基于SCIT算法的天气雷达回波风暴识别跟踪方法
2014-09-08汤玉杰
汤玉杰,佘 勇
(成都信息工程学院 电子工程学院,成都 610225)
基于SCIT算法的天气雷达回波风暴识别跟踪方法
汤玉杰,佘 勇
(成都信息工程学院 电子工程学院,成都 610225)
基于雷达数据的风暴体识别、追踪及预警方法是最早出现的临近预报技术,其中对风暴的准确识别是进行风暴体追踪和预警的前提。本文借鉴SCIT (Storm Cell Identification and Tracking)算法对强风暴进行识别,根据“宁短勿长,特征相似”的原则匹配两时刻的风暴单体。通过风暴在过去两时刻的质心位置进行线性外推从而预报下一时刻风暴的位置。结果显示可以较好地识别强风暴并实现对识别出的风暴的大致跟踪。
SCIT;线性外推;临近预报
0 引 言
对流云降水是一种局地性天气,在自然界降水中占了很大的比例。同时,又由于它具有生消变化快、降水强度大等特征,容易导致山洪、冰雹、泥石流等自然灾害。因此,人们越来越重视利用雷达系统对强对流天气进行自动识别、跟踪和警戒。20世纪70年代以来, 国内外雷达气象学者在用雷达探测强对流天气领域做了大量的工作:Zittel[1]提出了利用雷达反射率在连续的三维区域大于给定的反射率阈值来识别风暴的方法, 并利用被识别的风暴在过去与现在的位置来估计它的运动速度, 以此速度来预报它在下一时刻的位置, Dix on 和Wiener等人[2]又先后改进了这种方法;肖艳姣等人[3]在风暴的自动识别、跟踪与预报中详细介绍了WSR-88D中的风暴核识别方法;Johnson等人[4]提出了一种用来识别、特征化、追踪以及预报三维风暴体的短期运动的改进WSR-88D算法(SCIT,Storm Cell Identification and Tracking);张鹏等[5]在多普勒天气雷达单PPI上设想使用风暴核识别算法中搜索二维风暴分量的方法来探测强风暴;王芬等[6]用新一代多普勒天气雷达复合体扫描资料及WSR-88D提供的SCIT算法对2007至2008年发生在贵州黔西南地区的40次天气过程个例进行验证分析。本文则利用CAPPI资料对SCIT算法进行改进性的验证。
1 风暴识别
1.1 资料预处理
对风暴识别之前先对雷达数据资料进行处理,即先对立体压缩原始数据进行解压,然后对其读取至相应的内存中。通过简单插值将雷达数据映射到笛卡尔坐标下,则得到每个仰角层的原始雷达回波图。本文所处理的资料是针对CAPPI资料,因此需要对PPI资料作进一步的处理,再次利用插补技术将所有的仰角层上的雷达图按照高度进行切割,至此完成了本文的前期工作。
1.2 风暴定义
本文将某个连续三维区域的体积V和雷达反射率Z大于给定的体积阈值和反射率阈值(TZ)(其中也可包含一定数量的比反射率阈值小不到5 dBz的点)定义为风暴单体。文中假设风暴由每个高度层的二维风暴分量构成,而每个风暴分量又是由方位上连续的风暴段构成。反射率阈值的大小,根据不同的风暴类型来给定,可分成以下几类[7]:
超级单体风暴
TZ=40~50 dBz
对流风暴
TZ=30~40 dBz
中尺度对流复合体
TZ=25~30 dBz
雪带
TZ=15~20 dBz
1.3 风暴段的搜索
风暴段是指按径向排列的反射率因子大于或等于给定阈值的一组连续距离库,即该识别算法中的一维搜索。
1.3.1 风暴段搜索的阈值
本文中使用的主要阈值如下:
(1) 反射率因子阈值TZ:根据风暴定义此处选取40 dBz,大于该阈值的且满足一定条件的即为有效风暴段;
(2) 风暴段长度阈值L:风暴段的长度必须大于该阈值,本文设定为4 km;
(3) 淘汰的反射率因子差阈值DZ:若风暴段遇到的库点阈值与反射率因子阈值之差大于淘汰反射率因子阈值时,则终止该风暴段的搜索,本文设定为5 dBz;
(4) 淘汰的反射率因子个数阈值N:如果存在库点反射率值在反射率阈值与淘汰反射率阈值之间,统计其个数,若个数大于该阈值,则终止本段搜索,本文设定为2。
1.3.2 风暴段的搜索过程[8]
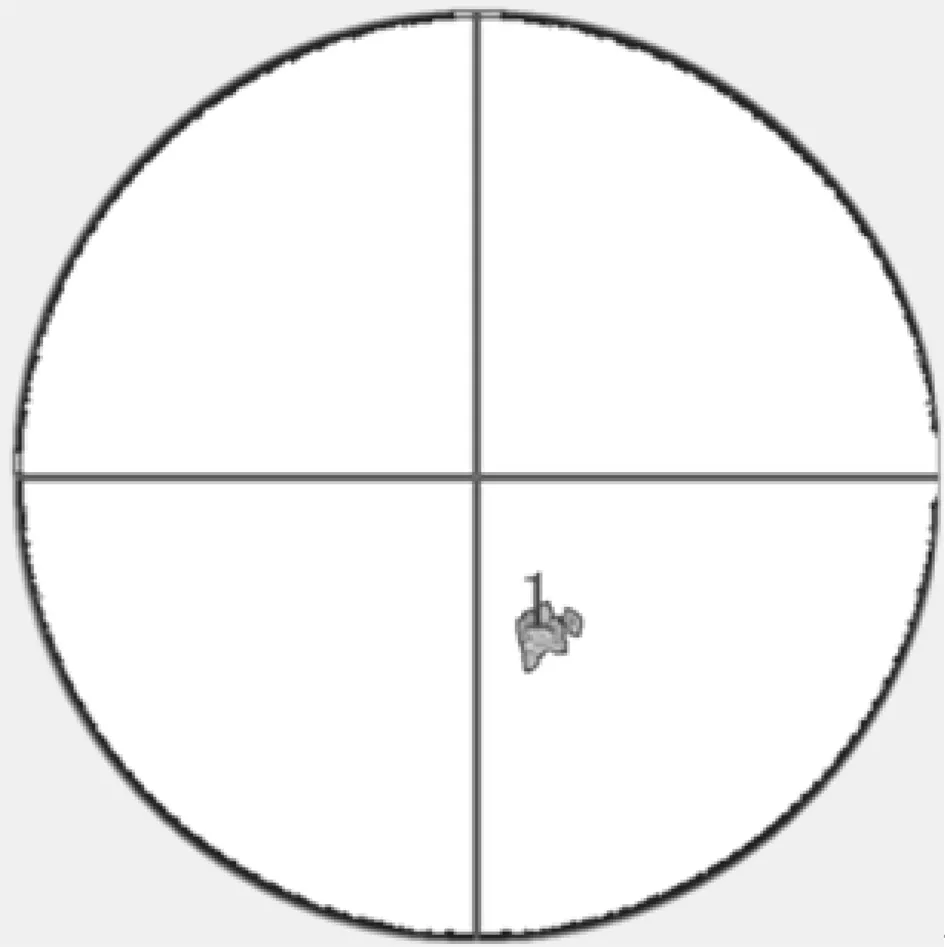
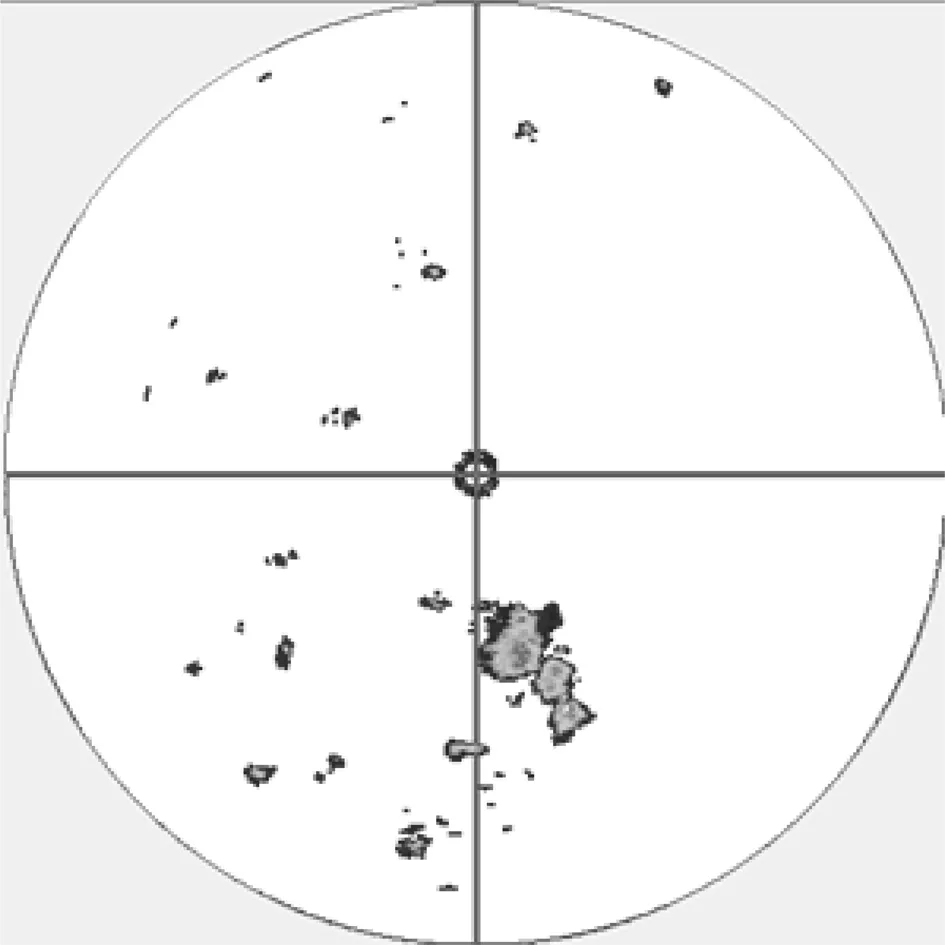
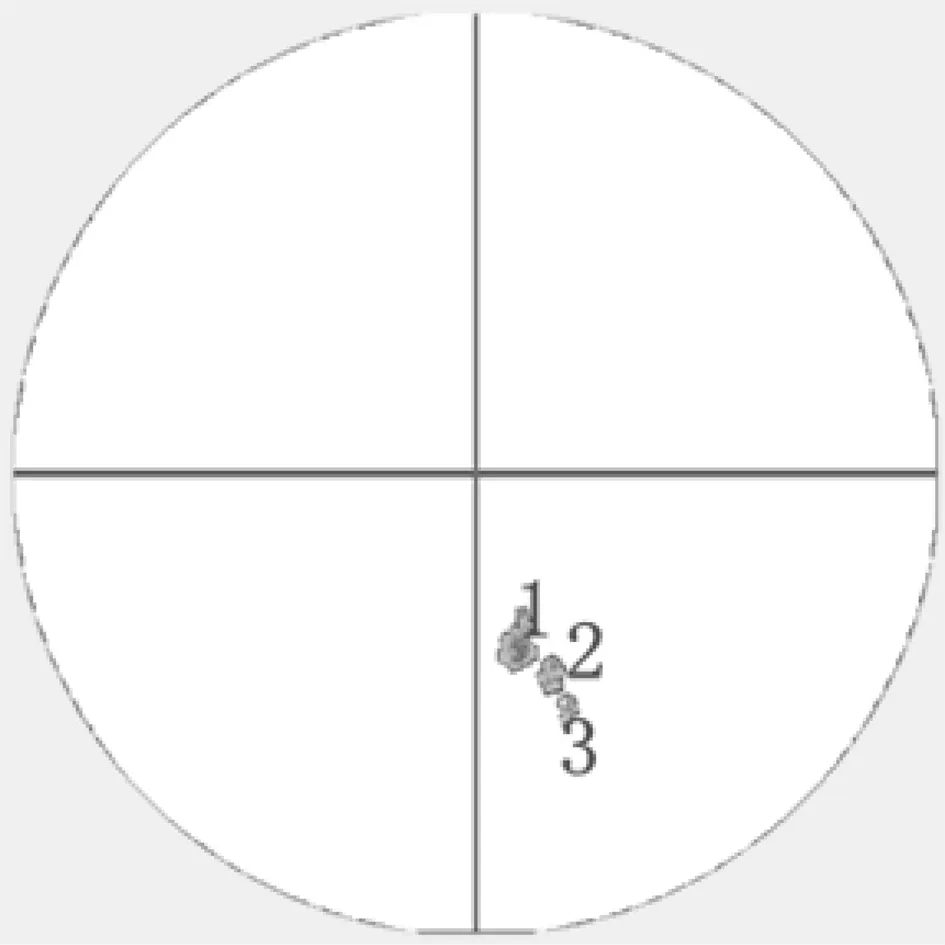
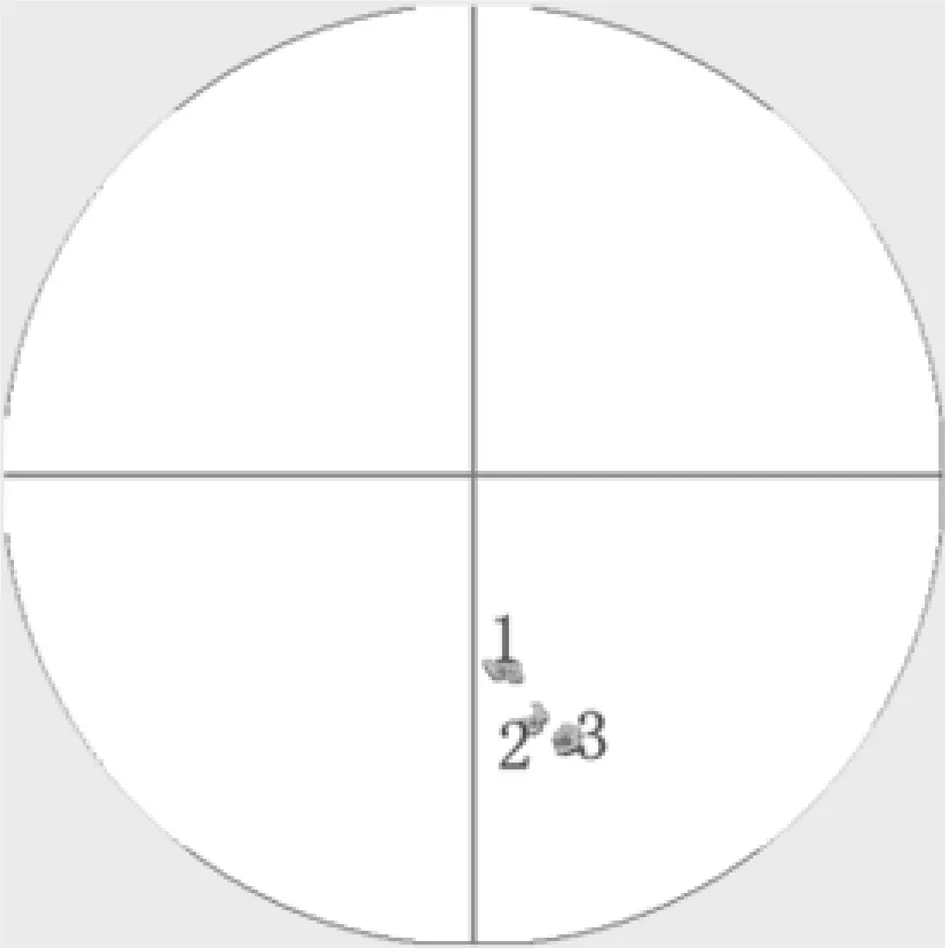
(1) 沿径向对240个库点进行判断,若搜索到反射率Z第一次大于TZ的点,则把这个点以后的连续满足Z>TZ的且属于同一条径线的点归入到一个风暴段中,直到遇到Z≤TZ的点。若这个满足Z≤TZ的点的Z值大于DZ,则开始记下满足DZ (2) 对于搜寻到的风暴段,若长度大于L,则被视为有效风暴段。 同时,将有效风暴段的段起始点、段终止点、段所在的径向标号、段所在的方位标号分别保存到数组中以备后用,还应通过计算得出每个有效风暴段的反射率中心点。 1.4 风暴分量的搜索 风暴分量的算法为在同一CAPPI中沿径向搜寻连续的有效风暴段。若能够同时满足以下3个条件[8]的风暴段则认为可以合并成一个风暴分量: (1) 在同一个风暴分量中,相邻的风暴段的方位间距为0.7°; (2) 在同一个风暴分量中,相邻的风暴段的首尾距离至少重叠2.0 km; (3) 一个风暴分量至少包含3个风暴段且几何面积应大于30 km2。 同时,对识别出的有效风暴分量计算出以反射率因子为权重的风暴分量中心和面积以备后用。 1.5 三维风暴体的合成 风暴的算法为搜寻不同高度层(不同CAPPI)垂直相关的风暴分量。从第2个高度层开始每个高度层的风暴分量都和它下面相邻的高度层的风暴分量进行比较,可分成以下几个步骤: (1) 寻相邻仰角层的风暴分量的反射率权重中心之间的水平距离(也称为搜寻半径[8])小于5 km的风暴分量为垂直相关的风暴分量。 (2) 步骤(1)后,如果没有垂直相关的风暴分量,则把搜寻半径改为7.5 km,继续搜寻。 (3) 步骤(2)后,如果还没有垂直相关的风暴分量,则把搜寻半径改为10 km,继续搜寻。 如果同时有几个风暴分量与其相邻仰角的一个风暴分量垂直相关,那么选择相邻高度层的风暴分量的反射率权重中心之间的水平间距最小的一个。 多个风暴分量要合并成一个风暴必须满足以下条件:同一个风暴中至少要有两个仰角相邻且垂直相关的风暴分量,并且风暴的体积必须大于50 km3。 对每一个风暴可先计算以反射率为权重的风暴中心和体积,以备后用。 要想对相邻两时刻的风暴单体进行跟踪,首先要对两时刻的单体进行匹配。本文借鉴TITAN算法中最优匹配[2,7]方法,即依据“宁短勿长,形状相似”原则,得到相应的匹配结果,进而通过计算匹配风暴对之间的质心长度来确定下一时刻单体的偏移方向和大小,依据该单体的偏移速度进一步求出下一时刻单体的预测位置。前提是要假定风暴趋向于沿直线运动,风暴的消失或者增长遵循线性规则,偏离上述行为则是随机发生的。根据风暴单体在过去相邻时刻的反射率权重中心位置和面积及移动矢量, 利用线性外推方法预报单体下一时刻的中心位置。 本文根据上述算法, 在Visual C++6.0平台上利用天气雷达体扫资料完成对风暴的自动识别、追踪和临近预报。图1为2012年4月4日成都市气象站X波段雷达14时52分体扫资料得到的12000 m高度上的原始雷达回波图,图2为利用SCIT识别后其单体图。图3为2012年4月4日成都市气象站X波段雷达15时14分体扫资料得到的12000 m高度上的原始雷达回波图,图4为利用SCIT识别后其单体图。 图5为2012年4月4日成都市气象站X波段雷达15时34分体扫资料得到的12000 m高度上的原始雷达回波图, 图6为利用SCIT识别后其单体图。图7为2012年4月4日成都市气象站X波段雷达16时00分体扫资料得到的12000 m高度上的原始雷达回波图, 图8为利用SCIT识别后其单体图,发现未识别出单体。前3组效果图的对比验证了基于SCIT强风暴识别方法的可行性。 对识别出的单体图进行了简单的跟踪,14时52分识别出2个单体,但由于其中一个较小单体可能在下一时刻发生了消亡,而较强回波块在15时14分的匹配单体如图4中十字叉表示的位置,15时14分识别出了3个单体,其中被标记的为已存在的单体,至于其余两个单体可能是上一时刻较大单体发生分裂或者 图1 14时52分原始雷达回波图 图2 14时52分实际单体图 图3 15时14分原始雷达回波图 图4 15时14分单体生成图 图5 15时34分原始雷达回波图 图6 15时34分单体生成图 图7 16时00分原始雷达回波图 图8 16时00分单体生成图 新生风暴。在此,只对标记的风暴单体进行预报,通过线性外推得到在15时34分单体质心的预测位置,如图2中十字叉所在位置,与图6中标号为1的单体的实测位置最为接近,基本实现了单体1的跟踪与预报。对于图4中两个新生单体在下一时刻相匹配的单体为图6中编号2与3的两个单体,由于风暴单体生存周期短,所以26 min后3个单体发生了消亡,风暴周期结束。 在SCIT算法基础上适当作了些调整,对处理的数据资料由PPI转换到CAPPI上,进而在垂直关联上也稍作调整,并用实测体扫资料检验了风暴自动识别、跟踪与短时预报方法的可行性,得到了不错的结果。但是,由于在识别过程中引用到的许多阈值都是国外长期研究总结的结果,并非是研究强对流风暴唯一的阈值,所以在试验过程中针对本文的情况作了一下改动,发现识别结果更好些。另外,可能由于较高层上单体较少以及没有地物杂波等的影响,所以得到的跟踪效果比较可观,但是对较低层进行验证时出现的跟踪结果不太好,需要在以后工作中进行改进。 [1] Zittel W D. Computer applications techniques for storm t racking and warning// Amer. M eteor. Soc, eds, Reprints of 17th conf on Radar Meteor, Boston: 1976:514- 521. [2] Dixon M, G Wiener. TITAN: Thunderstorm identification, tracking, analysis, and nowcasting—A radar-based methodology[J].J.Atmos.Oceanic Technol., 1993(10):785-797. [3] 肖艳姣,汤达章,李中华,蒋义芳.风暴的自动识别、跟踪与预报[J].南京气象学院学报,1998,21(2):223-229. [4] Johnson J T, Mac Keen P L, Witt A, et al. The storm cell identification and tracking algorithm: an enhanced WSR-88D algoritnm[J].Weather and Forecasting, 1998(13):263-276. [5] 张鹏,胡明宝,吴书君.多普勒天气雷达单PPI探测强风暴的方法[J].解放军理工大学学报,2003,4(3):83-85. [6] 王芬,李腹广,张辉. 风暴单体识别与跟踪(SCIT)算法评估[J].气象,2010,36(12):128-133. [7] 王改利,刘黎平,阮征,等. 基于雷达回波拼图资料的风暴识别﹑跟踪及临近预报技术[J].高原气象,2010,29(6):1546-1555. [8] 徐春芳.多普勒天气雷达的风暴单体自动识别算法及工程设计[D]. 南京信息工程大学理学硕士学位论文,2006. Storm identification and tracking of weather radars based on SCIT algorithm TANG Yu-jie, SHE Yong (Electronic Engineering School, Chengdu University of Information Technology, Chengdu 610225) The earliest nowcasting technology is referred to as the method of storm identification, tracking and early-warning based on radar data, and accurate storm identification is the premise of storm tracking and early-warning. The Storm Cell Identification and Tracking (SCIT) algorithm is used to identify strong storms, and storm cells at two adjacent time are matched according to the principle "better short than long and similar characteristics". The linear extrapolation is carried out through the centroid positions in the past two moments to forecast the storm position next time. The result shows that strong storms can be better identified and roughly tracked. SCIT; linear extrapolation; nowcasting 2013-12-10; 2014-01-02 汤玉杰(1988-),女,硕士研究生,研究方向:雷达信号与信息处理;佘勇(1968-),男,教授,研究方向:天气雷达信 号处理技术及其应用。 TN959.4 A 1009-0401(2014)01-0019-032 风暴跟踪与预报
3 结果分析




4 结束语
