基于级联和自适应子分类的目标检测方法
2014-09-18方向忠路庆春
郑 耀,方向忠,路庆春
(上海交通大学电子工程系,上海 200240)
基于图像的实际目标检测如行人检测、车辆检测、人脸检测[1]等是一个非常具有挑战性的问题。由于实际应用中图像的场景往往比较复杂,同一类物体常常会表现出不同的姿态、纹理、颜色,如何能够快速准确地识别这些目标就成为了人们广泛研究的问题。
基于机器学习的图像的目标检测方法主要有:基于决策树的目标检测方法,基于超平面分割的目标检测方法,基于神经网络的目标检测算法等。基于决策树的检测方法通常采用AdaBoost或类似的方法进行训练。常常使用 Haar-like 特征,Edge-let特征,或者 Image-strip 特征[2]等。使用该类方法通常可以得到很快的检测速度。基于SVM的目标检测方法通过利用支持向量获得基于超平面分割的分类器,通常配合HOG特征[3]、LBP特征地等。该类方法可以相对准确地进行目标分类和检测,因为该类方法在分类过程中需要使用所有提取的特征。另外还有基于神经网络的目标检测方法等。通常来说,一类方法使用的特征数越多,信息量越大,检测的准确度越高,但是同时,其消耗的运算量也越多[4]。
通过综合利用快速检测和准确检测两类方法的优点,本文提出了一种两级级联的目标检测方法。第一级被设计成具有快速检测的检测器,它能够检测到几乎所有的目标,同时,也会将很多非目标的检测窗当成正确的检测窗。即具有很高的检出率和相对较高的错检率。然后,对检测出的窗口进行分类,将检出的具有相似大小和相近位置的窗口分为一组。可以认为,正确的目标出现位置和目标的大小最有可能是一个分组检出窗口对应的中心位置和平均大小,同一组内检出的窗口将按照它们距离分组中心的距离进行排序。在第二级,设计的分类器将具有非常高的准确度,以此来对第一级的检出结果进行确认。为了实现第二级分类器的高识别率,首先将待检测的目标按照颜色、姿势等特征进行子分类。利用交叉验证的方法,可以自适应地获得子分类的分类数和最终的分类结果。然后对于不同的子分类,将训练出不同的识别模型。对于待检验的窗口,首先判断它属于哪一个子分类,再用对应的识别模型进行判别。
1 目标检测流程
图1为所设计的两级分类器的系统框图。

图1 目标检测流程
图1中的第一级给出的结果是一些排好序的检出窗口组。对于每一个检出窗口组,使用第二级级联分类器进行准确的识别,判断该窗口组的检出内容是否是需要的检测目标。第一级中,因为真实目标更有可能出现在每一个检出分组的中心位置,其大小更有可能是每一个分组内检出窗口的平均大小,所以每一组内的排序依据是该组每一个检出窗口到该分组的中心位置和平均大小的距离。第二级识别的方法是:对于第一级的每一组检出窗口,按组内顺序进行判断。如果一个窗口被判断为是正确的检测目标,则认为该组为正确的检测目标;输出被检测正确的检出窗口的位置和大小;继续进行下一组检出窗口的检测。如果全组检测窗口均被判断为不是正确的检测目标,则抛弃该检测窗口组。
后处理过程将相互重叠区域比较大的检出窗口进行聚类和取平均值,作为最终的检测结果。设计的细节将在下文中介绍。
2 第一级:快速检测和分组
图2为第一级检测和分组的示意图。首先采用Ada-Boost训练出的级联 Haar-like 检测器[5-6]作为基本检测器进行快速的目标检测。通过基本检测器,将可以得到一系列检出窗口。如图2中间所示,共检测出7个可能为目标的窗口。

图2 第一级结构示例图
然后采用投票和聚类的方法对所有检出的窗口进行快速的聚类,得到一系列的分组。对于每个分组,根据每一个检出窗口距离分组中心和平均分组大小的远近进行排序。如图2右侧所示,7个检测出的窗口被分成了3组。分组和排序的方法如下:
两个检出窗口的距离定义为

式中:centeri是第i个检出窗口的中心位置坐标,areai是第i个检出窗口的面积大小。根据本文对检测窗口之间距离的定义,设计了对快速目标检测的检出窗口进行分组和排序的方法。
首先对每一个检出窗口进行投票,伪代码为:

然后,根据式(1)中定义的距离,相近的检出窗口将被聚类到同一个组。同时,每个组内的子窗口将根据投票的结果和距离组中心的距离进行排序,伪代码为:

3 第二级:基于自适应子分类的准确识别
在实际场景中,即使是同一类物体,相互之间的差异也是非常巨大的,如不同的光照、外形、颜色、姿态等,如图3所示。所以,需要建立不同的模型来识别同一类目标。
相关工作[7]显示,将一类目标分成若干个子类进行识别检测,将能够有效地提升检测的性能。在第二级,将训练数据集分成K个子类。其中K是一个通过最优化交叉验证结果自适应计算出的参数,K的计算将在下文中进行描述。第二级准确识别的系统框图如图4所示。通过将一类目标分成K个子类,训练出K个分类器。每次判断检测窗口是否为待检测目标时,首先选择合适的分类器,然后用合适的分类器进行判别。这样大大提高了识别的准确性。

图3 左图为“树”;右图为“树”对应在提取的特征空间上的一种可能的分布

图4 第二级结构
不失一般性,在特征池中只提取图像的HOG特征。这一类特征常常用来描述目标的结构化信息。本文在计算HOG特征时,采用的块大小为16×16像素,细胞单元大小为8×8像素,相邻块之间交叠为8个像素,使用9通道直方图。对于一个80×32的窗口来说,可以计算出一个维度为972的HOG特征向量,记为v。
可以看出,特征向量v是一个高维度的欧氏空间上的向量。对应的正训练样本集就是一组特征向量的集合:P={v1,v2,…,vM}其中,M是正训练样本的图片数。使用K-means算法将整个正样本集分成K个子类:P1,P2,…,PK,其中P=P1∪P2,…,∪PK。负样本训练集对应的特征向量为N。于是,K组训练集合分别是:(Pi,N)其中i=1,2,…,K。使用这K组训练集合可以训练出K个分类器:fi其中i=1,2,…,K。对于一个待识别图像I,对应的特征向量为vx,首先计算它到K组训练集合中每个集合Pj所有向量的均值¯vj的欧氏距离‖vx-‖,并选择距离最小的一组Pi。通过使用Pi对应训练出的分类器来对当前图像进行识别。识别结果由fi(vx)给出。将训练一系列分类器到选择合适的分类器对图像进行识别的过程(即图4所示所有过程)抽象为训练和使用分类器FK,其中K是子类的个数。
为了自适应地完成“子分类”的工作,采用交叉验证中的“留一验证”的方法来获得最合适的子分类个数K,并自动完成子分类工作。假定整个训练集为S=(P,N),对应的标签集合D为{1,1,…,1,-1,-1,…,-1},其中标签为1表示对应的样本为正样本,-1表示对应的样本为负样本。记si是S中的第i个向量,di是D中的第i个元素。那么K可以定义为如下最优化问题的解

式中:是使用特征向量集S-{si}和对应的标签集D-{di}训练出来的分类器。通过全空间搜索的方法,可以求解出最优的K。
在求解出最优的K之后,可以得到第二级分类器FK。如图1所示,利用FK对第一级的结果进行再判别,得到的检出窗口将被认为是待检测的目标。为了消除重复检出的窗口,进行简单的后处理工作。
通过两级检测器的窗口,如果相互之间重叠的面积足够大,则认为是同一类,即

式中:centeri是第i个子窗口的中心位置;areai是第i个子窗口的面积。最终的输出结果是每一类的中心位置和平均尺寸。
4 实验结果及分析
实验采用了在目标检测问题中被广泛使用的UIUC车辆检测数据集[8]。该数据集包含550个车辆侧边的图像作为正训练样本和500张无车图像作为负训练样本;包含170张单一尺度的车辆检测测试图像,图像中共有200辆车;包含108张多尺度车辆检测测试图像,图像内包括139辆车。作为对样本集的简单扩充,从网络上收集了2 400张不包含车辆的图像,同时,对已有的正样本进行左右镜像变换。最终的训练集中包含了1 100张车辆图片和2 900张无车图片,训练样本如图5所示。这些训练图像首先被统一到尺寸80×32。对于第一级快速检测,训练分类器使得虚警率低于5×10-4,训练出的决策树高度为10左右。第一级的检测结果如图6a所示,不同的分组被使用不同的颜色标注出来。第二级计算出的最优K数值为2,对应的K-means算法将正样本分成的两个子类分别为车头向左和车头向右两种类,如图6b所示。第二级最终检测结果如图6c所示。图6d显示了针对高清图像的车辆检测结果。
4.1 检测准确性
对于目标检测准确性问题,采用常用的图像目标检测的正确检测定义[4]。如果一个检测到的窗口和真实的目标所在的位置大小重合的面积超过它们所覆盖的总面积,就认为该检测到的窗口为正确的窗口,否则认为检测出现了错误。具体定义如下

图5 训练样本示例

图6 目标检测结果示例

式中:Aread是检测到的窗口,Areag是某个目标所在的真实位置。通常使用查准率(Precision)和查全率(Recall)来衡量目标检测算法的优劣。其定义如下
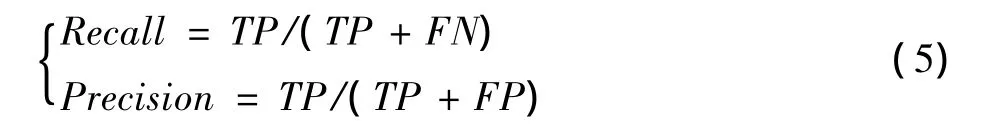
本文使用EER参数(当Precision和Recall相等时的查准率)比较了所提出的方法和现有算法的检测准确率。结果如表1所示。实验结果显示,本方法在检测的准确性上优于现有的算法。

表1 不同方法的EER比较 %
4.2 运算复杂度
计算并比较了在UIUC车辆检测单尺度测试图像集上的各种算法的运算复杂度。所有的方法均使用VisualStudio 2008 C++环境实现。在一台 I7 2600 CPU、4 Gbyte内存的机器上运行。计算了每个检测窗口平均需要耗费的判别时间,比较结果如表2所示。
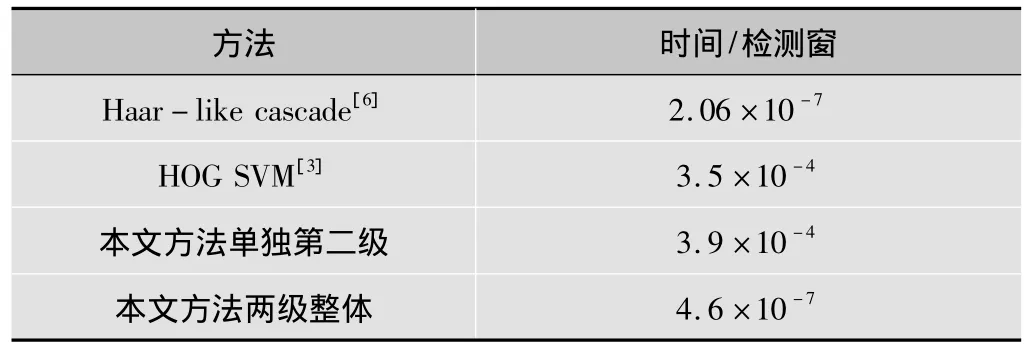
表2 UIUC数据集每个检测窗口需要的检测时间 s
可以看出,本文所述的方法具有相对较快的运算速度。在UIUC单尺度测试集上,只用了0.9 s完成对全部170张图片,共1 993 987个检测窗口的目标检测。
为了进一步测试目标检测的准确率和运算速度,使用了一些高分辨率图像(1 280×960)进行多尺度目标检测,如图6d所示。平均每幅图像检测时间为0.7 s左右。
5 结论
本文提出了一种快速和高准确率的目标检测方法。主要贡献有:1)提出了2级级联目标检测的方法。使得检测的速度和检测的准确率得到了有效的兼顾。2)提出了通过自适应子分类的方法,利用分而治之的思想,解决同一类待检测目标相互之间差异大的问题。有效地提升了检测的准确率。
UIUC数据集以及一些高清图像的测试结果表明,所提出的检测方法可以在达到很高的检测速度同时,获得非常高的检测准确度。第二级的实验结果表明,通过将同一类目标进行子分类的方法,将能够有效提升目标检测的准确性。
同时,可以通过在第一级结合更多的特征如Imagestrip特征[2]等,在第二级使用更多的图像特征等来获得更好的检测率。
:
[1]闫娟,程武山,孙鑫.人脸识别的技术研究与发展概况[J].电视技术,2006(12):81-84.
[2]ZHENG W,LIANG L.Fast car detection using image strip features[C]//Proc.IEEE Conference Computer Vision and Pattern Recognition.Miami,USA:IEEE Press,2009:2703-2710.
[3]DALAL N,TRIGGS B.Histograms of oriented graients for human detection[C]//Proc.IEEE Conference on Computer Vision and Pattern Recognition.Los Alamitos,CA,USA:IEEE Press,2005:886-893.
[4]REN Haoyu,HENG Cherkeng,ZHENG Wei.Fast object detection using boosted co-occurrence histograms of oriented gradients[C]//Proc.IEEE International Conference on Image Processing(ICIP).HongKong:IEEE Press,2010:2705-2708.
[5]LIENHART R,MAYDT J.An extended set of Haar-like features for rapid object detection[C]//Proc.International Conference on Image Processing.New York,USA:IEEE Press,2002:900-903.
[6]VIOLA P,JONES M.Rapid object detection using a boosted cascade of simple features[C]//Proc.IEEE Conference Computer Vision and Pattern Recognition.Kauai,USA:IEEE Press,2001:I-511.
[7]KUO N R.Robust multi-view car detection using unsupervised sub-categorization[C]//Proc.Applications of Computer Vision.Salt Lake City,USA:IEEE Press,2009:1-8.
[8]AGARWAL A A,ROTH D.Learning to detect objects in images via a sparse,part-based representation[J].Pattern Analysis and Machine Intelligence,2004,26(11):1475-1490.
[9]WU B,NEVATIA R.Cluster boosted tree classifier for multi-view,multi-pose object detection[C]//Proc.IEEE Conference International Conference on Computer Vision.Rio de Janeiro,Brazil:IEEE Press,2005:1-8.
