NoSQL系统的容错机制:原理与系统示例
2014-10-31钱卫宁周傲英
孔 超, 钱卫宁, 周傲英
(华东师范大学 数据科学与工程研究院,上海 200062)
0 引 言
传统的关系型数据管理系统已经不能满足高并发的读写、高可用性和高可扩展性的新兴互联网应用的需求.NoSQL系统在这种背景下应运而生.NoSQL常被认为不同于传统关系型数据管理系统,是具有非关系型、分布式、开源、横向扩展等特性的新型数据管理系统[1].这些系统牺牲了一些已在传统关系型数据库中成为标准的功能,如数据一致性、标准查询语言以及参照完整性等,以换取高可扩展性、高可用性和高可靠性.
随着互联网技术的快速发展,海量数据的存储、管理和处理已经成为全球各大互联网公司不可回避的严峻问题.以业务范围跨越C2C(个人对个人)和B2C(商家对个人)的淘宝网为例:截至2013年,淘宝网拥有近5亿的注册用户数,每天有超过6 000万的固定访客,每天的在线商品数已经超过了8亿件,平均每分钟售出4.8万件商品[2,3];2013年11月11日零时,开场仅1分钟成交的订单数量达到33.9万笔,总成交金额达到1.17亿元,第二分钟,成交数字突破3.7亿元,到了零时6分7秒,成交额直接冲上10亿元,截至11日24时,“双11”天猫及淘宝的总成交额破300亿元,达350.19亿元[4],这些海量交易信息的存储、分析和处理对淘宝网提出了巨大的挑战,类似的问题也出现在Google、Facebook、Yahoo等互联网应用上.例如,2012年Facebook在总部的一次会议中披露了一组Facebook每天要处理的数据:25亿条分享的内容条数,27亿个“赞”的数量,3亿张上传的照片数,超过500 TB新产生的数据,每半小时通过Hive扫描105 TB的数据,单个HDFS集群中的磁盘容量超过100 PB[5].
当今的互联网应用具有以下特性:
(1)用户基数大,而且增长速度快;
(2)数据类型多、总量大;
(3)对数据操作较为单一,一致性要求较弱.
虽然互联应用中涉及的数据类型多样,但普通用户的数据处理操作较为单一,对数据的操作无非读或写,或者是增加、删除、修改和查询等.Henderson在2008年Web 2.0expo中的报告指出:通常在互联网应用中,用户更多的是读数据;据统计,读/写数据的比例大约为80∶20或者90∶10[6].低延迟的用户响应、高吞吐量是首先要考虑的技术问题,以满足基本的用户需求;而对数据没有严格的强一致性要求,这有别于金融行业的数据操作.
互联网应用的这些特性对海量数据存储、管理和处理提出了巨大的挑战,例如:支持PB级甚至EB级数据的存储系统、具有良好的扩展性以满足不断增长的数据和用户需求,具有低延迟的用户响应和高吞吐量,具备良好的容错机制以保证互联网应用的高可用性和高可靠性等.
现有的NoSQL系统都有相应的机制来解决容错问题.容错机制与NoSQL系统的高可用性、高可靠性息息相关,在采用大量非可靠硬件的集群环境中尤为重要.良好的容错机制使得NoSQL系统在某些组件发生故障时,仍能继续为用户服务,满足基本的用户需要.Bigtable、HBase等几种典型的NoSQL系统的容错机制越来越成熟,大大提高了NoSQL系统的可靠性和可用性.
随着硬件技术,特别是内存技术的发展,基于内存计算的数据管理系统,如SAP HANA,因其所具有的高性能,已经引起了学术界和工业界的广泛关注[7].而在依赖于易失内存的数据管理系统中的容错处理,则是内存数据管理系统所无法回避的重要问题.NoSQL系统中能够保持系统高可扩展性的容错机制和实现技术,为这一问题的研究提供了思路.
本文以下主要从三个部分展开论述.第1部分对集群环境数据管理系统的一致性保持和容错处理基本原理进行介绍;第2部分对Bigtable、HBase、Dynamo、Cassandra和PNUTS五个典型的NoSQL系统的容错机制及实现进行分析对比,并讨论它们的设计原则和实现技术对于系统的可用性、性能、复杂负载的处理能力等方面的影响;第3部分讨论现有NoSQL系统容错机制对于设计和实现支持关键任务的内存数据管理系统的借鉴意义.
1 基础理论
数据库领域的容错指系统从故障恢复的能力,是数据管理应用中必须考虑的关键问题.
NoSQL存储系统的容错机制设计,需要考虑恢复和复制技术,还必须考虑它们对系统的性能和负载能力等方面的影响.本节介绍构建高可用、高可靠的NoSQL系统的基础理论,包括CAP理论,以及分布式锁服务、恢复和复制等实现技术.
1.1 CAP理论
2000年,Brewer提出了CAP理论,即一个分布式系统,最多只能同时满足:一致性(Consistency,用C表示),可用性(Availability,用A表示)和网络分区容忍性(Tolerance to Network Partitions,下文简称分区容忍性,用P表示),这三个需求中的两个[8].2002年Gilbert和Lynch论证了该理论的正确性[9].
一般而言,分布式系统首先应该具备分区容忍性,以满足大规模数据中心的相关操作.因此CAP理论意味着对于一个网络分区,在一致性和可用性二者之间的取舍[10].传统的关系数据库系统选择一致性,而互联网应用更倾向于可用性.Brewer指出:在大多数情况下,分区故障不会经常出现,因此在设计系统的时候允许一致性和可用性并存[11].当分区故障发生时,应该有一套策略来检测出这些故障,并有合理的故障恢复方法.当然,在系统设计时,不可能完全舍弃数据一致性,否则数据是不安全的和混乱错误的,以致再高的可用性和可靠性也没了意义.牺牲一致性指允许系统弱化一致性要求,只要满足最终一致性(Eventual Consistency)即可,而不再要求关系型数据库中的强一致性(即时一致性).最终一致性指:若对一个给定的数据项没有新的更新,那么最终对该数据项所有的访问都返回最后更新的值.它被集群环境的数据管理系统广泛采用,也常被称为“乐观复制”(Optimistic Replication)[12].
根据CAP理论,C、A、P三者不可兼得,必须有所取舍.传统关系型数据库系统保证了强一致性(ACID模型)和高可用性,但其扩展能力有限.而NoSQL系统则通过牺牲强一致性,以最终一致性进行替代,来使得系统可以达到很高的可用性和扩展性[13].
1.1.1 一致性(Consistency)
分布式存储系统领域的一致性指:在相同的时间点,所有节点读到相同的数据[14].传统的关系型数据库系统很少存在一致性问题,数据的存取具有良好的事务性,不会出现读写的不一致;对于分布式存储系统,一个数据存多份副本,一致性要求用户对数据的修改操作要么在所有的副本中操作成功,要么全部失败.若保证一致性,那么用户读写的数据则可以保证是最新的,不会出现两个客户端在不同的节点中读到不同的情况.
1.1.2 可用性(Availability)
可用性指:用户发送访问请求时,无论操作成功与否,都能得到及时反馈[14].系统可用不代表所有节点提供的数据是一致的.实际应用中,往往对不同的应用设定一个最长响应时间,超过这个响应时间的服务被认为是不可用的.
1.1.3 网络分区容忍性(Tolerance to Network Partitions)
分区容忍性指:任意消息丢失或部分系统故障发生时,系统仍能良好地运行[14].一个存储系统只运行在一个节点上,要么系统整个崩溃,要么全部运行良好,一旦分布到了多个节点上,整个存储系统就存在分区的可能性.
1.2 分布式锁服务:以Chubby为例
分布式锁是分布式系统中控制同步访问共享资源的一种方式.如果不同的系统或同一个系统的不同主机之间共享了一个或一组资源,当访问这些资源时,需要互斥来防止彼此干扰,从而保证一致性,则需要使用分布式锁[15].
分布的一致性问题描述为:在一个分布式系统中,有一组进程,需要这些进程确定一个值.于是每个进程都给出了一个值,并且只能其中的一个值被选中作为最后确定的值以保证一致性,当这个值被选出来以后,要通知所有的进程.Naïve的解决方案为:构建一个master server,所有进程都向它提交一个值,master server从中挑一个值,并通知其他进程.在分布式环境下,该方案不可行,可能会发生的问题有:master server宕机怎么办?由于网络传输的延迟,如何保证每个值到达master server的顺序等[16].
为解决以上问题,Chubby被构建出来,它并不是一个协议或者算法,而是Google精心设计的一个分布式的锁服务[17].通过Chubby,client能够对资源进行“加锁”、“解锁”.Chubby通过文件实现这样的“锁”功能,创建文件就是进行“加锁”操作,创建文件成功的server则抢占到了“锁”,用户通过打开、关闭和读取文件,获取共享锁或者独占锁,并且通过通信机制向用户发送更新信息[18].Chubby的结构见图1.
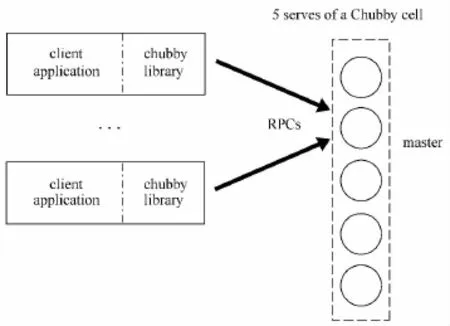
图1 Chubby结构[17]Fig.1 Structure of Chubby
如图1所示,Chubby有两个主要组件:Chubby cell和Chubby library;两者通过RPCs通信.Chubby cell由五个被称为replica的server组成;只要其中三个正常,它就能提供服务.这些server通过分布式一致性协议选举一个作为master server;client application和server间的通信都需要通过Chubby library;client application通过Chubby library的接口调用,在Chubby cell上创建文件获得相应锁功能.
文献[17]阐述了Chubby的工作流程:首先,Chubby cell从五个replica按照分布式一致性协议选举出一个master,master必须获得半数以上的选票,同时保证在该master的租约内不会再选举出新的master,replica通过Paxos协议[19]保持日志的一致性,采用Quorums[20]做决策,使用多副本满足高可用性;其次,每个replica维护一个数据库的拷贝,但只有master能够执行读/写操作,master通过一致性协议将更新传送到其他replica上.client向DNS中replica列表发送master定位请求来找到master,非master的replica返回master标识符响应请求,一旦client找到master就会将所有请求直接发送给master.读请求由master处理,只要master还在租约期内就是安全的.master会通过一致性协议将写请求发送给其他replica,当半数以上的replica收到请求,则认为操作成功;最后,一旦master意外停机,其他replica在master租约过期后选举其他的replica作为master.
1.3 分布式容错中的复制技术和恢复技术
容错指:一个系统的程序在出现逻辑故障的情况下仍能被正确执行[21].分布式系统中容错的概念指:在系统发生故障时,以不降低系统性能为前提,用冗余资源完成故障恢复,使系统具备容忍故障的能力[22].本节介绍分布式容错中的复制技术和恢复技术.
1.3.1 复制
分布式存储系统中的数据一般存储多个副本以保证系统的高可用性和高可靠性,当存储某个副本的节点发生故障时,系统能自适应地将运行中的服务切换到其他副本,实现自动容错.复制技术可以分为同步复制和异步复制两大类:同步复制能够保证主备副本的强副本一致性:当客户端访问一组被复制的副本时,每个副本就如同一个逻辑服务[23],但当备副本发生故障时,可能会影响系统正常的写操作,降低系统的可用性;异步复制通常只能满足最终一致性:保证副本的最终状态相同,在异步系统中,可能存在一个或多个主节点来完成副本间的状态同步[24],但当主副本出现故障时,可能会导致数据丢失,一致性得不到保障.分布式存储系统中使用的复制协议主要有:基于主副本的复制协议(Primary-based protocol)和基于多个存储节点的复制协议(Replicated-write protocol)[25].
主备复制通常在分布式存储系统中保存多个副本,选举其中一个副本为主副本,其他的为备副本,数据写入主副本中,由主副本按照一定的操作顺序复制到备副本[26].同步复制和异步复制都是基于主副本的复制协议,两者的区别在于:异步复制协议中,主副本无需等待备副本的响应,只需本地操作成功便告知客户端更新成功.同步复制的流程如下:第一,客户端向主副本发送写请求,记为W1;第二,主副本通过操作日志(Commit Log)的方式将日志同步到备副本,记为 W2;第三,备副本重放(replay)日志,完成后通知主副本,记为 W3;第四,主副本进行本地修改,更新完毕后通知客户端操作成功,记为W4.R1表示客户端将读请求发送给一个副本,R2表示将读取结果返回给客户端,具体见图2.
主备副本之间的复制通过操作日志的方式来实现:第一,将客户端的写操作顺序写到磁盘中;第二,利用内存的随机读写特性,将其应用到内存中,有效组织数据;第三,宕机重启后,重放操作日志恢复内存状态.为了减少执行长日志的代价,系统会定期创建checkpoint文件将内存状态dump到磁盘中.若服务器出现故障,则只需恢复在checkpoint之后插入的日志条目.
1.3.2 恢复
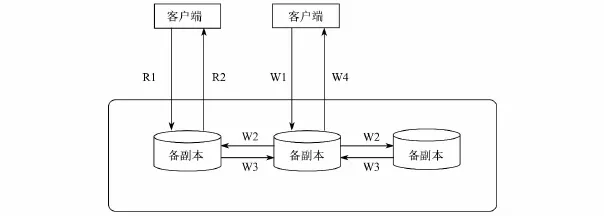
图2 同步复制流程[27]Fig.2 The process of synchronous replication
构建具备健壮性的分布式存储系统前提是具备良好的容错性能,具备从故障种恢复的能力.在NoSQL系统中,这样的恢复能力有一个前提:拥有有效的故障检测(Failure Detection)手段,只有能有效、即时地检测到故障发生,才有制定恢复策略的可能.故障检测是任何一个拥有容错性的分布式系统的基本功能,实际上所有的故障检测都基于心跳(Heartbeat)机制:被监控的组件定期发送心跳信息给监控进程,若给定时间内监控进程没有收到心跳信息,则认为该组件失效[28].
在NoSQL系统中,当master server检测到slave server发生故障时,便会将服务迁移到其他节点.常见的分布式系统有两种结构:单层结构和双层结构,如图3所示.
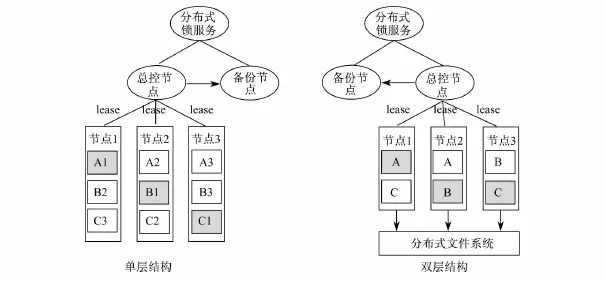
图3 故障恢复[27]Fig.3 Failure recovery
单层结构的分布式存储系统有三个数据分片A、B和C,分别存储了三个副本;其中A1、B1、C1为主副本,分别存储在节点1、节点2和节点3.若节点1发生故障,主控节点检测到该故障,就会选择一个最新的副本,A2或A3替换A1成为新的主副本提供写服务.
双层结构的分布式存储系统会将所有的数据持久化写入底层的分布式文件系统,每个数据分片同一时刻只有一个提供服务的节点.若节点1发生故障,主控节点将选择节点2加载A的服务.由于A的所有数据都存储在共享的分布式文件系统中,节点2只需要从底层分布式文件系统中读取A的数据并加载到内存中.
2 系统示例
高可用性和高可靠性是互联网应用需求下海量数据存储考虑的首要问题,也是核心存储系统的基本特性.以下通过分析对比Bigtable、HBase、Dynamo、Cassandra和PNUTS五个典型的NoSQL系统的容错机制:故障检测手段和故障恢复策略,探讨对系统的可用性、性能、一致性保持和复杂负载处理能力的影响.
2.1 Bigtable和HBase
Bigtable是一个高性能、高可扩展性的分布式的结构化数据存储系统,其系统结构如图4所示.Google的很多项目使用Bigtable存储数据,包括 Web索引、Google Earth和Google Finance.这些应用对Bigtable提出的要求差异非常大,无论是在数据量上(从URL到网页到卫星图像)还是在响应速度上(从后端的批量处理到实时数据服务)[29].作为集中式数据管理系统,Bigtable采用传统的服务器集群架构,整个系统由一个主控服务器(master server)和多个片服务器(tablet server)构成,主控节点集中控制、管理、维护从节点的元信息.集中式管理的优势在于:人为可控且维护方便,在处理数据同步时较简单;其劣势在于:系统存在单点故障的危险.
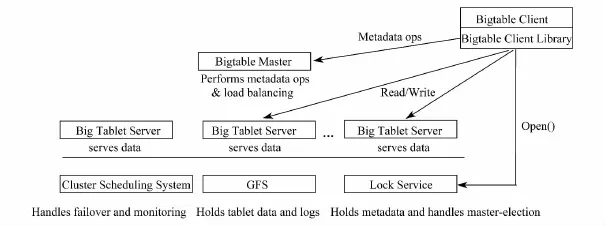
图4 Bigtable的系统结构[30]Fig.4 Architecture of Bigtable
HBase是在HDFS(Hadoop分布式文件系统)上开发的基于列的分布式存储系统,具有高可靠性、高性能、可伸缩、支持实时读写等特性,其系统结构见图5.该项目由Powerset公司的Chad Walters和Jim Kelleman在2006年末发起的,根据Chang等人发表的论文“Bigtable:A Distributed Storage System for Structured Data”来设计的[31].HBase的 Client使用远程过程调用(RPC)机制与master和region server通信,完成管理和读写等操作;HBase中的ZooKeeper当作一个协调工具[32].ZooKeeper中存储-ROOT-目录表的地址信息和master的地址信息.region server在ZooKeeper中注册,所以master可以跟踪每个region server的状态;HBase不同于Bigtable,允许启动多个master,ZooKeeper保证总有有效个master运行,因此弱化了Bigtable中单点故障的问题.
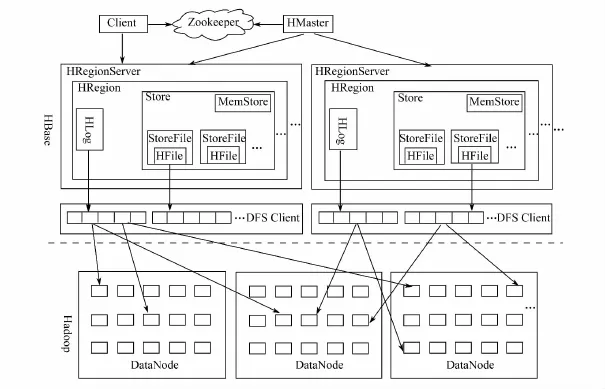
图5 HBase系统结构[33]Fig.5 Architecture of HBase
HBase作为Google的Bigtable架构的一个开源实现,在容错机制和一致性保持的某些方面继承了Bigtable的特性;但二者之间也存在细致的差别.下文主要从这两个方面进行阐述.
2.1.1 Bigtable和HBase的容错机制
Bigtable和HBase的故障检测手段都是基于Heartbeat机制,但具体的实现方式有区别.Bigtable通过分布式锁服务Chubby确保任何时刻最多只有一个活动的master副本,检测tablet server和master server状态,以便进行故障恢复.
在Bigtable中,通过Chubby跟踪tablet server状态信息.当启动一个tablet server时,系统会在特定的Chubby目录下,对一个唯一标识的文件获得排他锁(exclusive lock),master会通过该目录检测tablet server状态,当诸如网络不稳定等因素导致tablet server和Chubby之间的会话中断,tablet server失去排他锁,便停止对tablet的一切服务.
当tablet server出现故障时,tablet server尝试重新获取唯一标识的文件的排他锁,若该文件不存在,tablet server将永远不会提供服务,便自行终止进程.一旦tablet server终止,它将尝试释放锁,此时master便对tablet重新合并、切分、分配到其他tablet sever上.该过程中,master为了随时检测tablet server的状态信息,会通过Heartbeat机制周期性地询问每个tablet server排他锁的持有状态,若tablet server报告失去排他锁,或者master和tablet server无法通信,master便获取锁,一旦tablet server宕机或与Chubby通信出现故障,master便确认tablet server无法提供服务,便删除该tablet server在Chubby目录下唯一标识的文件.
当master与Chubby之间的会话失效时,master终止服务,但是不会改变tablet server当前对tablet的分配情况.此时,master会被系统重启:首先,master在Chubby中获取一个唯一的master lock,以防出现并发的master实例,确保只有一个master;其次,master扫描Chubby下server目录,获取现存的server信息;第三,master与现有的每个tablet server进行通信,以确定哪些已被分配了tablet;最后,master扫描METADATA表,获取tablet信息.在扫描时,一旦发现某个tablet尚未被分配,master便把该tablet信息添加到“未分配”的tablet集合中,保证这些未被分配的tablet有被分配的机会.
Bigtable的底层存储是基于GFS(Google File System)的,其对于数据、日志的容错主要通过GFS多副本冗余来保证.GFS存储的文件都被分割成一个个大小固定的chunk.在chunk创建之时,master服务器会给每个chunk分配一个唯一、不变的64位标识,chunk服务器把chunk以Linux文件的形式保存在本地硬盘上,每个chunk将副本写入多台chunk服务器中,master节点管理所有从节点文件的元数据(METADATA):命名空间、访问控制信息、文件和chunk的映射信息以及当前Chunk位置信息等[34].当客户端进行读操作时,从Namenode中获取文件和chunk的映射信息,再从可用的chunk服务器中读数据.
HBase基于Heartbeat机制进行故障检测,master和region server组件的故障恢复策略如下:
(1)当master出现故障时,ZooKeeper会重新选择一个master;当新的master被启用之前,数据的读取正常进行,但不能进行region分割和均衡负载等操作.
(2)当region server出现故障时,它通过Heartbeat机制定期和ZooKeeper通信;若一段时间内未出现心跳,master会将该region server上的region分配到其他region server上.由图5可知,MemStore中内存数据全部丢失;此时,region server中的一个实现预写日志(Write Ahead Log)的类HLog保存了用户每次写入MemStore的数据.具体恢复过程如下:master通过ZooKeeper感知region server出现故障,master首先处理该region server遗留的HLog文件,将不同region的日志文件拆分,放到相应region目录下;其次将失效的region重新分配到region server上,这些region server在加载被分配到的region的同时会重写历史HLog中的数据到MemStore;最后,Flush到StoreFile,数据得以恢复[35].
HBase 0.90版本以后开始使用基于操作日志(put/get/delete)的副本机制进行失效恢复:region server将客户端的操作写入本地HLog中,每个region server将HLog放入对应znode(ZooKeeper维护的树形层次结构中的一个节点)上的副本队列,将HLog内容发送到集群中某个region server上,并将当前复制的偏移量保存在ZooKeeper上,整个过程采用异步复制机制,满足高可用性的需求[36].
在工程实践中,Bigtable和HBase为避免某个节点的访问压力过载造成的节点失效,有专门的负载均衡策略[37]来解决这一问题.Bigtable的tablet服务节点上的负载均衡依靠master通过心跳机制周期性地监控tablet server的负载情况:将增长到阈值的tablet切分后迁移到负载压力较轻的节点上,可以将用户的请求均衡分布到tablet server上;HBase的数据在存储节点上的负载均衡由HDFS完成.一个文件的数据保存在一个个block中,当增加一个block时,通过以下四种方式保证数据节点的均衡负载[38]:
(1)将数据块的一个副本放在正在写这个数据块的节点上;
(2)尽量将数据块的不同副本分布在不同的机架上,这样集群可在完全失去某一机架的情况下还能存活;
(3)一个副本通常被放置在和写文件的节点同一机架的某个节点上,这样可以减少跨越机架的网络I/O;
(4)尽量均匀地将HDFS数据分布在集群的数据节点中.
2.1.2 Bigtable和HBase的一致性保持
Bigtable和HBase采用多副本冗余的方式满足系统性能,但多副本冗余的的直接后果就是数据一致性问题,本节主要探讨Bigtable和HBase如何在不影响系统的可用性和性能的前提下考量一致性问题.
Bigtable保证强一致性:某个时刻某个tablet只能为一台tablet server服务,即master将子表分配给某个tablet server时确保没有其他的tablet server正在使用这个tablet[29].通过Chubby的互斥锁机制来实现:首先,启动tablet server时获取Chubby互斥锁,一旦tablet server出现故障,master要等到tablet sever的互斥锁失效时才能把出现故障的tablet server上的tablet分配到其他tablet server上.
HBase保证最终一致性(eventual consistency),通过ZooKeeper来实现:第一,客户端的更新请求以其发送顺序被提交;第二,更新操作要么成功,要么失败,一旦操作失败,则不会有客户端看到更新后的结果;第三,更新一旦成功,结果会持久保存,不会受到服务器故障的影响;第四,一个客户端无论连接哪一个服务器,看到的是同样的系统视图;第五,客户端看到的系统视图滞后是有限的,不会超过几十秒[31].
2.2 Dynamo和Cassandra
Dynamo和Cassandra的数据管理方式是非集中式的.系统中没有主从节点的区分,每个节点都和其他节点周期性地分享元数据,通过Gossip协议[39],节点之间的运行状态可以相互查询.非集中式的数据管理方式避免了单点故障,但同时由于没有master,实现METADATA的更新操作会比较复杂.
Dynamo是Amazon2007年推出的基于Key-value的大规模高性能数据存储系统,面向服务的Amazon平台体系结构如图6所示[40].
Cassandra是Facebook的采用P2P技术实现的去中心化的结构分布式存储系统,Cassandra系统设计目标是:运行在廉价商业硬件上,高写入吞吐量处理,同时又不用以牺牲读取效率为代价[41].
2.2.1 Dynamo和Cassandra的容错机制
Dynamo采用多副本冗余的方式保证系统的高可用性,各节点之间通过Gossip机制相互感知,进行故障检测.Dynamo的容错机制主要有以下两点:(1)数据回传.在Dynamo中,一份数据被写到编号K,K+1,…,K+N-1的N台机器上,若机器K+i(0≤i≤N-1)宕机,原本写入该机器的数据转移到机器K+N上,若在给定的时间T内机器K+i恢复,K+N通过Gossip机制感知到,将数据回传到K+i上.(2)Merkle Tree[42]同步.当超过时间T机器K+i还没有恢复服务的话,被认为是永久性异常,通过Merkle Tree机制从其他副本进行数据同步[27].
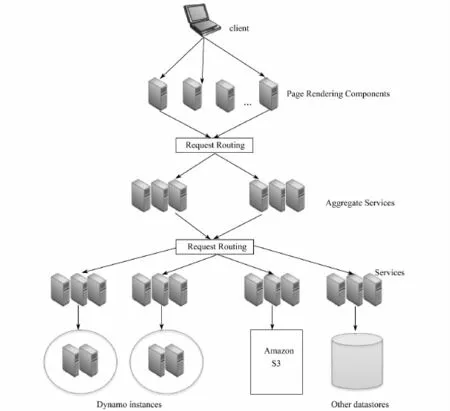
图6 面向服务的Amazon平台[40]Fig.6 Service-Oriented Amazon Platform
Cassandra同Dynamo一样通过Gossip跟踪各节点心跳信息,判断其异常与否.Cassandra通过网络条件、服务器负载等复杂的检测机制判断是否宕机.一旦检测到某一节点故障,原先对该节点的操作,会由其他节点替代,需要开启Hinted Handoff操作,若一个节点,宕机时间超过1 h,hints的数据将不会写入到其他节点.因此在每一个节点上由Node Tool定期执行Node Repair确保数据的一致性.在宕机节点恢复之后,也要执行repair,帮助恢复数据[43].
Dynamo采用虚拟节点技术改进了传统一致性hash[44]中由于节点的异构性带来的负载不均衡问题,将数据均匀地划分到各个节点上,保证系统的健壮性:每个节点根据性能差异分配多个token,每个token对应一个虚拟节点,其处理能力基本相同.存储数据时,按照hash值映射到的虚拟节点区域,最终存储在该虚拟节点对应的物理节点上.假设Dynamo集群中原有三个节点,每个节点分配三个token:node 1(1,4,7),node 2(2,3,8),node 3(0,5,9).存数据时,先计算key的hash值,根据hash值将数据存放在对应token所在的节点上.若此时增加一个节点node 4,集群可能会将node 1和node 3的token1、token5迁移到node 4,token重新分配后的结果为:node 1(4,7),node 2(2,3,8),node 3(0,9),node 4(1,5),从而达到负载均衡的目标,见图7.
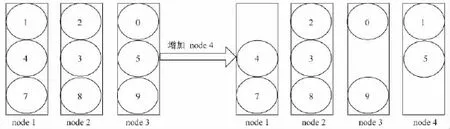
图7 Dynamo虚拟节点[27]Fig.7 Virtual nodes of Dynamo
改进后的一致性hash,将负载较大的虚拟节点分配给性能较强的物理节点,将负载较小的虚拟节点分配给性能较弱的物理节点,最终达成动态负载均衡.
Cassandra避免节点访问过载的容忍机制同Dynamo一样,来源于一致性hash算法,通过Order-preserving hash function(保序Hash)实现.Cassandra的设计考虑到传统的一致性hash算法无视节点处理能力的不均衡和分配数据的不均匀的弊端,不同于Dynamo增加虚拟节点的做法,Cassandra采用Stoica等人的的思想,分析hash环上各节点的负载信息,优先routing轻载节点减轻重载节点负担以均衡负载[45].
2.2.2 Dynamo和Cassandra的一致性保持
在Dynamo中,最重要的是要保证写操作的高可用性(Always Writeable),Dynamo牺牲部分的一致性,采用多副本冗余的方式来保证系统的高可用性.Dynamo只保证最终一致性,即:若多个节点之间的更新顺序不一致,客户端可能读取不到预期的结果.Dynamo中涉及三个重要参数NWR,N代表数据的备份数,W 代表成功写操作的最少节点数,R代表成功读操作的最少节点数.Dynamo中要求W+R>N,以保证当不超过一台机器发生故障的时候,至少能读到一份有效的数据.
Cassandra有一套自己的机制来保障最终一致性:(1)Read Repair.在读数据时,系统会先读取数据副本,若发现不一致,则进行一致性修复.根据读一致性等级不同,有不同的解决方案:当读一致性要求为ONE时,会立即返回用户最近的一份副本,后台执行Read Repair,意味着可能第一次读不到最新的数据;当读一致性要求为QUORUM时,则在读取超过半数的一致性的副本后返回一份副本给客户端,剩余节点的一致性检查和修复则在后台执行;当读一致性为ALL时,则只有Read Repair完成后才能返回一份一致性的副本给客户端;(2)Anti-Entropy Node Repair.通过 Node Tool负责管理维护各个节点,由 Anti-Entropy声称的Merkle Tree对比发现数据副本的不一致,通过org.apache.cassandra.streaming来进行一致性修复;(3)Hinted Handoff作为实现最终一致性的优化措施,减少最终一致的时间窗口[46].
2.3 PNUTS
PNUTS是由Yahoo公司推出的超大规模并发分布式数据库系统.PNUTS提供哈希表和顺序表两种数据存储方式,可以对海量并发的更新和查询请求提供快速响应,它是一个托管型、集中式管理的分布式系统,并且能够实现自动化的负载均衡和故障恢复,以减轻使用的复杂度[47].PNUTS的系统结构如图8所示:系统被划分为多个region,每个region包含整套完整的组件,例如:tablet controller维护活动节点的路由信息以判断节点失效与否;Yahoo!Message Broker(以下简称YMB)是基于topic的订阅/发布系统,一旦数据的更新操作发布到YMB则被认为是提交了的.在提交后的某个时间点,该更新操作被异步广播到不同的region和副本上.PNUTS区别于其他NoSQL系统的特性是:没有采用传统的日志或归档数据实现复制保证高可用性,而是利用订阅/发布机制来实现.
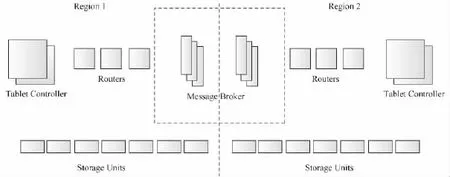
图8 PNUTS系统结构[47]Fig.8 Architecture of PNUTS
2.3.1 PNUTS的容错机制
PNUTS通过YMB防止在更新过程中的节点故障,从远程副本的拷贝实现故障恢复.YMB保证在一个Message Broker机器宕机后,已发布的消息仍然会传递给topic订阅者,该功能通过将message记录在不同服务器上的多个磁盘上来实现.所有的消息直到被系统确认已经写到数据库中后才会被YMB清洗.
PNUTS中的故障恢复是指从其他的副本中复制已丢失的tablet,其复制策略具体实现如下:首先,tablet controller从source tablet(一种特定的远程副本)申请一份拷贝;接着,发布检查点消息到YMB,确保正在执行的更新操作都在source tablet上进行;最后,将source tablet复制到目标region.要实现这个恢复策略要求tablet boundary在副本间保持同步,并且所有region的table在同一时间分裂.该策略的最大开销是将一个tablet从一个region迁移到另一个region,为避免远程获取的开销,通常会创建backup regions就近维护一个backup副本.
PNUTS拥有类似Bigtable均衡节点访问压力避免“热点”的容错机制,PNUTS主要瓶颈是存储单元和YMB的磁盘访问量.目前,用户还不能共享所有的组件,只能共享routers和tablet controller,不同的用户会被分配到不同的存储单元和YMB.PNUTS的tablet代表的是数据表被水平切分成的一组组记录.tablet分散在服务器上,每个服务器可能包含成百上千个tablet.在PNUTS中,一个tablet占用几百M或几个G的容量,包含几千条记录,tablet被灵活地分配到不同的server上以均衡负载.系统使用n-bit hash函数来得到hash值H(),其中0≤H()≤2n.hash空间[0,2n]被分裂为多个区间,每个区间对应一个tablet.要将一个key映射到一个tablet上,首先对这个key做hash,得到该key的H();然后搜索区间集;最后,采用二分查找定位到相应的闭合区间及对应的tablet和存储单元.PNUTS也采用了顺序分裂的方式按照key或H(key)来划分顺序表及其中的数据.图8中Routers仅包含一个区间映射的缓存副本,这个映射为tablet controller所有,router周期性地轮询tablet controller获取映射更新,当tablet空间到达阈值需要分裂时,tablet controller便在存储单元间移动tablet以均衡负载或处理故障.
2.3.2 PNUTS的一致性保持
PNUTS的一致性模型介于即时一致性和最终一致性之间,被称为per-record timeline consistency:一条记录所有的副本按照相同的顺序执行更新操作,如图9所示.timeline上包括对主键的增、删、改操作.对任意副本的读操作都会从这个timeline上返回一致的版本,并且副本总是沿着timeline向前移动.该一致性模型实现过程如下:首先,指派一个副本作为master,每条记录之间相互独立,互不干扰,对记录的所有操作转发给master,被指派为master的副本是自适应不断变化的,这主要依据哪个副本接受大多数的写操作;其次,随着写操作的执行,记录的序列号递增,每条记录的序列号包括该记录的generation(每一个新的insert操作)和version(每一个update操作创建一个version).

图9 Per-record timeline一致性[47]Fig.9 Per-record timeline consistency
3 讨 论
本文探讨了五种典型的NoSQL系统的容错机制及相关的一致性保持解决方案.它们有各自的适用场景,因此不能简单地判断孰优孰劣,只有结合业务特性,才会产生高效的解决方案.例如Bigtable和Dynamo,后者的亮点是“无主”的架构,从而能避免单点故障,但并不代表Dynamo比Bigtable更优秀.Bigtable的主控节点足够可靠,达到“4个9”的可靠性,足够满足通常的应用场景,因此可以采取简单的一个master主控节点的解决方案.Bigtable、HBase、Dynamo、Cassandra、PNUTS的容错机制及一致性保持方案的异同点及自身主要的优缺点概括如表1所示.
面对海量数据的挑战,Bigtable、HBase、Dynamo、Cassandra、PNUTS等优秀的NoSQL存储系统解决了高可靠性、可用性、和可扩展性的问题,这些面向互联网的应用满足横向扩展,面对用户量、访问量的急速增长的挑战,灵活提高负载的能力为学术界、工业界提供了新思路.2011年,“云计算”、“大数据”袭来,越来越多的企业趋之若鹜,大量企业级的应用也在发生革命.越来越多的企业级应用要求更快的访问速度,内存计算和内存数据管理也成为热门的研究方向.内存数据管理中列存储、多核多节点的分布式实现等本质与本文分析比较的五种典型NoSQL系统实现有诸多的契合点,本文从一定程度上为内存数据管理的研究提供经验指导.

表1 NoSQL系统的对比Tab.1 Comparison of NoSQL systems
[1] NoSQL matters.NoSQL DEFINITION[EB/OL].[2014-06-08].http://nosql-database.org.
[2] 百度百科.淘宝网[EB/OL].[2014-06-08].http://baike.baidu.com/view/1590.htm?fromtitle=%E6%B7%98%E5%AE%9D&fromid=145661 &type=syn
[3] 淘宝网品牌介绍[EB/OL].[2014-06-08].http://www.maigoo.com/maigoocms/special/services/170taobao.html.
[4] 张潇.“双11”网购疯狂!天猫及淘宝成交额突破350亿[EB/OL].[2014-06-08].http://money.163.com/13/1112/16/9DGCT0BJ00253B0H.html.
[5] CONSTINE J.How Big Is Facebook’s Data?2.5 Billion Pieces Of Content And 500+ TerabytesIngested Every Day[EB/OL].[2014-06-08].http://techcrunch.com/2012/08/22/how-big-is-facebooks-data-2-5-billion-piecesof-content-and-500-terabytes-ingested-every-day/.
[6] HENDERSON C.Flickr-Scalable Web Architectures:Common Patterns and Approaches[EB/OL].[2014-06-08].http://krisjordan.com/2008/09/16/cal-henderson-scalable-web-architectures-common-patterns-and-approaches.
[7] PLATTNER H,ZEIER A.In-memory Data Management:Technology and Applications[M].Berlin:Springer,2012.
[8] BREWER E A.Towards robust distributed systems(Invited Talk).ACM SIGACT-SIGOPS,2000.
[9] GILBERT S,LYNCH N.Brewer’s conjecture and the feasibility of consistent,available,partition-tolerant web services[C].SIGACT News,2002.
[10] BREWER E A.Pushing the cap:Strategies for consistency and availability[J].IEEE Computer,2012,42(2):23-29.
[11] AGRAWAL D,DAS S,ABBADI A E.Data Management in the Cloud Challenges and Opportunities[M].California:Morgan &Claypool,2013.
[12] VOGELS W.Eventually consistent[J].ACM Queue,2008,6(6):14-19.
[13] 何坤.基于内存数据库的分布式数据库架构[J].程序员,2010(7):116-118.
[14] WIKIPEDIA.CAP theorem[EB/OL].[2014-06-08].http://en.wikipedia.org/wiki/CAP_theorem.
[15] COULOURIS G,DOLLIMORE J,KINDBERG T,et al.Distributed Systems:Concepts and Design[M].5th ed.[s.l.]:Addison-Wesley,2011.
[16] Chubby总结[EB/OL].[2014-06-08].http://blog.csdn.net/ggxxkkll/article/details/7874465.
[17] Mike Burrows.The Chubby lock service for loosely-coupled distributed systems[C].OSDI,2006.
[18] Google利器之Chubby[EB/OL].[2014-06-08].http://blog.csdn.net/historyasamirror/article/details/3870168.
[19] LAMPORT L.Paxos made simple[J].ACM SIGACT News,2001.
[20] GIFFORD D K.Weighted voting for replicated data[C].SOSP,1979.
[21] AVIZIENIS A.Design of fault-tolerant computers[C].AFIPS,1967.
[22] OZSU M T,VALDURIEZ P.Principles of Distributed Database Systems[M].3rd ed.[s.l.]:Springer,2011.
[23] GUERRAOUI R,SCHIPER A.Fault-Tolerance by Replication in Distributed System[EB/OL].[2014-06-12].http://link.springer.com/chapter/10.1007%2FBFb0013477#page-1.
[24] SAITO Y,SHAPIRO M.Optimistic Replication[C].ACM Computing Surveys,2005.
[25] BERNSTEIN P A,NEWCOMER E.Principles of Transaction Processing[M].2nd ed.Elsevier,2009.
[26] 李磊.分布式系统中容错机制性能优化技术研究[D].湖南:国防科技大学,2007.
[27] 杨传辉.大规模分布式存储系统原理解析与架构实践[M].北京:机械工业出版社,2013.
[28] Distributed Algorithms in NoSQL Databases[EB/OL].[2014-06-10].http://vdisk.weibo.com/s/t3HPkX2GaIpf.
[29] CHANG F,DEAN J,GHEMAWAT S,et al.Bigtable:A Distributed Storage System for Structured Data[C].OSDI,2006.
[30] DEAN J.Building Large-Scale Internet Services[EB/OL].[2014-06-19].http://static.googleusercontent.com/media/research.google.com/zh-CN//people/jeff/SOCC2010-keynote-slides.pdf.
[31] HADOOP W T.The Definitive Guide[M].O'Reilly,2012.
[32] Apache ZooKeeper.What is ZooKeeper[EB/OL].[2014-06-19].http://zookeeper.apache.org/.
[33] Searchtb.HBase技术介绍[EB/OL].[2014-06-08].http://www.searchtb.com/2011/01/understanding-hbase.html.
[34] GHEMAWAT S,Howard Gobioff,and Shun-Tak Leung.The Google File System[C].SOSP,2006.
[35] 康毅.HBase大对象存储方案的设计与实现[D].南京大学,2013.
[36] APACHE HBASE[EB/OL].[2014-06-15].http://hbase.apache.org/replication.html.
[37] 负载均衡技术大盘点[EB/OL].[2014-06-10].http://www.mmic.net.cn/news/865/9.htm.
[38] 陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2011.
[39] SUBRAMANIYAN R.Gossip-based failure detection and consensus for terascale computing[EB/OL].[2014-06-15].http://etd.fcla.edu/UF/UFE0000799/subramaniyan_r.pdf.
[40] DECANDIA G,HASTORUN D,JAMPANI,et al.Dynamo:Amazon’s highly available key-value store[C].SOSP,2007.
[41] LAKSHMAN A,MALIK P.Cassandra– A Decentralized Structure Storage System[C].SIGMOD,2008.
[42] MERKLE R.A digital signature based on a conventional encryption function[C].Proceedings of CRYPTO,1988.
[43] DATASTAX.Internode communications[EB/OL].[2014-06-11].http://www.datastax.com/documentation/cassandra/2.0/cassandra/architecture/architectureGossipAbout_c.html.
[44] KARGER D,LEHMAN E,LEIGHTONT,et al.Consistent hashing and random trees[C]//Procceding STOC’97 ACM Symposium,1997:643-663.
[45] STOICA I,MORRIS R,KARGER D,et al.Chord:A Scalable Peer-to-peer Lookup Service for Internet Applications[C]//SIGCOMM’01.San Diego:ACM,2001.
[46] DATASTAX.Configuring data consistency[EB/OL].[2014-06-11].http://link.springer.com/chapter/10.1007%2FBFb0013477#page-1.
[47] COOPER B F,RAMAKRISHNAN R,SRIVASTAVA U,et al.PNUTS:Yahoo!’s Hosted Data Serving Platform[C].VLDB’08.Auckland:ACM,2008.
