基于Cache的HEVC运动补偿带宽优化设计
2014-09-18郭铮言方向忠
郭铮言,方向忠,王 慈
(上海交通大学电子工程系,上海200240)
HEVC是由JCT-VC组织研发的最新一代视频压缩标准[1],和上一代 H.264/AVC 标准[2]相比,HEVC 在保证视频质量的同时可以带来两倍的视频编码压缩量。现在电视广播以及家庭影音中的主流视频格式是1 080p和720p,新一代高端影音产品将目标锁定在更高分辨率的视频格式,比如QFHD(4K×2K)。HEVC的高视频压缩率将会更好地满足超高清分辨率视频对于海量数据吞吐的需求,也被业界公认为下一代最为普遍应用的标准。新标准中采用了很多先进视频压缩技术,比如说在运动补偿模块亮度插值中使用8抽头滤波器来预测1/4分数精度像素值,同时在色度差值中使用4抽头滤波器来预测1/8分数精度像素值。与之前的视频压缩标准相比,更高精度的插值预测能够带来更好的视频压缩效果,与此同时视频编解码的过程对于带宽的需求就更高。
运动补偿插值模块是视频解码器中计算需求最大的模块之一,插值预测的过程中需要大量读取外设存储器中的参考帧信息,占用了约70%的解码带宽。实时解码3 840×2 160@60 f/s(帧/秒)格式视频,数据吞吐量会达到500 Mpixel/s[3]。假如使用 H.264/AVC 解码,带宽的需求将会是1 080p的4.3倍,即7 Gbit/s。HEVC标准的插值部分因为应用了抽头数更多的8抽头滤波器,相比H.264标准需要更多的参考帧信息,因此会带来更大的带宽消耗。所以,运动补偿模块会是HEVC标准进行超高清视频实时解码过程中的瓶颈。
通过利用2D Cache结构和插值顺序重排,本文提出了一种有效合理的运动补偿带宽优化设计。首先,并行化插值结构设计可以保证3 840×2 160@60 f/s的视频实时解码时的数据吞吐量需求。其次,利用在插值计算处理器与主存储器中间使用2D Cache结构进行高速缓冲存储,从而达到数据快速读取以及大量减少带宽的目的。然后,在保证Cache读取命中率的前提下,利用插值顺序重排方案提高每次所读取参考帧数据之间的时/空相关性,从而减少Cache面积,减少片内硬件开销。
1 HEVC运动补偿系统框架
图1为所设计的运动补偿模块系统框架,主要由亮度插值计算模块、色度插值计算模块、Cache高速缓冲存储模块以及外设主存储器组成。
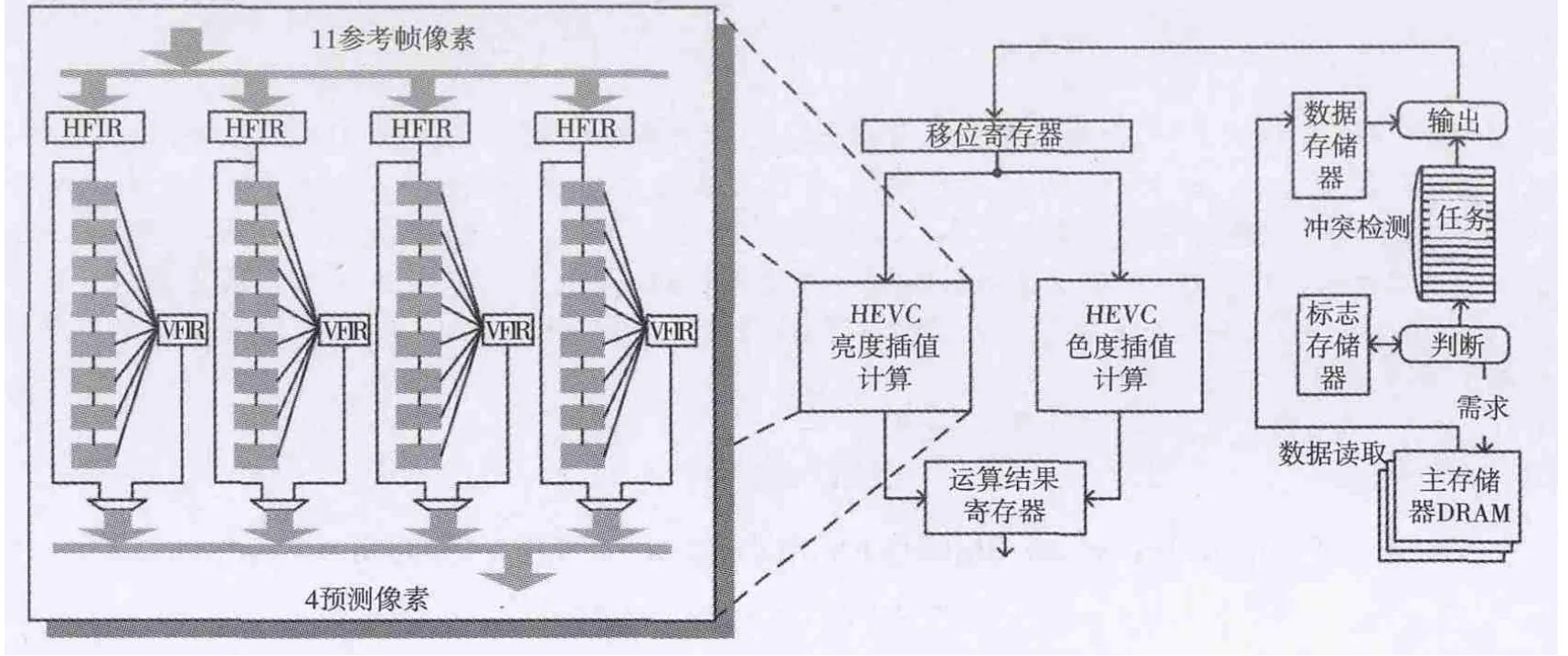
图1 HEVC运动补偿模块系统框架
1.1 运动补偿插值模块
在许多基于H.264/AVC标准所设计的运动补偿结构中,一个宏块往往被拆分成16个4×4模块然后进行插值计算,一个4×4亮度模块需要最多读取9×9参考帧像素信息[4-5]。在HEVC中,3种不同系数的8抽头滤波器的应用使得插值一个4×4亮度模块需要读取最多11×11参考帧像素信息。
本文运动补偿模块基于作者先前的研究成果[6],利用亮度插值中3种系数结构中的相同项,将3种不同系数的滤波器整合设计成为一个具有复用结构的8抽头滤波器,减少了计算模块的硬件开销。插值计算模块采用流水线设计,1/4精度亮度插值首先由8抽头滤波器进行水平方向插值,得到半像素值或者1/4像素精度中间值。在8个时钟周期之后,寄存器阵列中的8个中间值被传送至垂直方向8抽头滤波器进行插值计算,最后得到所求像素预测值。对于N个像素并行插值计算,整个HEVC亮度插值模块需要由2N个8抽头滤波器(N个水平方向,N个垂直方向)和N×8个15 bit寄存器组成。而在H.264/AVC中,亮度插值模需要(3N+1)个6抽头滤波器(N个水平方向,2N+1个垂直方向),(2N+1)×6个8 bit寄存器和N个2抽头滤波器[7-8]。和H.264/AVC相比,HEVC所需的滤波器数量和寄存器队列减少了,但是滤波器的面积、寄存器的位宽以及寄存器队列的长度增加了。同时因为插值所需参考帧像素信息的增加,HEVC运动补偿对于带宽需求也更大了。本文中的亮度插值结构为8个像素并行预测。色度模块与亮度模块结构相似。
1.2 Cache模块
运动补偿插值模块计算时所用到的参考帧信息由于数据量巨大,存储在片外的主存储器中。为了减少从数据片内外数据交互带宽,计算模块与片外主存储器之间引入Cache[9]。首先,用来描述插值位置和参考块大小的插值指令会被发送到判断模块中,判断模块通过访问标志存储器判断得出所需数据是否命中。若命中,则将插值指令发送至任务队列;若没有命中,则将数据读取请求发送给片外主存储器,主存储器确认请求后会将被请求数据传送写入片内数据存储器中。当所有所需参考帧数据都已经被写入数据存储器中并且插值模块已经准备就绪时,参考帧数据和插值指令随后被发送至插值模块中进行插值计算。
2 Cache优化设计
Cache设计中的三个主要问题为高速缓存映射机制,内部存储器结构以及Cache缓存区面积优化。高速缓存映射机制[10-11]在许多研究者的文章中都被讨论过,而内部存储器结构和缓存区面积优化问题却很少被研究。
2.1 内部存储结构设计
本文的内部存储器结构设计主要为了优化存储器面积和功耗问题。首先,和标清视频图像解码相比,在超高清视频图像解码的过程中,插值模块往往采用并行化流水线结构来增加数据吞吐量,导致内部存储器的宽度也会成比例增加。其次,内存访问过程中的数据对齐问题也会导致存储器宽度的增加。如图2a所示,RAM中数据通常是一列中多个像素在一起存储和读取,被称为存储单元。图2a中以4个像素为基本存储单元,假设内存输出宽度为2个存储单元即8个像素,以读取8个像素值为例说明RAM数据访问对齐问题。图2a(1)中所示情况为数据对齐访问,即所需8个数据正好完全包含2个存储单元内数据,因此只要一个时钟周期便可以读取所需数据。图2a(2)中所示情况为数据未对齐访问,即只需要3个存储单元内的部分数据,因为RAM一次只能输出2个存储单元的数据,因此需要2个时钟周期来读取所需数据。为了保证数据读取速度满足一个时钟周期内读取所有所需值,就需要增加RAM宽度。内存输出宽度的增加虽然不会影响内存缓存区的大小,但是会导致功耗增加。

图2 内部存储器RAM结构设计
一个解码单元通常会被拆分成多个4×4或者8×4小模块来进行插值计算。插值一个8×4模块,在H.264中需要参考帧模块大小为12×9,而在HEVC中需要大小为15×11的参考帧模块。文献[3]使用4片宽度为32 bit(4个像素)的RAM结构来输出数据,称之为4S×4结构。这种4S×4结构保证了12个参考帧像素值能在1个时钟周期内从RAM中被读取出来,但是无法满足HEVC亮度插值时一个时钟周期读取15个像素值的需求。有两种方法可以增加RAM输出,保证HEVC的快速数据读取需求。第一种方法是增加1片宽度为32 bit的RAM,即4S×5结构如图2c所示。但是这种结构虽然保证了数据输出速度,却也增加了RAM宽度,为原先的1.25倍。本文提出了另一种2S×8结构,即使用8片RAM,每片RAM宽度为16 bit(2个像素)。这种2S×8结构使得15个参考帧像素能在1个时钟周期内被全部读取,从而有效地保证了亮度插值模块的并行计算速度,并且没有增加内存宽度。
2.2 Cache缓存区面积优化
运动补偿插值计算过程中所需要的参考帧模块数据之间事实上是有相关性的[9]。图3展示了当前帧解码单元P0,P1,P2,P3在进行运动补偿时所需参考帧模块大小的例子。从图3可以发现,参考帧模块之间互相有重叠。即在当前插值模块Pk所需的参考帧模块中,有部分信息有很大概率仍然会被下一个插值模块Pk+1所需要,此为数据的时域相关性。另一种数据相关性是由存储器中数据的存放格式所引起的。在外部存储器中,多个像素通常被组合在一起当作一个访问单元来存放和读取。比如在本文设计的Cache中,一个访问单元由8 byte(64 bit)组成。当这个访问单元中的部分数据需要被读取时,整个访问单元都会从存储器中读取出来,包括单元中剩下的不需要数据。而那些当前模块插值过程中所不需要的数据信息有很大概率在下一个模块插值的过程中被请求读取。因此,同一个访问单元可能被连续多次地反复读取,此为数据的空域相关性。在2D Cache结构中,这些数据相关性直接影响了Cache高速缓冲区的大小。合理高效地运用这些数据相关性来进行数据读取,可以在保证带宽减少的同时,优化Cache缓冲区的大小和减少硬件开销。
文献[12]使用了4×64×64大小的Cache缓冲区来减少带宽,是H.264中32×32大小的Cache设计[10]的16倍。虽然带宽减少了,但是也为解码芯片带来了巨大的片内硬件开销。图4a为HEVC中最大解码单元(64×64)的原始运动补偿插值顺序,基于HM 9.0。由图可知,各个模块的原始插值计算顺序与预测单元的存放结构有关。但是,按照这种树状存放结构读取的参考帧模块,其数据相关性的利用率很低。因此,本文提出3种插值顺序重排方法,目的是为了提高参考帧数据相关性的利用率来减少Cache大小,从而减少片内硬件开销。如图4b~4d所示,分别为垂直读取、水平读取和混合读取(将解码单元分成上下两块进行垂直读取)。

图3 数据时域空域相关性
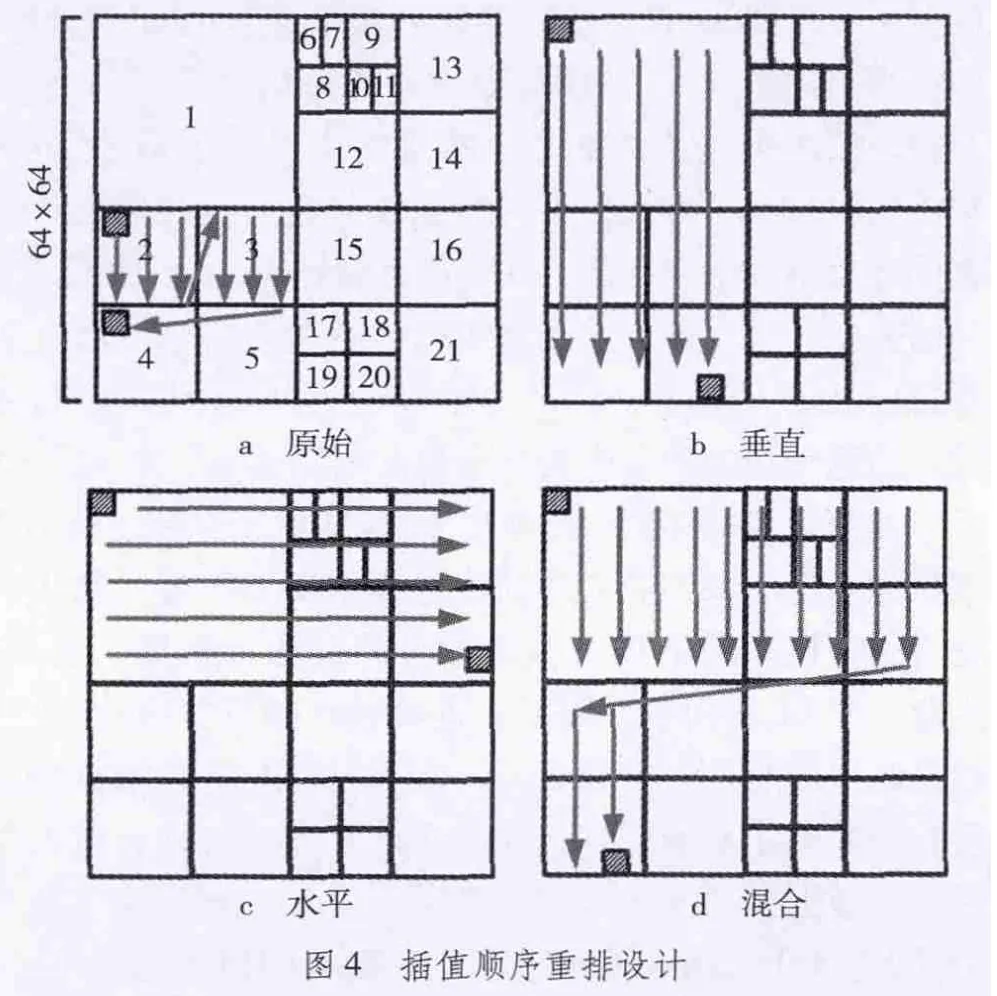
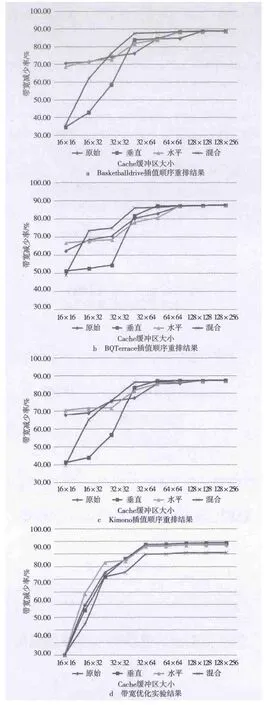
图5 部分插值顺序重排实验结果及混合读取带宽减少率
3 实验结果及分析
图5为部分插值顺序重排实验结果,所使用的视频来自HEVC标准测试序列集,为IPPPP编码模式,测试工具为HM 9.0。
以图5a为例,测试了3种插值顺序重排在不同的缓冲区大小情况下的带宽优化结果,其中横坐标表示Cache缓冲区大小(高×宽字节),纵坐标表示带宽减少率。从此图中可以看出,在原始插值顺序的情况下,带宽优化曲线(此处称之为Rc曲线)在128×128处收敛,即在这个缓冲区大小下带宽优化效果最佳。另外三种插值顺序使得曲线提前收敛,其中混合顺序重排使得带宽优化效果在Cache缓冲区大小为32×64时就已经接近于最佳。其他视频序列的测试结果也均表明利用混合插值顺序重排,在保证带宽优化效果的同时,可以将片内Cache硬件开销减少为原来的(32×64)/(128×128)=1/8。使用插值顺序重排的方法也会带来一些额外的硬件开销,那就是需要在外部存储器中利用一块64×64 byte大小的存储空间来存储整个最大解码单元内的参考帧数据信息。片外存储器原先存储空间远大于64×64 byte,而且流水线设计有效地解决了数据等待时间问题,因此这点额外的硬件开销是可接受的。图5d为混合插值顺序重排下的带宽减少率,从图中可以看出带宽优化率达到80% ~90%,合理有效地优化了超高清视频编解码过程中带宽过大的问题。
4 结论
本文提出了一种基于Cache的HEVC运动补偿带宽优化设计。主要贡献有:1)提出了内部存储器低功耗结构设计,保证HEVC标准下超高清视频解码数据吞吐量需求,同时降低RAM功耗。2)提出了Cache大小优化设计,通过插值顺序重排的方法高效地利用了参考帧数据间的相关性,将片内Cache硬件开销减少了87.5%。
HEVC视频测试集的实验结果表明,本文Cache设计用与H.264有可比性的32×64 byte内存就可以减少HEVC运动补偿插值计算过程中的80%以上的带宽。本文为HEVC解码器芯片的实际生产和未来针对超高清视频实时解码应用提出了合理的解决方案,同时比较了HEVC和H.264运动补偿模块在硬件实现和开销上的异同。
:
[1] Working draft 5 of high-efficiency video coding,joint collaborative team on video coding(JCT-VC)[S].2011.
[2] Draft ITU-T recommenda-tion and final draft international standard of joint video specification[S].2003.
[3] ZHOU J,ZHOU D,HE G,et al.Cache based motion compen-sation architecture for quad-HD H.264/AVC video decoder[J].IEICE Trans.Electron.,2011(4):439-447.
[4] GUO Zhengyan,ZHOU Dajiang,GOTO S.An optimized mcinterpolation architecture for HEVC[C]//Proc.IEEE Int.Conf.on Acoustics,Speech,and Signal Processing.[S.l.]:IEEE Press,2012:1117-1120.
[5]刘立峰,方向忠.低运算复杂度的H.264解码器运动补偿模块[J].电视技术,2011,35(9):23-26.
[6] SZE V,FINCHELSTEIN D,SINANGIL M,et al.Chandrakasan.A 0.7-V 1.8-mW H.264/AVC 720 p video decoder[C]//Proc.IEEE J.Solid-State Circuits.[S.l.]:IEEE Press,2009:2943-2956.
[7] WANG S,LIN T,LIU T,et al.A new motion compensation designfor H.264/AVC decoder[C]//Proc.IEEE Int.Symp.Circuits Syst. [S.l.]:IEEE Press,2005:4558-4561.
[8] ZHOU D,LIU P.A hardware-efficient dual-standard VLSI archi-tecture for MC interpolation in AVS and H.264[C]//Proc.IEEE Int.Symp.Circuits and Syst..[S.l.]:IEEE Press,2007:2910-2913.
[9] CHEN X,LIU P,ZHOU D,et al.A high performance and low bandwidth multi-standard motion compensation design for HD video decoder[J].IEICE Trans.Electronics.,2010(3):253-260.
[10] CHUANG T,CHANG L,CHIU T,et al.Bandwidth-efficient Cachebased motion compensation architecture with DRAM-friendly data access control[C]//Proc.IEEE Acoust.,Speech and Signal Process..[S.l.]:IEEE Press,2009:200-2012.
[11] MEHENDALE M,DAS S,SHARMA M,et al.A true multistandard,programmable,low-power,full HD video-codec engine for smartphone SoC[C]//Proc.IEEE Solid-State Circuits Conf.[S.l.]:IEEE Press,2012:226-228.
[12] HUANG C,TIKEKAR M.A 249Mpixel/s HEVC video-decoder chip for quad full HD applications[C]//Proc.IEEE Solid-State Circuits.[S.l.]:IEEE Press,2013:162-163.
