试题难度的主观预估方法
2014-11-28杨涛辛涛杨婷婷
杨涛 辛涛 杨婷婷
试题难度的主观预估方法
杨涛 辛涛 杨婷婷
试题难度一般通过实际测试考生而获得,但这种预试方法的实施具有一定局限性。难度的主观预估方法无需依赖考生,主要由学科专家根据经验对试题难度进行预测,因此在中、高考等考试实践中受到广泛应用。在研究和实践中,研究者们不断完善主观预估法,并提出不同的估计方法。本文对传统的主观评判法与配对比较的难度估计法进行介绍,以期更系统地认识难度的主观预估方法,促进主观预估法在考试实践中的应用。
试题难度;主观预估;主观评判法;配对比较
1 引言
试题难度是评价试题质量的重要指标,难度的准确估计对测验编制或题库建立都有重要意义。在不同的测量理论框架下,试题难度的含义存在差异。经典测量理论(Classic Test Theory,CTT)用受测考生样本在试题上的通过率表示题目难度。项目反应理论(Item Response Theory,IRT)用项目反应函数表示考生正确作答的概率与考生能力间的关系,每个项目反应函数对应一道题目,项目反应函数的曲线——项目特征曲线的拐点位置反映了该题的难度。相比而言,IRT框架下的难度更客观地体现试题难度。
无论是CTT或IRT框架下的难度参数,都需要通过预试获得。然而预试也存在一定局限性:预试必然涉及大量的人力物力投入,这要求考试项目有足够的资金支持;预试过程中很多人提前接触到考题,这可能引起考试安全隐患。于是,一些学者尝试探索不依赖预试的难度预估方法。早期的难度预估主要依赖专家主观经验直接判断试题难度,这一系列方法统一称为主观评判法。项目反应理论的发展促使研究者们探索新方法,进而更有效地利用专家评判的信息,因此又发展出配对比较的IRT模型(Paired comparison IRT model),即配对比较法。除了上述两种主观预估方法外,研究者们还提出建立估计模型(主要包括多元回归分析模型与人工神经网络模型)预测试题难度(Perkins,Gupta&Tammana,1995;Gorin&Embretson,2006;余嘉元,2002),并取得一些可喜的进展,但是,研究者们也指出模型预估法大多处于模拟研究或理论探讨阶段,在现实考试情境中应用的可操作性有待进一步验证(孙恒李和金波,2008)。本文拟系统地介绍主观评判法与配对比较法,评述这两种类方法特点,并对其在今后的研究与应用进行展望。
2 难度预估方法的介绍
2.1 主观评判法
主观评判法是指命题人员或学科专家根据个人的经验、观点等,直接对题目的难易程度做出主观的判断。这种方法是比较传统、广泛使用的一种难度预估法,早在1928年Farmer就尝试采取专家主观评判的方法估计题目难度。主观评判难度虽然不像预试那样工程浩大,但是其具体实施也涵盖很多细节,需要一一考虑:试题难度值的不同界定;主观评判过程中的影响因素;如何评价难度估计准确性的标准。
2.1.1主观评判法下的难度估计法
主观评判的难度并非通过CTT或IRT理论计算出来,因此难度值的具体涵义也与这两种理论框架下的难度存在差异。我国研究者针对标准参照测验提出基于作答影响因素的难度评估,例如卢正勇(1991)提出的考试试题的内容难度估计——按教学目标要求衡量的试题难易程度的指标,主要依据试题所属的认知水平层次,试题考核的知识面、知识深度,解题的推理步数、技能技巧等方面综合评定。命题教师通过讨论试题在上述属性上的特征,对试题赋予难度等级(1~9级),九等级分别对应0.1~0.9九级内容难度指标。相似地,申亚全和张守臣(1996)提出了绝对难度估计的概念,此难度与考生群体无关,完全依据题目自身的属性而确定。这一难度概念与内容难度相似,但是其评估过程更为细致,将影响试题绝对难度的每种因素划分为5个层次,形成评价的指标体系,请专家对指标进行评定,最后依据简单的公式获得绝对难度。
除内容难度和绝对难度外,柳博(2007)介绍了目前考试中采用的一种难度——预估难度。内容难度与绝对难度都主要从试题本身的因素来评估难度,而预估难度还进一步考虑到了考生样本的因素。预估难度的估计是指在命题时由命题教师根据试题内容和标准常模的答对概率,综合考虑各种影响难度的因素进行评估而得出的试题难度。这种难度也是针对标准参照测验提出的,其中“标准常模”(或“标准团体”)是个重要的概念,这是指刚好达标的学生群体,主要通过命题教师来构建。难度评估专家的任务就是评价对于标准常模而言试题的难度。预估难度同时考虑了试题内容与标准常模的作答反应两个方面,比较全面地体现了考试作为标准参照测验的难度内涵,并且也将控制自学考试及格标准的思想融入命题过程(田霖和王桥影,2010)。
在形式上,主观评判法最终获得的难度值可能是简单的等级评定,也可能是接近于连续量表的百分评定(如1~100分评分),因此其难度值的形似CTT中的难度;但是从其内涵考虑,正如柳博(2007)所形容的,内容难度、预估难度与IRT的难度“神似”。
2.1.2主观评判过程中的影响因素
主观评判法中评判人员起着关键的作用,一般而言,评判“专家”是考试的命题组成员,可能是学科教师或学科专家,并且对该学科的考试或命题有一定实践经验。专家的专业程度、对试题的剖析以及专家数量等都将影响难度估计的结果。Quereshi和Fisher(1977)的研究发现,当以试题的实测难度值(CTT难度)作为参考评价标准,不同专家对试题难度的估计准确性存在差异。分析专家预估难度的书写报告发现,对题目内容、结构展开更深入分析的专家,其难度预估的准确性更理想。因此选拔高水平的评判专家对命题与试题难度预估有重要意义,高水平不一定要求其科研能力高,柳博(2007)指出高水平的专家应当具备的特点为:教学经验丰富,长期从事考试课程的教学,了解学生的学习状况等。此外,评判人员的数量也是一个重要的考虑因素。Bejar(1983)认为专家评判员的数量增多也有益于提高难度估计的准确性。不过卢正勇(1991)的研究却发现将专家分为两人一组,以两人对难度等级的独立评判值的均值作为试题内容难度的估计值就可以有效提高估计效果,其结果与三人或者四人一组的估计效果差不多。
主观预估难度时一般都有多名专家参与难度预估工作,为了确保专家对难度估计的准确性与一致性,在难度预估前对专家进行统一的培训非常有必要。一般而言,刚开始时专家们需要经过共同讨论,对难度的影响因素以及评估的标准、方法达到一致的意见,然后再选取有代表性的试题进行难度估计的练习,练习包括独立练习与共同讨论环节,期间可以提供这些试题的实测信息作为参考,而后评判专家们相互交流自己在难度估计过程中的认识与观点,经过多次的练习与讨论专家们形成的统一的评定标准后方可展开正式的难度预估工作。当然,培训过程中培训者若给予适当的指导也将起到有利作用,Quereshi等(1977)认为请专家预估难度前先作答试题有助于专家对任务的思考,要求专家写下详细的评判规则等都可能有助于达到更精确的估计。
不过,即使专家的培训工作很充分,专家们对难度评定的标准达到一致意见,难度预估的结果也未必准确。难度预估工作的组织者或者评判专家们需要在难度预估工作中明确影响难度的试题因素有哪些、从而确定最有效的试题参数预估方法。在自学考试中,申亚全等认为影响难度的因素包括:试题涵盖的知识点多少,试题考核的认知目标的层度,试题解答的心理加工过程,正确表征问题所需要的技巧。柳博(2007)认为除了以上几点,还应当重点从题型角度分析题目。在不同的学科,研究者们都对影响难度的因素进行了深入的探讨,如研究成果比较丰富的图形推理测验(Embretson,2002;李中权等人,2011)、数学测验(辛自强,2003;鲁庆云和宋乃庆,2009)。因为影响试题难度的因素很多,目前也没有比较统一或令人信服的观点,所以实际中,专家经常根据自己的经验来预估试题难度,这种做法当然不可取。笔者认为以后的研究者可以从认知分析的角度提出一种通用的理论模型,确定影响难度因素有哪些方面,该理论模型提供一个适用于不同类型的题目的大框架,并允许实践者再根据测试目的与测试内容的不同,细化或者调整难度影响因素。事实上,有部分研究者已经在朝着这一方向展开研究。例如,朱行建(2010)主张采用教育心理学家Biggs的SOLO评价法(Structure of the Observed Learning Outcome)来预估试题的难度;认知心理学界应用认知任务分析技术(Cogni⁃tive Task Analysis,CTA)建立对试题难度进行事前认知任务分析的系统方法。不过,研究者们还需要探讨这些方法在不同学科中的适用情况,才能将其广泛推广。
2.1.3如何评价难度预估的准确性
根据难度类型的不同,预估结果的准确性评判也有不同的标准。评价者间的信度(一致性系数)是很多研究中通用的一个指标(Bejar,1983;卢正勇,1991;邵志芳和余岚,2008),若评价者间的信度较高,表明难度预估前的培训有一定作用,专家们对难度估计的标准、影响试题难度的因素有比较统一的看法。除此之外,当期望预估的难度是考生在某道题上的通过率时(CTT的难度值),那么研究者就直接以实测的难度值作为评判预估值准确性的指标(Quereshi et al.,1977;东晓华和赵凤敏,2010)。然而对于“内容难度”与“预估难度”而言,专家们需要预估的不是整个考生群体在实际考试中的实测难度,而是从试题内容本身出发进行难度估计,所以有研究者认为这种情况下不应该将实测难度与预估难度的吻合度作为其准确性的衡量指标。对于预估难度而言,除非能证明统计实测难度时选取的考生样本与标准常模的特征高度吻合,才可以用实测难度来替代预估难度,由于这种“高度吻合”的样本难于界定,所以预估难度的的精确性验证很困难(柳博,2009)。
总体而言,虽然传统的主观评判法很早就受关注,应用很广泛,但是在实践中仍然存在很多需要解决的问题。例如,评判专家的选择标准,专家人数多少最为合适;专家培训的规范性流程,培训细节(如是否需要提供实测数据,判断培训结束的标准等);难度预估结果的准确性评价。关于主观评判法操作的规范化流程,笔者建议可以借鉴标准设定的相关研究成果[如Steps for Setting Standards with the Angoff Method(Arrasmith,D.G.,Hambleton,R.K.1988)①标准设定。]。此外,田霖和王桥影(2010)还提到开发难度影响因素的模型,并对其进行验证;试题难度的等值研究,如何将预估难度赋值用于题库建设等。
2.2 配对比较的难度估计法
IRT因其获得的试题参数以及能力参数具有恒定性,被广泛地应用于很多大规模的考试,如TOEFL、GRE考试。(van der Linden,1986)。为了更科学地编制测验,人们开始组建基于IRT模型的题库,从题库中选择已知参数的题目便可组织出满足要求的试卷。题库中的试题参数需要经过大规模的样本试测获得,然后再经过等值方法将所有参数校准到同一量尺上。大样本试测意味着存在试题泄露的可能性,针对这一问题,Ozaki&Toyoda(2006)提出一种新的主观预估难度方法,他们将Thurstone(1927)的配对比较法引入到专家对难度预估的工作中。在配对比较的估计法中,专家只需要对试题对逐个进行难度比较,最后使用改良的IRT模型分析试题配对比较的数据,最后便可计算出每道题的IRT参数。
2.2.1配对比较的难度估计法介绍
总结Ozaki&Toyoda(2006)的方法,以最简单的配对比较模型为例,配对比较的难度估计法包括以下步骤:(1)构造试题对,假如有n道待估计的题目,将所有试题两两组合,相应的待比较试题对有个。(2)请专家专家一一比较试题对,对于题目i与题目j,评判专家可以作出的判断为“题目i比题目j难”或“题目i比题目j容易”。(3)IRT模型的构建,
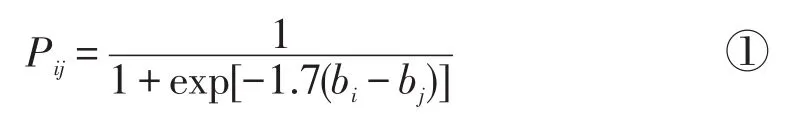
上式中,Pij代表题目i比题目j难的概率,bi是题目i的难度,bj是题目j的难度;类似于IRT模型,Qij=1-Pij,代表题目i比题目j容易的概率。该式与传统IRT模型不同的是,没有潜在能力(θ)这个未知数,因此作者假定对于所有评分者,方程是相同的。(4)参数计算,定义nij0是认为题目i比题目j难的评判者人数,nij1是认为题目i比j容易的人数,m是总题量假定uij是所有评判者对试题对评定的反应向量,则向量uij的似然方程为,

可见,该模型与传统IRT模型相似,不过这里它假定评判者对各个试题对的评定是相互独立的。接下来的计算方法与传统IRT相同,针对各个未知数对似然函数求导,令导函数的值都为零,然后同时求解方程获得题目参数。
Ozaki等人(2006)认为当专家比较试题对的难度时,还可能出现一种反应结果是2道题没有难度差异,因此他们将原始的2值评定改为三值评定:“题目i比题目j难”、“题目i与题目j难度相当”或“题目i比题目j容易”。此时当评判者k在比较题目i比题目j的难度,存在一个判断标准指标θijk,θijk服从正态分布,记为,其中对于所有θijk,σ2假定为已知的常数值(Ozaki等的研究中将其值设为1)。那么此时评判者认为题目i容易的概率(比标准θijk难)是,
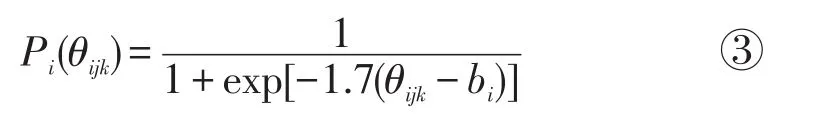
记 Qi(θijk)=1-Pi(θijk)(代表将题目i判断为难的概率),同样地当判断题目j为容易的概率记为Pj(θijk) ,那 么 此 时 bi>bj、bi=bj、bi<bj的 概 率 分 别 为Qi(θijk)Pj(θijk)、Pi(θijk)Pj(θijk)+Qi(θijk)Qj(θijk)、Pi(θijk)Qj(θijk)。接着仍然借鉴IRT似然函数的构建方法建立似然函数,再求解方程,这里不再累述,不过在计算过程中需要消除θ参数。
2.2.2配对比较预估法的影响因素
配对比较的预估方法是一种比较新颖的难度预估法,但它和传统的主观评判法一样,也受到主试选拔培训、难度影响要素的确定等因素的影响。除此之外,它还受到待估计的题目总量、已知的固定参数数量、试题难度值本身的大小等多方面的影响。例如Ozaki等人(2006)的模拟研究表明,当待估计题量为15题时(每位专家需要判断105个试题对),随着评判专家数量的增多,参数估计越准确。不过尽管评判专家为20名时,配对比较法获得的参数估计值与实测的IRT参数值也很相近。而当专家数量一定时,题目数量越多,参数估计越准确。计算题目参数过程时,若固定部分题目的参数,对剩余题目参数的估计有一定帮助,固定参数的题目量越多,剩余题目的参数估计越准确,实证研究也证明了这一点。另外作者还有个有趣的发现,对于一批试题,处于难度均值附近的题目,其参数估计的准确性更高,其原因可能是这些题目有更多的机会与相似难度的题目进行比较,从而能获得更高的信息量,这类似于IRT中当题目难度与被试能力接近时,被试能力的估计值更准确。为了提高参数估计的准确性,Ozaki和Toyoda(2009)又提出一种改进模型,研究者从题库中选择出数道难度顺序已知的题目,然后请专家判断一道新题在这一批题中的难度序列,最后根据等级反应模型(一种适用于多值计分题的IRT模型)计算出题目的参数。
当然,该方法的应用也存在一些局限性。首先,该法要求每位专家对所有可能的试题对进行判断,所以不适用于题量过多的难度预估,否则评判专家的需要评判的任务量就过重。其次,这个方法的假设条件过多,例如专家对各个试题对的评价是独立的、专家进行难度估计时的评价标准满足正态分布(现实是为了避免试题泄露,评判专家数量一般比较少)、专家评判过程中出错率比较低。这些假设在实际中能否满足,如果不满足又将带来什么影响,这些都需要我们思考、验证。此外,这种方法刚刚起步,还有待更多的研究证明它的有效性,验证其适用于各种类型的题目。
3 难度主观预估方法的评析与展望
无论是传统的主观评判法还是配对比较的方法,都能有效地避免题目过度曝光于公众,并且难度估计的有效性也得到部分研究的证明。相对而言,主观评判法的原理简单,适用范围广泛,并且人们在长期的实践中积累了相当丰富的经验,许多考试在命题过程中一直采用此法预估试题难度。而配对比较法的发展较晚,将来还需要更多的研究进行验证,从数据获得的来源角度看,该方法与传统的主观评判法一样,只依赖于专家对题目的主观评判。但是它具备一些独特的优势:(1)简化了专家的任务。在配对比较的预估方法中,专家的任务要简单得多,只需要对题目的难度进行两两排序,然后通过模型就可以计算出连续的难度参数;然而主观评判法中,专家需要直接对每道题做出等级判断或者给出连续量表上的参数值。(2)更科学地获得IRT参数。从理论上讲,传统的主观评判法适用性极强,适用于预估任何题型、任何学科的难度,包括CTT与IRT框架下的难度,但若想预估IRT的难度估计,前期的培训工作将很复杂,评判专家需要具备扎实的高级测量理论知识,深入理解IRT理论。配对比较法完全可以借助计算机程序,从而通过简单的判断数据获得IRT参数。(3)可以实现参数的等值。Ozaki等人(2006)在其模拟研究中已经证明当采用固定某些题目的参数时,可实现其余题目的估计参数与旧题的参数处于同一量尺上。传统主观评判法的等值则尚待进一步的研究探讨。
当然两种方法都存在值得进一步深入探讨、改进的空间。因为本文探讨的难度估计法都是依赖于评判人员,所以评判人员的培训至关重要,以后的研究者可以探讨如何标准化培训工作从而获得最有效的培训结果。特别是对于传统的主观评判法而言,评判人员直接决定着评判工作的准确性,因此如何对评判专家进行培训,实现偏差最小化是重中之重。为了有效指导评判人员开展难度预估工作,确定题目难度的影响因素是必备的前提。这两种主观预估法各自也存在一些待解决的问题,例如,主观评判法中重视“标准常模”的运用,但是这个标准常模的界定却很含糊,目前也没有出现很明确的方法(田霖和王桥影,2010);经过适当的培训后,这种方法是否适用于估计IRT理论下的难度参数也还未知。根据目前的研究和实践结果,配对比较的预估法适用于小规模的难度预估,那么小型的考试实践可考虑将其采纳到实际工作中,并在实践中进一步改进方法。此外,配对比较法中存在着许多的假设性条件,为了验证这一方法的科学性与适用性,有必要对这些假设条件的违背进行一一试验。
试题难度的预估是命题、题库建立的重要工作,确保难度预估的准确性具有重要的实践意义,本文介绍的两种主观预估方法均适用于保密要求较高的考试(例如中考、高考),研究者可以依据考试的特点与实际条件的许可选择合适的方法,从而更好地为实践服务。
[1]Bejar,I.I.Subject matter experts'assessment of item statistics[J].Applied Psychological Measurement,1983(3):303-310.
[2]Embretson,S.E.Generating abstract reasoning item with cognitive theory.In S.H.Irvine,&P.C.Kyllonen(Eds.),Item generation for test development(pp.219–250)[C].Mahwah,NJ:Lawrence Erl⁃baum Associates Publishers.2002.
[3]Farmer,E.Concerning the subjective judgement of difficulty[J].British Journal of Psychology,1928(18):438-442.
[4]Gorin,J.S.,&Embretson,S.E.Item difficulty modeling of para⁃graph comprehension items[J].Applied Psychological Measure⁃ment,2006,30(5):395-411.
[5]Ozaki,K.,&Toyoda,H.A Paired comparison IRT model by 3-val⁃ue judgment:Estimation of item parameters prior to the administra⁃tion of the test[J].Behaviormetrika,2006(33):131-147.
[6]Ozaki,K.,&Toyoda,H.Item diff i culty parameter estimation using the idea of the graded response model and computerized adaptive testing[J].Japanese Psychological Research,2009,51(1):1-12.
[7]Perkins,K.,Gupta,L.&Tammana,R.Predicting item difficulty in a reading comprehension test with an artificial neural network[J].Language Testing,1995,12(2):34-53.
[8]Quereshi,M.Y.&Fisher,T.L.Logical versus empirical estimates of item difficulty[J].Educational and Psychological Measurement,1977(37):91-100.
[9]Thurstone,L.L.(1927).A law of comparative judgement[J].Psy⁃chological Review,34:273-286.
[10]van der Linden,W.J.The changing conception of measurement in education and psychology[J].applied psychological measurement,1986,10(4):325-332.
[11]戴海崎.高等教育自学考试命题难度的标准团体控制法研究[J].江西师范大学学报(哲学社会科学版),1994,27(1):89-93.
[12]东晓华,赵凤敏.高等教育自学考试命题预估难度准确性研究[J].中国高等教育,2010(13):68-69.
[13]韩菡.基于人工神经网络预测汉语阅读理解测验题目难易度的研究[D].北京语言大学,2005.
[14]李中权,王力,张厚粲,周仁来.不同认知成分在图形推理测验项目难度预测中的作用[J].心理学报,2011,43(9):1087−1094.
[15]柳博.预估难度一种自学考试的试题难度确定方法[J].中国考试,2007(7):29-30.
[16]柳博.预估难度的理论模型及应用探析[J].中国考试.2009(4):3-7.
[17]鲁庆云,宋乃庆.我国数学试题难度影响因素的研究综述[J].数学通报,2009,48(4):47-49.
[18]卢正勇.标准参考性考试试题的内容难度及其专家共同评判法[J].应用统计概率,1991,7(2):201-208.
[19]毛竞飞.高考命题中试题难度预测方法探索[J].教育科学,2008,24(6):22-26.
[20]全国高等教育自学考试指导委员会.高等教育自学考试命题工作手册[M].北京:中国财政经济出版社,2005.
[21]邵志芳,余岚.试题难度的事前认知任务分析[J].心理科学,2008(3):696-698.
[22]申亚权,张守臣.目标参照测验的难度及其估计[J].中国考试(高考版),1996(3):11-12.
[23]孙恒李,金波.高考试题难度的预估研究[J].教育理论与实践,2008(10):3-5.
[24]田霖,王桥影.自学考试的试题难度赋值方法评述[J].中国考试,2010(4):24-30.
[25]辛自强.关系——表征复杂性模型的检验[J].心理学报,2003(4):504-513.
[26]余嘉元.基于联结主义的连续记分IRT模型的项目参数和被试能力估计[J].心理学报,2002,34(4):193-199.
[27]朱行建.SOLO评价:一种试题难度预估的新方法[J].教学与管理,2010(25):76-77.
Subjective Prediction Methods of Item Difficulty Estimation
YANG Tao,XIN Tao and YANG Tingting
Item difficulty is usually estimated by field test,which has some limits in practice.Subjective prediction of item difficulty doesn't need real examinees,these approaches obtain estimates mainly depending on the subject experts'experience,So subjective prediction approaches are widely applied in many test programs.And researches have proposed different subjective prediction methods based on research and test practice.This article attemps to review two of those methods systematically:direct prediction of item difficulty by experts,paired comparison method,then put forwards some advice on future directions and implementation of the methods in practice.
Iitem Difficulty;Subjective Prediction;Direct Prediction of Item Difficulty by Experts;Paired Comparison Method
G405
A
1005-8427(2014)02-0003-7
杨 涛,女,北京师范大学教育统计与测量研究所,讲师,博士(北京 100875)
辛 涛,男,北京师范大学发展心理研究所,教授,博士(北京 100875)
杨婷婷,女,北京师范大学认知神经科学与学习国家重点实验室,研究生,硕士(北京 100875)
