基于描述符的输出调度IP核的设计与实现
2014-09-15赵国鸿胡勇庭孙志刚
赵国鸿,胡勇庭,李 韬,孙志刚
(国防科学技术大学计算机学院,湖南 长沙 410073)
基于描述符的输出调度IP核的设计与实现
赵国鸿,胡勇庭,李 韬,孙志刚
(国防科学技术大学计算机学院,湖南 长沙 410073)
输出调度是实现QoS支持的重要技术。基于报文的输出调度技术由于实现简单等优点,广泛应用于各种QoS部件的设计与实现中。然而,基于报文的输出调度由于需要缓存大量待调度报文,因此增加了设备的芯片面积和实现成本。针对上述问题,提出了一种基于描述符的输出调度技术,通过对携带报文长度信息的描述符进行调度,在保证系统性能的前提下,可有效降低输出调度的存储空间需求。还介绍了基于此种输出调度算法的IP核设计与实现,介绍了模块的外部接口、参数配置以及内部处理流程。最后,通过实验验证了此IP核的可行性。
QoS;输出调度;描述符;IP核
1 引言
近年来互联网应用的快速发展,不仅需要网络设备的处理速率不断提升,而且要求网络处理设备提供必需的服务质量QoS(Quality of Service)保证。服务质量[1,2]QoS是指网络能够提供有保证的、可预测的数据服务。输出调度是QoS的一项最基本技术,输出调度技术可以按照用户实际需要分配硬件资源,在网络发生拥塞时区分服务不同的用户。目前对输出调度算法的研究比较成熟,最早的输出调度方法是先来先服务FCFS(First Come First Served)的方式,后来为了区别不同的优先级用户又出现了严格优先级队列PQ(Priority Queue)调度算法,由于PQ算法对用户并不公平,低优先级的队列可能长时间无法占用到硬件资源,因此出现了基于轮循的DRR[3]算法以及基于虚拟时钟[4]的WFQ[5]算法;为了完善WFQ算法,出现了W2FQ[6]算法,为了公平调度不同流对多种资源的需求,又出现了DRFQ[7]算法。
目前,大多数的网络设备都采用了基于报文的输出调度方式,这种方式实现简单、高效。报文在处理单元处理完毕后被发送到输出调度部件,经过调度后输出到网络接口。在网络中存在突发流量时,调度部件需要缓存大量报文,而网络设备芯片上的存储空间比较受限,增加外部存储将会导致芯片面积与成本的大幅提高。存储资源的大量占用是基于报文的输出调度方法的最大缺点。
针对以上问题,本文提出了一种基于描述符的输出调度技术,在不降低设备处理性能的基础上大幅减少了存储资源的消耗。由于输出调度广泛应用于网络设备中,因此为了降低网络设备的开发成本以及难度,本文还利用这种基于描述符的输出调度技术设计了一个输出调度IP核[8,9]。用户可以配置不同的参数,使输出调度IP核实现不同的功能。本文第2节从理论上分析基于描述符的输出调度的优点;第3节介绍输出调度IP核的接口信息以及参数配置;第4节介绍IP核内部的工作流程;第5节给出实验结果以及分析;第6节为结束语。
2 基于描述符的输出调度设计
2.1 主要思想
如图1所示,网络设备中基于报文的输出调度方式通常包括以下基本流程:
(1) 处理单元读取主存中的报文进行处理。
(2) 处理单元将处理完成的报文描述符发送到存取控制单元。
(3) 存取控制单元根据接收的描述符构造读请求,从主存储器中读取出待调度报文。
(4) 输出调度器对待调度报文进行调度。
(5) 将调度后的报文发送到网络中。

Figure 1 Procedure of packet-based output scheduling图1 基于报文的调度输出流程
针对目前网络设备中报文调度时存储资源消耗较大的问题,基于描述符的报文输出调度流程如图2所示,可以分为以下几个步骤:
(1) 处理单元读取主存中的报文进行处理。
(2) 输出调度器接收来自处理单元的报文描述符,对报文描述符进行调度。
(3) 输出调度器将调度后的报文描述符发送到存取控制单元。
(4) 存取控制单元根据接收的描述符构造读请求,从主存储器中读取出待调度报文。
(5) 将调度后的报文发送到网络中。

Figure 2 Procedure of descriptor-based output scheduling图2 基于描述符的调度输出流程
2.2 理论分析
本节将着重于分析基于描述符的输出调度方式在存储资源消耗以及系统性能方面的特点。
2.2.1 存储资源消耗
调度输出器中所使用的缓存空间如图3所示,存储空间可以分为输入队列以及输出队列。多个输入队列中携带的多条流调度输出到输出队列中。

Figure 3 Architecture of output scheduler图3 输出调度器结构图

如果考虑用描述符的方式,一般以太网报文的大小从64字节至1500字节不等,我们取800字节作为平均值,而一个描述符只需要8个字节就可以存储报文在I/O操作以及队列调度时所需各种摘要信息,这样原本250 Mb的存储空间采用描述符的方式压缩后只需要2.5 Mb。
假设输出调度器中的队列数量为m,每个队列中存储的报文个数为k,输出调度器的总存储空间为B,报文的长度取平均值800字节。如果采用基于报文的调度方式,则B=800*k*m;如果采用基于描述符的调度方式,描述符的长度为8 B,则B=8*k*m。基于报文与基于描述符的调度方式在存储空间上的对比如图4所示。
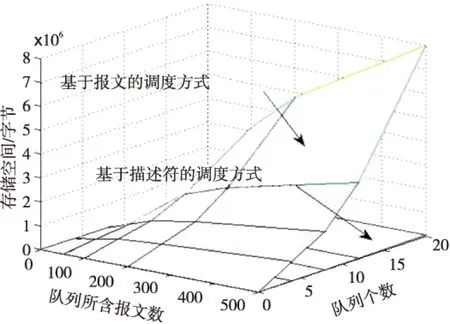
Figure 4 Storage contrast图4 存储空间对比图
可见,描述符输出调度方式与直接调度报文相比,可节省大量存储空间。
2.2.2 处理性能分析
本小节将着重分析基于报文的输出调度方式与基于描述符的输出调度方式在处理性能上的差异。相关参数如表1所示。
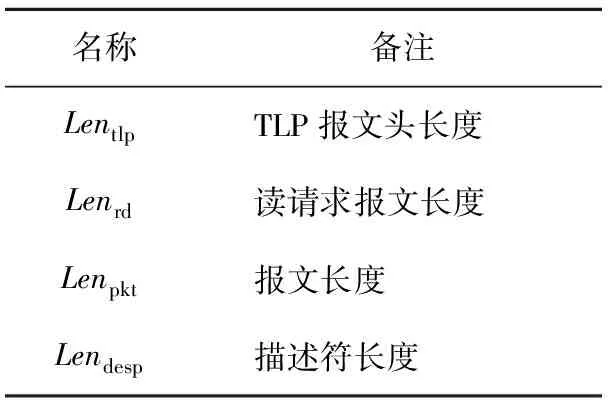
Table 1 Analysis parameters instruction
(1)基于报文的输出调度方式。
若采用直接对报文进行输出调度的方式,各阶段性能分析如下:
①提取报文,包括:
a处理单元通告存取控制单元所需处理的发送描述符的基地址及个数,根据描述符的基地址和长度,存取控制单元启动一次DMA读请求描述符操作,存取控制单元向报文I/O引擎发送报文描述符。
b 存取控制单元向主存发送报文读请求。
c 系统向存取控制单元返回报文。
②输出调度器中的入队操作,将报文根据其所属流的不同优先级插入不同队列中,所需时间记为Tpkt_in_queue。
③输出调度器中的出队操作,不同队列中的报文调度后输出,所需时间记为Tpkt_out_queue。
记报文I/O的速率为Si/o,则Si/o等于总线带宽除以每个报文在发送过程中占用的实际位数,因此:

整个系统的处理速率为:
min{Si/o,1/Tpkt_in_queue,1/Tpkt_out_queue}
(2)基于描述符的输出调度方式。
若采用基于描述符的输出调度,相关性能分析如下:
①处理单元通告存取控制单元所需处理的发送描述符的基地址及个数,根据描述符的基地址和长度,存取控制单元启动一次DMA读请求描述符操作,处理单元向存取控制单元发送报文描述符。
②输出调度器中的入队操作,将描述符根据其所属流的不同优先级插入不同队列中,所需时间记为Tdesp_in_queue。
③输出调度器中的出队操作,不同队列中的报文调度后输出,所需时间记为Tdesp_out_queue。
④输出调度器利用报文描述符向主存发送报文读请求。
⑤处理单元向存取控制单元返回报文。
基于描述符的调度方式与基于报文的调度方式相比,报文I/O的传输速率不变,整个系统的处理速率为:
min{Si/o,1/Tdesp_in_queue,1/Tdesp_out_queue}
由于报文长度远远大于报文描述符的长度,因此在输出调度器内部的入队以及出队操作时,基于描述符的输出调度方式在从主存中读取数据以及向主存中写入数据时的延迟都会较小,即:
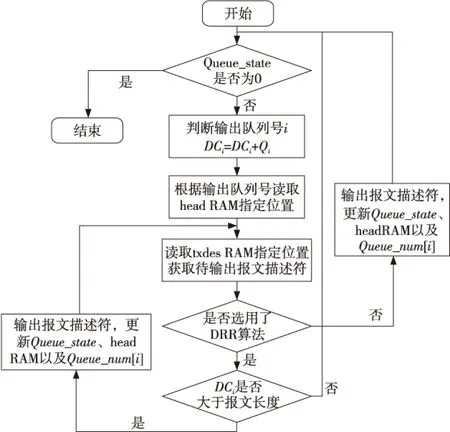
Tdesp_in_queue Tdesp_out_queue 由于在大部分网络设备调度输出的时候,通常情况下报文I/O的传输速率或处理单元的处理速率是限制系统性能的重要因素,而调度模块的处理速率相比快很多,因此两种处理方式在处理速率上是近乎相等的。 而对于相同大小的输入缓冲队列,由于基于描述符的方式可以存放更多的报文,调度模块可以更好地缓存突发流量,减少丢包现象的发生。额外缓存下来的报文会在模块相对空闲的时候被调度输出,这样在系统遭遇突发流量的时候可以提高系统吞吐率。 在实例化输出调度IP核时,会通过参数传递的方式对输出调度IP核支持的队列数目以及每个队列中缓存的描述符个数进行初始化。 输出调度IP核的外部接口如图5所示,其中,输出调度IP核与处理单元和存取控制单元用FIFO连接,输出调度IP核接收来自处理单元的描述符,经调度处理后发送到存取控制单元,存取控制单元从主存中取出报文发送。图中的txdesRAM用于缓存报文描述符;headRAM用于存储不同优先级队列头部报文描述符在txdesRAM中的存储位置;tailRAM则用于存储不同优先级队列尾部报文描述符在txdesRAM中的存储位置;管理模块负责配置此输出调度IP核可能用到的参数。 Figure 5 Interface of output scheduling IP core图5 输出调度IP核接口图 输出调度IP核与txdesRAM、tailRAM以及headRAM的接口为Alter的RAM。IP核的标准接口与处理单元和存取控制单元的接口为两个FIFO接口。在与管理单元的接口中,test信号是检测信号,在IP核出现故障时检测其内部状态,test信号由IP核内部重要状态寄存器以及子模块状态机运转中的当前状态拼接而成。queue_wren为写有效信号,该信号置1时,写入的队列发送额度有效。queue_id为欲配置的队列编号。queue_q表示为队列配置的发送额度。scheduling_mode信号用于调节输出调度模块的输出调度算法选择,其中00代表严格优先级算法,01代表轮循算法,10代表差额轮循算法,11为保留位。 在输出调度IP核工作之前,会先根据接收的管理模块的配置信息为每个队列分别设置发送额度,对txdes RAM的存储空间进行分配,对head RAM以及tail RAM中的内容进行初始化。 本IP核支持严格优先级调度算法(PQ)、轮循调度算法(RR)以及差额轮询(DRR)输出调度算法。严格优先级调度算法(PQ)即根据队列的不同优先级,采取高优先级队列先输出、低优先级队列后输出的算法。轮循算法调度(RR)即每个队列输出一个报文后轮循下一个队列输出。差额轮询调度算法(DRR)为每个队列设置不同的发送额度Qi,并为每个队列设置差额计数器DCi。系统每次输出前会顺序轮询不同队列,每次轮询到一个队列,会将该队列的差额与发送额度相加,得到新的差额值。队列每发送出去一个报文,差额值会减去报文长度,当剩余差额值小于待发送报文长度时,则队列无法输出,轮询下一个队列。IP核主要的状态存储器包括: Queue_num[i]:用于存储优先级为i的队列的描述符个数。 Queue_state:记录所有队列的当前发送状态,第i位对应优先级为i的队列,对应位为1代表队列有描述符需要调度输出,为0代表无描述符需要调度输出。 输出调度IP核可以分为接收数据和发送数据两个子模块。 4.1 接收数据 接收一个报文描述符,根据描述符中的优先级信息获取描述符需要插入的队列号。利用Queue_num[i]判断对应队列是否已满,若已满,则丢弃该报文描述符。若对应队列还有剩余存储位置,则根据描述符中所包含的报文优先级信息访问tail RAM,获取报文描述符在txdes RAM中的存储位置,将报文描述符写入到txdes RAM中,对tail RAM存储的队列尾部存储位置内容进行更新,将Queue_num[i]加1,Queue_state指定位置写1。接收、处理一个报文描述符的流程如图6所示。 Figure 6 Flowchart of receiving data图6 接收数据流程图 根据接收数据的处理流程,接收数据模块的状态机如图7所示。 Figure 7 State machine of receiving data图7 接收数据模块状态机 receive_initial:初始化tail RAM以及txdes RAM,状态跳转到receive_idle。 receive_idle:若连接fifo中有数据,则从FIFO中取出一个数据,状态跳转到receive_readtail;若无数据,则状态跳转回receive_idle。 receive_readtail:根据队列优先级读取tailtable中的值。 receive_stalone:读取RAM空转的第一个周期。 receive_staltwo:读取RAM空转的第二个周期。 receive_insert:根据从tailtable中读取的数据将描述符插入到txdestable对应位置中。 4.2 发送数据 根据队列状态寄存器Queue_state判断要输出的队列,判断方法如下:假设共有m条队列,编号由1至m,上一次轮询发送的队列编号为m,若采用的是DRR或者RR算法,则将Queue_state循环向右移动x位,而后由低位向高位找出第一个为1的数据位,设为y,则此次需要轮询发送的队列编号i=(x+y)%m。而若采用的是PQ算法,则由高位到低位选取第一个为1的数据位作为输出的队列号。 获取发送队列编号i后,将队列的剩余差额DCi加上队列的发送额度Qi(若不是采取DRR算法,则省略此步),根据编号i访问head RAM获取队列头部报文描述符在txdes RAM中的存储位置,访问txdes RAM获取待发送的报文描述符。若采取的不是DRR算法,则更新状态信息,Queue_num[i]减1,若Queue_num[i]等于0,则将Queue_state的对应位置0,将head RAM的第i位加1,输出报文描述符,重新选择下一个输出队列进行输出;若采用的是DRR算法,则用报文描述符中携带的报文长度信息与差额DCi进行比较,若长度信息大于DCi,则轮询下一个队列;若长度信息小于DCi,则将此报文描述符发送出去,并将DCi减去报文长度,Queue_num[i]减1,若Queue_num[i]等于0,还须将Queue_state的第i位置为0,而后继续输出次队列的数据,直到剩余差额DCi小于待发送报文长度。发送数据时的流程图如图8所示。 Figure 8 Flowchart of sending data图8 发送数据流程图 根据图8的处理流程,发送数据模块的状态机如图9所示,其状态描述如下: send_initial:初始化head RAM,状态跳转到send_idle。 send_idle:读取Queue_state,若其为0,代表无队列可以输出,状态跳转回send_idle;若Queue_state不为0,且使用的调度算法为DRR或者RR算法,则将Queue_state循环向右移位,移动位数如4.2节所述。 send_match:根据Queue_state选择输出队列号,并读取对应的head_RAM值。 send_stalone:读RAM表空转的第一个周期,状态跳转到send_staltwo。 send_staltwo:读RAM表空转的第二个周期,若申请读RAM的是send_match状态,则状态跳转到send_rdhead;若读RAM的是send_rdhead或send_output状态,则状态跳转到send_output。 send_rdhead:根据从head RAM中读取出的head位置读取txdes RAM相应位置,状态跳转到send_stalone。 Figure 10 Diagram of signal tap图10 signal tap示意图 send_output:若选取的是RR或PQ算法,则将报文描述符输出,修改Queue_num以及Queue_state寄存器,状态跳转到send_stalthree。若采取的是DRR算法,则需要根据DCi与待发送报文的长度进行比较,如果DCi大于待发送报文长度,但是发送出当前描述符后队列中无剩余报文描述符,则将报文描述符发送并修改状态寄存器Queue_num以及Queue_state后,状态跳转到send_stalthree;若DCi小于待发送报文长度,则不发送报文描述符,状态跳转到send_stalthree。如果DCi大于报文长度,则将描述符输出,修改Queue_num以及Queue_state寄存器,读取队列的下一个报文描述符进行输出判定,状态跳转到send_stalone。 send_stalthree:空转一个时钟周期,否则send_idle状态里对Queue_state寄存器的移位操作会发生错误,状态跳转回send_idle。 Figure 9 State machine of sending data图9 发送数据模块状态机 我们使用Altera FPGA[11](现场可编程门阵,Stratix IV EP4SGX180KF40C2)实现了基于描述符的输出调度IP软核,通过使用QuartusII硬件编程工具对代码进行分析,综合分析其所占用的逻辑资源情况,如表2所示。 Table 2 Logic resource consume of descriptor-based output scheduling IP core 图10给出了系统运行时QuartusII中的signal tap图,其中numqueue对应队列中报文描述符的个数,tdma_des_wr表示输出FIFO的写信号,当该信号置高时,报文被调度输出。 针对基于报文的输出调度方式占用存储空间大的缺点,本文提出了一种基于描述符的报文输出调度方式,给出了这种报文处理模式的基本流程,并通过理论分析证明基于描述符的输出调度方式可以在大量降低存储空间需求的同时,保证系统的性能。在此基础上,对输出调度IP核进行了设计实现。该IP可以通过参数配置多种常用输出调度算法,基于FPGA的实验验证了所设计实现的基于描述符的输出调度IP核在实际应用中的功能正确性和可行性。 [1] Zeng Liang-zhao,Benatallah B, Ngu A H H, et al. QoS-aware middleware for web services composition[J]. IEEE Transactions on Software Engineering,2004,30(5):311-327. [2] Ran Shu-ping. A model for web services discovery with QoS[J]. ACM SIGecom Exchanges, 2003,4(1):1-10. [3] Shreedhar M, Varghese G. Efficient fair queuing using deficit round robin[J]. ACM Transactions on Networking, 1996,4(3):375-385. [4] Zhang Li-xia, VirtualClock:A new traffic control algorithm for packet switching networks[C]∥Proc of the ACM Symposium on Communications Architectures&Protocols, 1990:19-29. [5] Demers A, Keshav S, Shenker S. Analysis and simulation of a fair queueing algorithm[C]∥Proc of SIGCOMM’89, 1989:1-12. [6] Bennett J C R, Zhang Hui. WF2Q:Worst-case fair weighted fair queueing[C]∥Proc of INFOCOM’96, 1996:120-128. [7] Ghodsi A, Sekar V, Zaharia M, et al. Multi-resource fair queueing for packet processing[C]∥Proc of SIGCOMM’12, 2012:1-12. [8] Chauhan P,Clarke E M,Lu Y,et al.Verifying IP-core based system-on-chip designs[C]∥Proc of the 12th Annual IEEE International ASIC/SOC Conference, 1999:27-31. [9] Varma P, Bhatia S. A structured test re-use methodology for core-based system chips[C]∥Proc of International Test Conference, 1998:294-302. [10] Appenzeller G,Keslassy I,McKeown N.Sizing router buffer[C]∥Proc of SIGCOMM’04, 2004:284-292. [11] Wang Cheng,Cai Hai-ning,Wu Ji-hua. The design of altera FPGA/CPLD[M]. Beijing:Posts & Telecom Press, 2005.(in Chinese) 附中文参考文献: [11] 王诚,蔡海宁,吴继华.Altera FPGA/CPLD设计[M]. 北京:人民邮电出版社,2005. ZHAO Guo-hong,born in 1965,research fellow,his research interests include network communication, and routing and switching. 胡勇庭(1989-),男,黑龙江牡丹江人,硕士生,研究方向为网络处理器、路由与交换。E-mail:yongtinghu@163.com HU Yong-ting,born in 1989,MS candidate,his research interests include network processor, and routing and switching. 李韬(1983-),男,安徽萧县人,博士,助理研究员,研究方向为网络处理器和网络通信。E-mail:Taoli.nudt@gmail.com LI Tao,born in 1983,PhD,assistant researcher,his research interests include network processor, and network communication. 孙志刚(1973-),男,江苏东海人,博士,研究员,研究方向为下一代网络和高性能互连。E-mail:sunzhigang@263.com SUN Zhi-gang,born in 1973,PhD,research fellow,his research interests include next generation network,and high performance interconnection. Design and implementation of output scheduling IP core based on packet descriptor ZHAO Guo-hong,HU Yong-ting,LI Tao,SUN Zhi-gang Output scheduling is an important QoS technique. The packet-based output scheduling technique is widely used for QoS component due to its simplicity. However, large on-chip packet buffer required by the technique increases the chip area and production cost. Aiming at the problem, a novel output scheduling technique based on packet descriptor is proposed. The descriptor-based output scheduling technique can reduce storage space requirements without degrading system performance. The design and implementation of the output scheduling IP core based on this descriptor-based technique is also introduced, including the external interface of the IP core, the parameter configuration and the internal processing procedure. The experiments carried out on FPGA demonstrate the feasibility of the IP core. QoS;output scheduling;descriptor;IP core 2013-07-05; 2013-10-16 国家973计划资助项目(2009CB320503);国家863计划资助项目(2011AA01A10,2011AA01A103,2013AA013505);国家自然科学基金资助项目(61202483) 1007-130X(2014)03-0426-07 TP393.02 A 10.3969/j.issn.1007-130X.2014.03.009 赵国鸿(1965-),男,湖南娄底人,研究员,研究方向为网络通信、路由与交换。E-mail:ghzhao@nudt.edu.cn 通信地址:410073 湖南省长沙市国防科学技术大学计算机学院662教研室 Address:Section 662,College of Computer,National University of Defense Technology,Changsha 410073,Hunan,P.R.China3 接口设计以及参数配置

4 处理流程
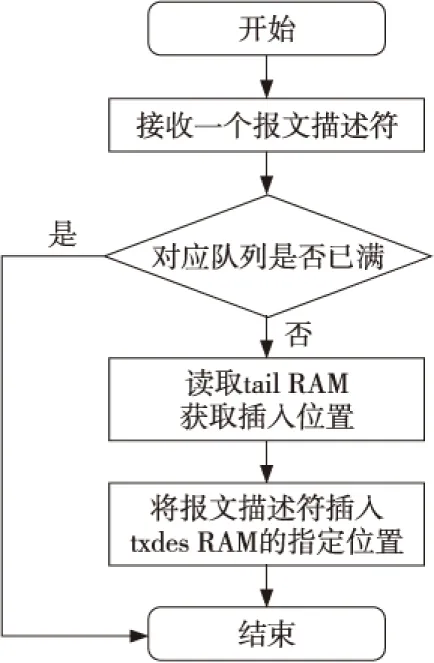
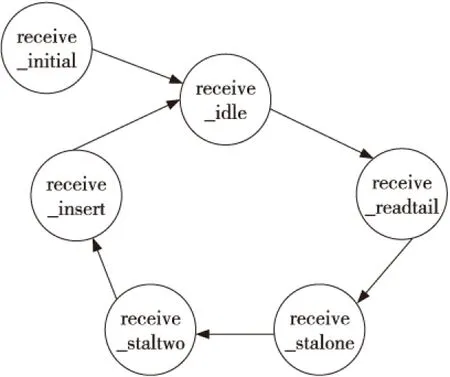


5 实验结果与分析

6 结束语



(College of Computer,National University of Defense Technology,Changsha 410073,China)
