题分析的方法,Riahi等人[3]使用分段主题模型来研究专家用户发现问题,效果比LDA模型要好一些。Qu等人[4]提出了一种基于概率潜在语义分析 (PLSA)的模型来进行专家发现,进而将新问题推荐给专家。Liu等人[5]综合考虑用户的历史回答信息、用户权威度和用户活跃度,提出了一种混合语言模型和LDA模型的方法来向专家用户推荐新问题。基于链接分析的方法,Jurczyk等人[6]将用户看作节点并利用HITS算法寻找权威用户。Jie等人[7]则HITS算法进行了改进,使用带权重的HITS算法计算用户的权威值。此外,Liu等人[8]就将体育比赛中的竞争机制应用于专家发现的研究中,对用户进行两两比较,计算用户的权威值。
专家用户与普通用户之间存在很大的区别,部分学者通过观察专家用户的习惯,如专家用户的初期活动规律[9]和偏好选择规律[10],来构建模型以更好地发现专家用户。本文通过观察得知大部分专家用户的擅长领域是相近的,根据用户不同类别的参与度不同,提出了一种基于用户类别参与度的社区问答专家发现方法,除了考虑所属类别回答者的回答质量外,还考虑了相近类别中回答者的回答质量,综合考虑来分辨出专家用户。
1 相关工作
1.1 PageRank算法
PageRank算法在1998年由Sergey Brin和Larry Page提出,是一种静态的网页评级算法,可用于提高搜索引擎对网页排序的准确度[11]。主要思想是:
(1)网页i指向网页j的超链接表示对网页j权威的隐含认可,即网页j的权威度与其链入超链接数量成正比关系;
(2)指向网页j的网页i自身权威值对网页j的权威度会产生影响。若高权威值网页i1和低权威值网页i2都指向网页j,则网页i1对网页j权威度的贡献要比网页i2要大些。即一个被其它重要网页所指向的网页也很重要。
将PageRank算法运用于本文的专家发现时,网页代指用户。对于一个社区问答网络,从一个用户出发,链接出去的其它用户的概率为(1-λ);则给定一用户i,其Page-Rank值定义公式如下
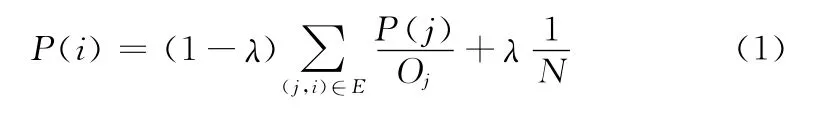
式中:Oj——用户j的出链数。初始值设为:P(i)=1/N,i=1,……,N;λ取值为0.15。故P(i)∈ [0,1]。
1.2 HITS算法
HITS算法在1998年由Jon Kleinberg提出,对网页的评级指标为权威等级 (authority)和中心等级 (hub)。其关键思想是:权威网页和中心网页之间的关系相互影响并促进。即权威等级高的网页会被很多中心等级高的网页所指向,同理中心等级高的网页会被很多权威等级高的网页所指向。
将HITS算法运用于本文的专家发现时,网页代指用户。对于一个社区问答网络,每个用户i的权威分值表示为a(i),中心分值表示为h(i),则两种分值的相互增益关系可表示成公式如下
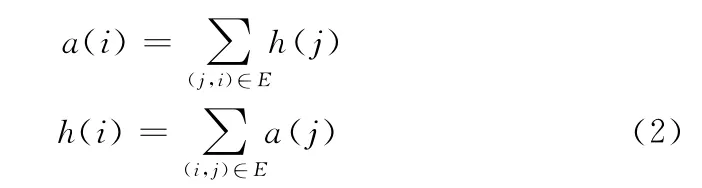
初始值设为:a(i)=h(i)=1,i=1,……,N。每次迭代后,都进行归一化处理∈ [0,1],h(i)∈ [0,1]。
1.3 LDA主题模型
LDA主题模型是一种包含词、主题和文档三层结构的产生式概率模型,其概率图模型如图1所示。LDA生成文档中词的过程是一个概率抽样过程,由参数 (α,β)来确定文档集合中的三层结构,其中参数α控制了文档中不同主题的相对出现概率,参数β调节所有主题中不同词的出现概率分布,其生成文档的具体过程如下:
(1)由参数α确定的Dirichlet(a)分布得到文档d上的主题多项式分布函数θd。
(2)由参数β确定的Dirichlet(β)分布得到主题t上的词多项式分布函数(t)。
(3)循环抽样得到每个文档中的每个单词wdi:
1)从文档d对应的θd中,抽样得到主题t。
2)从主题t对应的(t)中,抽样得到一个单词作为wdi。
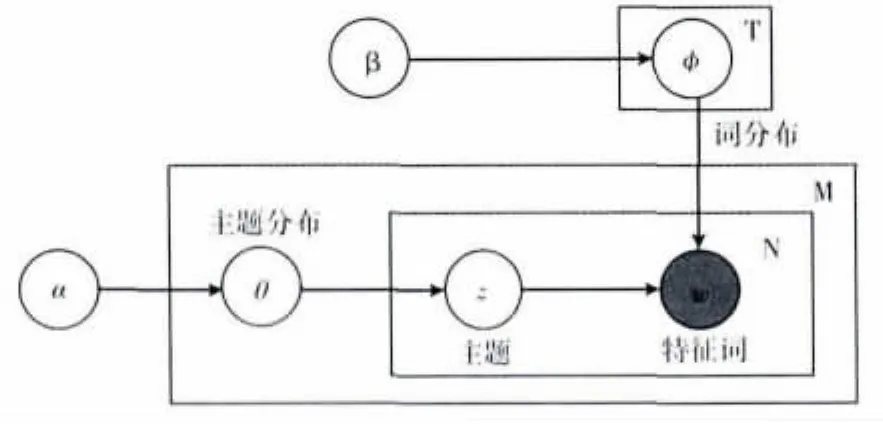
图1 LDA的概率图模型
将LDA主题模型运用于本文的专家发现时,对于类别的主题分布,一篇文档对应为某一类别中所有的问题答案集;对于用户的主题分布,一篇文档对应为某一用户参与的所有的问题和答案。
2 基于类别参与度的专家发现
通过观察百度知道的用户信息,可以从中得出一个结论:大部分专家用户的擅长领域是相近的。图2是从百度知道中截取的两位有代表性的专家用户的信息。第一位专家用户的擅长领域是 “文化教育”,第二位专家用户的擅长领域是 “运动娱乐”。由图2可见,对某一类别领域进行专家发现时,用户u在其它相近的类别参与度,有助于提高在该类别领域的专家得分,故本文提出了一种基于用户类别参与度的社区问答专家发现方法。

图2 百度知道专家用户信息
2.1 系统框架
基于用户类别参与度的专家发现系统的基本流程如图3所示,具体分为以下过程:
(1)根据用户之间提出问题、回答问题的关系,对每一个类别,将社区问答中的用户构建成一个有向图网。
(2)对每一个类别用链接分析算法PageRank和HITS得到用户的初步专家得分。
(3)将每一个类别看成一个文档,利用LDA主题模型来进行训练,得到每一个类别的主题分布,利用KL距离来计算类别之间的相似度。
(4)把用户看成文档,用LDA模型进行推断,得到每一个用户的主题分布,利用KL距离来计算用户对每一个类别的参与度。
(5)根据类别间相似度和用户类别参与度,得到本类别对应的其它相近类别参与度得分。
(6)最后,综合用户在本类别的初步专家得分和其它相近类别的参与度得分,即为最终的本类别专家得分。

图3 基于类别参与度的专家发现系统框架
2.2 网络结构
在社区问答系统中,用户j回答用户i提出的问题q,则用户i和用户j之间存在着链接关系,如图4(a)所示。用户3回答了用户1的问题,则转化为用户1指向用户3的有向边,如图4(b)所示。于是,对每一个类别,根据用户之间提出问题、回答问题,答案对应问题的关系,可以构建成一个用户有向图网。

图4 社区问答用户链接有向图
设类别集合为 C = {c1,c2,...,cn},用户集合为U ={u1,u2,...,um},则给定类别c,可将类别c中的用户网络看作是一个有向图Gc= (Vc,Ec),其中,Vc= {ui}是类别c中所有用户的集合,Ec={eij}是类别c中用户间的有向边集合,eij指用户uj回答了用户ui提出的问题。
2.3 用户类别专家得分
每一位专家用户都有自己感兴趣,并擅长的领域,在社区问答中,会经常参与到对应的类别中为他人提供专业标准的答案。于是,每一个用户在不同的类别中具有不同的初步专家得分。
对每一个类别,先构建一个用户有向图网,再利用链接分析算法,得到初步专家得分。给定类别cj,用户ui,可如下得到用户的初步专家得分。
(1)PageRank算法:PageRank值体现了用户的权威等级,故初步专家得分为对应的PageRank值,即为scorePageRank(ui,cj)=P(i)∈ [0,1]。
(2)HITS算法:权威分值 (Authority)体现了回答者的重要性,中心分值 (Hub)体现了提问者的重要性,故把权威分值作为初步专家得分,即scoreHITS(ui,cj)=a(i)∈ [0,1]。
2.4 类别间相似度
对某一类别领域进行专家发现时,用户u在其它相近类别的参与度,有助于提高在该类别领域的专家得分,故需要得到两两类别间的相似度。
将所有类别的问题答案集看成一个语料集D,每一个类别看成一个文档d,文档的内容为该类别中所有的问题和答案。利用LDA模型,进行训练,可以得到每一个类别对应的K维主题分布p(z|c),K为主题个数。
利用KL距离[12]来计算类别之间的相似度,则类别ci和类别cj的相似度计算公式如下
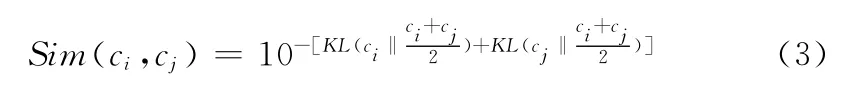
2.5 用户类别参与度
用户类别参与度是指在某一类别领域进行专家发现时,用户在其它相近类别的参与度。由上面得到的类别间相似度,可以得到该类别的相近类别;参与度为用户主题分布和类别主题分布之间的相似性。
先得到用户的主题分布。将所有用户参与的问题和答案作为一个语料集,语料集中的文档个数为用户数量,文档内容为用户的属性,即用户参与的所有的问题和答案。利用LDA模型,进行推断,可以得到每一个用户对应的K维主题分布p(z|u),K为主题个数。
利用KL距离[12]来计算用户对类别的参与度,则用户ui在类别cj中的参与度计算公式如下
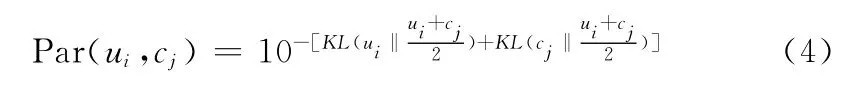
2.6 综合专家得分
除了考虑所属类别回答者的回答质量外,还考虑了相关类别中回答者的回答质量,综合考虑来分辨出专家用户。本文采用线性结合的方法,综合用户在本类别的专家得分和其它相近类别的参与度得分,作为最终的本类别专家得分。
对于用PageRank算法,其综合得分如式 (5)所示

其中,Sim(cj,ck)>λ,λ为判断相近类别的阈值。
同理,用HITS算法时,其综合得分如式 (6)所示
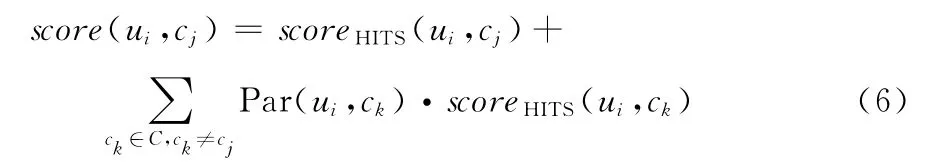
其中,Sim(cj,ck)>λ,λ为判断相近类别的阈值。
由于 Par(ui,cj)∈ (0,1],score(ui,ck)∈ [0,1],故为类别总数。score(ui,cj)值越大,则用户ui在类别cj中称为专家的可能性也越大。
3 实 验
3.1 实验数据
本文采用的实验语料来自Yahoo!Answers网站上抽取的真实标注数据集。去掉匿名用户和匿名者给出的答案,实验语料集共有94596个问题和587354个对应的答案,详细的信息见表1。
3.2 结果评价
本文对比了5种不同的专家发现方法来进行评价本文所提出方法的性能,其中 (2)为文献 [7]中的方法。
(1)HITS:分别对每一个类别,使用HITS算法
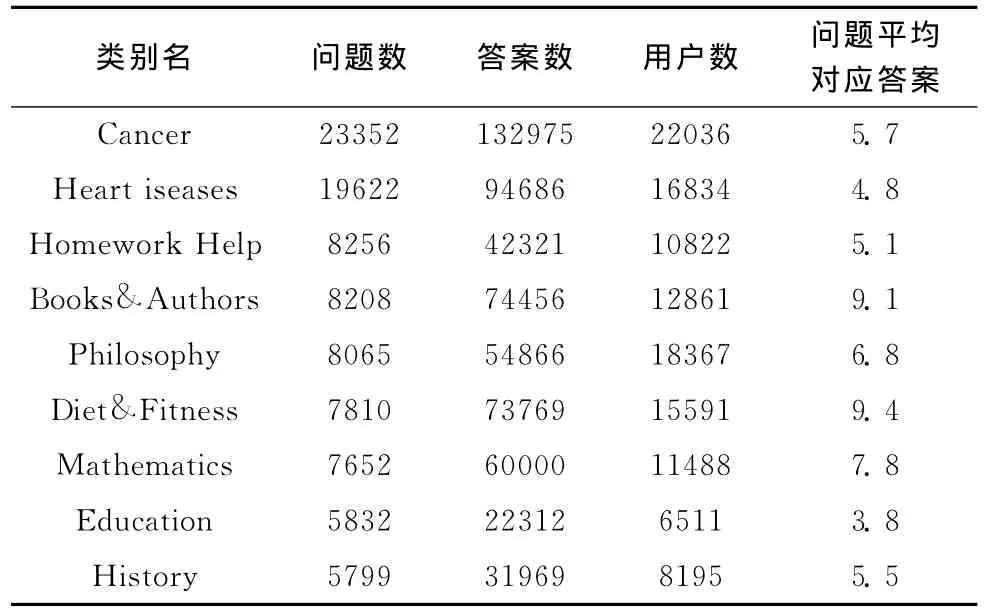
表1 语料集的统计信息情况
(2)WeightHITS[7]:在方法 (1)的基础上,使用带权重的HITS算法
(3)BoostHITS:在方法 (1)的基础上,使用基于类别参与度的HITS算法
(4)PageRank:分别对每一个类别使用PageRank算法
(5)BoostPageRank:在方法 (4)的基础上,使用基于类别参与度的PageRank算法
本文采用AP@10和MAP两种指标来进行结果的评价,得分越高,对应的性能越好。本文的方法与对比实验的方法在评价指标AP@10上的结果如表2所示,在评价指标MAP上的结果如图5所示。

表2 5种方法的AP@10值

图5 5种方法的MAP值
3.3 实验结果分析
本文采用了AP@10指标和MAP指标来评价方法的效果,结果评价数据如表2和图5所示,并对实验结果进行如下分析。
(1)对于常规的PageRank算法和 HITS算法而言,PageRank算法的结果要明显好于HITS算法。这是因为HITS算法有权威分值 (authority)和中心分值 (hub)两个评级,权威分值体现了回答者的重要性,中心分值体现了提问者的重要性,两者是相互关联、耦合的。故一些提问比较多的用户会影响回答者的权威分值。
(2)带权重的HITS算法比常规的HITS算法略好一些,说明用户之间边的连线具有差异性。用户i回答了用户j提出的问题,根据答案是否被选为正确答案,用户j指向用户i的边权重应设为不同,选为正确答案的,边权重应大些。
(3)基于类别参与度的HITS算法比前两个效果又要好一些,说明对某一类别领域进行专家发现,用户u在其它相近的类别参与度,有助于提高在该类别领域的专家得分。进一步证明了本文提出的方法。
(4)基于类别参与度的PageRank算法的效果是最好的,比BoostHITS算法要好很多。这与常规的PageRank算法比HITS算法好很多是相一致的。由于用户有向图的拓扑结构的微小的改动能够明显改变HITS算法得到的权威分值和中心分值,而对于PageRank算法来说几乎没有影响。因此由语料得到的网络图可能会存在影响。
(5)本文进一步采用了MAP指标来进行评价,如图5所示,其结果趋势与AP@10指标的结果趋势是相一致的。每一个类别返回前20个用户,故MAP值也比较高。
3.4 网络图分析
结果分析部分是通过实验得到的数据,来定量地分析本文方法的有效性。为了更直观地分析,利用网络分析工具UCINET来可视化用户网络图,图6为社区问答系统中用户有向网络图。
图6 (a)为类别 “Homework Help”中与15个专家用户有关联的用户构成的有向网络图,图6(b)为所有类别中与15个专家用户有关联的用户构成的有向网络图,图中的小圆点为一般用户,大圆点为专家用户,带箭头的边为用户间的关系,箭头的指向为提问者用户指向回答者用户(意义与图4(b)一致),而且两图中专家用户的位置是一一对应的。从图6中可以看出,加入其它参与类别的信息后,专家用户的入度数更多了,更容易成为一个小网络的中心,即权威性也有所提高,从而更有效地进行专家发现。
表3 为图6中用户的入度数。可知,加入其它参与类别的用户后,15个专家用户的平均入度数增加了一倍多,而且整个网络用户的平均入度数也有所增加。说明专家用户在其它类别的参与度也是非常多的,因此,利用用户在其它类别的参与度信息可以有效地提高本类别的专家发现水平。
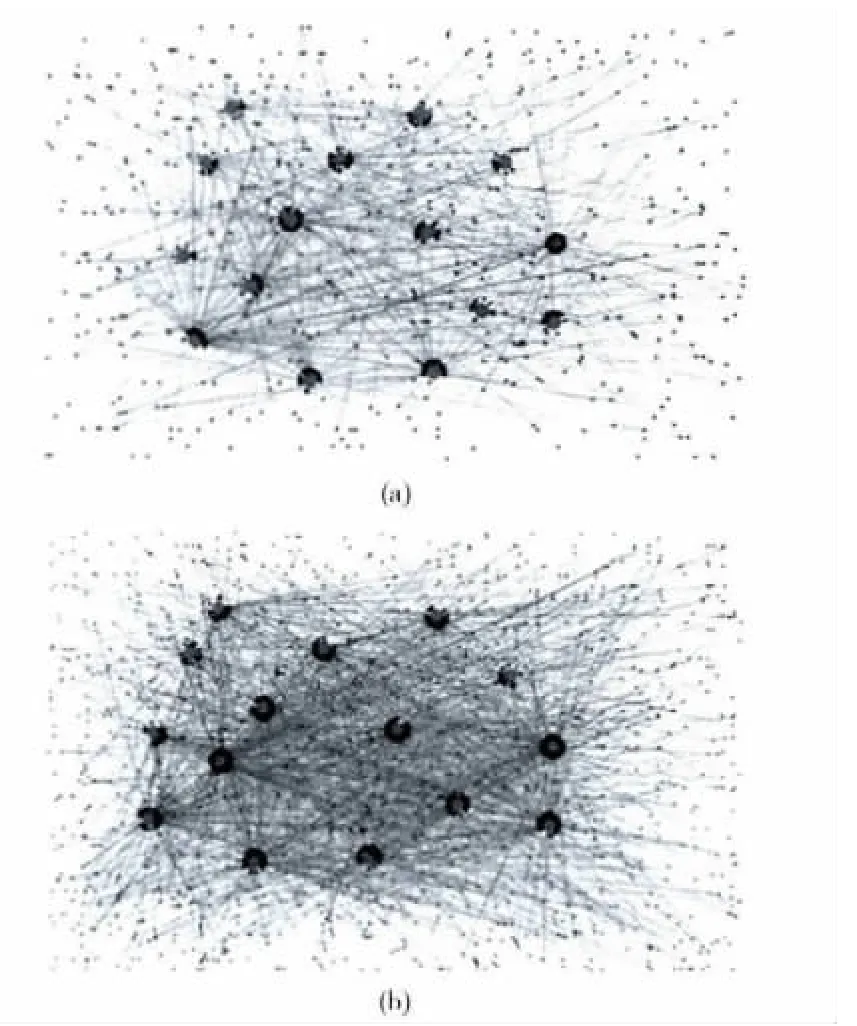
图6 社区问答系统中用户有向网络

表3 社区问答系统中用户入度数
4 结束语
本文提出了一种基于用户类别参与度的方法,来帮助辨别社区问答中的专家用户。首先利用链接分析方法Page-Rank和HITS分别计算用户在每一个参与类别的专家得分,然后由LDA模型得到类别和用户的主题分布,再利用KL距离函数得到类别间的相似度和用户对每一个参与类别的参与度得分,最后线性综合用户在本类别的专家得分与其它相近类别的参与度得分即为用户在该类别的最终得分。如实验部分所述,本文所述的专家发现方法显示出了良好的性能。该方法能够很好地挖掘出兴趣、爱好和擅长领域相近的专家用户,但对于擅长领域差异比较大的、或是没有交集的专家用户,本方法还有待于改进,这也是今后需要进一步研究的方向。
[1]Chen Lin,Nayak R.Expertise analysis in a question answer portal for author ranking [C]//Washington,USA:Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology,2008:134-140.
[2]Kao Weichen,Liu Duenren,Wang Shiuwen.Expert finding in question-answering websites:A novel hybrid Approach [C]//Sierre,Switzerland:Proceedings of the ACM Symposium on Applied Computing,2010:867-871.
[3]Riahi F,Zolaktaf Z,Shafiei M,et al.Finding expert users in community question answering [C]//Lyon,France:Proceedings of the 21st International Conference Companion on World Wide Web,2012:791-798.
[4]Qu Mingcheng,Qiu Guang,He Xiaofei,et al.Probabilistic question recommendation for question answering communities[C]//CM:Proceedings of the 18th International Conference on World Wide Web,2009:1229-1230.
[5]LIU Mingrong,LIU Yicen,YANG Qing.Predicting best answerers for new questions in community question answering[M].Web-Age Information Management.Springer Berlin Heidelberg,2010:127-138.
[6]Jurczyk P,Agichtein E.Discovering authorities in question answer communities by using link analysis[C]//Lisboa,Portugal:Proceedings of the 16th ACM Conference on Conference on Information and Knowledge Management,2007:919-922.
[7]Jie Shen,Wen Shen,Xin Fan.Recommending experts in Q & A communities by weighted HITS algorithm [C]//Chengdu,China:International Forum on Information Technology and Applications,2009:151-154.
[8]Liu Jing,Song Y I,Lin C Y.Competition-based user exper-tise score estimation [C]//Beijing,China:Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval,2011:425-434.
[9]Aditya P,Rosta F,Joseph A K,et al.Early detection of potential experts in question answering communities [C]//Girona,Spain:Proceedings of the 19th of User Modeling,Adaptation and Personalization,2011:231-242.
[10]Aditya P,Joseph A K.Expert identification in community question answering:Exploring question selection bias[C]//Toronto,Canada:Proceedings of the 19th ACM International Conference on Information and Knowledge Management,2010:1505-1508.
[11]GUO Qingbao,JIA Daiping.Improved PageRank algorithm of merging feedback information and topical relationship [J].Computer Engineering and Design,2011,32 (12):4071-4074(in Chinese).[郭庆宝,贾代平.融合反馈信息与内容相关度的PageRank改进算法 [J].计算机工程与设计,2011,32 (12):4071-4074.]
[12]Celikyilmaz A,Tur D H,Tur G.LDA based similarity modeling for question answering [C]//Stroudsburg,PA,USA:Proceedings of the NAACL HLT Workshop on Semantic Search,2010:1-9.
