基于舞弊三角理论的财务舞弊识别模型研究:支持向量机与Logistic回归的耦合实证分析
2014-09-21金花妍,刘永泽
金 花 妍, 刘 永 泽
(1.辽宁师范大学 数学学院,辽宁 大连116029;2.东北财经大学 会计学院,辽宁 大连116023)
继美国安然世通等财务舞弊案爆发后,全球不少著名跨国公司相继东窗事发,严重损害了广大投资者的利益及对资本市场的信心,也推动了各国舞弊风险相关审计准则的制定以及相关领域的学术研究。
美国现代内部审计之父Lawrence B.Sawyer早在20世纪50年代就提出著名的舞弊三角理论,后来由美国注册舞弊审核师协会(Association of Certified Fraud Examiners,简称ACFE)的创始人Albrecht进一步发展了舞弊学理论,提出舞弊是由压力、机会和借口三要素共同作用下产生的[1]。2002年10月,美国注册会计师协会(AICPA)发布的第99号审计准则《财务报表审计中对舞弊的考虑》(以下简称SAS NO.99)和我国财政部于2006年2月发布的《中国注册会计师审计准则第1141号——财务报表审计中对舞弊的考虑》,都是在舞弊三因素理论的基础上提出的舞弊风险因素。
从现有财务舞弊影响因素的相关研究来看,通常都是从财务指标、公司治理指标、审计师指标来进行实证检验的。首先,公司财务稳定性指标是发现舞弊的主要征兆之一。例如,Albrecht研究认为,财务数据中一些无法解释的变化、非同寻常的大额交易、收益质量的不断降低、高额负债、无法及时收回应收账款、其他现金流量等特征是发现舞弊的主要征兆之一[1];姚宏、佟飞研究发现,盈利能力、销售能力、货币资产占比、资产利用率和短期偿债能力等确实明显低于非舞弊公司[2]。其次,大多研究将舞弊行为的发生归咎于公司治理不够完善。如Beasley的研究发现,外部董事的比例与会计舞弊的可能性显著负相关,董事会中外部董事的任期增加、持股比例增加、在其他公司任职减少使会计舞弊发生的可能性下降;董事会规模小,会计舞弊发生的可能性下降[3];张翼、马光研究发现,第一大股东持股比例、董事长持股比例、领取报酬的监事比例与公司发生丑闻的可能性相关,但未发现董事会规模、独立董事数量、机构投资者持股比例、以及监事会规模等与公司发生丑闻的可能性之间的相关性[4];蔡志岳、吴世农的研究发现,与代理理论相矛盾,关于董事会领导权结构的实证结果支持现代管家理论,董事长兼任总经理的公司越不容易违规,且违规程度越轻微[5]。最后,独立审计是发现舞弊的主要手段之一,Hoffman、Morgan和Patton对130位审计师的调查结果发现,客户诚实程度是会计舞弊最重要的征兆[6]。Hudaib等研究发现,与非舞弊公司相比,曾经发生舞弊的公司更换审计师可能更会引起利益相关者的关注[7]。
基于舞弊三角理论的财务舞弊识别模型的相关研究来看,Dunn运用舞弊三角理论对上市公司舞弊倾向进行了研究,并构建了比较全面、有效的舞弊识别模型[8]。在我国,基于舞弊三角理论进行全面分析的文章并不多见,韦琳等以舞弊三角理论为基础,构建了舞弊(或违规)识别模型[9],但对于借口因素的代理变量并不全面,而且都是采用Logistic回归模型进行判别,判别率不够高且判别的也不够精确。而沈乐平采用支持向量机的算法[10],对舞弊及信息披露违规判别模型的准确率较高,但单纯采用这些模型具有解释能力较低的缺陷。本文鉴于支持向量机方法的识别模型具有更高的识别率,以及Logistic回归模型的各要素解释力高的优点,利用这两个方法达到了优势互补效果。
一、变量的选取与模型的构建
本文的因变量(Y)为财务报告舞弊(fraudulent financial reporting),舞弊的形式包括未按时披露定期报告、未及时披露公司重大事项、未依法履行其他职责、信息披露虚假或严重误导性陈述、业绩预测结果不准确或不及时。Y为哑变量,某A股上市公司在某年度发生了财务报告舞弊行为时,该变量取值为1;否则取值为0。自变量为可导致财务舞弊的各种风险因素,本文按照舞弊三角理论中提出的舞弊风险因素确定代表性变量。
1.变量的选取
舞弊三角理论认为,导致舞弊发生的条件有3个,即动机或压力、机会和借口。
(1)财务舞弊的动机或压力
根据舞弊三角理论,与舞弊动机或压力相关的风险因素包括:公司财务的稳定性或盈利能力受到经济、行业或公司经营状况威胁;管理当局承受着来自满足第三方要求或预期的压力。
财务稳定性的代表性指标包括:主营业务比率(MBR)、经营活动净收益/利润总额(BANI)、经营活动产生的现金流量净额是否为负值(CASHNe,小于零时取1,否则为0);净资产收益率同比增长率(ROE-grow)、总资产同比增长率(Agrow)以及营业收入同比增长率(Sgrow);存货周转率(STOCK)、应收账款周转率(Account)和总资产周转率(Aturn)。
SAS NO.99指出,管理层所承受的工作压力主要来源于外部压力和财务契约冲突。本文以破产风险(Z值)、经营活动产生的现金流量净额/负债合计(CashLia)、资产负债率(LEV)指标替代外部压力;以舞弊前1年预测的净利润增长比例(PROE)、净利润是否小于零(PROF,小于零时取1,否则为0)、高管持股数量(LnSTOC)、高管年度报酬(LnSPay)等指标替代报酬契约动机。
(2)财务舞弊的机会
舞弊机会通常与行业或公司经营的性质、对管理者控制的失效、复杂或不稳定的组织结构等因素相关。代表性指标包括:未经审议程序的重大交易(SRT,舞弊当年发生该事项时取值为1,否则为0);第一大股东控制度(ROFS)、股东大会出席率(SMAtte)以及年度内股东大会会议次数(SM)、董事会会议次数(DM)和监事会会议次数(SuM);二重性(DUAL,董事长兼任总经理时取1,否则为0)、董事会规模(DIRS)、监事会规模(SUPE)、独立董事比例(IDP)、独立董事出席率(IDAtte)以及非常规性高管变更情况(CHANGE,发生此类事项时取1,否则为0)。
(3)财务舞弊的借口
舞弊的借口即是态度或自我合理化,在舞弊者不受道德约束时,即使舞弊动机或机会相对较小的情况下,也很可能发生。本文采用高管平均教育背景(EDUC)来替代道德变量;以舞弊前1年应计利润率(ACCR,(净利润-经营活动产生的现金流量净额)/总资产)来替代管理者对利益相关者就实现不切实际的目标作出的承诺。以审计师规模(AUDTOP20,审计师为20大事务所时取值为1,否则为0)审计师变更(CHANGEAUD,舞弊前3年发生审计师变更的次数)和审计意见(AO,舞弊前3年曾被出具非标准意见的次数)指标反映管理当局与现任或前任审计师(包括会计师事务所和注册会计师)的紧张关系。
2.模型的构建
基于以上舞弊三角理论,本文共确定了33个变量,分别为16个舞弊动机、12个舞弊机会以及5个舞弊借口的变量,从而构建以下舞弊识别模型:
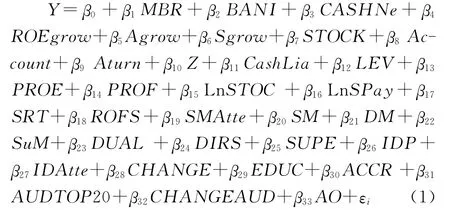
其中,β0是截距,表示当以上33个变量为零时,Y的平均值。β1~β33为回归系数,回归系数>0,表明变量与因变量呈正相关关系;回归系数<0,表明变量与因变量呈负相关关系。
二、样本的选择与均值检验分析
1.样本的选择
本文以2007~2011年为研究区间,利用Wind资讯的中国上市公司重大违规处理数据库收集了共224项违规记录。剔除非财务舞弊公司33项,剩下191项;剔除上市前发生违规事项的2项,剩下189项;剔除舞弊行为发生年度在2007年以前的69家,剩下120项。在这120项处分公告中,15家企业受过2次处分,5家企业受过3次处分,共有95家企业受到中国证券监督管理委员会、中华人民共和国财政部、深圳证券交易所、上海证券交易所等处罚单位的公开处分,涉及147份年报,对每家公司配对一个控制公司。具体选择标准如下:(1)与舞弊公司同一上市地点,并且证监会行业代码相同;(2)与舞弊年度样本相同年度;(3)获得标准审计意见;(4)舞弊当年资产总额与舞弊样本最接近;(5)非ST公司;(6)无违规记录。
在根据以上条件配对的过程中,有20家公司无法找到合适的配对公司,剩下75家公司的116份年报,因此本文以116个样本和116个控制样本为研究对象。本文最终要建立舞弊识别模型,因此财务数据选取舞弊前1年的值,其他指标则选择舞弊当年的数据。
关于数据来源,本文主要通过深圳市国泰安信息技术有限公司的CSMAR数据库、上海万得资讯科技有限公司的Wind资讯金融终端数据库、中国注册会计师协会网站(http://www.cicpa.org.cn/)、深圳证券交易所网站(http://www.szse.cn/)、上海证券交易所网站(http://www.sse.com.cn/)收集并整理了研究对象相关的财务数据、公司的治理信息等各方面资料。
2.均值检验分析
本文运用SPSS18.0进行独立样本均值检验(T检验),研究舞弊公司和非舞弊公司在舞弊动机、机会、借口三因素上的均值差异及其显著性,为建立舞弊识别模型奠定基础。表1为对33个变量进行均值检验的结果。通过T检验得出如下结论:(1)舞弊动机或压力特征。舞弊前1年舞弊公司的主营业务比率、经营活动净收益/利润总额、营业收入同比增长率、经营活动产生的现金流量净额/负债合计、高管年度报酬等特征均值的差值为负数,显著低于非舞弊公司;经营活动产生的现金流量净额为负值、净资产收益率同比增长率、破产风险、资产负债率、亏损、高管持股数量等特征的均值差值为正数,显著高于非舞弊公司。(2)舞弊机会特征。舞弊当年舞弊公司的第一大股东控制度、股东大会出席率、独立董事出席率特征的值差值为负数,显著低于非舞弊公司;未经审议程序的重大交易、股东大会会议次数、董事会会议次数、二重性、非常规性高管变更状况等特征的值差值为正数,显著高于非舞弊公司。(3)舞弊借口特征。舞弊公司在舞弊前3年审计师变更次数、舞弊前3年曾获得非标准审计意见这两个特征的值差值为负数,均显著高于非舞弊公司。
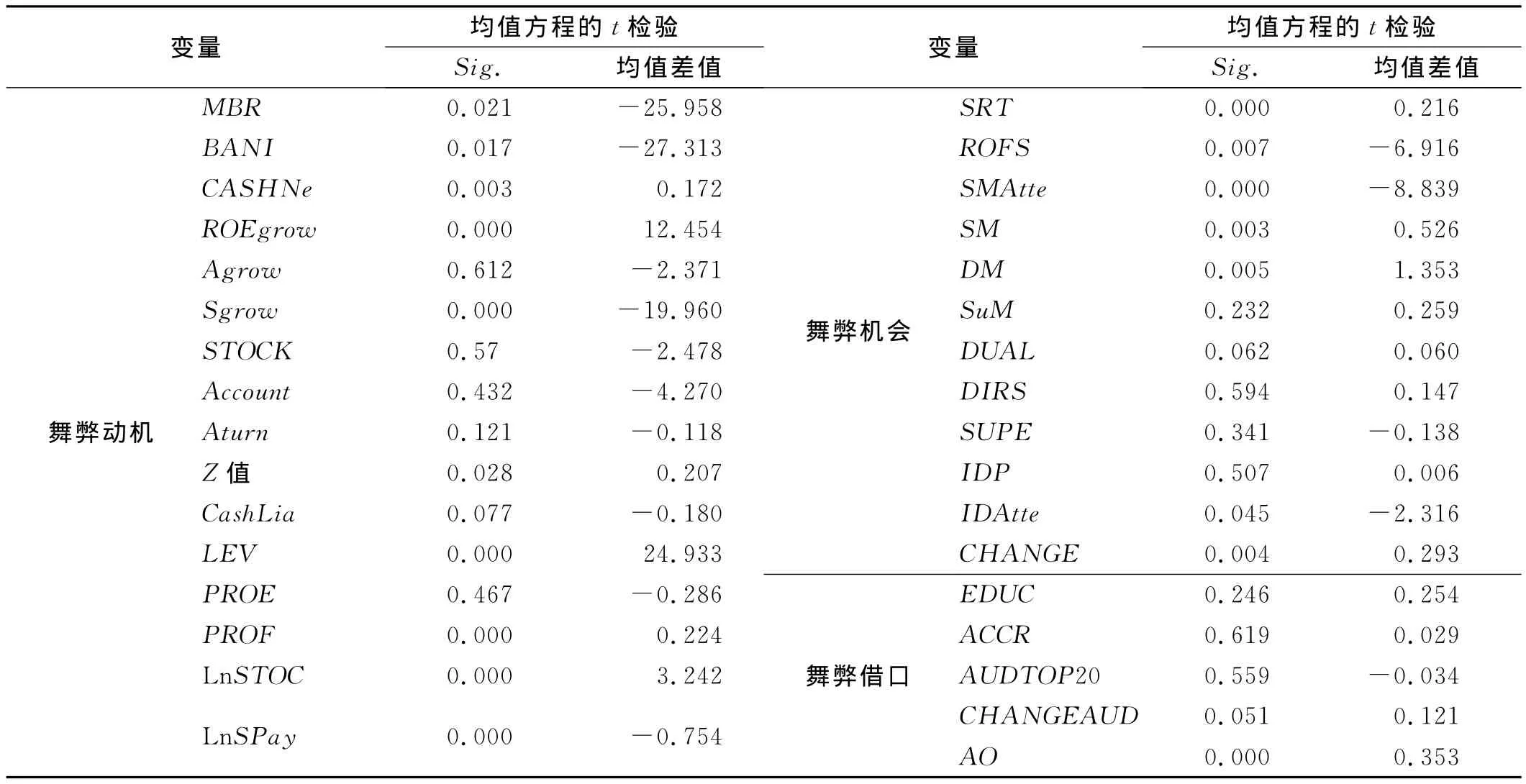
表1 变量均值检验结果
三、舞弊识别模型的构建
本文采用支持向量机方法提高对未知现象的学习能力和推广能力,并通过Logistic回归模型辨别各变量对整个模型的解释力。支持向量机之所以能具有优秀的推广能力,是因为它以结构风险最小化原则为基础。支持向量机是一种通用的统计学习机器,能使结构风险最小化目标得到较好实现,通过将输入向量映射到高维特征空间,能够构造出最优分类面,弥补了多层前向网络无法解决的缺陷。支持向量机所运用的二次规划寻优,可以求到全局最优解,这是神经网络局部极小问题无法攻克的难题,但是支持向量机的解释能力较弱,而Logistic回归模型恰好能弥补这一缺点,能够帮助我们观察每个变量对因变量的影响。
1.基于支持向量机方法的舞弊识别模型
(1)构建样本空间与特征空间
样本数据总体为2007~2011年,所有样本分为两个部分:一部分为训练集,包括模型训练样本和验证样本,用于支持向量机的学习过程;另一部分为测试样本,完全独立于学习过程,在训练模型完成后才被用来评估分类器的推广能力。原始样本数据的分配要保证训练样本集中的样本数量必须足够多,不能少于样本数的50%。因为,如果训练集样本所占比例过少,通常不足以代表总体样本的分布,会导致测试阶段识别率出现明显落差。因此,将训练样本集和测试样本集按照三种分配情况分别进行测试(见表2)。
为了提高舞弊识别模型的识别效果,本文对财务舞弊特征进行T检验后,以21个舞弊公司与非舞弊公司之间均值差异显著的变量(见表1)作为特征空间。
(2)核函数的选择
核函数形式包括径向基(RBF)核函数、线性核函数、多项式核函数、指数基核函数和双层神经网络核函数等多种形式。其中,本文选用RBF核函数,其原因在于它具有以下特点:一是能够实现非线性映射;二是参数的数量影响模型的复杂程度,RBF核函数参数相对较少;三是稳定性较强。
RBF核函数:Kg(xi,xj)=exp(-g‖xi-xj‖2),g>0
其中,g是可调节的核参数。本研究根据各类特征对是否存在财务舞弊进行预测,属于二分类问题,而支持向量机在分类应用方面具有优良的解决能力,从而可以利用支持向量机提高正确预测财务舞弊的概率。
(3)参数寻优
本文采用网格搜索方法来寻找最优的惩罚参数C和核参数g,网格搜索就是在给定范围内遍历所有可能的(C,g)对,然后进行交叉验证,找出使交叉验证精确度最高的(C,g)对。网格搜索的方法很直观但比较耗费时间,也可以使用一些近似算法或启发式的搜索来降低复杂度。由于本文的数据研究对实时性要求不高,所以使用网格搜索来进行全面的参数搜索。
(4)支持向量机舞弊识别模型研究结果分析
运用支持向量机算法,对舞弊识别模型进行预测的结果如表2所示。从表2可以看出,在训练过程中,随着训练集样本的增多,训练精度也随之提高,而对应的分类器推广能力也呈上升趋势,测试精度都在94%以上,表现了分类器的良好性能。

表2 支持向量机舞弊识别模型结果
2.基于Logistic回归分析的舞弊识别模型
为了对Logistic回归模型与支持向量机识别模型进行比较,本文选择T检验表现显著的变量构建Logistic回归识别模型。因变量(Y)为财务报告舞弊,自变量共有21个均值差异显著的变量(见表1)。经过对自变量进行相关性检验,结果显示大部分自变量之间相关性系数都没超过0.5(限于篇幅,未列出相关系数表)。但是,有个别的变量之间的相关系数超过了0.5,如主营业务比率(MBR)与主营业务活动净收益/利润总额(BANI)的相关系数为0.672。为了防止这些高度相关的变量带来严重的多重共线性,从而影响模型的估计,剔除主营业务比率(MBR)变量。
利用SPSS18.0统计软件进行二元Logistic回归,结果如表3所示。
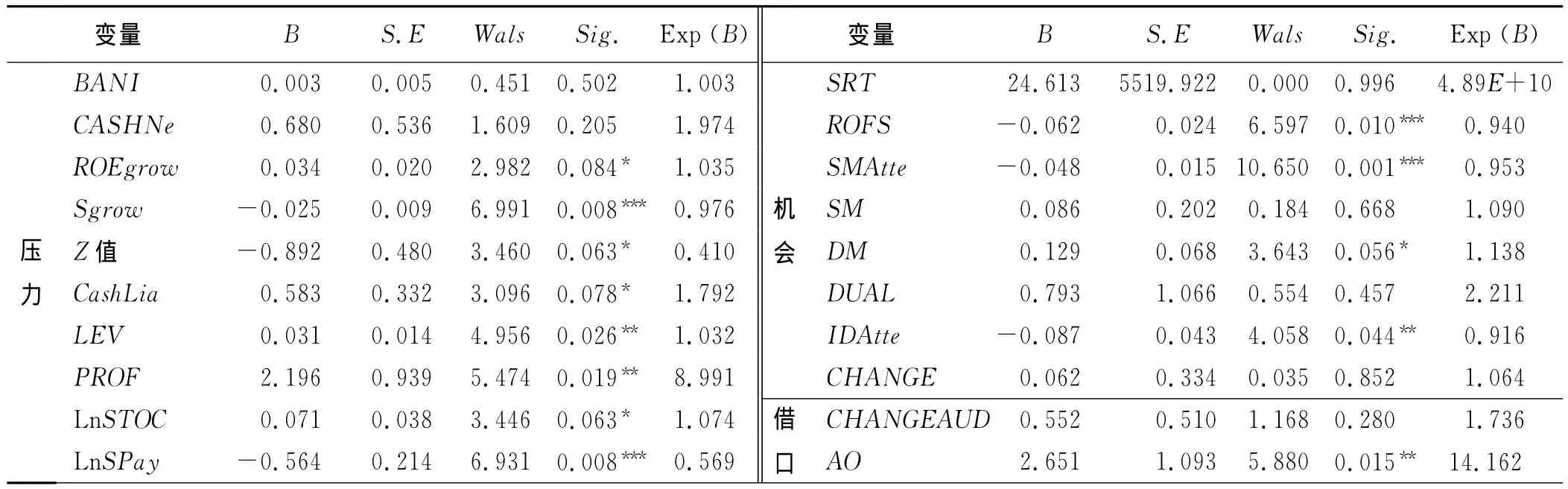
表3 模型逻辑回归结果
通过回归分析,获得常数项β0为9.468,自由度(df)为1。Cox &Snell R2和Nagelkerke R2分别为0.546和0.728,模型的拟合优度比较好。回归结果显示,Sgrow、LnSPay、ROFS、SMAtte等变量在1%水平下显著;LEV、PROF、IDAtte、AO等变量在5%水平下显著;ROEgrow、Z值、CashLia、LnSTOC、DM等变量在10%的水平下显著。也就是说,过高的增长率、破产风险、资产负债率、亏损额和过低的营业收入增长率、经营活动产生的现金流量净额/负债合计,使公司的财务稳定性严重受损;高水平的高管持股数量和低报酬给舞弊者带来较强的舞弊动机或压力。而第一大股东控制度、股东大会出席率、独立董事出席率越低,董事会会议次数越多,说明组织结构越不稳定,给舞弊者留下的机会越大,舞弊的可能性越高。而曾经获得非标准审计意见,说明管理层在诚信或态度上出现一定问题,舞弊前3年获得非标准审计意见次数越多,舞弊的可能性越高。
根据以上回归结果,构建舞弊识别模型:
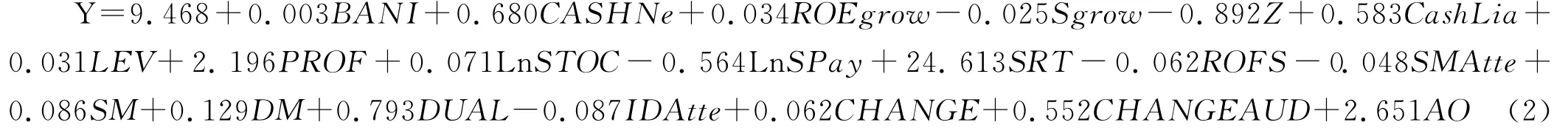
利用舞弊识别模型,进行舞弊分类检验结果如表4所示。
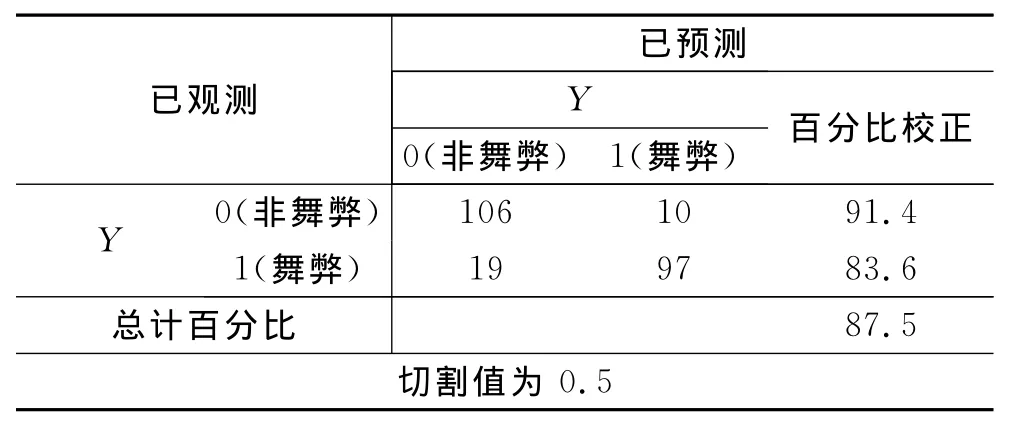
表4 Logistic回归模型对舞弊识别结果
如表4所示,在建立的Logistic识别模型中,116家非舞弊公司中有10家公司被误判,识别率为91.4%;116家舞弊公司中有19家被误判,识别率为为83.6%。舞弊识别模型的整体识别率为87.5%。总之,Logistic识别模型的整体识别率低于支持向量机的识别率,但是各个变量对舞弊概率影响的解释力较好。
四、结论及建议
本研究得出以下结论:第一,在支持向量机方法下,随着训练集样本数的增多,训练精度也随之提高,而对应的分类器推广能力也呈上升趋势,测试精度都在94%以上。由此可见,采用支持向量机的机器学习方法对财务数据进行处理,其所表现出的预测能力表明对未知数据的判断更为可靠、有效。在总体识别率方面,支持向量机算法下的总体识别率相比Logistic回归模型较高,表现出分类器的良好性能。在各个变量对舞弊概率的影响方面,Logistic回归模型表现出较高的解释能力。第二,在舞弊压力方面,增长速度、破产风险、资产负债率、是否亏损、高管持股数量与财务舞弊可能性之间存在显著正相关关系;而经营活动产生的现金流量净额/负债合计、营业收入增长率、高管年度报酬与舞弊概率之间呈显著负相关关系。第三,舞弊机会方面,董事会会议次数越多,舞弊概率越高;第一大股东控制度、股东大会出席率、独立董事出席率越低,舞弊的可能性越高。第四,舞弊借口方面,曾经获得非标准审计意见次数越多,说明管理层在诚信或态度上出现一定问题,舞弊的可能性越高。
据此,要有效预防和发现舞弊,不仅要加强内部控制的建设和运行过程,更要加强股东、独立董事以及独立审计师等团体的外部监督。首先,缓解企业和管理层面临的内外部压力。通过制定科学的发展战略、设计稳定的组织结构、合理的报酬激励机制、建立健康的企业文化等健全内部控制环境。第二,进行内部控制与风险管理评价,防止给舞弊者提供任何舞弊机会。第三,加强内外监督,杜绝舞弊借口。本文的实证结果表明,我国企业内部监督职能虚化问题还比较严重,在提高内部监督效率、效果的同时,应加强外部投资者以及审计师的监督力度。
[1]ALBRECHT W S.舞弊检查[M].李爽译.北京:中国财政经济出版社,2005.29-61.
[2]姚宏,佟飞.会计信息失真背景下的上市公司价值质量评价模型[J].大连理工大学学报(社会科学版),2011,32(2):32-37.
[3]BEASLEY M S.An empirical analysis of the relation between the board of director composition and financial statement defraud[J].The Accounting Review,1996,71(4):443-465.
[4]张翼,马光.法律、公司治理与公司丑闻[J].管理世界,2005,(10):113-122.
[5]蔡志岳,吴世农.董事会特征影响上市公司违规行为的实证研究[J].南开管理评论,2007,10(6):62-68.
[6]HOFFMAN V B,MORGAN K P,PATTON J M.The warning signs of fraudulent financial statement[J].Journal of Accountancy,1996,182(10):75-77.
[7]HUDAIB M,COOKE T E.The impact of managing director changes and financial distress on audit qualification and auditor switching[J].Journal of Business Finance &Accounting,2005,32(9-10):1703-1739.
[8]DUNN P.Fraudulent financial reporting:a deception based on predisposition,motive and opportunity[D].Boston:Dissertation of Boston University,1999.
[9]韦琳,徐立文,刘佳.上市公司财务报告舞弊的识别——基于三角形理论的实证研究[J].审计研究,2011,3(2):98-106.
[10]沈乐平,黄维民,饶天贵.基于支持向量机的上市公司违规预警模型研究[J].中大管理研究,2008,(2):125-135.
