一种基于MapReduce 的并行聚类模型
2014-11-26顾瑞春王静宇
顾瑞春,王静宇
(1.内蒙古科技大学内蒙古白云鄂博矿多金属资源综合利用重点实验室,内蒙古 包头 014010;2.内蒙古科技大学信息办与网络中心,内蒙古 包头 014010)
0 引言
数据挖掘是从海量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。随着网络技术的不断发展和各种应用爆炸式增长,随之产生的数据量也急速膨胀,使用传统的单机存储和串行数据挖掘算法已经无法在有效时间内发现重要信息,而云计算具有海量的存储能力和弹性化的计算能力,因此在数据挖掘领域逐渐发挥出其显著优势。Hadoop 平台是Apache 推出的开源云计算平台,是Google 云计算平台的开源实现。
1 MapReduce 简介
MapReduce 是Google 公司提出的一项极富盛名的并行软件框架,是基于分布式文件系统之上的并行编程模型,是目前各种云计算平台的基础模型。该模型的核心操作是2 个函数Map 和Reduce。这2 个函数均可高度并行运行,Map 函数用来处理多份数据,并把一组键值(Key/Value)对映射成一组新的键值(Key/Value)对,Map 函数的输出作为Reduce 的输入,由并发的Reduce 函数来保证所有映射键值(Key/Value)对中的每一组都具有相同的Key 键值[1-3]。

图1 MapReduce 工作模式
图1 是MapReduce 的工作模式。将大数据集分解成为成百上千的小数据集splits,每个(或若干个)数据集分别由集群中的一个节点执行Map 计算任务并生成中间结果,然后这些中间结果又由大量的并行执行的Reduce 计算任务进行处理,形成最终结果后输出给用户[4-7]。
MapReduce 模型主要是针对海量数据的高效并行处理,相对传统的并行分布式计算模型而言,该模型由底层封装任务分配、并行处理以及容错等细节问题,开发者仅需关注自身要解决的分布式计算任务的表述即可,极大地简化了分布式程序设计[8-9]。本文的MapReduce 模型采用CADD 算法作为原型算法进行并行聚类分析,用以对海量数据进行处理。
2 CADD 算法介绍
基于密度和自适应密度可达算法(Clustering Alogrithm base on Density and Adaptive Dentsity-reachable,CADD)在聚类过程中,首先利用高斯密度函数f(xi)=计算数据集D 中每个数据点xi(i=1,2,…,n)的密度值,其中σ 为密度参数,决定密度函数的变化梯度[10-11]。然后,寻找局部密度最大吸引点QdensityMax,将其作为第一个簇中心,根据初始密度可达半径R0,得到第一个密度可达簇C1,如图2所示;然后在C1 簇之外的数据点中搜索次级局部密度最大点,将其作为第二个促中心,根据自适应密度可达半径Radaptive 得到第二个密度可达簇C2,以此类推,直到将所有满足条件的数据点都聚集到相应的簇中,如C3;最后把不属于任何簇的数据点标记为孤立点O0。
为了能够提升聚类效率,充分利用闲置资源,采用孟海东[10]等提出使用MPI 方式将CADD 算法并行化,得到了较好结果。本文采用更为高效的Hadoop平台下的MapReduce 框架来进行CADD 聚类的并行化处理。

图2 CADD 算法聚类簇
3 MapReduce 聚类模型
基于MapReduce 的并行聚类模型难点在于规划不同输入与输出的键值(Key/Value)对,海量数据的聚类挖掘则需要考虑采用多个Mapreduce 过程来处理,上一个Mapreduce 过程的输出作为下一个Mapreduce 过程的输入。该模型采用3 个MapReduce 步骤来实现[12-14]。
步骤1 数据准备。
根据计算节点的数量对海量原始数据集D 进行划分,形成p 个子数据集D1,D2,…,Dp(p 为节点个数或进程数),然后使用MapReduce 模式对其进行并行处理。
(1)Map 处理:确定各个子数据集的Key/Value键值对。
(2)Reduce 处理:将Map 处理后输出的Key/Value 对按照Key 进行排序,将Key 键相同的数据统一由一个Reduce 进行处理,保存输出结果,作为下一个步骤的输入数据。
步骤2 并行聚类。
对第一步处理输出的结果分别进行CADD 聚类,形成多个局部聚类结果,再次进行MapReduce 处理。
(1)Map 处理:每个Mapper 以CADD 聚类后的局部聚类结果作为输入,并以簇中心作为Key 值,存储中间数据。
(2)Reduce 处理:对CADD 聚类处理后的数据进行Reduce 处理,输出数据中,对所有相同簇中心的各个簇进行合并,形成新的聚类簇。输出并存储结果,作为下一次处理的输入数据。
步骤3 合并结果。
将步骤2 处理输出结果作为输入,进行MapReduce 处理,该步骤使用多个Mapper 函数,该步骤的Reduce 阶段仅使用一个Reducer 处理函数,根据不同特征值合并后的数据数量,将所有聚类结果根据聚类特征键值进行合并,形成最终处理结果。
(1)Map 处理:每个Mapper 以第二步输出的中间结果作为输入,以新的聚类簇中心点作为Key 值,存储中间数据;
(2)Reduce 处理:最后一步的Reduce 过程中,使用一种改进的BIRCH[15]算法聚类特征,将Mapper 传来的具有聚类簇进行特征值提取,并对具有相同特征值的聚类簇进行合并,仅适用一个Reducer 函数,对合并后的数据,形成最终聚类结果。
整个流程如图3 所示。

图3 MapReduce 处理过程
4 实验结果与分析
使用Hadoop 平台对该聚类模型进行测试,Hadoop 是Google 云计算平台的Java 开源实现,其核心主要包括HDFS、MapReduce 和HBase。
实验使用5 台计算机,装有Ubuntu Linux 10.10,Hadoop 版本选用1.0.3。其中,1 台机器作为Master和JobTracker 服务节点,其他4 台机器作为Slave 和TaskTracker 服务节点,5 台计算机使用1 台普通百兆交换机进行连接,具体的硬件配置和基本配置如表1和表2 所示。

表1 各个节点硬件配置情况
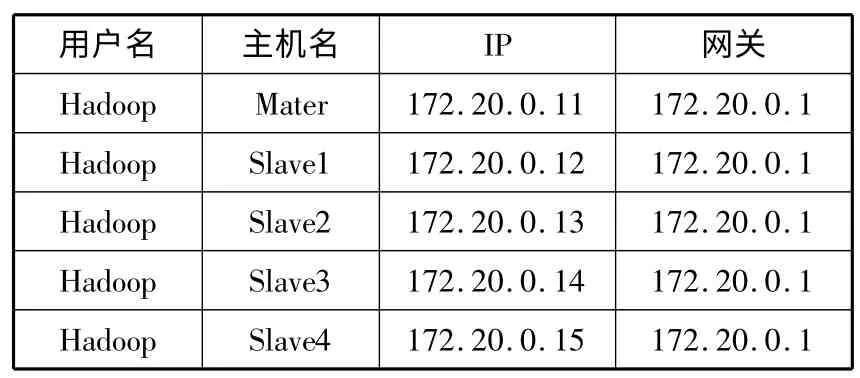
表2 各个节点基本设置情况
实验数据采用一组内蒙古科技大学校园计费系统日志数据,数据中包含用户名、用户IP、登录时间、目标URI 等数据。逐渐增加数据量,分别使用单机和MapReduce 并行处理,进行对比。如图4 所示。
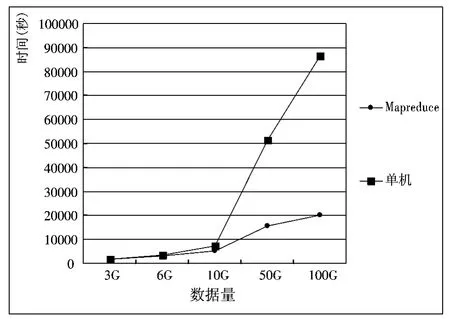
图4 二种处理方式效率对比
结果显示,当处理较小数据量时,Hadoop 集群系统处理效率并不占优势,但是当采用较大数据时,具有良好的收敛性能,且聚类时间大大缩短,聚类效率显著提高。
5 结束语
本文采用MapReduce 架构可高效并行的优势,设计了一种基于MapReduce 的并行聚类模型,该模型能够提高对海量数据进行挖掘研究的效率,能够充分提高普通PC 机组成的Cluster 的计算性能,能够在短时间内得出聚类结果。实验表明,在Hadoop 平台上该模型具有较好的加速比,并能达到较高的准确率。
[1]刘洋.基于MapReduce 的中医药并行数据挖掘服务[D].杭州:浙江大学,2010.
[2]李成华,张新访,金海,等.MapReduce:新型的分布式并行计算编程模型[J].计算机工程与科学,2011,33(3):129-135.
[3]郝晓飞,谭跃生,王静宇.Hadoop 平台上Apriori 算法并行化研究与实现[J].计算机与现代化,2013(3):1-5.
[4]施佺,肖仰华,温文灏,等.基于Mapreduce 的大规模社会网络提取方法研究[J].计算机应用研究,2011,28(1):145-148.
[5]刘永增.基于Hadoop/Hive 的海量Web 日志处理系统的设计与实现[D].大连:大连理工大学,2011.
[6]舒琰,向阳,张骐,等.基于PageRank 的微博排名MapReduce 算法研究[J].计算机技术与发展,2013,23(2):73-76,81.
[7]张宇,程久军.基于MapReduce 的矩阵分解推荐算法研究[J].计算机科学,2013,40(1):19-21,36.
[8]丁光华,周继鹏,周敏.基于MapReduce 的并行贝叶斯分类算法的设计与实现[J].微计算机信息,2010,36(9):190-191,176.
[9]艾树宇.基于Hadoop/MapReduce 的K_NN 算法[J].科技传播,2013(1):203-204,200.
[10]孟海东,杨彦侃.并行聚类算法的设计与研究[J].计算机与现代化,2010(8):5-8.
[11]王淑玲.增量聚类算法的设计与实现[D].包头:内蒙古科技大学,2009.
[12]戎翔,李玲娟.基于MapReduce 的频繁项集挖掘方法[J].西安邮电学院学报,2011,16(4):37-39,43.
[13]梁建武,周杨.一种异构环境下的Hadoop 调度算法[J].中国科技论文,2012,7(7):495-498.
[14]李锐,王斌.文本处理中的MapReduce 技术[J].中文信息学报,2012,26(4):9-20.
[15]周迎春,骆嘉伟.一种改进的BIRCH 聚类分析算法及其应用研究[J].湛江师范学院学报,2009,30(3):83-87.
