一种应用机器学习和D-S证据理论的Linux病毒检测方案*
2014-09-06黄一峰黄俊伟吴恋
黄一峰,黄俊伟,吴恋
(重庆邮电大学新一代宽带移动通信终端研究所,重庆 400065)
一种应用机器学习和D-S证据理论的Linux病毒检测方案*
黄一峰,黄俊伟,吴恋
(重庆邮电大学新一代宽带移动通信终端研究所,重庆 400065)
设计了一种应用机器学习和D-S证据理论来进行Linux病毒检测的方案。主要包括方案的总体框架、样本特征选择方法、分类器选择、检测效果融合以及方案验证与结果分析等。在样本特征选择时引入了控制流程图的概念,在检测效果融合时使用了D-S证据理论的方法。最后在基于Weka软件的机器学习平台上实现和测试了该方案。验证结果表明,该Linux病毒检测方案具有良好的检测率和可靠性,可以应用于实际的商业产品中。
Linux系统;病毒检测;机器学习;D-S证据理论;控制流程图
引 言
计算机病毒检测可以看作是机器学习理论中的二分类问题。机器学习理论在病毒检测中已经得到应用,但目前的研究多数是针对于Windows操作系统平台, 对Linux平台少有涉及。参考文献[1]介绍了机器学习在病毒检测中的一般流程。这些研究表明,机器学习在病毒检测中的表现优于传统的基于特征码对比的检测方式。
近年来,随着Android等基于Linux核心的衍生操作系统的流行,Linux操作系统平台下病毒检测与防治的重要性日益凸显。大致来说,Windows平台下的病毒检测思路可以为Linux下病毒检测提供借鉴。但两种操作系统在可执行文件格式、系统调用方式、内核空间划分等方面存在差异,因此有必要对Linux下的病毒检测进行具体的研究。
本文结合机器学习理论中分类问题的处理框架,提出了一种Linux病毒检测方案。包括检测系统的整体框架设计,特征选择预处理流程、以及基于D-S理论的对检测结果的整合流程。
在基于Weka软件的机器学习平台上实现本文提出的方案,在检测准确率、误判率等方面都得到较好的实验结果,验证了本文设计的可靠性和可行性。
1 检测系统方案设计
1.1 检测系统总体框架
本文提出的Linux病毒检测方案主要包括规则生成和病毒检测两个部分,如图1所示。
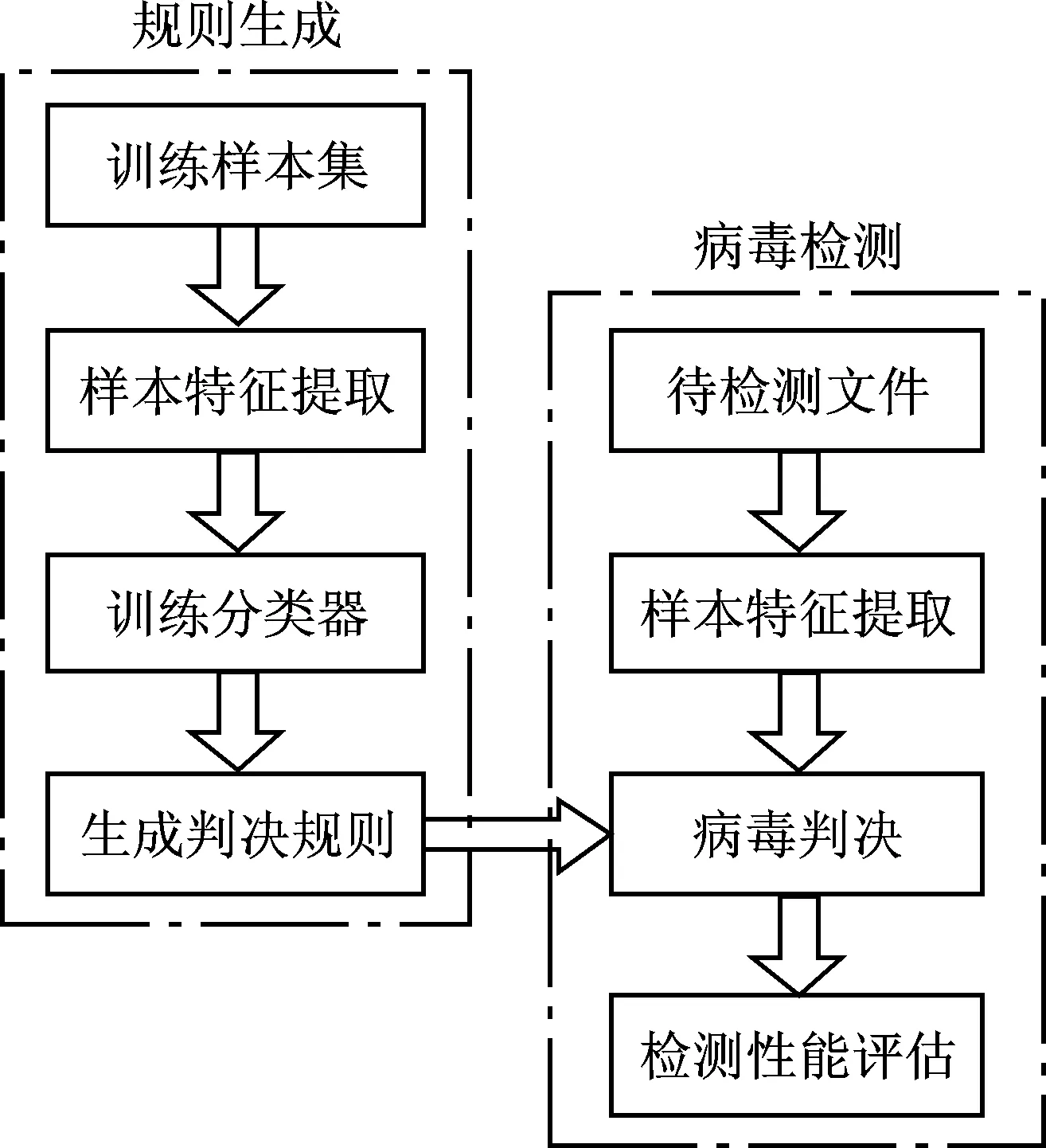
图1 Linux病毒检测方案整体框架
在生成判决规则时,首先需要获取一定量的训练样本(包括病毒和正常文件),然后从这些样本中提取出代表其特性的样本特征,最后将这些样本特征输入到机器学习分类器中,生成病毒判决规则。在这个过程中样本特征的提取方法和分类器的选择对系统的检测性能有重要影响,因此是规则生成模块的主要关注点。
病毒检测部分则是在提取待检测文件的样本特征后,利用前面生成的规则对其进行判决(病毒还是正常文件),这里的侧重点是对系统检测性能的评估。
1.2 样本特征提取
对于样本特征的提取选择动态(dynamic)和静态(static)两种方式。这样可以最小化两种检测方式的关联性,提高最后检测结果融合的效果。
这里动态特征选择的是程序流程控制图(CFG),静态特征选择为ELF代码段特征。
1.2.1 基于CFG的特征
现代的软件工程学把软件的内部拓扑结构视为一个有序的网络(network),代表了软件的内部控制流程和语义结构等信息[2]。通过CFG,可以表示软件内部的拓扑网络,提取出所需要的特征向量,进而作为病毒判决的依据。具体操作如下:
① 使用反汇编工具IDA Pro,将文件的二进制代码转换成汇编语言,并且生成其软件CFG。将函数作为CFG的最小组织单位,一个函数为一个网络节点,节点之间的连线表示函数间的调用关系。
② 根据每个函数在虚拟内存中的位置为其编号,作为CFG中节点的标识。
③ 定义需要从CFG提取的特征,包括节点数量(开始节点、结束节点、孤立节点等),连线数量,孤立子图数量等。
④ 使用一定的统计学方法从CFG中提取出特征,在本文中使用邻接表(adjacency list)保存CFG中的特征。
最后获得的部分特征如表1所列。从表中可以得到一些有用的信息,如正常文件的连线数和节点总数均大于病毒,表明正常文件内部函数间的交流要大于病毒文件。
最后,从软件的CFG中共得到了48种特征作为后续分类器的输入。
1.2.2 ELF代码段特征
在Linux操作系统中的可执行文件和库文件均采用ELF(Executable and Linking Format)格式来进行组织[3]。典型的ELF文件格式视如图2所示,包括ELF文件头、程序文件头、代码段等,其中的Segment和Section字段分别包含了可执行文件和库文件的主要代码信息。
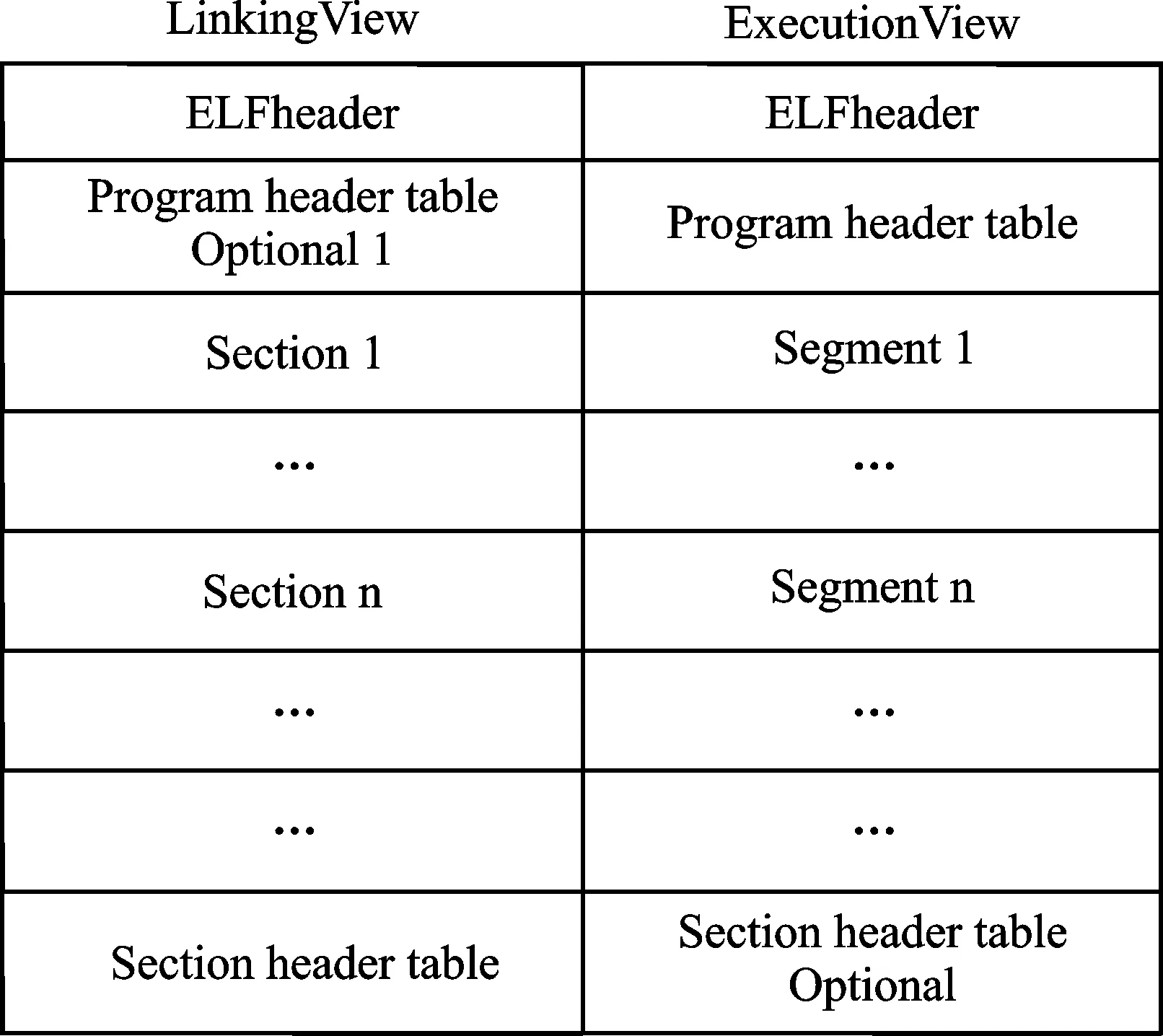
图2 ELF文件格式示意图
作为一种特殊可执行文件(具有破坏性),Linux操作系统下的病毒文件同样必须符合ELF文件格式的标准。与此同时,为了完成其破坏功能,病毒文件的代码段中必定包含一些与正常文件不同的特殊代码。因此,可以使用ELF文件中的Segment和Section字段的代码特征作为病毒检测系统的特征向量。具体操作如下:
① 使用Linux下的反汇编工具objdump将文件反汇编,得到其代码段的十六进制形式,图3为ls命令的十六进制代码截图。
② 使用N-gram[4]方法从十六进制代码段中提取特征向量,这里选用3-gam,共获得13 847个特征。
③ 由于特征比较庞大,使用信息增益的方法(IG)[4]的方法消除特征冗余,最后得到768个特征作为分类器的输入。
图3 ls命令反汇编后代码段截图
1.3 分类器算法选择
在机器学习理论中已经提出了多种经典的分类器算法。包括决策树算法、贝叶斯网络算法、支持向量机(SVM)、人工神经网络(ANN)等。
本文的重点不在于对各种分类算法的细节讨论,因此在此不对分类器算法的细节进行介绍。同时,图1的Linux病毒检测方案也不依赖于特定的分类器算法,具有较大的灵活性。为了讨论方便,选择决策树和人工神经网络(ANN)作为本文的分类器算法。
2 检测效果整合
对于检测效果的整合属于机器学习中集成学习的范畴,其目的是整合多个子分类器的结果,使集成后的检测效果优于各个子分类器的检测效果。D-S证据理论被广泛应用于集成学习中[5],结合D-S理论后Linux病毒检测系统如图4所示,这是图1的另一种表示方式。
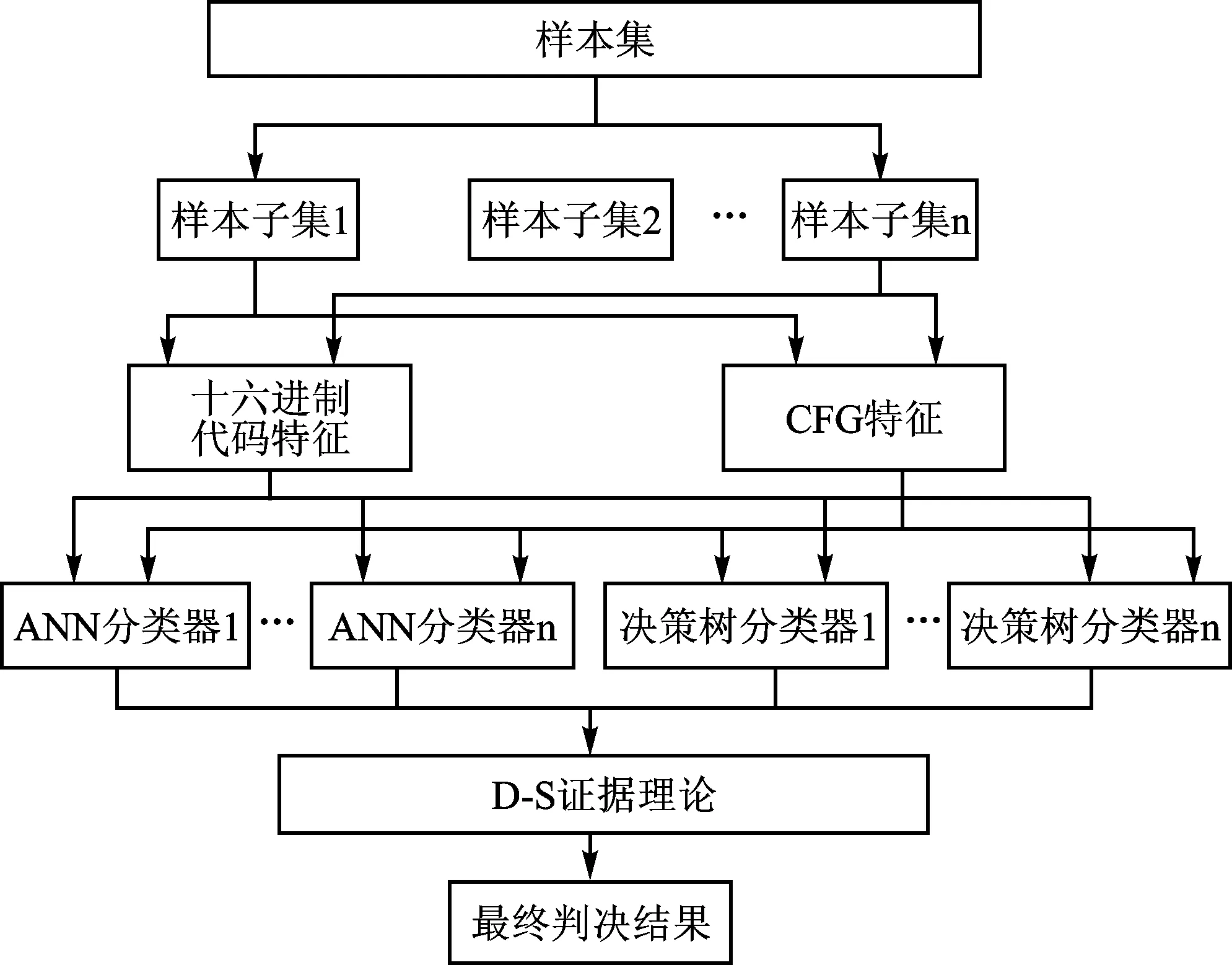
图4 结合D-S理论的病毒检测系统框图
其具体流程如下:
① 将包含正常文件和病毒文件的样本集随机划分为样本子集1、样本子集2……样本子集n。
② 对于每个样本子集,分别提取其十六进制代码段特征和CFG特征,作为分类器的输入。
③ 将每个样本子集的两类特征分别作为每个子分类器的输入得到分类结果。譬如对样本子集1,将其十六进制代码段特征作为ANN分类器1至ANN分类器m的输入,得到m种分类结果,再将十六进制代码段特征作为决策树分类器1至决策树s分类器的输入,得到s种分类结果;对于样本子集1的CFG特征,采用同样的方式处理。因此,对于每个样本集,最后得到(m+s)种分类结果;整个系统得到(m+s)·n种分类结果。
④ 将得到的(m+s)·n种分类器进行基于D-S理论的结果整合,得到最终的判决结果。
在使用D-S理论融合各种分类器结果的过程时,将各个分类器的分类表现作为基本的概率分配函数。在参考文献[5]中的手写字识别过程研究中,提出了一种基于识别率、拒绝率的概率分配方法,实验表明这种方法具有稳定性并且优于表决法。
但在参考文献[5]中提出的方法在病毒检测中具有局限性,因为其并没有考虑各子分类器在不同的分类选项中的表现。对其改进如下:
① 在病毒检测中,检测结果只有正常和病毒两种,所以命题空间为Ω={N,﹁ N,A,﹁ A},其中N表示对样本判定为正常的信任,﹁ N对样本判定为正常的不信任,A表示对样本判定为病毒的信任,﹁ A对样本判定为病毒的不信任。
② 据此,建立以命题组合为基础的概率映射M:2{N,﹁ N,A,﹁ A}→[0,1],其中M(φ)=0,M{N,﹁ N,A,﹁ A}=1-M(N)-M(﹁ N)-M(A)-M(﹁ A)。
③ 对于一个给定的测试样本x,每个子分类器n都会作出对这个样本类型的判断,即信任其正常(N)、信任其不正常(﹁ N)、信任其为病毒(A)、信任其不为病毒(﹁ A)。对于每种情况的置信函数定义为:
(1)
其中,TP、FP、TN、FN分别是病毒被正确分类、正常文件被正确分类、病毒被错误分类、正常文件被错误分类的比例。
④ 对由m个ANN分类器和s个决策树分类器的组合,一个样本的命题基本概率BPA赋值函数为:
M=mann(1)⊕…mann(m)⊕mdecison tree(1)⊕…mdecison tree(s)
⑤ 最后,最终判决结果表示为:
E(x)=θjif bel(θj)=arg max Bel(θi)
3 实验结果与分析
从专门提供病毒样本的vxheaven.org网站上得到共949个Linux文件样本,其中正常文件503个,病毒文件446个。两种文件大小的信息如表2所列。

表2 实验样本大小数据
除了验证本文提出的方案外,还测试了单独使用ELF代码段和CFG特征的检测效果。在实验中使用了10折交叉验证的方法来减少系统误差。
实验结果如表3所列,从中可以得到如下结论:
① 程序的内部拓扑结构能很好地表示一个程序的特征,使用CFG方法的病毒检测率在96.88%以上,具有较高的检测率。
② 使用CFG方法获得的特性维数要明显低于N-gram等方法获得的特征维数,相同的样本集,CFG方法获得48种特征。N-gram方法得到768种特征,二者的检测效果相当。这说明CFG方法能在维持检测效果的情况下降低系统的运算负荷。
③ 结合了ELF代码段特征和CFG特征的检测器的效果优于单一的检测器。因为ELF代码段特征和CFG特征具有无关性,基于D-S证据理论的集成分类器的性能得到了最大程度的融合。
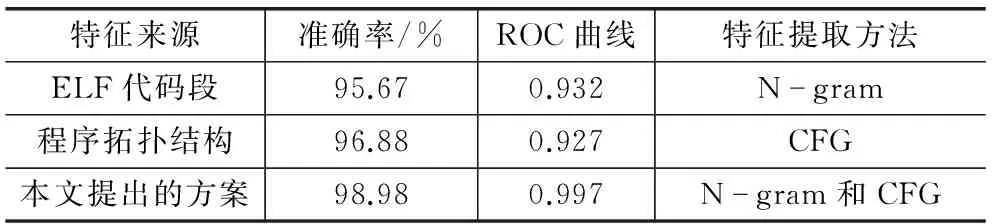
表3 三种检测器效果对比
结 语
本文提出的Linux病毒检测方案已经在Weka开源机器学习平台上实现。
本文方案的设计结合了机器学习和D-S证据理论的研究方法。在样本特征提取时选择了动态调用和静态代码段特征,减少了二者的耦合性,提高了最后结果融合的效果;使用CFG获得的特征反映了程序的内部拓扑结构,得到的特征维数较小,能够提高系统的运行效率。最后,在应用D-S理论进行结果融合时,使用子分类器的检测效果作为其置信函数,恰当地反应了各子分类器的检测能力,提高了整个系统的检测性能。

[1] Gavrilut D,Cimpoesu M,Anton D, et al. Malware detection using machine learning[C] //Computer Science and Information Technology, 2009. IMCSIT '09. International Multiconference on.IMCSIT, 2009: 735-741.
[2] Zongqu Zhao. A virus detection scheme based on features of Control Flow Graph[C]// Artificial Intelligence, Management Science and Electronic Commerce (AIMSEC), 2011 2nd International Conference on AIMSEC, 2011:943 - 947.
[3] 朱裕禄. Linux系统下的ELF文件分析[J].电脑知识与技术, 2006(8):111-113.
[4] 张小康,帅建梅,史林.基于加权信息增益的恶意代码检测方法[J].计算机工程, 2010, 6(36):149-151.
[5] 雷蕾,王晓丹.结合SVM与DS证据理论的信息融合分类方法[J].计算机工程与应用, 2013(11):114-117.
[6] Xu L. Methods of combining multiple classifiers and their applications to handwriting recognition[J]. IEEE Transactions on Systems,Man and Cybernetics Society, 1992(5/6):418-435.
黄一峰(硕士),研究方向为Linux应用软件开发;黄俊伟 (正高级工程师),研究方向为TD-SCDMA移动通信终端开发;吴恋(硕士),研究方向为嵌入式Linux终端设备开发。
参考文献
[1] 董超,李立伟,张洪伟.新型电动汽车锂电池管理系统的设计[J].通信电源技术,2012(29):33-35.
[2] 张金顶,王太宏,龙泽,等.基于MSP430单片机的12节锂电池管理系统[J].电源技术,2011(35):514-516.
[3] Paul Horowitz, Winfield Hill.电子学[M] .2版.吴利民,等译. 北京: 电子工业出版社, 2011:749-754.
[4] 沈建华,杨艳琴,翟骁曙.MSP430系列16位超低功耗单片机原理与应用[M].北京: 清华大学出版社, 2004.
[5] 林成涛,王军平,陈全世.电动汽车SOC 估计方法原理与应用[J].电池,2004(35):336-338.
[6] 李文江,张志高,庄益诗.电动汽车用铅酸电池管理系统SOC算法研究[J].电源技术,2010(34):1266-1268.
[7] 李哲,卢兰光,欧阳明高.提高安时积分法估算电池SOC精度的方法比较[J]. 清华大学学报:自然科学版,2010(50):1293-1296.
陈翰沫(硕士研究生),主要从事仪表与测量技术的研究。
(责任编辑:高珍 收稿日期:2013-11-02)
A Linux Virus Detection Method Using Machine Learning and D-S Theory
Huang Yifeng,Huang Junwei, Wu Lian
(Next Generation Mobile Communication Terminal Laboratory,Chongqing University of Posts and Telecommunications,Chongqing 400065,China)
This paper mainly designs and realizes a Linux virus detection method using machine learning and D-S theory. It includes the design’s general framework, feature selection method, classifier selection method, detection result fusion and the design verification and result analysis. It intrdouces the control flow graph while doing feature selection, and introduces D-S theory while doing detection result fusion. Then it implements and test the method on the platform of Weka software. The results of implementation show that this design to detect Linux virus has high efficiency and good reliability, and it is adequate for commercial products.
Linux operating system; virus detection; machine learning; D-S theory; CFG
国家重大专项“TD-SCDMA增强型多媒体手机终端的研发和产业化”(2009ZX03001-002-01)。
TP36.2
A
珍
2013-11-11)
