饮水安全工程信息的元数据分级索引算法*
2014-09-13蔡朝晖涂国庆
胡 薇,蔡朝晖,梁 甜,涂国庆
(武汉大学计算机学院,湖北 武汉 430072)
饮水安全工程信息的元数据分级索引算法*
胡 薇,蔡朝晖,梁 甜,涂国庆
(武汉大学计算机学院,湖北 武汉 430072)
分析了当前饮水安全工程数据的发展趋势和主要类型,根据饮水安全工程数据的特点,提出了一种应用型的饮水安全核心元数据模型,设计了饮水安全工程核心元数据的结构和内容,将饮水安全工程核心元数据分为标识信息、数据质量信息、内容信息、空间参照系信息和分发信息五个部分,并且分别描述了五个部分的结构。同时,设计了符合饮水安全工程元数据的元数据分级算法,比较了元数据分级算法和目录子树分区算法以及哈希算法的实验结果。
饮水安全工程;分布式NameNode模型;元数据分级算法
1 引言
饮水安全工程数据是在建设农村饮水安全工程的过程中产生的数据信息,是衡量水质、水量和用水方便程度等综合因素的一种特殊水利信息。饮水安全工程数据要素多,主要包括地图基础地理信息、供水工程信息、行政单位基础数据和监测数据等,数据形式多种多样,如地理信息空间数据、图像、文本等。在传统的农村饮水安全工程建设中,数据的多元化和数据形式的多样化给饮水安全工程数据的存储和检索带来了不便,现有的非结构化的组织形式已经不能适应饮水安全工程数据发展的要求。为此,本文提出了饮水安全工程核心元数据的概念以及元数据分级索引算法。
元数据是描述数据的数据[1],只有对数据进行统一描述,才能有效地管理数据。规范的元数据描述有利于建立各数据间的关联和信息的发现,能够提高检索的效率[2]。由于饮水安全工程信息化是近两年提出的概念,并没有学者专门对饮水安全工程数据进行研究,但在其它领域的数据研究已经比较成熟,如2005年王国复[3]发表的《气象元数据标准与信息发布技术研究》、国土资源信息核心元数据标准(TD/T1016-2003)[4]、2011年张继红[5]发表的《海量交通安全数据的元数据管理研究》等。现有的水利行业的元数据研究主要集中于水利元数据的应用,并没有涉及到饮水安全工程元数据。如2012年孟令奎等人[6]发表的《面向水文数据共享的水文核心元数据模型研究及应用》,该文着重描述水利元数据在水利共享平台中的应用;2011年冯钧等人[7]发表的《水利信息资源元数据管理方法研究》主要研究水利元数据的管理。本文利用水利行业现行的元数据标准作为参考,提出饮水安全工程核心元数据的概念,规范饮水安全工程元数据的定义,利用元数据分级索引算法来查找饮水安全工程数据,着重解决饮水安全工程数据种类多、数据标准化程度低、关联复杂、数据量大的问题,提高农村饮水安全工程信息的规整性,加快检索速度。
2 饮水安全工程数据的特点
与一般的科学数据相比,饮水安全工程数据具备以下两个特点:
(1)地理分布性。作为基本数据,国家农村饮水安全工程数据库包括了国内各省(直辖市)、市(州)、县(市、区)、乡镇内供水水厂的集中式工程数据,包括工程建设信息、实时监测信息,遍布全国,因此饮水安全工程数据具备地理空间的分布特性。
(2)数据要素多。饮水安全工程数据包括了地图数据,供水工程专题数据,省、市州、县区、乡镇专题基础信息,水质、管压安全监测信息,政务信息等。而且每类数据又包括多种要素的数据,如供水工程专题数据包括专题地理信息和专题建设信息,监测数据包括余氯、浊度、水压、流量等测量数据。
整体来说,饮水安全工程数据是描述饮水安全工程的数据,数据量大,且与日俱增,专业性强,具有时间维上的有效性,且数据区域性强,不同市县统计的数据不交叉,数据存储形式多样,以小文件居多。
3 饮水安全工程核心元数据
3.1 元数据定义
首先,介绍几个关于元数据的定义。
元数据:关于数据的数据[2]。
元数据元素:元数据的基本单元,元数据元素在元数据实体中是唯一的[9]。
元数据实体:一组说明数据相同特性的元数据元素,元数据实体可以包含一个或一个以上的元数据实体[8]。
元数据子集:元数据的子集合,由相关的元数据实体和元素组成[6]。
数据集:可以标识的数据集合。通常在物理上可以是更大数据集较小的部分。从理论上讲,数据集可以小到更大数据集内的单个要素或要素属性,一张硬拷贝地图或图表均可以被认为是一个数据集[8]。
饮水安全工程核心元数据指的是标识饮水安全工程信息所需要的最小元数据元素和元数据实体,为元数据元素集的子集[9,10]。
其次,本文采用UML类图方法描述饮水安全工程信息元数据。在元数据结构上采用《水利信息核心元数据》的结构作为本标准的基本结构,在内容上对元数据的特征,包括子集/实体名、元素名、英文名、英文缩写、定义、约束/条件、出现次数、类型和值域[7]进行详细描述。
3.2 饮水安全工程核心元数据结构
饮水安全工程元数据分为元数据元素、元数据实体和元数据子集三层[9,11]。饮水安全工程核心元数据由一个元数据实体和四个元数据子集构成。其中,标识信息、数据质量为必选子集,内容信息、参照系信息为可选子集。每个子集由若干个实体(UML类)和元素(UML类属性)构成。
3.3 饮水安全核心元数据内容
3.3.1 饮水安全核心元数据信息
饮水安全工程元数据信息实体描述饮水安全工程信息的全部元数据信息,用必选实体MD_元数据表示,由以下元数据实体和元数据元素构成:
元数据实体:MD_标识、DQ_数据质量、RS_参照系、MD_分发、MD_内容描述;
元数据元素:元数据创建日期、联系单位、元数据名称、字符集、元数据使用的语言、元数据标准名称、元数据标准版本。
3.3.2 标识信息
标识信息包含唯一标识数据的信息,用MD_标识实体表示,是必选实体。MD_标识是下列实体的聚集:MD_关键词、MD_数据集限制、EX_时间范围信息、MD_联系单位或联系人、MD_维护信息。
MD_标识实体本身包含如下元素:名称、行政区编码、字符集、摘要、日期、状况、数据表示方式。
3.3.3 数据质量信息
数据质量信息包含对数据资源质量的总体评价,用DQ_数据质量实体表示。应包括与数据生产有关的数据志信息的一般说明。DQ_数据质量实体包括两个条件必选的实体,DQ_数据质量说明和DQ_数据志。DQ_数据质量说明是数据集的总体质量信息。DQ_数据志是从数据源到数据集当前状态的演变过程说明。包括数据源信息实体和处理过程信息实体。
3.3.4 内容信息
内容信息包含提供数据内容特征的描述信息,用MD_内容描述实体表示。
3.3.5 空间参照系信息
参照系信息包含对数据集使用的空间参照系的说明,是条件必选子集,用RS_参照系实体表示。是关于地理空间数据集的坐标参考框架的描述信息,它反映了现实世界的空间框架模型化的过程和相关的描述参数。
RS_参照系由三个条件必选的实体构成:SI_基于地理标识的空间参照系、SC_基于坐标的空间参照系、SC_垂向坐标参照系。
4 元数据分级索引算法
本文根据饮水安全工程数据的区域性特点,选取分布式NameNode模型[12],改进目录子树分区算法[13~15]和哈希算法[16],利用Bloom Filter原理设计符合饮水安全工程信息的元数据分级索引算法。
4.1 概念与公式
行政区划请求量:表示该行政区划所需的农村饮水安全工程元数据的请求量,用Request表示。由于请求量的具体数值难以确定,工程元数据的请求量与工程的数量有直接关系,而饮水工程的数量与行政区划的人口密度存在一定的换算关系。每个工程所涉及的文件包括招标文件、合同、工程规划、预算、管网图、厂区布置图、每年的运营报表等多种文件。因此,第m个行政区划的请求量Requestm为:
Requestm=Densitym×f×Naverage
(1)
其中,Densitym代表第m个行政区划的人口密度,f表示饮水安全工程数量与人口密度的转换因子,Naverage代表每个工程文件的平均值。
4.2 Bloom Filter基本思想
元数据分级索引算法包括三部分:一部分是元数据请求被分配到哪个普通NameNode节点上,第二部分是分配到NameNode节点的哪个目录,最后根据NameNode节点中的目录信息查找元数据文件在DataNode中的具体位置。本文采用Bloom Filter与Key-Value的存储位置对应表,来确定元数据文件在DataNode中的存储位置。
Bloom Filter的基本思想是使用一个比特的数组保存信息[17],初始状态时,整个数组的元素全部为0,如图1所示。

Figure 1 Initial data for Bloom Filter
图1 Bloom Filter初始数组
采用k个独立的Hash函数,将每个元数据文件对应到{1,…,m}的位置,当有饮水安全元数据文件存储请求时,k个独立的Hash函数将以元数据标识信息中的元数据文件名为变量,得到k个哈希值,然后将比特数组中的相应位置更改为1,即:
hashi(x)=1(1≤i≤k)
(2)
其中,x是元数据文件名。数组中的某一位置被置为1后,只有第一次有效,以后再置为1将不起作用。如图2所示,假设k=3,x1先通过哈希函数,将数组中的三个位置置为1,在x2通过哈希函数得到的数组位置,将是0的位置置为1,已经是1的位置则不重复置1。
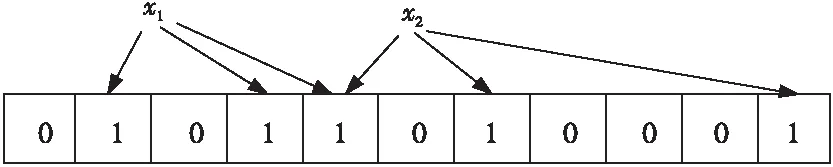
Figure 2 Run of Bloom Filter图2 Bloom Filter运行过程
判断某元素y是否属于这个集合,需对y应用k次哈希函数,如果所有的位置都是1(1≤i≤k),那么就认为y是集合中的元素,否则就认为y不是集合中的元素。如图3所示,y1可能是集合中的元素,y2则不属于这个集合。
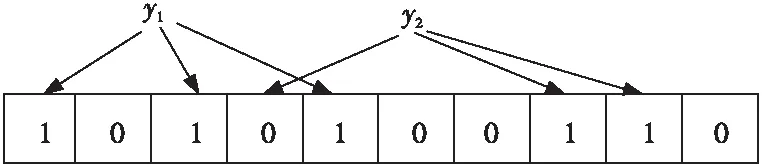
Figure 3 Search process of Bloom Filter图3 Bloom Filter查找过程
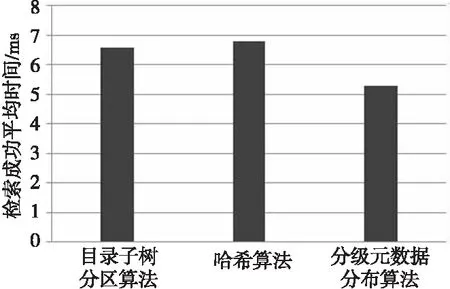
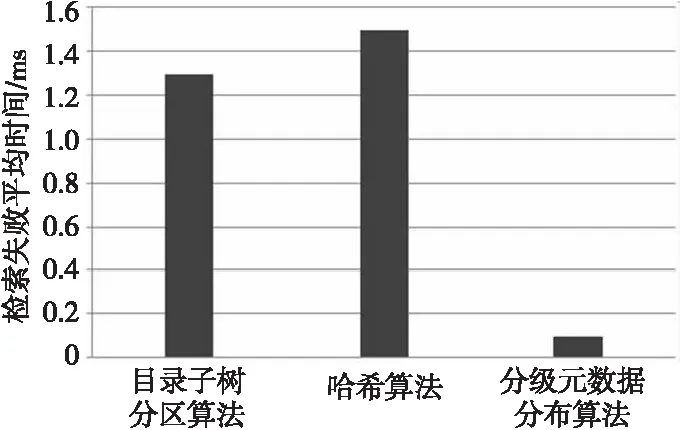
BloomFilter能高效地判断某个元素是否属于一个集合,但这种高效是有代价的,是存在一定的错误率,因为它有可能会把不属于这个集合的元素判定为属于此集合。为简化计算,假设kn (3) 其中第二次近似计算是因为: (4) 令ρ代表比特数组中0的比例,则ρ的数学期望E(ρ)=p,则ρ≈p,因此: (5) 4.3 元数据分级索引算法 元数据分级索引算法包括三个步骤:一是选NameNode节点,二是选目录,三是分配存储位置。 4.3.1 选取NameNode节点 分布式NameNode模型有一个主NameNode节点,一个主SecondaryNameNode和n个普通NameNode节点。其中,主SecondaryNameNode是主NameNode的快照,防止单点失效。算法的基本思想如下: (1)计算行政区划请求数。在本文中所涉及的饮水安全工程指的是湖北省的农村饮水安全工程,因此在普通NameNode节点上分布的是以市级为单位的元数据信息。在这一步中,根据公式(1)给每个市级行政区划的请求赋值,用Requestm表示。 (2)分配NameNode节点。若n为奇数,则将其中一个NameNode节点作为备用节点,n=n-1;若n为偶数,则n不变。分配NameNode节点,得出市级行政区划与NameNode节点映射表。 (3)第二次分组。将偶数个NameNode两两分成组,互为SecondaryNameNode节点,分组的原则为请求量较大的NameNode节点与请求量较小的NameNode节点一组。 4.3.2 选择目录 分配完NameNode节点后,须设定每个NameNode节点的目录,根据市级行政区划与NameNode节点映射表设定一级目录。然后根据一级目录的编码,设定二级目录,二级目录为对应市及所管辖县级行政区划的目录。在饮水安全工程项目中,所涉及的数据类型分为图片类型、视频类型、文本类型等,所以将三级目录按文件类型进行划分,即每个二级目录下对应的三级目录为pic、video、txt等。 4.3.3 分配存储位置 当用户要查找某个饮水安全元数据时,系统首先根据待查找元数据的行政区划编码,从市级行政区划与NameNode节点映射表中找到其对应的NameNode节点;然后,主NameNode节点将用户请求转发给此NameNode节点,收到转发的用户请求的NameNode节点同样将行政区编码进行处理,转化为市级编码,找到其一级目录;然后在一级目录下,根据编码找到二级目录,再根据用户请求的元数据类型,定位到三级目录,在三级目录下根据哈希表,找到对应存储位置并提交给主NameNode节点,由主NameNode节点返回给用户。 饮水安全元数据检索结果分为两种情况,第一种是查找成功,第二种是查找失败。一次饮水安全元数据成功检索过程的检索时间包括主NameNode节点并发处理延迟、主NameNode节点找到对应的NameNode节点的时间、转发用户请求与普通NameNode节点的通信时间、普通节点执行查找目录的时间、查找Hash表读取元数据的时间和返回查找结果给主NameNode的时间。 一次失败的检索包含两种情况,一是定位到目录后,通过BloomFilter过滤后,判定要查找饮水安全工程元数据哈希表不属于该目录;二是通过BloomFilter过滤后,判定其属于该目录,但是通过查询Key-Value表,发现匹配错误,即上文提到的BloomFilter自身的错误率。第一种情况,根据BloomFilter的原理,可知经过k次独立的哈希函数后,如果得到的位置不是全为1,则返回查找失败,要查找的元数据请求不在此目录中,时间复杂度为O(1)。第二种情况是BloomFilter自身的缺陷,但是由于有对应的Key-Value表,即使经过k次哈希操作得到的位置在比特数组中全为1,通过查找对应的键值,如果发现元数据名称不能与之匹配,则返回检索不成功,时间复杂度也为O(1),在用户可以接受的范围内。 本文通过实验仿真验证饮水安全工程元数据模型的元数据分级索引算法在元数据检索上的性能,并与目录子树分区算法和哈希算法在检索成功时间和检索失败时间进行对比。 第一组实验,测试三种算法检索成功的平均检索时间,其中用户数为10,请求数为1 000,仿真结果如图4所示。 Figure 4 Comparison of average time for successful retrieval图4 三种算法检索成功的平均检索时间 在定位NameNode节点的时间上来说,目录子树分区算法能够根据用户请求中的类型定位节点,哈希算法是通过特定的Hash函数,算出用户请求元数据所在的节点。而本文设计的元数据分级索引算法,将市级行政区划和NameNode节点编号存储在一张静态的表中,查找时间与NameNode节点个数有关,时间复杂度为O(n)。在本文的应用中,至多会有14个NameNode节点,三种算法的定位时间基本相同,在查找NameNode节点的步骤上所用时间可以近似算作相等。定位目录的时间复杂度,三种算法也相同,可认为是O(1)。在最后一步定位元数据文件存储位置上,由于Bloom Filter查找成功的时间复杂度是O(1),而目录子树分区算法和哈希算法没有考虑定位物理位置,查找目录下的元数据名称,时间复杂度为O(n),目录下的元数据文件越多,查找速度越慢。 第二组实验,测试三种算法检索失败的平均检索时间,其中用户数为10,请求数为1 000,仿真实验结果如图5所示。 Figure 5 Comparison of average time for failure rerieval图5 三种算法检索失败的平均检索时间 若是检索不在目录下的文件,Bloom Filter将文件名进行Hash运算,可以判定被请求的文件名不在目录中,时间复杂度为O(1)。而另外两种算法,则会遍历目录中的所有文件,直至遍历完,找不到所请求的文件,时间复杂度为O(n)。 对比三种算法在饮水安全工程元数据检索上的应用情况,由于元数据分级算法使用了Bloom Filter,检索效率比其它两种算法效率高,尤其是检索失败的检索请求。 本文分析了饮水安全工程核心元数据的基本特点,并根据相关的标准提出了一种饮水安全工程核心元数据框架,提出了元数据分级索引算法。建立饮水安全工程核心元数据框架和元数据分布算法是统一管理饮水安全工程数据的基础,只有很好地对饮水安全数据进行描述和检索,才能有效地对饮水安全数据进行管理。 由于饮水安全工程数据具有地理分布广、时间有效性和数据要素多的特点,而且数据量与日俱增,所以本文提出的饮水安全工程核心元数据结构和算法不一定适用于所有的情况,该结构仍然需要不断地完善。 [1] Geng Qing-zhai, Zhu Xing-ming. Research and construction of standard system of scientific data sharing of water resources[J]. Journal of Hydrolic Engineering, 2007, 38(2):233-238.(in Chinese) [2] Guo Shi-ming, Jing Ji-peng. The metadata function of network information resource organization and retrieval[J]. Information Science, 2004,22(12):1455-1457.(in Chinese) [3] Wang Guo-fu,Xu Feng,Wu Zeng-xiang.Technology research of meteorological metadata standard and information release[J]. Journal of Applied Meteorological Science, 2005,16(1):114-121.(in Chinese) [4] TD/T 1016-2003,Core metadata standard for land and resources information[S].Beijing:Ministry of Land and Resources of the People’s Republic of China,2003.(in Chinese) [5] Zhang Ji-hong, Chen Xiao-quan. Research of metadata management for large-scale traffic security data[J]. Journal of Computer Research and Development,2011,48(1):74-77.(in Chinese) [6] Meng Ling-kui, Li San-xia, Zhang Wen, et al. Research and application of hydrological core metadata model for hydrological data sharing[J]. Journal of China Hydrology, 2012, 32(1):1-5.(in Chinese) [7] Feng Jun, Tang Zhi-xian, Huang Ru-chun, et al. Study on water conservancy information resources metadata management method[J]. Water Resource Informatioin, 2011(5):1-4.(in Chinese) [8] Guo Chun-yi, Gang Qiang. Hydrological information sharing and its security analysis based on spatial data warehouse[J]. Jilin Water Resources, 2009(5):38-40.(in Chinese) [9] SL 473—2010, Core metadata of water resources information[S]. Beijing:Ministry of Water Resources of the People’s Republic of China, 2010.(in Chinese) [10] Yao Yan-min, Jiang Zuo-qin, Yan Tai-lai. A study of core metadata for land and resource information[J]. Acta Geodaeticaet Cartographica Sinica, 2001, 30(4):349-354.(in Chinese) [11] Gu Ji-rong, Miao Fang, Wang Cheng-shan. Research of metadata information sharing system[J]. Computing Techniques for Geophysical and Geochemical Exploration, 2006, 28(1):75-79.(in Chinese) [12] Li Kuan. Research of the model of distributed NameNodes in HDFS[D]. Guangzhou:South China University of Technology, 2011.(in Chinese) [13] Morris J H, Satyanarayanan M, Conner M H, et al. Andrew:A distributed personal computing environment[J]. Communications of the ACM, 1986, 29(3):184-201. [14] Satyanarayanan M, Kistler J J, Kumar P, et al. Coda:A highly available file system for a distributed workstation environment[J]. IEEE Transactions on Computers, 1990, 39(4):447-459. [15] Weil S A, Pollack K T, Brandt S A, et al. Dynamic metadata management for petabyte-scale file systems[C]∥Proc of the 2004 ACM/IEEE Conference on Supercomputing, 2004:4. [16] Corbett P F, Feitelson D G. The Vesta parallel file system[J]. ACM Transactions on Computer Systems(TOCS), 1996, 14(3):225-264. [17] Niu De-jiao, Cai Tao, Zhan Yong-zhao, et al. Hierarchical metadata indexing algorithm of mass storage system[J]. Application Research of Computers, 2012, 29(2):510-517.(in Chinese) 附中文参考文献: [1] 耿庆斋,朱星明.水利科学数据共享标准体系研究与构建[J].水利学报,2007,38(2):233-238. [2] 过仕明,靖继鹏.元数据在网络信息资源组织与检索中的作用[J].情报科学,2004,22(12):1455-1457. [3] 王国复,徐枫,吴增祥.气象元数据标准与信息发布技术研究[J].应用气象学报,2005,16(1):114-121. [4] TD/T 1016-2003,国土资源信息核心元数据标准[S].北京: 中华人民共和国国土资源部,2003. [5] 张继红,陈小全.海量交通安全数据的元数据管理研究[J].计算机研究与发展,2011,48(1):74-77. [6] 孟令奎,李三霞,张文,等.面向水文数据共享的水文核心元数据模型研究及应用[J].水文,2012,32(1):1-5. [7] 冯钧,唐志贤,黄如春,等.水利信息资源元数据管理方法研究[J].水利信息化,2011(5):1-4. [8] 郭纯一, 冮强.基于空间数据仓库的水文信息共享及其安全性浅析[J].吉林水利,2009(5):38-40. [9] SL 473—2010,水利信息核心元数据[S].北京:中华人民共和国水利部,2010. [10] 姚艳敏,姜作琴,严泰来.国土资源信息核心元数据的研究[J].测绘学报,2001, 30(4):349-354. [11] 辜寄蓉, 苗放, 王成善. 基于元数据的信息共享机制研究[J]. 物探化探计算技术, 2006, 28(1):75-79. [12] 李宽.基于HDFS的分布式NameNode节点模型的研究[D].广州:华南理工大学,2011. [17] 牛德姣,蔡涛,詹永照,等.海量存储系统中的元数据分级索引算法[J].计算机应用研究,2012,29(2):510-517. HUWei,born in 1989,MS candidate,her research interest includes computer architecture. 蔡朝晖(1968),女,湖北黄冈人,博士,副教授,研究方向为分布式信息处理。E-mail:zhcai@whu.edu.cn CAIZhao-hui,born in 1968,PhD,associate professor,her research interest includes distributed information processing. 梁甜(1988),女,河北石家庄人,硕士生,研究方向为信息存储。E-mail:441493972@qq.com LIANGTian,born in 1988,MS candidate,her research interest includes information storage. Ametadataclassificationindexingalgorithmfordrinkingwatersafetyprojectinformation HU Wei,CAI Zhao-hui,LIANG Tian,TU Guo-qing (School of Computer,Wuhan University,Wuhan 430072,China) The current developmental trends and the main types of the drinking water safety project data are analyzed.Considering the characteristics of the drinking water safety project data,a core metadata model applied in the drinking water safety is proposed, and the structure and content of the core metadata of the drinking water safety project are designed.The core metadata of the drinking water safety project can be divided into five parts:identity information, data quality information, content information, space reference information and distribution information whose construction is described respectively. A metadata classification algorithm is designed, which conforms to the drinking water safety project data.The metadata classification indexing algorithm improves the management and work efficiency of rural drinking water safety compared with the subtree partitioning algorithm and the Hash algorithm. drinking water safety project;distributed NameNode model;metadata classification algorithm 1007-130X(2014)11-2223-06 2014-06-05; :2014-08-21 TP311.13 :A 10.3969/j.issn.1007-130X.2014.11.028 胡薇(1989),女,湖北武汉人,硕士生,研究方向为计算机系统结构。E-mail:380476943@qq.com 通信地址:430072 湖北省武汉市武汉大学计算机学院 Address:School of Computer,Wuhan University,Wuhan 430072,Hubei,P.R.China5 实验结果
6 结束语



